

头图 | 视觉中国
本期的“AI 内参”首先关注全球范围内的云计算巨头垄断风险,当美国三大云计算公司获取全球六成云市场支出、中国四大云计算公司拥有近八成中国市场,这个领域接下来会有怎样的变化?
2022 年的大模型继续流行,Meta 的翻译模型与语言模型、Yandex 的千亿参数模型等陆续开源,大模型是否会成为通往 AGI 的必由之路?
虽然微软停止销售面部识别技术,但基于面部识别的各类产品还是层出不穷;亚马逊 Alexa 新功能是否增加声音的“Deep Fake”?以及,沃尔玛的云计算案例、英伟达继续统治 MLPerf 2.0 竞赛等,都是本期关注的议题。
接下来,欢迎和我一起复盘最近围绕计算与智能的产业变化。
云
无论是全球,还是中国市场,云计算产业呈现出的“头部效应”越发明显,WSJ 援引咨询公司 Synergy Research 的数据称,2022 年第一季度,美国三大云计算公司——AWS、Azure、Google Cloud——在全球 530 亿美元的云计算市场里占比达到 65%。
四年前,这个比例还是 52%。考虑到整个产业的“蛋糕”越来越大,这也和三大云计算公司近来持续增加的营收相呼应。
在中国,结合咨询公司 Canalys 不久前给出的数据,2022 年第一季度,中国云市场总体规模达到 73 亿美元,阿里云、华为云、腾讯云、百度云四家公司瓜分了将近 80% 的市场份额。

更进一步去看,云计算领域的“头部效应”也会在产业与政策层面产生深远影响。一方面,无论是 AWS 还是微软、阿里云,早已不局限于所谓云服务商的定位,向下定义硬件——芯片、服务器——与向上延伸服务,已然成为一股潮流,这将极大改变过往 IT 产业的价值分工体系。
譬如云上的机器学习争夺战,根据 Gartner 不久前发布的云 AI 开发者魔力象限,美国三大云计算公司与阿里云、腾讯云上榜,这些云计算巨头利用其规模优势,构建起庞大的机器学习服务平台,以下是几家公司在机器学习开发领域的优势和不足:
微软:其最大的特点是将 AI 开发服务整合到其庞大的 2B 产品线里,但除了北美地区之外,其他地区的 AI 开发服务产品较少;
AWS:SageMaker 极大降低了在 AWS 平台开发部署机器学习服务的门槛,但 AWS 的机器学习服务显然还没有为多云或混合云场景做好准备;
Google:Google 在数据集、模型层面拥有不小的优势,不过对私有云的支持力度有限,而且其模型局限在神经网络领域;
阿里云:阿里云的 AI 开发服务或产品非常多,而且拥有一定的价格优势,但其 AI 开发者群体基本都在中国,海外影响力非常有限;
另一方面,美国三大云计算公司在欧洲拥有巨大影响力,而欧洲作为全球科技监管的前沿阵地,势必会进一步加强对 AWS、微软等公司是否涉及垄断的审查,甚至,分拆 AWS 也会成为一个备选项。
沃尔玛最近分享了该公司部署云计算的案例,几个要点:
