

出品丨妙投 APP
作者丨李赓
头图丨视觉中国
今天凌晨4点,英伟达如约在GTC2024上“交出”一系列技术和产品创新成果。
作为全球 AI 行业毫无疑问的 “卖铲人” 和 “铺路人”,对于英伟达自身的市场价值有怎样的影响?英伟达又为全球AI产业给出了什么“风向标”?其中又有哪些与A股相关的机会值得投资者关注?
抛开各种常规内容的报道,我简单为大家聊聊我的看法。
一、英伟达本身的价值影响
先给个观点总结:这次GTC再次展示了英伟达对于AI毫无争议的“主权”。
从全球半导体行业技术进展愈发艰难下大环境下,英伟达照样可以拿出性能更强悍的GPU芯片;到英伟达自身愈发强大的局域网网络通信能力;再到英伟达超大GPU集群上全新采用的液冷服务器机架解决方案,都能看出英伟达在基础设施硬件上的强悍实力。

参考全新B200 GPU相对于上一代H200 GPU的综合应用性能提升(典型场景7-30倍提升),去年年末开始宣称在性能上要开始追上英伟达的各种芯片解决方案(AMD、Intel、其他芯片创业公司),即将在AI算力和AI成本上再次被英伟达抛离。
相比硬件统治性能更厉害的,是英伟达此次在AI产业应用落地祭出的“小”创新——“英伟达推理微服务(NVIDIA Interference Microservices,NIM)”。
早在去年,在 ChatGPT 能力之上二次开发的 AutoGPT 就曾大火过一波,当时 AutoGPT 的策略是通过 ChatGPT 的多次循环,实现对复杂目标的拆分和分散寻找答案。但随着后来的实践,整个行业其实已经看到了其中的关键——单个AI大模型很难解决所有问题,至少只靠语言不行。
在那之后没多久,OpenAI自己就对外发布了开发者基于GPT能力进行二次应用开发的GPT Store。相应的,智能体的概念也一度大火了一把。
但究竟如何将分散的、解决不同场景、不同需求的智能体(可以理解为不断提升能力的大模型)组织起来,进一步实现复杂问题的解决。包括后期智能体覆盖人类绝大多数需求之后,在单一入口实现“一步到位”解决绝大多数问题,变相实现通用人工智能(AGI),其实大家一直没有给出一套完整的解决方案。
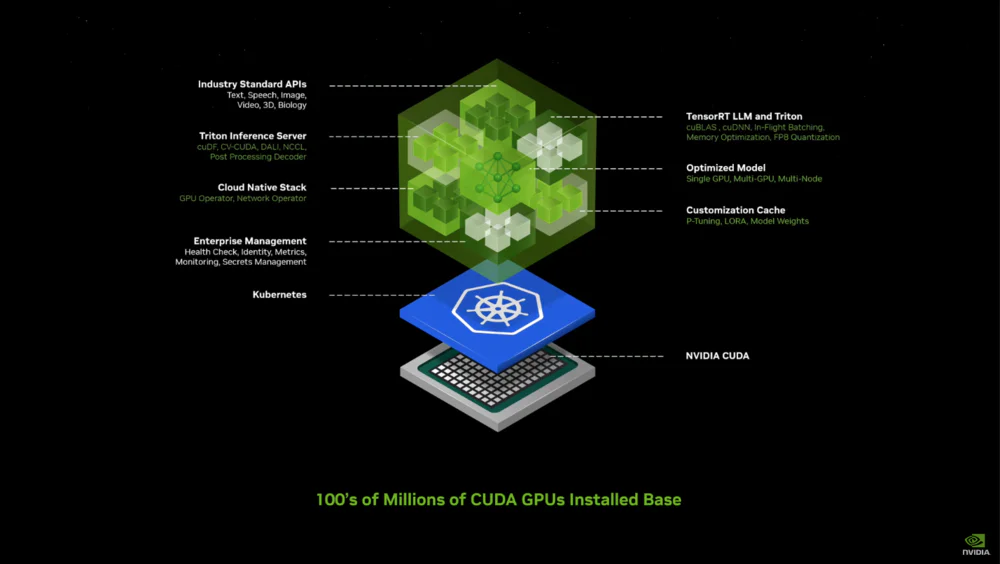
而NIM正是因此而诞生,上层将单个智能体的所有组件(行业 API,AI 算法支持库、云端架构支持、AI 算法加速、定制模型、定制存储、企业管理等)全部打包,然后通过k8s的容器化技术,直接与拥有NVIDIA CUDA计算能力的硬件对接。
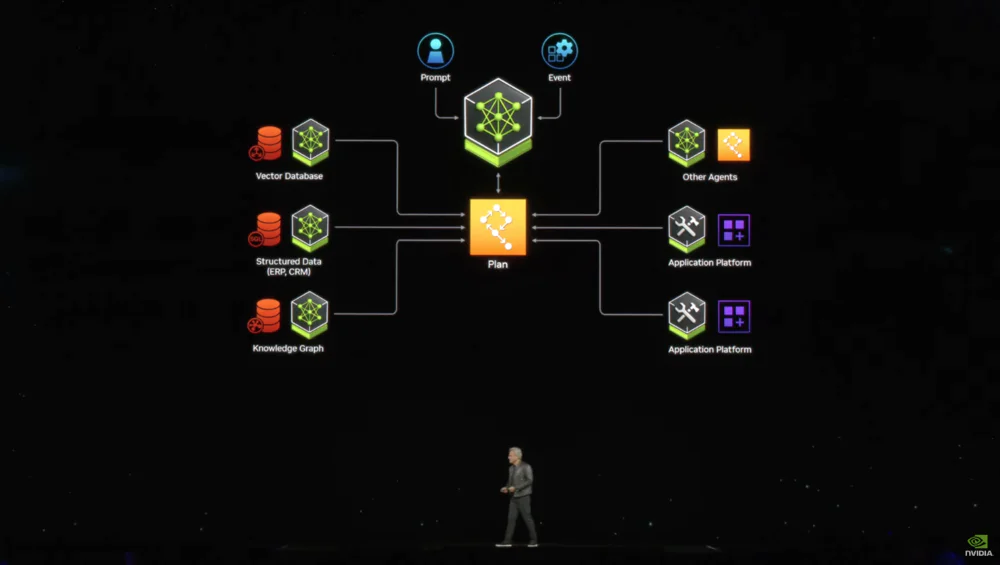
按照黄仁勋的构想,多个智能体将在基础大模型的组织协调下共同解决复杂问题
从硬件到应用计算结果的全过程,NIM扮演的角色就是PC时代的操作系统。虽然未来其他厂商大概率还会在NIM的骨架上套上各种各样的外皮,但至关重要的骨架部分,已经被英伟达所占据(反过来说,也是因为其他厂家没有英伟达这样的实力)。
考虑到英伟达目前对于自身硬件、自身CUDA生态的绝对话语权体系,NIM大概率将逐步把各种有潜力的 AI 模型和应用,紧紧地绑定在英伟达有着明显优势的云端算力性能和成本之上。
二、对AI产业的指向意义
NIM这套体系如此的强势也透露出了英伟达对于AI产业的一个预测——所有端侧AI应用构想,或将在不久的将来面临被直接淘汰的“窘境”。
进入2024年,包括国内手机厂商甚至是苹果这样的全球龙头移动设备公司,都在推动着自身设备的AI化,不断放出诸如“以后只做AI硬件”的狠话。但现实的情况是,即便强如苹果的M系列Ultra芯片,在运行单个图片生成的大模型,也需要几秒钟的反应时间。
这些辛辛苦苦才计算出来的结果,对于大部分用户而言,还只是“图一乐”的存在。侧面反应了当前端侧硬件设备计算能力,与人类实际AI需求之间的巨大隔阂。

