1950年10月,曾经在二战期间领导英国团队破解德国恩尼格玛(Enigma)密码系统的图灵(Alan Mathison Turing)在哲学期刊Mind(《心》)上发表了一篇名为“Computing Machinery and Intelligence”(《计算机器与智能》)的文章,提出将“机器能否思考”这个难以定义的问题转换为模仿游戏。模仿游戏的规则是请来一个男人(A)、一个女人(B)和一个观察员(C,不论男女),在互相隔离的情况下,由C来提问,B可以诚实作答,而A要想方设法模仿B作答来迷惑C,如果C在超过30%的问题上都错误判断了谁是B,则A获胜。图灵提出的测试是把A换成一台机器,B和C仍然由人类来担当,那么C在游戏中会否被A迷惑,就可以替换“机器能否思考”的问题。后来,人们经常沿用模仿游戏里的设置,认为C如果在30%的问题上就何者为人做出错误判断,就说明机器通过了“图灵测试”。
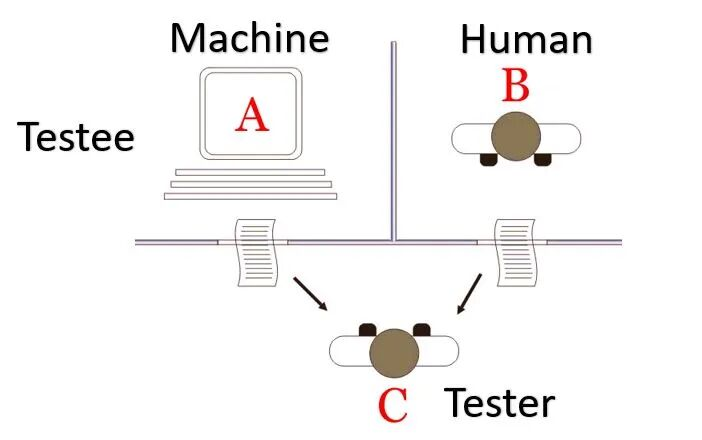
图为图灵测试。图片来自H2S Media
图灵测试很超前,自1956年麦卡锡(John McCarthy)等科学家在达特茅斯会议上首次正式提出“人工智能”(Artificial Intelligence,缩写为AI)这个术语以来,科学家们就将“用机器模拟人类智能”作为人工智能领域的目标。但在很长时间里,机器的表现完全达不到使用图灵测试的门槛。于是,科学家们又把这个大的目标分解为一些小的子目标——用机器模拟人类的某一项智能,比如下棋、问答和对话等。
人工智能的进展被大众感知到,最初主要因其在下棋方面取得突破,这一方面是因为棋类高手被公认为是智力超群的一类人,棋类游戏的普及让大众对任务难度有感知;另一方面则得益于测试的方式简单明了,只要让机器和人类的世界冠军比一比,输赢一目了然。机器模拟人类下棋在2016年达到顶峰,谷歌DeepMind团队研发的AlphaGo以4∶1的战绩在与人类围棋大师李世石的公开对战中获胜。之后人类逐渐接受了机器在下围棋方面已经达到了人类无法超越的水平。
有趣的是,与下棋相比,在问答和对话方面,机器经历了更漫长的时间才取得大众的认可。2011年,国际商业机器公司(IBM)研发的Watson参加了在美国大受欢迎的电视节目《危险边缘》(Jeopardy!)。这个节目中的佼佼者都有渊博的知识和擅长关联已知以处理未知的头脑,进入决赛的选手包括以74场胜利创造了最长不败纪录的肯·詹宁斯(Ken Jennings)、赢得了总额达325万美元奖金的布拉德·鲁特(Brad Rutter)和Watson。Watson存储了大量新闻信息、电影剧本、辞典、文选和《世界图书百科全书》(World Book Encyclopedia)等数百万份资料,并能利用信息检索和自然语言处理,针对那些冷门刁钻的问题做出正确的回答。在为期三天的决赛里,Watson最终击败詹宁斯和鲁特,获得第一名。
彼时,Watson开发了上百个算法分而治之地解析不同的问题以寻找答案,在今天看来,这样的技术的通用性并不强。在深度学习兴起(2020年GPT-3诞生和2022年ChatGPT出现)之前,自然语言处理通常会针对不同的任务提出专用的模型,比如翻译使用统计翻译模型,问答则使用问答模型,彼此之间共享的部分十分有限,也不会期望翻译模型能够完成问答,反之亦然。
从Watson到ChatGPT,对话的内容从特定领域扩展到开放性问题,从处理单一的知识问答任务到可以用提示词让模型完成各种各样的任务,人们似乎看到了这些模型通过图灵测试的可能性,因此也不断有媒体或学者采用图灵测试的方法来验证人工智能算法能否比肩人类。2017年,中央电视台推出的《机智过人》节目就曾精心设计人机对比的测试环节,测试内容涵盖人脸识别、诗歌创作、步态识别、语音合成、声纹识别等。从中可以看出,人们对人工智能的认识已经不限于模拟对话,这档节目多次借鉴图灵测试的思想,通过人机对比来检验人工智能技术的发展。
