2013-05-28 10:29

天下武功,唯快不破。这句话滥觞于《拳经》,经过雷军等人的演绎,几乎成了互联网时代商业致胜的不二法则。那么,大数据的快又从何说起呢?
话说道哥(Doug Laney)当年创立三V经,背景是电子商务:Velocity衡量的是用户“交互点”(Point-of-Interaction),如网站响应速度、订单完成速度、产品和服务的交付速度等。假设交互点是一个黑盒子,一边吸入数据,经过黑盒子处理后,在另一边流出价值,那Velocity指的是吸入、处理和产生价值的快速度。随后“快”进入了企业运营、管理和决策智能化的每一个环节,于是大家看到了形形色色描述“快”的文字用在商业数据语境里,例如real-time(实时),lightning fast(快如闪电的),speed of light(光速),speed of thought(念动的瞬间),Time to Value(价值送达时间),等等。
本篇试图讨论“快”的四个问题:
* 为什么要“快”?
* “快”的数据和处理模型
* 怎么实现“快”?
* “快”的代价是什么?
为什么要“快”?
“快”,来自几个朴素的思想:
1)时间就是金钱。时间在分母上,越小,单位价值就越大。面临同样大的数据矿山,“挖矿”效率是竞争优势。Zara与H&M有相似的大数据供应,Zara胜出的原因毫无疑问就是“快”。
2)像其它商品一样,数据的价值会折旧。过去一天的数据,比过去一个月的数据可能都更有价值。更普遍意义上,它就是时间成本的问题:等量数据在不同时间点上价值不等。NewSQL的先行者VoltDB发明了一个概念叫做Data Continuum:数据存在于一个连续时间轴(time continuum)上,每一个数据项都有它的年龄,不同年龄的数据有不同的价值取向,“年轻”(最近)时关注个体的价值,“年长”(久远)时着重集合价值。
3)数据跟新闻和金融行情一样,具有时效性。炒股软件免费版给你的数据有十几秒的延迟,这十几秒是快速猎食者宰割散户的机会;而华尔街大量的机构使用高频机器交易(70%的成交量来自高频交易),能发现微秒级交易机会的吃定毫秒级的。物联网这块,很多传感器的数据,产生几秒之后就失去意义了。美国国家海洋和大气管理局的超级计算机能够在日本地震后9分钟计算出海啸的可能性,但9分钟的延迟对于瞬间被海浪吞噬的生命来说还是太长了。
大家知道,购物篮分析是沃尔玛横行天下的绝技,其中最经典的就是关联产品分析:从大家耳熟能详的“啤酒加尿布”,到飓风来临时的“馅饼(pop-tarts)加手电筒”和“馅饼加啤酒”。可是,此“购物篮”并非顾客拎着找货的那个,而是指你买完帐单上的物品集合。对于快消品等有定期消费规律的产品来说,这种“购物篮”分析尚且有效,但对绝大多数商品来说,找到顾客“触点(touch points)”的最佳时机并非在结帐以后,而是在顾客还领着篮子扫街逛店的正当时。电子商务具备了这个能力,从点击流(clickstream)、浏览历史和行为(如放入购物车)中实时发现顾客的即时购买意图和兴趣。这就是“快”的价值。那传统零售业是不是只能盯着购物清单和顾客远去的背影望“快”兴叹了呢?也不见得,我有空时会写一篇小文“O4O:Online for Offline”专门写传统零售业怎么部署数据实时采集和分析技术突破困局。
“快”的数据和处理模型
设想我们站在某个时间点上,背后是静静躺着的老数据,面前是排山倒海扑面而来的新数据。前文讲过,数据在爆炸性产生。在令人窒息的数据海啸面前,我们的数据存储系统如同一个小型水库,而数据处理系统则可以看作是水处理系统。数据涌入这个水库,如果不能很快处理,只能原封不动地排出。对于数据拥有者来说,除了付出了存储设备的成本,没有收获任何价值。
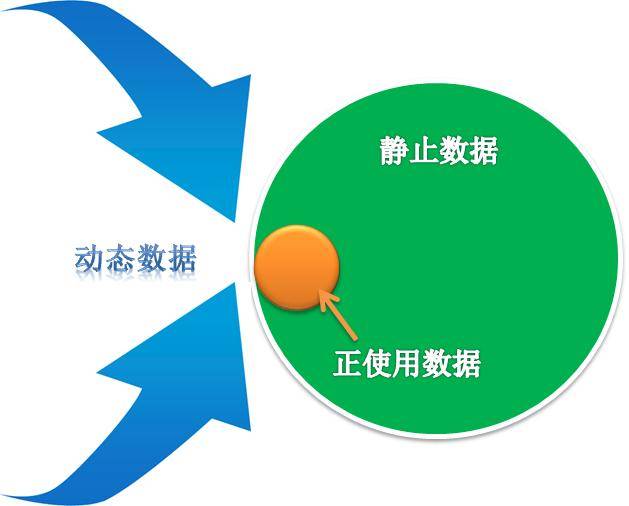
如上图所示,按照数据的三状态定义,水库里一平如镜(非活跃)的水是“静止数据(data at rest)”,水处理系统中上下翻动的水是“正使用数据(data inuse)”,汹涌而来的新水流就是“动态数据(data in motion)”。
“快”说的是两个层面:
一个是“动态数据”来得快。动态数据有不同的产生模式。有的是burst模式,极端的例子如欧洲核子研究中心(CERN)的大型强子对撞机(Large Hadron Collider,简称LHC),此机不撞则已,一撞惊人,工作状态下每秒产生PB级的数据。也有的动态数据是涓涓细流的模式,典型的如clickstream,日志,RFID数据,GPS位置信息,Twitter的firehose流数据等。
