




2023-09-04 11:25

扫码打开虎嗅APP


本文来自微信公众号:硅基研习社 (ID:gh_8448ad119f2e),作者:王一川,编辑:戴老板,头图来自:视觉中国
2023年8月3日,华尔街和硅谷联袂奉上了一件震撼业界的大事:让一家创业公司拿到23亿美元的债务融资,抵押物则是当前全球最硬的通货——H100显卡。
这个大事件的主角叫做CoreWeave,主营业务是AI私有云服务,简单说就是通过搭建拥有大量GPU算力的数据中心,来给AI创业公司和大型商业客户提供算力基础设施。CoreWeave累计融资5.8亿美金,目前是B轮,估值20亿美元。
CoreWeave成立于2016年,创始人是三个华尔街大宗商品交易员。刚开始公司的主营业务只有一个:挖矿,采购大量GPU来组建矿机中心,尤其是在币圈低潮时,公司会逆周期囤大量显卡,也因此跟英伟达建立了铁杆的革命友谊。

CoreWeave三位联合创始人 图片来自:CoreWeave
2019年,CoreWeave开始把这些矿机改造成企业级数据中心,向客户提供AI云服务,刚开始的生意也不温不火,但ChatGPT诞生之后,大模型的训练和推理每天都在消耗大量算力,已经拥有数万张显卡(当然未必是最新型号)的CoreWeave嗖的一下起飞,门口挤满了客户和风投。
但令人感到蹊跷的是:CoreWeave累计一共只融到了5.8亿美金,账面GPU的净值不会超过10亿美元,甚至公司整体估值也只有20亿美元,但为何却能通过抵押借到23亿美元呢?一向精于算计、热衷对抵押物价值膝盖斩的华尔街,为何如此慷慨呢?
原因极有可能是:CoreWeave虽然账上还没这么多显卡,但它拿到了英伟达的供货承诺,尤其是H100。
CoreWeave跟英伟达的铁杆关系已经是硅谷公开的秘密。这种铁杆根源于CoreWeave对英伟达的毫无二心的忠诚和支持——只用英伟达的卡、坚决不自己造芯、显卡卖不动时帮英伟达囤卡。对黄仁勋来说,这种关系的含金量,远超跟微软、Google和特斯拉的那些塑料友情。
因此,尽管英伟达H100十分紧缺,英伟达还是把大量新卡分配给了CoreWeave,甚至不惜限制对亚马逊和谷歌等大厂的供应。黄仁勋在电话会议里夸赞:“一批新的GPU云服务提供商会崛起,其中最著名的是 CoreWeave,他们做得非常好。”
而在喜提23亿美金的一周前,CoreWeave就已对外宣称,将耗资16亿美元在德州建立一个占地面积42,000 平方米的数据中心。仅凭借跟英伟达之间的关系和优先配货权,CoreWeave就可以把建数据中心的钱从银行里借出来——这种模式,让人想起了拿地后立马找银行贷款的地产商。
所以可以这样说:当下一份H100的供货承诺,堪比房地产黄金时代的一纸土地批文。
今年4月在接受采访时,马斯克抱怨道[2]:“现在似乎连狗都在买GPU。”
很讽刺的是,特斯拉早在2021年就发布了自研的D1芯片,由台积电代工,采用7nm工艺,号称能替代当时英伟达主流的A100。但2年过去了,英伟达推出了更为强大的H100,而特斯拉的D1没有后续迭代,因此当马斯克试图组建自家的人工智能公司时,还是得乖乖地跪在黄老爷门前求卡。
