2017-12-08 15:55

虎嗅注:我们都知道,许多以讹传讹,引起过舆论轰动的假照片都是PS过的,不光看起来非常不真实,而且经过一些技术手段是可以检测的。但是如果AI介入到图像、视频造假当中呢?如果逼真到检测设备都无法分辨,那被混淆视听的我们又该如何分辨真假?
本文转载自公众号“DeepTech深科技”(ID:mit-tr),作者:詹子娴,原文标题《一项AI革命性技术将“造假”推向极致,连发明人也表示了深度担忧! 独家解读GAN如何“批量制造现实”》。
当网络上出现一则美国总统特朗普与朝鲜领导人金正恩把酒言欢的偷拍视频,你会觉得是真还是假?
一直以来,人类想要判断事件真假、是非对错,常常会说“眼见为凭”、“有图有真相”,但这些准则很有可能即将失灵,因为一项被誉为近十年来机器学习领域最有趣的突破——生成式对抗网络(GAN,Generative Adversarial Networks),很有可能因为误用而扰乱我们的认知。
Google Brain 研究科学家 Ian Goodfellow 上个月在《麻省理工科技评论》举办的 EmTech 大会上警告:“未来我们可能会不得不退回到 100 年前阅读新闻的方式”。他也是生成式对抗网络的发明人,并因为发明 GAN 这项革命性技术而被评为本年度《麻省理工科技评论》35 岁以下 35 名科技创新先锋之一。

11月,EmTech 大会上 Ian Goodfellow 的一番言论让人印象深刻
过去,我们可以将一段视频视为是某件事情发生的证据,但像 GAN 这样的人工智能技术出现之后,可以创造出更容易让人信以为真的假图片、假视频。“从历史的角度来看,我们依靠视频来证明事情真的发生过,这其实有点侥幸的意味。” 他承认,在未来,研究人员或俄罗斯特务将有可能创造出政客们说出各种言论的视频,这种情况将与GAN相关。“我们正在让可能发生的事情加速发生”。 
“未来面对新闻,我们只能更加小心,时时刻刻保持怀疑的态度。也许要习惯不相信你在网上看到的大多数影音或图像,就像回到 100 年前那个不通过照片、影像来传递信息的时代。”
身为 GAN 发明人的 Ian Goodfellow,说出这番话显得有些讽刺,GAN 可能对信息传播、舆论造成巨大影响、甚至是一种危机,恐怕这也是他始料未及的。 “在这种情况下,人工智能正在关上某些大门,而我们这一代早已习惯了这些大门处于敞开的状态。” 

利用GAN进行图片编辑
GAN 的精神:想变强,就要有神一般的对手
2014 年,Ian Goodfellow 还在蒙特利尔大学(Université de Montréal)念博士时,某日他在酒吧与朋友讨论该如何解决训练 AI 需要大量标注数据的问题,给了他开发出 GAN 的灵感。
想要建立一个神经网络学习识别人、猫、狗,方法就是把每张图像上的人、猫、狗仔细的标注(labeling)起来,再让系统分析这些成千上万张的照片,但如果没有做好标注,这些照片就无法用来训练网络,要不然就是训练出来的网络的识别力很差,因此发展深度学习往往需要大量的人力及时间。
GAN 能利用现有的数据来建立已经带有标注的图像,如此就能减少上述提及需要大量人力来标注数据的麻烦。因此,被人工智能先驱、Facebook 人工智能研究院(FAIR)院长 Yann LeCun 赞许是“机器学习最近 10 年来最有趣的想法”,NVIDIA 创始人黄仁勋口中的“一项突破性的发展”。

