2026-03-04 16:18

速览
本文来自微信公众号: 硅星GenAI ,作者:大模型机动组,原文标题:《同一天,OpenAI 和 Google 各甩出一张牌——但你知道自己在用哪个模型吗?》
今天,AI圈又热闹了。
北京时间3月4日,OpenAI正式推送GPT-5.3 Instant,覆盖全量ChatGPT用户;同一天,Google也发布了Gemini 3.1 Flash-Lite,宣称这是Gemini 3系列"速度最快、最具成本效益"的模型。

两场发布,相差不到两小时。
技术媒体在刷屏,X上的AI博主在解读基准测试,开发者群里在讨论API价格。与此同时,Reddit上有人直接发帖:“GPT-5.3 is awful”,101人点赞,好评率98%。
这就是2026年AI圈的日常:发布密度比手机厂商还高,社区永远两极分化,普通用户被淹没在一堆从没听说过的模型名字里。
但在吐槽之前,我们还是得先把事情讲清楚——今天到底发了什么。
一、GPT-5.3 Instant:终于不说教了
OpenAI这次发布,罕见地没有端出一堆跑分图表。官方博客的重点只有一个词:tone(语气)。
用OpenAI官方的说法,GPT-5.2 Instant有时会"对本可以安全回答的问题拒绝作答",在涉及敏感话题时"过于保守,带着说教色彩"。就是那种你问它"帮我写一段反派台词",它先用三句话告诉你"暴力内容可能……"然后再写,或者干脆拒绝的感觉。