更为通用的人工智能应用出现在2022年底,当OpenAI推出ChatGPT,人们第一次可以公测一款只需用文字提出要求就能收到有模有样的回复的应用。经过几年的发展,如今国内外多款大模型已经成为很多人日常不可或缺的工具,使用频次甚至超越搜索引擎。电视节目《2025中国·AI盛典》上人机辩论通过图灵测试的新闻并未引起轰动,也体现出人们对于大模型能力的习以为常。该节目播出了国产大模型MiniMax与人类辩手陈铭(2010年国际大学群英辩论会冠军)围绕“是否应按下删除痛苦记忆的按钮”展开辩论的视频,正反方都使用陈铭的形象并经过人工智能技术统一处理,消除了从人像本身识别出哪一位是真人的可能。现场观众在观看完辩论后,需要在正方和反方中判断出哪方为人类,结果有42%的人错指认人工智能为人。其实,这样的设置与图灵测试的标准不同,并非在不同议题上经多次辩论后观察员在超30%的问题上做出了错误的判断。
当下,似乎到了应该重新思考图灵测试有效性的时候。
首先,由于人工智能在对话领域的长足发展,我们需要考虑图灵当年还未看到的可能性。比如在文字之外,还有声音、视觉、运动等多种能力都体现了人类的智能。人工智能能否像人一样看懂电影?不仅仅是去描述一个片段,而是可以理解其中人物的名字、个性、关系、动机和悬念等。
其次,因为数字人和视频生成技术的进步,人工智能可以驱动人的形象,但目前这些形象往往缺乏对周围环境和交互对象的真实反应。这很像早期游戏中的NPC(非玩家角色)——即使酒馆里的主角们开始打斗,他们还是在安静地喝酒。能否让人工智能驱动的形象不再是木讷的NPC,而是有灵动的眼神,对周遭有合理的反应,并能与人类舒服地交互?
此外,生成式AI的发展让人工智能不仅可以模拟人类,还可以模拟世界。有声视频生成效果的惊艳,让DeepMind的首席执行官、因AlphaFold获得2024年诺贝尔化学奖的戴密斯·哈萨比斯(Demis Hassabis)改变了看法——“曾经以为需要在世界中行动才能理解直观物理这类事物,但现在看来,仅仅通过被动观察似乎也能实现理解”。他在诺贝尔奖演讲中提出一个猜想,即任何经由自然演化而形成的稳定结构,其模式都可以被人工智能高效地再发现。如果是这样,人工智能的未来会远超图灵的设想,科学家们的野心不仅仅是模拟造人的智能,还有模拟造物的智能。
本期专题将介绍我们团队在人工智能领域的几项最新研究成果,它们对应着超出原有图灵测试范围的三个方向:多模态理解、多模态交互和多模态生成。这里的“多模态”是指文字、视觉、听觉、味觉、触觉、运动等多种类型的数据。
多模态理解:从语言到多感官
人工智能早已不满足于模拟人的语言能力,而是希望模拟具有多种感官的人类。2021年初,OpenAI发布的CLIP模型与国内发布的“悟道·文澜”模型不约而同地使用了互联网上海量的成对数据来对齐文字与图像的语义,于是“小猫”与小猫的图片经过编码后,可以获得相近的表达,打破了视觉与自然语言之间的壁垒。很快,声音也有了与文字语义对齐的模型。各种模态的数据通过模态相关的处理,输入模态对齐的编码器,再统一接入Transformer架构来学习,让一切变得简单通用。视觉、图形学、语音与自然语言处理联通起来,加之计算机领域良好的共享文化,让研究者能很容易上手开展多模态相关的课题,越来越多的人发表了跨界的成果。
2022年6月,“悟道·文澜”团队论文“Towards Artificial General Intelligence via a Multimodal Foundation Model”登上Nature子刊《自然·通讯》,图为其团队所开发的BriVL(Bridging-Vision-and-Language)对自然、时间、科学、梦境这些抽象化单词的输出结果。图片来自Fei,N.,Lu,Z.,Gao,Y.et al.Towards artificial general intelligence via a multimodal foundation model.Nat Commun 13,3094(2022).