Facebook 人工智能研究院(FAIR)院长 Yann LeCun
GAN 独到之处在于同时训练两个网络,一个是生成网络(generator network),又称生成器(generator),另一个是判别网络(discriminator network),又称判别器(discriminator),而且让这两个网络相互对抗、彼此竞争却又互相学习。
生成器想的是骗过判别器,或是让判别器觉得它做的东西是好的,而判别器的任务就是去抓什么是真实的,什么是生成器做的。可以想象成是一个是罪犯,另一个是警察,互相斗智,谁也不让谁。而你想要变得超强,就是要有一个神一般的对手,就是 GAN 的核心精神。
在 GAN 的训练过程,会先有一个生成器 V1,产生影像,判别器 V1 看了这个影像之后,分辨究竟这是一个假的影像还是真实的,有了判别器 V1 的回馈后,生成器进化成 V2,再产生新的影像,如果成功骗过判别器 V1,判别器 V1 就会更新其参数,制造一个进化版的判别器 V2,但如果没有骗过判别器 V1,生成器 V2 就会更新其参数以生成更逼真的影像,继续诈欺判别器...... 此过程不断循环、更新,生成器或及判别器一代比一代厉害。
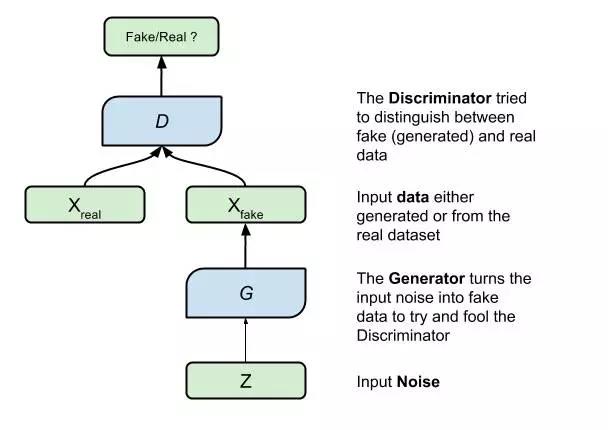
GAN 的示意图(图片来源:AWS 网站)
而 GAN 与另一项技术强化学习(RL,Reinforcement Learning),听起来有点异曲同工,不过,两者还是有所差异。GAN 有一个生成器、一个判别器。在强化学习里则是有一个 Agent,一个环境,两者会不断互动,环境会给 Agent 奖惩分数(reward),Agent 会不断更新参数,以争取环境给它的分数值越大越好。所以,Agent 的角色类似生成器,环境就象是判别器,但环境的参数是固定的,判别器的参数是会不断更新,这就是 RL 和 GAN 的最大差异。

台湾大学电机工程学系教授李宏毅
“GAN 做的事很像‘演化’”,专门研究 GAN 的台湾大学电机工程学系教授李宏毅道出重点,他解释,演化是突变跟自然选择的结果,例如眼睛是怎么产生的呢?复杂的器官并不会凭空出现,可能会先出现一个例如感光细胞的简单版本,通过很多步骤慢慢演变成眼睛,GAN 也是如此。刚开始 GAN 生成出来的东西可能不太好,但经过多次更新之后,就可能创造出非常逼真的东西。

台湾大学电机工程学系助理教授李宏毅示范用 GAN 制造动漫人物头像。此图为生成器更新 100 次的结果,时间大概不到 5 分钟(图片来源:李宏毅提供)

生成器更新 1000 次的结果(图片来源:李宏毅提供)

生成器更新 1 万次的结果,在这个阶段的图来看,机器抓出了动漫人物的特色:都有水汪汪的大眼以及蓬松的刘海(图片来源:李宏毅提供)

生成器更新 5 万次的结果,有些图可以做到以假乱真。当然还可以继续更新下去,效果就会更好(图片来源:李宏毅提供)
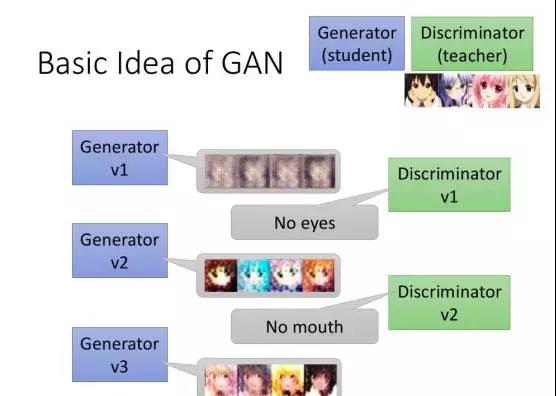
GAN 就是生成器与判别器相互对抗、彼此竞争(图片来源:李宏毅提供)