H100在去年9月20日正式推出,由台积电4N工艺代工。相较于前任A100,H100单卡在推理速度上提升3.5倍,在训练速度上提升2.3倍;如果用服务器集群运算的方式,训练速度更是能提高到9倍,原本一个星期的工作量,现在只需要20个小时。
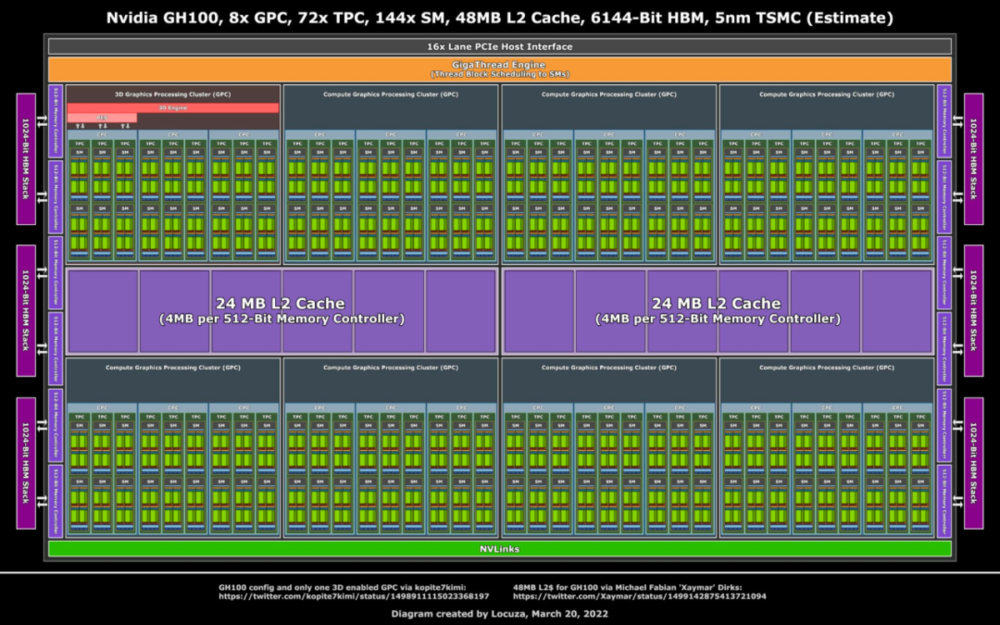
GH100 架构图
相比A100,H100的单卡价格更贵,大约是A100的1.5~2倍左右,但训练大模型的效率却提升了200%,这样折算下来的“单美元性能”更高。如果搭配英伟达最新的高速连接系统方案,每美元的GPU性能可能要高出 4-5 倍,因此受到客户疯狂追捧。
抢购H100的客户,主要分成三类:
第一类是综合型云计算巨头,比如微软Azure、谷歌GCP和亚马逊AWS这样的云计算巨头。他们的特点是财大气粗,动辄就想“包圆”英伟达的产能,但每家也都藏着小心思,对英伟达的近垄断地位感到不满,暗地里自己研发芯片来降低成本。
第二类是独立的云GPU服务商,典型公司如前文提到的CoreWeave,以及Lambda、RunPod等。这类公司算力规模相对较小,但能够提供差异化的服务,而英伟达对这类公司也是大力扶持,甚至直接出钱投资了CoreWeave和Lambda,目的很明确:给那些私自造芯的巨头们上眼药。
第三类是自己在训练LLM(大语言模型)的大小公司。既包括Anthropic、Inflection、Midjourney这种初创公司,也有像苹果、特斯拉、Meta这样的科技巨头。它们通常一边使用外部云服务商的算力,一边自己采购GPU来自建炉灶——有钱的多买,没钱的少买,主打一个丰俭由人。
在这三类客户中,微软Azure至少有5万张H100,谷歌手上大概有3万张,Oracle大概有2万张,而特斯拉和亚马逊手上也拿有1万张左右,CoreWeave据称有3.5万张的额度承诺(实际到货大概1万)。其他的公司很少有超过1万张的。
这三类客户总共需要多少张H100呢?根据海外机构GPU Utils的预测,H100当前需求大概43.2万张。其中OpenAI需要5万张来训练GPT-5,Inflection需求2.2万张,Meta则是2.5万张(也有说法是10万张),四大公有云厂商每家都需要至少3万张,私有云行业则是10万张,而其他的小模型厂商也有10万张的需求[3]。
英伟达2023年的H100出货量大概在50万张,目前台积电的产能仍在爬坡,到年底H100一卡难求的困境便会缓解。
但长期来看,H100的供需缺口会随着AIGC的应用爆发而继续水涨船高。根据金融时报的报道,2024年H100的出货量将高达150万张~200万张,相比于今年的50万张,提升3~4倍[4]。
而华尔街的预测则更为激进:美国投行Piper Sandler认为明年英伟达在数据中心上的营收将超过600亿美元(FY24Q2:103.2亿美元),按这个数据倒推,A+H卡的出货量接近300万张。