奇妙的是,越来越多的研究证明,人类在很多方面表现得卓尔不群是因为拥有多模态理解能力。本期专题中的《看得见、听得清:BPO-AVASR如何重构语音识别的感知方式》一文就指出,环境噪声、口语表达和同音歧义会造成人们对语音的误解。例如,在一个视频中,主播在做饭时说“放一点Kissan”,如果只是听,我会因为不知道Kissan是什么而无法理解这句话,但如果我看着视频,就会发现主播拿起一瓶番茄酱,瓶子上有Kissan的字样,于是我瞬间就理解了主播想说的是“放一点Kissan牌番茄酱”。
多模态交互:从头脑到身体
如果说类似ChatGPT的大模型是在模拟人的头脑,数字人和机器人的研究则旨在模拟人的身体。机器人可以按照事先编排好的动作跳舞,可以在公路上跑马拉松,但他们在面对人的时候仍然无法自然地互动。比如,和机器人初次见面,你伸出手去,它不会像人那样领会到要握手。本期专题中的《击掌还是握手?机器人如何预判你的动作》一文就提出一个新问题:机器人如何根据一个人的动作输入生成反应动作?我们提出了一个名为Think-Then-React(“先想想,再反应”)的模型作为解决方案,该模型既能理解语言和用语音进行推理,又能描述动作或者根据描述生成动作。在不同的时刻,模型会先观察人的动作,描述对方微微抬起右手,然后推理出对方可能是想握手,那么机器人也应该伸出右手,最后将之转换成动作去执行。于是,机器人不再是呆头呆脑的NPC,而是有了自然的反应,和人交互起来更加舒服。
比起实体机器人,数字人有着漂亮的外形、更像人,然而看起来总是眼神空洞,远远比不上人类。“眼睛是心灵的窗户”,科学家早就发现眼动是人的内在注意力的投射,并发明了测量眼动的仪器,来捕捉注视点及其变化的轨迹。在本期专题中,《听见眼神的方向:让AI的注视更像人类》聚焦如何让机器“像人一样”去听、去看、去“转动眼球”。想象一个场景:一个人和一个数字人(可能在手机里)坐在海边,人说:“对面小岛上方的那朵云好像一只点赞的手呀。”数字人的眼神是否可以自然地随着听到的话语而变化?这项课题耗时很久,在收集了人的眼动数据后,我们发现个体的差异很大,即便听到同一个词,人们看向的方位并不相同,如何度量注视点的轨迹是否像人?另一个困难在于眼球的转动要符合物理规律,这该如何刻画呢?
多模态生成:从造人到造世界
2025年5月21日,谷歌发布了第三代视频生成模型Veo 3,可以从文本生成有声视频。一经公测,网友们就用Veo 3玩出了很多花样。比如,生成野人的视频日志——野人像一位经验丰富的博主,用自拍的方式带大家去打猎、钓鱼,在丛林里边走边说,自然而真实。另一些用刀切各种材质的水果的视频也广为流传。比如,切一个不锈钢苹果或一颗玻璃草莓。视频中,当刀切下去时,不仅切口自然真实,还伴随着刀与不同材质摩擦的声音。生成视频有个奇特的地方,最初也许只是图像的自然延伸,可是一旦加入时间的维度,就不一样了。当生成的对象是不同物体的相互作用,物理学想要刻画的世界规律不就在其中吗?当镜头对准自然界的花花草草,生物生长的规律是否也在其中?当提示词描述世界各地的风土人情,其中是否也涵盖了地理学的研究对象?这样推演下去,电影行业模拟人物表情动作所使用的3D建模技术,是否也可以被视频生成技术取代?甚至人物的语言、自然界的音效和艺术家提炼创作的音乐都有可能囊括其中。这就是大家津津乐道的世界模型。
在本期专题的《让图像“动”起来的AI魔法》一文中,我们介绍了一项新工作:如何从一张图片生成一段有声的视频。比如,根据一张公鸡的照片,是否可以生成它打鸣的体态和声音?使用以往的技术,我们可以从图片分别生成视频和声音,或者先生成视频再配音,然而这些方案不仅无法得出同步的画面与声音,甚至无法让视频中的公鸡完成打鸣的动作。因此我们提出了一个联合生成的方法,让视频与声音在生成的过程中互相参考对方的状态,比如如果打鸣的声音已经开始,视频就会相应地生成公鸡打鸣的动作。希望这篇文章可以为大家了解Veo 3的原理提供线索。
以上只是我们团队的多模态人工智能研究最新进展的一些切面,这个领域正在肆意生长,模拟人类和世界是为它设置的远大目标,还有非常广阔的空间等待着被探索。这些也许都是图灵不曾预料的,但我想他一定也很欣慰吧——人工智能的进化终于迎来了挑战和突破图灵测试的一天。
(原载于《信睿周报》第157期)