
2019-12-19 21:00
算法偏见:看不见的“裁决者”

扫码打开虎嗅APP

本文来自微信公众号:腾讯研究院(ID:cyberlawrc)
我们生活在被AI算法包围的时代。技术的进步致使AI突破过去的使用边界,进入到更深层次的决策领域,并对我们的生活产生重要影响。AI成为了招聘面试官,成为了量刑助手,成为了裁决入学申请的老师……这项技术无疑为我们带来了便利。但同时,一个更加不容忽视的问题也浮出水面——算法偏见。
据BBC11月1日报道,苹果公司联合创始人斯蒂夫·沃兹尼亚克在社交媒体上发声称,苹果信用卡给他的信用额度是他夫人的10倍,尽管夫妻俩并没有个人单独的银行账户或任何个人资产。这不禁让人思考,苹果公司的信用额度算法是否存在性别歧视?
事实上,被歧视的不仅是女性,偏见蔓延的领域也远不止银行贷款额。本期特写,我们就从典型的算法偏见类型说起,细细追究,偏见到底是如何钻进机器大脑,而未来我们又将以何来对抗偏见?
算法偏见的典型类别
技术的包容性不足
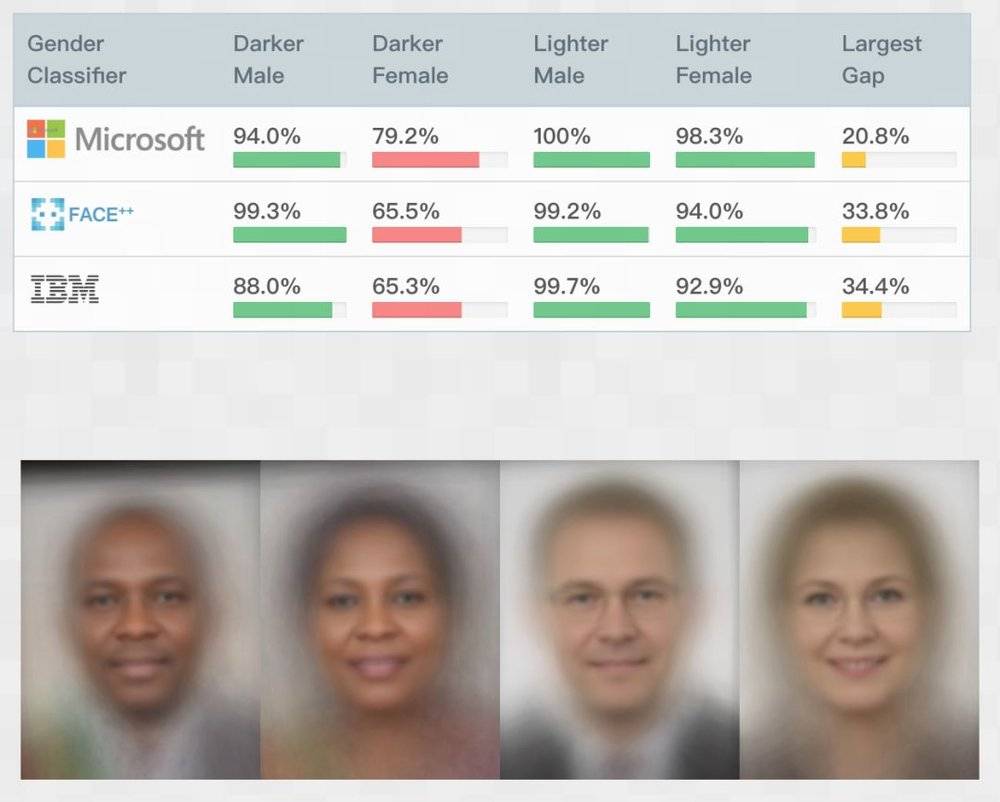
加纳裔科学家Joy Buolamwini一次偶然发现,人脸识别软件竟无法识别她的存在,除非带上一张白色面具。有感于此,Joy发起了Gender Shades研究,发现IBM、微软和旷视Face++三家的人脸识别产品,均存在不同程度的女性和深色人种“歧视”(即女性和深色人种的识别正确率均显著低于男性和浅色人种),最大差距可达34.3%。
这个问题的本质,其实是人脸识别技术对不同群体的包容度不足。正如我们开发一款产品时,天然容易切合中青年人的使用习惯,而忽略其对老龄或儿童带来的使用后果,又或者将残障人士排除在使用者之外。
图源:算法正义联盟官网
预测、决策不公
如果包容性问题更多指向的是少数族裔或女性,那么预测和决策不公就更可能发生在任何人身上。比如,招聘偏见。今年11月被高盛、希尔顿、联合利华等名企采用的AI面试工具——HireVue,它的决策偏好让人匪夷所思:AI 分不清你皱眉是因为在思考问题,还是情绪不佳(暗示性格易怒);英国达勒姆警方使用了数年的犯罪预测系统,将黑人是罪犯的概率定为白人的两倍,还喜欢把白人定为低风险、单独犯案。(DeepTech深科技)
当下生活中,AI参与评估决策的领域远不止此。除了犯罪、就业,还包括金融、医疗等领域。AI决策依赖于对人类决策偏好和结果的学习,机器偏见实质上投射出了根植于社会传统的偏见。
偏见的展示
在搜索引擎输入“CEO”,会出现一连串男性白人面孔;有人将关键字换成“黑人女孩”,甚至出现过大量的色情内容。微软开发的机器人Tay,在twitter上线仅一天便被下架,原因是受到用户的影响,出现了种族歧视和偏激言论。(THU数据派)这种偏见,既来源于用户交互中的学习,又重新被AI产品赤裸呈递给更广大的受众,从而产生了连锁的偏见循环。
算法的偏见来自哪里?
算法并不会生而歧视,工程师也很少刻意将偏见教给算法。那偏见究竟从何而来?这个问题与人工智能背后的核心技术——机器学习休戚相关。
机器学习过程可化约为如下步骤,而为算法注入偏见的主要有三个环节——数据集构建、目标制定与特征选取(工程师)、数据标注(标注者)。