二是对“正使用数据”处理得快。水处理系统可以从水库调出水来进行处理(“静止数据”转变为“正使用数据”),也可以直接对涌进来的新水流处理(“动态数据”转变为“正使用数据”)。这对应着两种大相迥异的处理范式:批处理和流处理。
如下图所示,左半部是批处理:以“静止数据”为出发点,数据是任尔东西南北风、我自岿然不动,处理逻辑进来,算完后价值出去。Hadoop就是典型的批处理范式:HDFS存放已经沉淀下来的数据,MapReduce的作业调度系统把处理逻辑送到每个节点进行计算。这非常合理,因为搬动数据比发送代码更昂贵。
右半部则是流数据处理范式。这次不动的是逻辑,“动态数据”进来,计算完后价值留下,原始数据加入“静止数据”,或索性丢弃。流处理品类繁多,包括传统的消息队列(绝大多数的名字以MQ结尾),事件流处理(Event Stream Processing)/复杂事件处理(Complex Event Processing或CEP)(如Tibco的BusinessEvents和IBM的InfoStreams),分布式发布/订阅系统(如Kafka),专注于日志处理的(如Scribe和Flume),通用流处理系统(如Storm和S4)等。

这两种范式与我们日常生活中的两种信息处理习惯相似:有些人习惯先把信息存下来(如书签、To Do列表、邮箱里的未读邮件),稍后一次性地处理掉(也有可能越积越多,旧的信息可能永远不会处理了);有些人喜欢任务来一件做一件,信息来一点处理一点,有的直接过滤掉,有的存起来。
没有定规说哪种范式更好,对于burst数据,多数是先进入存储系统,然后再来处理,因此以批处理范式为主;而对于流数据,多采用流范式。传统上认为流处理的方式更快,但流范式能处理的数据常常局限于最近的一个数据窗口,只能获得实时智能(real-time intelligence),不能实现全时智能(all-timeintelligence)。批处理擅长全时智能,但翻江倒海捣腾数据肯定慢,所以亟需把批处理加速。
两种范式常常组合使用,而且形成了一些定式:
* 流处理作为批处理的前端:比如前面大型强子对撞机的例子,每秒PB级的数据先经过流处理范式进行过滤,只有那些科学家感兴趣的撞击数据保留下来进入存储系统,留待批处理范式处理。这样,欧洲核子研究中心每年的新增存储存储量可以减到25PB。
* 流处理与批处理肩并肩:流处理负责动态数据和实时智能,批处理负责静止数据和历史智能,实时智能和历史智能合并成为全时智能。
怎么实现“快”?
涉及到实现,这是个技术话题,不喜可略。
首先,“快”是个相对的概念,可以是实时,也可以秒级、分钟级、小时级、天级甚至更长的延迟。实现不同级别的“快”采用的架构和付出的代价也不一样。所以对于每一个面临“快”问题的决策者和架构师来说,第一件事情就是要搞清楚究竟要多“快”。“快”无止境,找到足够“快”的那个点,那就够了。
其次,考虑目前的架构是不是有潜力改造到足够“快”。很多企业传统的关系型数据库中数据量到达TB级别,就慢如蜗牛了。在转向新的架构(如NoSQL数据库)之前,可以先考虑分库分表(sharding)和内存缓存服务器(如memcached)等方式延长现有架构的生命。
如果预测未来数据的增长必将超出现有架构的上限,那就要规划新的架构了。这里不可避免要选择流处理结构,还是批处理结构,抑或两者兼具。Intel有一位老法师说:any big data platform needs tobe architected for particular problems(任何一个大数据平台都需要为特定的问题度身定做)。在下不能同意更多。为什么呢?比如说大方向决定了要用流处理架构,我们前面列举了很多品类,落实到具体产品少说上百种,所以要选择最适合的流处理产品。再看批处理架构,MapReduce也不能包打天下,碰到多迭代、交互式计算就无能为力了;NoSQL更是枝繁叶茂,有名有姓的NoSQL数据库好几十种。这时候请一个好的大数据咨询师很重要(这也是我在这里说大数据咨询服务有前景的原因)。
总体上讲,还是有一些通用的技术思路来实现“快”:
1)如果数据流入量太大,在前端就地采用流处理进行即时处理、过滤掉非重要数据。前段时间王坚把大数据和无人机扯一块,这无人机还真有个流处理的前端。它以每秒几帧的速度处理视频,实时匹配特殊形状(如坦克)和金属反光(武器),同时把处理过的无用视频帧几乎全扔了。