还有更夸张的估计。某H100服务器最大的代工厂(市占率70%~80%),从今年6月开始就陆续出货了H100的服务器,7月份产能陆续爬坡。一份最近的调研显示,这家代工厂认为2024年A+H卡的出货量会在450万张~500万张之间。
这对英伟达意味着“泼天的富贵”,因为H100的暴利程度,是其他行业人难以想象的。
为了搞清H100有多暴利,我们不妨把它的物料成本(Bill of Materials, BOM)彻底拆解出来。
如图所示,H100最通用的版本H100 SXM采用的是台积电CoWoS的7晶粒封装,6颗16G的HBM3芯片分列两排紧紧围绕着中间的逻辑芯片。
而这也构成了H100最重要的三个部分:逻辑芯片、HBM存储芯片、CoWoS封装,除此之外,还有诸如PCB板以及其他的一些辅助器件,但价值量不高。

H100拆机图
核心的逻辑芯片尺寸是814mm^2,产自台积电最先进的台南18号工厂,使用的工艺节点则是“4N”,虽然名字上是4打头,但实际上是5nm+。由于5nm的下游,手机等领域的景气度不佳,因此台积电在保供逻辑芯片上没有任何问题。
而这块逻辑芯片是由12寸(面积70,695mm^2)的晶圆切割产生,理想状态下可以切出86块,但考虑到“4N”线80%的良率以及切割损耗,最后一张12寸晶圆只能切出65块的核心逻辑芯片。
这一块核心逻辑芯片的成本是多少呢?台积电2023年一片12寸的晶圆对外报价是13400美元,所以折算下来单块大概在200美元。
接下来是6颗HBM3芯片,目前由SK海力士独供,这家起源于现代电子的企业,2002年几乎要委身与美光,凭借着政府的输血以及逆周期上产能的战略,如今在HBM的量产技术上至少领先美光3年(美光卡在HBM2e,海力士2020年中期量产)。
HBM的具体价格,各家都讳莫如深,但根据韩媒的说法,HBM目前是现有DRAM产品的5-6倍。而现有的GDDR6 VRAM的价格大概是每GB 3美元,如此推算HBM的价格是在每GB 15美元左右。那一张H100 SXM在HBM上的花费就是1500美元。
虽然今年HBM的价格不断上涨,英伟达、Meta的高管也亲赴海力士“督工”,可下半年三星的HBM3就能逐步量产出货,再加上韩国双雄祖传的扩张血脉,想必到了明年HBM就不再是瓶颈。
而真正是瓶颈的则是台积电的CoWoS封装,这是一种2.5D的封装工艺。相比于直接在芯片上打孔(TSV)、布线(RDL)的3D封装,CoWoS可以提供更好的成本、散热以及吞吐带宽,前两者对应HBM,后两者则是GPU的关键。
所以想要高存力、高算力的芯片,CoWoS就是封装上的唯一解。英伟达、AMD两家的四款GPU都用上了CoWoS就是最好的佐证。
CoWoS的成本是多少呢?台积电2022年财报披露了CoWoS工艺占总营收7%,于是海外分析师Robert Castellano根据产能,以及裸晶的尺寸推算出封装一块AI芯片能给台积电带来723美元的营收[6]。