采用混合云架构:将微软和 Google 的公有云与自己数据中心结合起来;
引入云原生技术;
根据沃尔玛的说法,上述架构可以灵活应对门店流量增长或促销时的价格变化等,极大提升了公司的运营能力,同时每年还能降低 10%——18% 的云计算支出。
两个新产品:
计算
英特尔最近的消息不少,上月,英特尔表示原计划在美国俄亥俄州兴建的一座芯片工厂推迟开工,这个工厂原计划 7 月 22 日正式开始建设,整个项目投资至少 200 亿美元。
之所以推迟开工,最大的原因是美国国会对是否推出支持芯片产业的法案还存在不确定性,根据此前的报道,美国国会计划推出总额为 520 亿美元的一揽子支持法案,支持芯片公司在美国国内建立工厂并开展研发工作。
从这个角度看过去,英特尔此举多少有点威胁的意味。
英特尔上周分享了旗下 Habana 实验室 Gaudi2 深度学习处理器的最新表现,根据英特尔的新闻稿,在业界知名的 MLPerf 2.0 竞赛里,Gaudi 2 在包括训练时间在内的多个指标上领先英伟达的 A100 GPU。
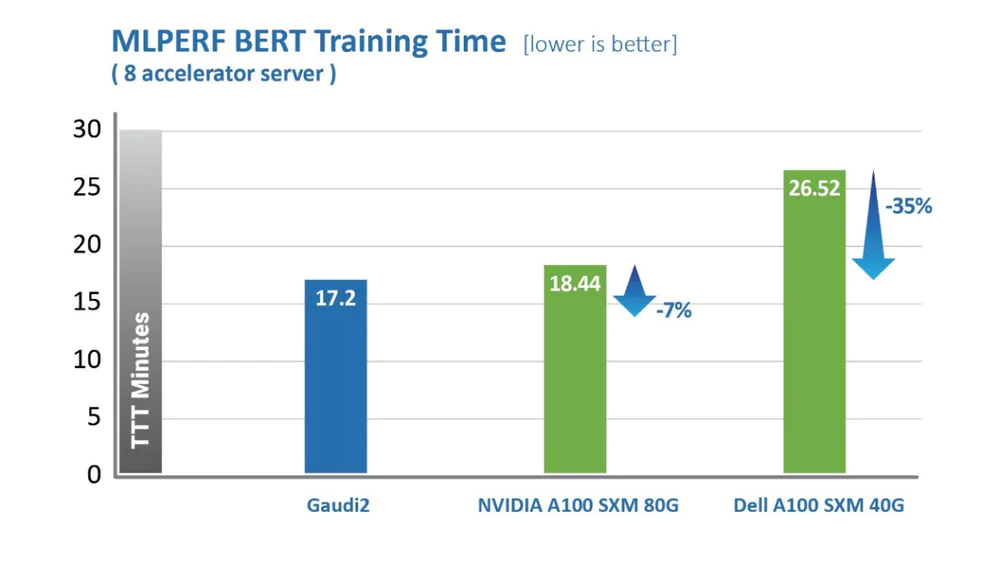
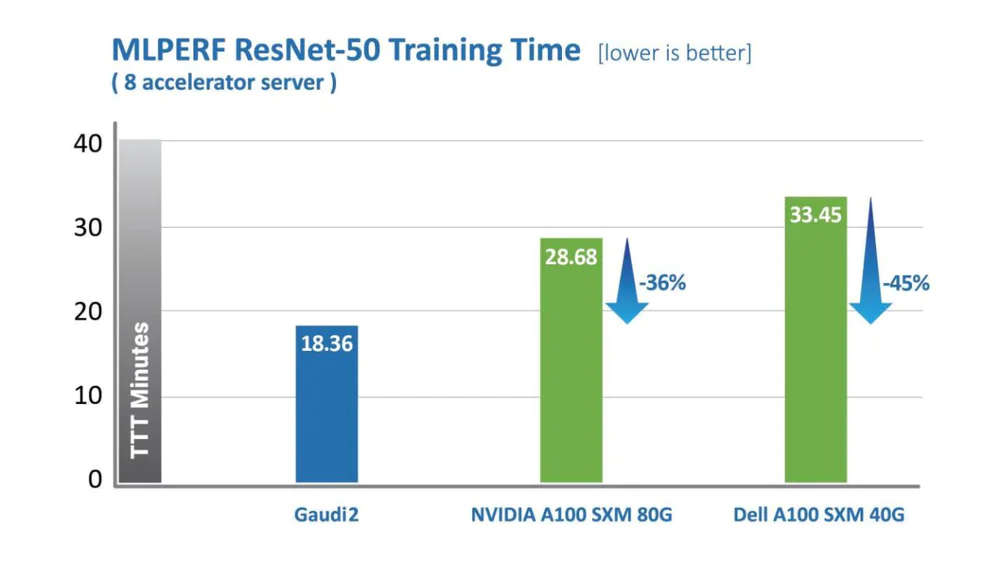
不过,英特尔并未透露 Gaudi2 和 A100 的性能对比。
事实上,在此次 MLPerf 2.0 比赛里,英伟达是唯一一家完成 8 项基准测试的公司,这些测试涵盖了从语音识别到推荐系统、NLP 以及目标、图像检测等多个领域。
与此同时,还有数十家公司采用英伟达的平台进行了测试,如下图所示,这些带有绿框的公司,都是基于英伟达的 GPU,由此可见英伟达的生态影响力。

开源指令集架构 RISC-V 被认为是包括中国在内的众多国家突破 X86 或 ARM 架构垄断的关键技术,中国科学院技术专家、现任中国 RISC-V 联盟秘书长包云岗在知乎撰文称,如果发生极端情况,中国可以“Fork”RISC-V 的代码(类似克隆),因为中国具备自主发展 RISC-X 架构的产品,且可与“一带一路”国家建立生态系统。
但问题是,芯片远不是架构这么简单。
大模型
Meta 最近不断释出自研的大模型。首先是开源了一个可以翻译 200 多种语言的翻译模型“No Language Left Behind (NLLB) ”,你可以在这里查看其 Demo 演示。
其次,Meta 也开放了拥有 660 亿参数的语言模型 Open Pretrained Transformer,根据 Meta 的说法,这是一种大语言模型的“民主化”尝试。
俄罗斯科技巨头 Yandex 日前也将一个 1000 亿参数的语言模型正式开源,这个名为 YaLM100B 的大模型允许商用。
大模型正在成为 AI 领域的关键基础设施,由此也引发一个命题:大模型会成为人类迈向 AGI(通用人工智能)的必由之路吗?