2) 把数据预处理成适于快速分析的格式。预处理常常比较耗时,但对不常改动的惰性数据,预处理的代价在长期的使用中可以忽略不计。谷歌的Dremel,就是把只读的嵌套数据转成类似于列式数据库的形式,实现了PB级数据的秒级查询。
3)增量计算--也即先顾眼前的新数据,再去更新老数据。对传统的批处理老外叫做reboil the ocean,每次计算都要翻江倒海把所有数据都捣腾一遍,自然快不了。而增量计算把当前重点放在新数据上,先满足“快”;同时抽空把新数据(或新数据里提炼出来的信息)更新到老数据(或历史信息库)中,又能满足“全”。谷歌的Web索引自2010年起从老的MapReduce批量系统升级成新的增量索引系统,能够极大地缩短网页被爬虫爬到和被搜索到之间的延迟。我们前面说的“流处理和批处理肩并肩”也是一种增量计算。
4)很多批处理系统慢的根源是磁盘和I/O,把原始数据和中间数据放在内存里,一定能极大地提升速度。这就是内存计算(In-memory computing)。内存计算最简单的形式是内存缓存,Facebook超过80%的活跃数据就在memcached里。比较复杂的有内存数据库和数据分析平台,如SAP的HANA,NewSQL的代表VoltDB和伯克利的开源内存计算框架Spark(Intel也开始参与)。斯坦福的John Ousterhout(Tcl/Tk以及集群文件系统Lustre的发明者)搞了个更超前的RAMCloud,号称所有数据只生活在内存里。未来新的非易失性内存(断电数据不会丢失)会是个game changer。Facebook在3月宣布了闪存版的Memcached,叫McDipper,比起单节点容量可以提升20倍,而吞吐量仍能达到每秒数万次操作。另一种非易失性内存,相变内存(Phase Change Memory),在几年内会商用,它的每比特成本可以是DRAM的1/10,性能比DRAM仅慢2-10倍,比现今的闪存(NAND)快500倍,寿命长100倍。
除内存计算外,还有其它的硬件手段来加速计算、存储和数据通讯,如FPGA(IBM的Netezza和Convey的Hybrid-Core),SSD和闪存卡(SAP HANA和Fusion IO),压缩PCIe卡,更快和可配置的互联(Infiniband的RDMA和SeaMicro SM15000的Freedom Fabrics)等。此处不再细表。
5)降低对精确性的要求。大体量、精确性和快不可兼得,顶多取其二。如果要在大体量数据上实现“快”,必然要适度地降低精确性。对数据进行采样后再计算就是一种办法,伯克利BlinkDB通过独特的采用优化技术实现了比Hive快百倍的速度,同时能把误差控制在2-10%。
“快”的代价是什么?
这世界上没有免费的午餐,实现了“快”必然要付出代价。要么做加法,增加硬件投入、改变架构设计;要么做减法,降低精确性、忍受实时但非全时的智能。其实,这个好比看报纸,时报、日报信息快,需要采编投入,但因为短时间内所能获得信息的局限性,缺乏深度和全景式的文章;周报、月刊则反之。
“快”很贵。有些行业,肯定是越快越好的,比如说金融领域,所以他们愿意买贵得离谱的SAP HANA或IBM Netezza。对绝大多数企业来说,需要精打细算。关键还是,对每一个问题,仔细调研清楚“足够快”的定义。心里有底,做事不慌。
“快”容易错。丹尼尔·卡尼曼在《思考,快与慢》中讲到快思考容易上当,在那一瞬间,“眼见为实”、厌恶损失和持乐观偏见等习惯常常引导我们作出错误的选择。基于“快”数据的分析同样会有这样的问题,可能是数据集不够大导致了统计偏差,或是因为“快”而牺牲了精确性。
再进一步,“快”出错了常常“覆水难收”。Wolters Kluwer的一个高级分析师Marcia Richards Suelzer说:“我们现在可以在几纳秒内作出灾难性的错误计算,随即将其广播到世界的各个角落。我们不再具有计算延迟带来的缓冲性”。技术带来了分析的快速性和全球的连接性,同时也把我们创造破坏的能力放大了。美国新闻向来是求“快”,彭博社误报“中国经济刺激计划”导致全球股市大涨,至少结果还不错,CNN在2008年误报乔布斯有心脏病导致苹果股价大跌就不那么美好了(彭博社还在同年误报乔布斯的死讯)。
简单地总结,Variety和Velocity是Volume的左右护法,它们修正和充实了“大”的内涵。Velocity带来了诸般好处,也需要付出代价。下一篇讲Veracity 鱼龙混杂、真假难辨。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
频道: 金融财经