因此把上述最大的三块成本项加总,合计在2500美元左右,其中台积电占了$1000(逻辑芯片+CoWoS)左右,SK海力士占了1500美金(未来三星肯定会染指),再算上PCB等其他材料,整体物料成本不超过3000美金。
那H100卖多少钱呢?35000美金,直接加了一个零,毛利率超过90%。过去10年英伟达毛利率大概在60%,现在受高毛利的A100/A800/H100的拉动,今年Q2英伟达的毛利率已经站上了70%。
这有点反常识:英伟达严重依赖台积电的代工,后者地位无人撼动,甚至是唯一能卡英伟达脖子的核心环节。但这么一块3.5万美金的卡,制造它的台积电只能拿1000美金,而且只是收入,不是利润。
不过,用毛利率来定义暴利,对于芯片公司意义不大,要是从沙子开始算,那毛利率更高。一张4N工艺的12寸晶圆,台积电卖给谁都差不多是1.5万美金一片,英伟达能加个零卖给客户,自然有其诀窍。
这个诀窍的秘密在于:英伟达本质上,是一个伪装成硬件厂商的软件公司。
英伟达最强大的武器,就藏在毛利率减去净利率的那一部分。
在本轮AI热潮之前,英伟达的毛利率常年维持在65%上下,而净利率通常只有30%。而今年Q2受高毛利的A100/A800/H100的拉动,毛利率站上70%,净利率更是高达45.81%。
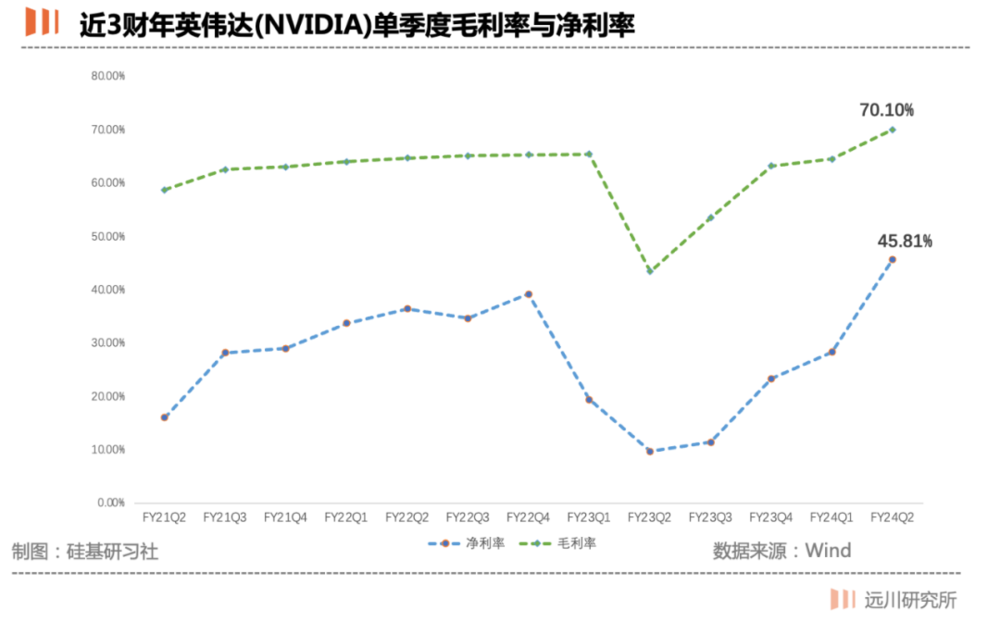
近 3 财年英伟达(NVIDIA)单季度毛利率与净利率
英伟达目前在全球有超过2万名员工,大都是高薪的软硬件工程师,而根据美国猎聘Glassdoor的数据,这些岗位的平均年薪基本都高于20万美元/年。

近十个财年英伟达研发费用率
在过去的十年里,英伟达研发支出的绝对值保持着高速增长,而研发费用率稳态下也维持在20%以上。当然,如果某一年的终端需求爆发,比如2017年的深度学习、2021年的挖矿,以及今年的大语言模型,营收的分母骤然抬升,研发费用率就会短暂地跌到20%,相应地利润也会非线性暴增。
而在英伟达研发的这么多项目中最关键的无疑是CUDA。
2003年为解决DirectX编程门槛过高的问题,Ian Buck的团队推出了一款名为Brook的编程模型,这也是后来人们常说的CUDA的雏形。2006年Buck加入英伟达,并说服黄仁勋研发CUDA[8]。
因为支持C语言环境下的并行计算,使得CUDA一跃成为工程师的首选,也让GPU走上了通用处理器(GPGPU)的道路。
在CUDA逐渐成熟之后,Buck再次劝说黄仁勋,让英伟达未来所有的GPU都必须支持CUDA。2006年CUDA立项,2007年推出产品,当时英伟达的年营收仅有30亿美元,却在CUDA上花费5亿美金,到了2017年时,单在CUDA上的研发支出就已超过了百亿。
曾经有位私有云公司的CEO在接受采访时说过,他们也不是没想过转去买AMD的卡,但要把这些卡调试到正常运转至少需要两个月的时间[3]。而为了缩短这两个月,英伟达投入上百亿走了20年。
芯片行业浮沉大半个世纪,从来没有一家企业像英伟达一样,既卖硬件、也卖生态,或者按黄仁勋的话来说:“卖的是准系统”。因此,英伟达对标的也的确不是芯片领域的那些先贤们,而是苹果——另一家卖系统的公司。