GAN 获得关注后发展出许多种类(图片来源:李宏毅提供)
李宏毅进一步指出:“GAN 有利于 AI 在结构学习(structured learning)研究的突破,当你今天想要机器输出的东西(output)是具有结构性,也就是由许多零件构成的,例如句子、音乐、图片,使用 GAN 会比其他技术得到更好的结果。”
比恐怖谷还恐怖?
专以程序、 AI 进行艺术创作的德国艺术家 Mario Klingemann 在 YouTube 上发了一段名为“替代脸孔 v1.1”(Alternative Face v1.1)的视频,内容是法国音乐家 Françoise Hardy 评论美国总统特朗普的言论,但在现实世界 Françoise Hardy 根本没说过这些话。
原来是 Mario Klingemann 只花了几天时间利用 GAN 就完成了这一个把 Françoise Hardy 的脸配上了特朗普顾问 Kellyanne Conway 声音的假视频,但由于视频的品质不太好,很容易让人发现破绽,不过 Mario Klingemann 只是想借此表达“当代即时新闻抄袭、截取、杜撰,正在摧毁世界”,而不是真的要让人误以为真。
但事实上,一个训练良好的 GAN 再配上丰富的计算资源,想要制造出以假乱真的图片或影像,已经是可以实现的事了。
NVIDIA 研究人员以真实名人的照片作为训练数据集,利用 GAN 创造出极为逼真、分辨率 1024 X 1024 的假社交名人照,“这个研究最让人惊艳的是,可以生成很高分辨率的图片,大幅提升假人物的细腻度,突破了过去 GAN 的瓶颈”,李宏毅说。

NVIDIA 的 GAN 技术可以创造出 1024 X 1024 高分辨率的假名人照(这些照片人物都不是真实存在的人),可以看出品质远高于最右边面部扭曲的两张图(图片来源:NVIDIA)
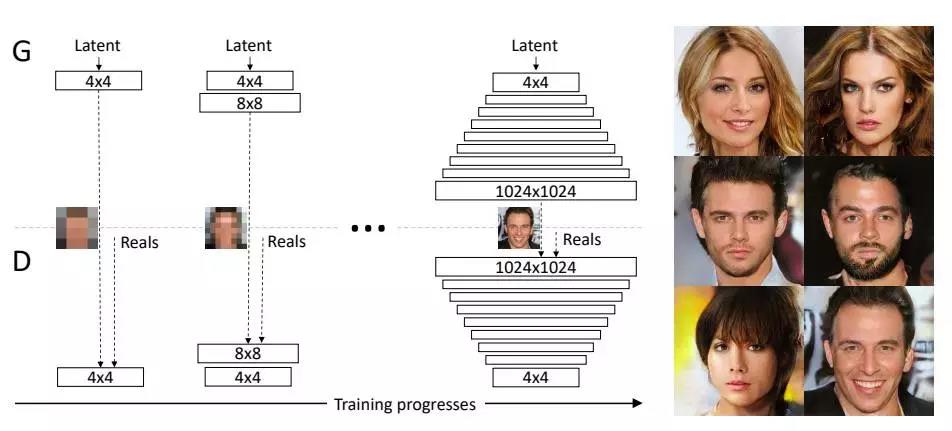
NVIDIA 的生成器制造出高解析的图片,大幅提升假人物的细腻度,突破了过去 GAN 的瓶颈(图片来源:NVIDIA)
为什么这件事会让人感到毛骨悚然?研究机器人或 AI 的人,都会听过恐怖谷(uncanny valley)理论,是一个探讨人类对于机器人和非人类物体有何感觉的假设理论。
日本机器人专家森政弘认为,由于机器人与人类在外表、动作上相似,所以人类会对机器人产生正面的情感,但若这个相似程度超过了某一个水准,人类的反应就会变得极为负面,会认为机器人僵硬、恐怖、令人头皮发麻,例如先前获得沙乌地阿拉伯公民权身份的女性机器人索菲亚(Sophia),曾说了一句“我想摧毁人类”,就引起不小的话题,人类无法知道它究竟是开玩笑、机器有 bug,还是它真的有此打算。