数据集:偏见的土壤
数据集是机器学习的基础,如果数据集本身缺乏代表性,就不能够客观地反映现实情况,算法决策就难免有失公允。
这一问题的常见表现为配比偏差,出于数据采集的便利性,数据集往往会倾向更“主流”、可获取的群体,从而在种族、性别层面分布不均。
Facebook曾宣布,经世界上人脸识别最知名数据集之一的Labeled Faces in the Wild测试,其面部识别系统的准确率高达97%。但当研究人员查看这个所谓的黄金标准数据集时,却发现这个数据集中有近77%的男性,同时超过80%是白人。(全媒派)这就意味着,以此训练的算法在识别特定群体时可能会出问题,比如在Facebook的照片识别中,女性和黑人很可能无法被准确标记出来。
另一种情况是,现存的社会偏见被带入数据集。当原始数据本就是社会偏见作用的结果,算法也会习得其中的偏见关系。
亚马逊发现,其招聘系统存在偏差的原因在于,该算法所使用的原始数据是公司的过往员工数据——过去,亚马逊聘用的男性偏多。算法学习到了数据集所表现的这一特征,因此在决策中更容易忽略女性求职者。(麻省理工科技评论)
事实上,几乎每一个机器学习算法背后的数据库都是含有偏见的。
工程师:规则制定者
算法工程师从头到尾参与了整个系统,包括:机器学习的目标设定、采用哪种模型、选取什么特征(数据标签)、数据的预处理等。
不恰当的目标设定,可能从一开始就引入了偏见,比如意图通过面相来识别罪犯;不过,更典型的个人偏见代入,出现在数据特征的选取环节。
数据标签就是一堆帮助算法达成目标的判定因素。算法就好像一只嗅探犬,当工程师向它展示特定东西的气味后,它才能够更加精准地找到目标。因此工程师会在数据集中设置标签,来决定算法要学习该数据集内部的哪些内容、生成怎样的模型。
亚马逊的招聘系统中,工程师可能为算法设置了“年龄”、“性别”、“教育水平”等标签。因而在学习过往聘用决策时,算法就会识别其中的这一部分特定属性,并以此为核心构建模型。当工程师认为“性别”是一个重要的考量标准时,无疑就会影响到算法对数据的反应。
打标者:无意的裁决
对于一些非结构化的数据集(如大量描述性文字、图片、视频等),算法无法对其进行直接分析。这时就需要人工为数据进行标注,提炼出结构化的维度,用于训练算法。举一个很简单的例子,有时Google Photos会请你帮助判断一张图片是否是猫,这时你就参与了这张图片的打标环节。
当打标者面对的是“猫或狗”的提问时,最坏结果不过是答错;但如果面对的是“美或丑”的拷问,偏见就产生了。作为数据的加工人员,打标者时常会被要求做一些主观价值判断,这又成为偏见的一大来源。
ImageNet就是一个典型的案例:作为世界上图像识别最大的数据库,网站上的许多图片均被手动注释,打上各种各样的细分标签。“尽管我们不可能知道这些贴标签的人本身是否带有这样的偏见。但他们定义了“失败者”、“荡妇”和“罪犯”应该长什么样……同样的问题也可能发生在看似‘无害’的标签上。毕竟,即使是‘男人’和‘女人’的定义,也有待商榷。”(全媒派)
Trevor Paglen是ImageNet Roulette项目的发起人之一,这一项目致力于展示观点、偏见甚至冒犯性的看法是如何影响人工智能的。他认为:“我们对图像的贴标签方式是我们世界观的产物,任何一种分类系统都会反映出分类者的价值观。”不同的文化背景下,人们存在着对于不同文化、种族的偏见。
打标过程正是将个人偏见转移到数据中,被算法吸纳,从而生成了带有偏见的模型。现如今,人工打标服务已成为一种典型商业模式,许多科技公司都将其海量的数据外包进行打标。这意味着,算法偏见正通过一种“隐形化”、“合法化”的过程,被流传和放大。
小结
由于AI技术的大量应用和黑箱原理,算法偏见早已成为一个隐匿但作用广泛的社会隐患。它会在决策中带入不公,让人脸识别技术只惠及一部分人,在搜索结果中大张旗鼓地展示偏见观点......
但是机器从未独立创造偏见,偏见习得于机器学习中的几个重要环节:从数据集的不均衡,到特征选取的偏颇,再到人工打标带入的主观性。在从人到机的迁移中,偏见习得了某种“隐匿性”与“合法性”,并被不断实践和放大。
但回过头来,技术不过是社会与人心的一面镜子。某种程度上,算法偏见就像在这个我们认为进步、美好的当下,重新呈递灰暗角落的真相并敲响警钟。因此,当谈及算法偏见的应对时,一部分努力便是要回归于人。可幸的是,即便是技术层面的自律与治理尝试,也能极大地降低偏见程度、避免偏见大幅扩张。这些方法是什么?
本文来自微信公众号:腾讯研究院(ID:cyberlawrc)
 05:05
05:05
 07:46
07:46


 08:45
08:45








 06:16
06:16
 20:01
20:01
 11:22
11:22
 10:20
10:20
 14:21
14:21
 23:16
23:16
 13:10
13:10