从2007年推出CUDA,到成为全球最大的印钞厂,英伟达也并不是没有过对手。
2008年当时芯片届王者英特尔中断了与英伟达在集显项目上的合作,推出自己的通用处理器(GPCPU),打算在PC 领域“划江而治”。可英伟达在随后几年的产品迭代中,硬是把自家处理器推广到太空、金融、生物医疗等需要更强大计算能力的领域,于是2010年英特尔眼看打压无望,被迫取消了独立显卡计划。
2009年苹果的开发团队推出了OpenCL,希望能凭借着通用性在CUDA身上分一杯羹。但OpenCL在深度学习的生态上远不如CUDA,许多学习框架要么是在CUDA发布之后,才会去支持OpenCL,要么压根不支持OpenCL。于是在深度学习上的掉队,使得OpenCL始终无法触及更高附加值的业务。
2015年AlphaGo开始在围棋领域初露锋芒,宣告人工智能的时代已经来临。此时的英特尔为了赶上这最后一班车,把AMD的GPU装入自己的系统芯片内。这可是两家公司自上世纪80年代以来的首次合作。可如今CPU老大、老二+GPU老二的市值之和仅是GPU老大英伟达的1/4。
从目前看来,英伟达的护城河几乎是牢不可摧。即使有不少大客户笑里藏刀,私下里在研发自己的GPU,但凭借着庞大的生态和快速的迭代,这些大客户也无法撬动帝国的裂缝,特斯拉就是明证。英伟达的印钞机生意,在可见的未来还会持续。
可能唯一让黄仁勋萦绕乌云的地方,便是那个客户众多、需求旺盛但H100卖不进去、但人家又在咬牙攻坚的地方——这个地方全世界只有一个。
参考资料
[1] Crunchbase
[2] 'Everyone and Their Dog is Buying GPUs,' Musk Says as AI Startup Details Emerge-tom's HARDWARE
[3] Nvidia H100 GPUs: Supply and Demand-GPU Utils
[4] Supply chain shortages delay tech sector’s AI bonanza,FT
[5] AI Capacity Constraints - CoWoS and HBM Supply Chain-DYLAN PATEL, MYRON XIE, AND GERALD WONG,Semianalysis
[6] Taiwan Semiconductor: Significantly Undervalued As Chip And Package Supplier To Nvidia-Robert Castellano,Seeking Alpha
[7] 芯片战争,余盛
[8] What is CUDA? Parallel programming for GPUs-Martin Heller,InfoWorld
[9] NVIDIA DGX H100 User Guide
本文来自微信公众号:硅基研习社 (ID:gh_8448ad119f2e),作者:王一川,编辑:戴老板,视觉设计:疏睿,责任编辑:陈畅