女性机器人索菲亚(Sophia)
但是,如果利用 GAN 来制造假新闻,或是把假图像、假视频发布在社交媒体上,恐怖程度就不只是恐怖谷讲的情感面的厌恶而已,很可能成为别有用心者操弄人民跟社会的工具,甚至是造成群体对立,上升为一种外交冲突、国家安全等级的问题。
这几年外国的社交媒体如 Facebook 一直深受假新闻、假信息的散布所苦恼,特别是先前美国大选期间,更是将此问题推到了顶点,日前 Google、Facebook、微软、Twitter 等科技公司宣布加入由曾经获得美国专业新闻记者协会(SPJ)、皮博迪奖(Peabody Award)等奖项的记者 Sally Lehrman 及圣塔克拉拉大学(SCU)应用伦理中心主导的“信任专案”(The Trust Project),希望辨别“可信”新闻来源,打击网络不实信息。
生成假影片可能在三年内实现
回想一下,过去出现的假新闻多利用似是而非的图片配上错误的文字内容,或是利用现有的 Photoshop 或合成技术,就已经造成严重影响。而今,GAN 之类的 AI 技术 将使得这件事变得愈加复杂,让人更难以分辨真假。
“生成 YouTube 假影片有可能在三年内实现……AI 会改变我们所信赖的证据——图像和音频”,Ian Goodfellow 被媒体询问如果要预估用 AI 制作假影片时这么回答。不过,他也表示,GAN 还需要更多研究做进一步突破,目前 GAN 在生成“单一”图像时可以表现得很好,但无法同时画猫、狗又会画其他影像,它距离制造复杂的数据还有很长的路。
李宏毅也提出类似看法,利用 GAN 或 AI 来造假图片、假影像以影响新闻或舆论,“是有这个可能,但是,在当下这个时间,机器充其量只能做到骗过机器,应该还无法骗过人类”,他说。
他进一步解释,单看一两张照片或许可以骗过人,但如果你要机器产生大量图片,例如几百张,就会发现它生成的图片看来看去就是那个样子,背后还是有固定的模式。如果是生成影片,目前还是很困难,画面通常很模糊。但这些问题会随着时间而被突破。
目前可检测的方式:反向搜索、色彩分析、查看脉搏等等
用 GAN 制作假图像、假新闻,现在听起来可能有点遥远,不过,利用 Photoshop 或合成技术,并不是新鲜事,已有少数的专家投入数字取证(digital forensic),识别被篡改过的图像,例如协助执法机构调查儿童色情图片或影片是合成的还是有受害者。