《经济学人》此前援引一份数字称:目前有 80% 的 AI 服务运行在大模型上。这个数字与微软首席技术官 Kevin Scott 的判断基本一致。
在中国,围绕 AGI 的研究包括三个领域:
机器学习
类脑智能
脑机接口
乔治城大学的研究者们以上述三个领域为切入点,梳理了国内 30 多个研究机构的公开研究报告和数据,勾勒出一幅中国特色的 AGI 探索之路,你可以在这里获取这份 78 页的分析报告。
AI+X
关注面部识别。微软上月底表示将逐步淘汰面部识别技术,自 6 月 30 日开始,除了特别批准的项目,微软将不再为新客户提供面部识别的技术或解决方案。
目前基于面部表情的情绪识别已经在众多领域被应用,比如在中国合肥市的一个宣传视频里,将“面部表情特征、脑电特征、皮电特征进行协同与融合,实现对党员接受思政教育时专注度、认可度、掌握度判断,从而了解思政教育的效果。”该宣传新闻稿已经删除。
Instagram 也在尝试将面部信息纳入到用户年龄审核机制里,系统会要求用户提供自拍照片或视频,然后根据面部特征估计用户的年龄。
值得一提的是,该机制并不是 Instagram 或其母公司 Meta 研发,而是借助第三方公司 Yoti 提供的技术,这家公司的技术同时也被英国、德国政府部门用来预测照片里的人物年龄。
关于 Yoti 公司的这项技术,感兴趣的朋友可以通过这个视频做进一步了解,你会发现,即便用户希望通过精心化妆来掩盖年龄信息,该系统还是可以判断出来。
谈到化妆,手机厂商 OPPO 日前申请了一份基于 AI 芯片的“化妆品推荐方法及相关装置”专利,尽管专利并未提及面部识别,但终究还是围绕“脸”进行“商业开发”,专利摘要这样写道:
本申请应用于电子装置,该电子装置包括控制器、AI芯片和显示屏,其中控制器用于获取用户需要化妆时所处的场景、场景对应的天气和用户需要化妆时的皮肤状态;AI芯片用于根据上述信息和推荐模型确定第一化妆品组合;显示屏用于显示上述组合中的化妆品。采用本申请实施例可提高化妆品推荐的准确度。
面部识别技术在大卖场或超市的主要应用场景是识别小偷,消费者研究公司 Choice 对 25 家澳洲连锁零售商进行了一组调查,该机构认为,面部识别技术的使用完全没有必要,这些零售商更多还是出于对数据的渴望。
再来看看几个 AI 落地的场景:
2022 年卡塔尔世界杯将引入基于 AI 的 VAR 裁判,以更好应对诸如越位等争议性的判罚;
法国能源巨头 Engie SA 使用 DeepMind 训练的神经网络技术,能够高效预测风电的输出能力,该公司计划在德国的 13 个风电厂部署这项技术;
微软与西班牙 CaixaBank 合作,成立 AI 创新实验室,除了开展围绕金融领域的 AI 产品创新之外,还将探索面向未来的办公机制,比如如何在元宇宙里办公;
《纽约客》的编辑使用 OpenAI 的 GPT-3 写诗, 其中的十四行诗写得非常不错;
温布尔登网球赛期间,IBM 上线了一个预测比赛结果的网站,基于 Watson 的 AI 技术进行赛事预测;
亚马逊近期发布了两个非常重要的产品。其一是语音助理 Alexa 的语音合成能力,能够根据用户提供的声音片段,快速模仿一个人说话的音色、语气等,这里有一个演示,各位不妨先看看。
站在亚马逊或科技公司的视角去看,该技术增加了语音助理机器人个性化、情感化的特质,比如在语音助理为孩子读故事书的场景里,如果此时的声音是孩子的奶奶,是不是能够提升用户体验呢?
但在另一个维度上,这其实也是一种“Deep Fake”,如果参考图像领域造假与合成所引发的后果,基于声音的“Deep Fake”,已经埋下了“作恶”的种子。
这也让我再次想起一句话:人类未来的很大一部分工作是检测所看、所听是否是由人类生产创造。
其二,亚马逊云计算部门 AWS 发布了对标 Github Copilot 的 CodeWhisperer。这个产品面向开发者,提供代码自动补全、自动优化等一系列功能,目前该产品已经以预览版的形式集成到了 AWS IDE 里,未来也会适配诸如 Visual Studio Code 等其他主流 IDE。
TechCrunch 的测试发现,相比于 Copilot 潜在的代码版权问题,AWS 这款产品会特别提醒开发者相关代码的许可证,正在一定程度可以缓解版权问题。
而就在不久前,Github 刚刚宣布 Copilot 结束测试进入商用阶段,每月需要 10 美元。
评论