人类从1960年至今,的确一步步在CPU层面的需求上,完成了从只能计算加减乘除的巨型机,到随手塞入裤袋还能无线通信的智能手机的跨越。
只可惜由于AI诞生的全新计算需求,我们很可能要重新在这个尺度把流程走一遍,这个过程要多久不好说,甚至有可能会比60年更长(同时也要考虑能源变革方面的进展)。
强烈建议投资者在这两年看待相应的AI创新机会时,要更加谨慎。
三、A股相关机会
遍观英伟达的整场发布会,对于A股有直接影响的大致只有两个概念,一个是光模块,一个是液冷服务器。
液冷服务器因为英伟达也没有直接透露供应商是谁,所以先不展开分析,重点讲讲光模块。
英伟达基于此次发布的B200 GPU打造了多种数据中心/计算中心解决方案,能够直接替换上一代H100系列的传统DGX没什么好聊,但是全新的GB200模块,液冷计算节点(就是1U内放入两个GB200模块)、GB200 NVL72机架,以及由NVL72机架所组成的超级计算机集群,一口气对于集群的网络通信能力提出了全新的需求。

根据官方参数表来看,单个NVL72机架大概需要72个400Gb光模块和36个200Gb光模块。
如果涉及多个NVL72机架,则需要英伟达此次专门配套研发的搭载64个800Gb/s端口、且配备RoCE自适应路由的NVIDIAQuantum-X800InfiniBand交换机,以及搭载144个800Gb/s端口,网络内计算性能达到14.4TFLOPs(每秒14.4万亿次)的Spectrum-X800交换机。
根据官方介绍,如果客户追求超大规模、高性能可采用 NVLink+InfiniBand 网络;如果是多租户、工作负载多样性,需融入生成式 AI,则用高性能 Spectrum-X 以太网架构。
考虑到接下来全球对于英伟达全新云端AI算力的建设需求,很可能会相应拉升国内800Gb光模块厂商的未来生产需求。值得投资者重点关注。

评论