达特茅斯学院(Dartmouth College)计算机科学教授 Hany Farid
专门侦测假影像的达特茅斯学院(Dartmouth College)计算机科学教授 Hany Farid,就协助美国的法院、媒体如美联社、路透社、纽约时报做数字媒体的分析与判别,不久前他接受《Nature》期刊采访时,就对利用机器学习技术伪造图像,尤其是 GAN,感到担忧,“我已经看到技术变得足够好,我感到非常不安,未来 5~10 年技术会达到很好的水准”,Hany Farid 忧心的说。
为了预防未来网络上流传假信息或假新闻的事件愈演愈烈,加上能够做数字影像判别的专家相当稀少,图像处理检测工具也不多,美国国防部高级研究计划局(DARPA)就启动了一项名为“Media Forensics”研究计划,希望开发一项技术可以自动评估图像或视频的真实性,识别出是否经过编辑、带有操控目的的影像(manipulated images and videos)。Hany Farid 就是此计划的一员。
Hany Farid 举出一些现有的检测方法,首先,在图片部分,“一个简单却很有效的技术就是反向图像搜索(reverse image search)。”把图片发到 Google Image Search 或 TinEye 网站,它们会显示相关图片,可能是你所搜索的图片或是类似的图片。“当有人想要改变照片时,我们会思考哪些图案、几何形状、颜色或结构会被打乱。例如,把一个物体添加在场景中,他们摆放阴影的位置往往都是错的。”
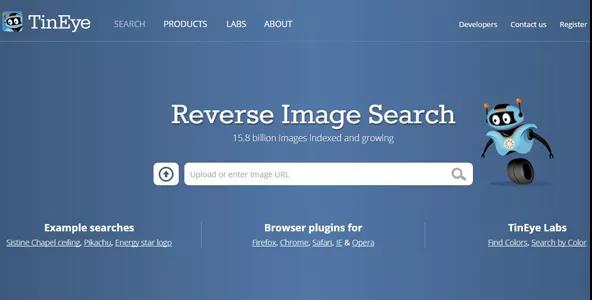
如果是只有小幅度编辑的图片呢?他表示,可以做很多分析,像是在彩色的图片中,每一个像素(pixel)都需要三个值,也就是红色、绿色、蓝色的数值,大多数的相机每一个像素只会记录一个颜色,相机再通过取其周围像素的平均值来填满空隙,也就是说,如果有人想要增加或减少某些东西,一定会破坏这个特定的关联性。
另一种则是 JPEG 压缩(JPEG compression)技术,大多数图片都用 JPEG 格式储存,为了减少存档时占用太多空间,就会丢掉一些信息。如果用 Photoshop 打开 JPEG 档案,然后再储存,一定会和原始档存有细微差别,就可以检测出来。
有没有可能打造良善 AI 专门对抗邪恶 AI?
在视频部分,问题就变得更棘手,可以尝试使用上述的 JPEG 压缩方法,但视频结构较为复杂,所以很难检测,“另一种方法是使用机器学习进行检测,但计算机生成内容总是挺完美。”
除此之外,MIT 电机工程与计算机科学系教授 William Freeman 与研究团队研发出一种“动作显微镜”(motion microscope)的技术, 通过放大视频片段,观察像素的颜色变化,就可以查看出一些细微动作,例如脉搏的微小变化。所以,可以检查视频中人脸的色彩差异,去对照这个人是否有脉搏,借此判断是真人还是计算机生成的。

动作显微镜(motion microscope)技术
既然 AI 可以造假,是否也可以打造一个 AI 可以识别图片或视频是经过改造或是机器制造出来的呢?对于这样的想法,李宏毅向 DT 君表示,“理论上可行,要让机器抓假的东西是可以做到,以 GAN 为例,判别器做的事情就是去抓这个东西是否为生成器生成的。”前提是,我们得先教机器什么是真、什么是假,也就是说,想要训练专抓假货 AI,必须喂给它带有标识的数据——标识出这是假的图片、或是由其它机器创造的,用这些数据去训练,让它学会分辨。
不过,Hany Farid 则持保守的看法,他认为,GAN 只是尝试欺骗训练它的判别器。这不能保证它将学习到可以区别图片或影片真伪的所有特征。目前在视频的识别上,仍是很困难。
人们正在创造更复杂的技术,使得数字媒体判别的发展始终追不上影像处理技术的脚步。因此,不论是 GAN 或是其他 AI 技术,有没有可能制造出一个能让一般大众信服的假图片、假视频,只是时间问题,而非可行或不可行。
所以,未来当你看到一个特朗普与金正恩把酒言欢的视频,你会觉得是真还是假?
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。