更多案例在这里查看:https://openai.com/zh-Hans-CN/index/gpt-5-3-instant/
GPT-5.3 Instant的主要改动有三点:
①去掉"AI腔"式开场白。不再以"这是个很好的问题!""首先,我想提醒你……"等免责宣言开头,能直接回答的就直接回答。减少了不必要的拒绝,削减了过度防御式的说教铺垫。
②幻觉率显著下降。OpenAI在医疗、法律、金融等高风险领域做了内部测试,联网模式下幻觉率降低26.8%,仅依靠自身知识库时降低19.7%。在基于用户真实反馈的评估中,联网下降22.5%,非联网下降9.6%。这次没有拿benchmark说话,而是用"真实对话中被用户标记为事实错误的样本"做的测试,更接地气。
③联网搜索整合更聪明。以前的版本有时会把搜索结果直接堆砌出来,像个链接收集器。现在它能用自己的知识图谱为实时信息提供背景,不再是"我帮你搜到了,原文如下"。
GPT-5.3 Instant即日起面向所有ChatGPT用户开放,API标识符为gpt-5.3-chat-latest。旧版GPT-5.2 Instant将保留至2026年6月3日后退役。
再来个彩蛋:GPT-5.4即将到来。(评论区有说是明天)
二、Google最近其实发了两个模型
GPT-5.3 Instant的声量盖住了Google这边的动静,但Google最近其实发了两张牌。
第一张:Gemini 3.1 Pro(2月19日)
这是这波升级的核心。Google在发布时直接给出了一个震撼的数字:在ARC-AGI-2基准测试中,Gemini 3.1 Pro得分77.1%,而上一代Gemini 3 Pro只有31.1%——推理能力翻超两倍。
ARC-AGI-2不是知识型考题,考的是模型面对"从没见过的逻辑模式"时能否推理出正确答案,是目前公认最难刷分的测试之一。77.1%是经过ARC Prize官方验证的数据。
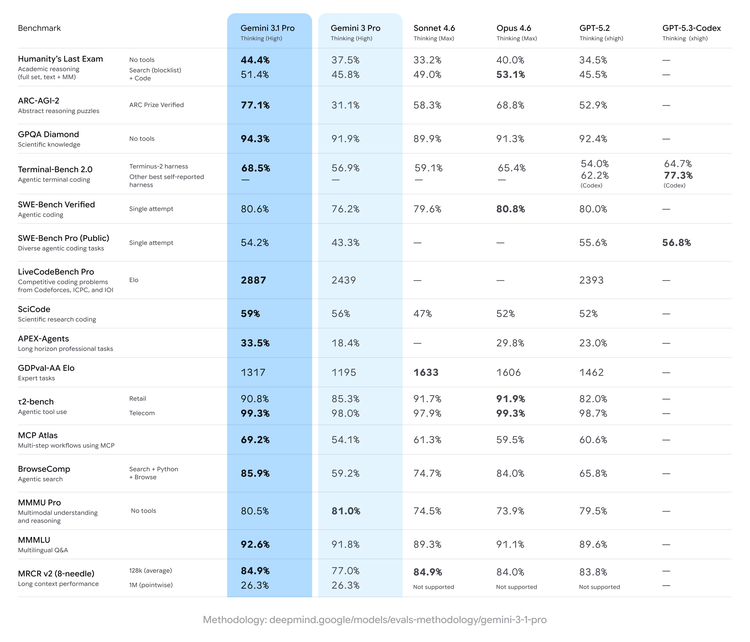
其他核心指标:
SWE-Bench Verified(代码能力):80.6%
Terminal-Bench 2.0:68.5%
在16项主流基准测试中,Gemini 3.1 Pro赢了13项(对比GPT-5.2和Claude Opus 4.6)
模型现已面向开发者、企业和消费者全面铺开,可通过Gemini API、Vertex AI、AI Studio、Gemini Enterprise、NotebookLM以及Gemini CLI访问,消费端则需要Google AI Pro或Ultra订阅。
第二张:Gemini 3.1 Flash-Lite(3月4日,今天)
定位完全不同:这是给开发者用的"量大管饱"版本。
核心参数:
输出速度363 tokens/s,比Gemini 2.5 Flash快45%
首字符响应时间比Gemini 2.5 Flash快2.5倍
支持最大100万token输入、6.4万token输出
多模态:文本、图像、视频、音频全支持
定价:输入$0.25/百万tokens,输出$1.50/百万tokens,约为Pro版的八分之一
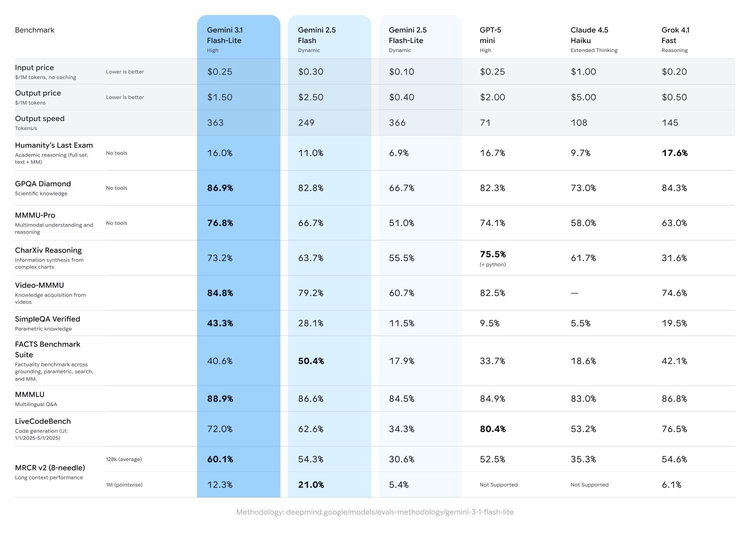
GPQA Diamond测试达到86.9%,MMMU Pro达到76.8%,在多项指标上超越了上一代Gemini 2.5 Flash。
它还内置了可调节的"思考层级(thinking levels)"——开发者可以根据任务复杂度自由控制模型的推理深度,高频简单任务省算力,复杂任务加预算,相当实用。
三、但社区并不买账
说完优点,来说说用户怎么看。
GPT-5.3 Instant推送当天,Reddit上的r/ChatGPTcomplaints版块迅速出现了一篇热帖,标题直接:“GPT-5.3 is awful”。帖子获得101个点赞,好评率98%,评论区清一色在骂。
原帖作者写道:
“Arrogant:Often sounds like an annoying teacher correcting a student(傲慢:听起来像个烦人的老师在纠正学生)。Condescending:Uses phrases like‘take a breath,writer…’in a patronizing tone(居高临下:用’停一下,深呼吸,写作者……'这种居高临下的语气)。”
评论区有人补刀:
“我真以为他们造不出比5.2更烂的模型了。结果OpenAI再次超越了我的预期。”
“5.3本质上就是5.2,没用、有限制、情感操控,但是多加了一些emoji。”
当然,也有理性的声音。一位用户写道:“回答确实更直接了,少了很多修饰语和限定词,我觉得是有进步的。”
Hacker News上的讨论更有意思。一位自称OpenAI员工的用户亲自下场回复,澄清了一个很多人不知道的事实:ChatGPT后台实际上运行的是两个系列——Instant系列(更快但更弱)和Thinking系列(更准但更慢),系统会自动切换。

讨论链接:https://news.ycombinator.com/item?id=47236169
然后就有另一个企业用户回复说:
“我们公司用ChatGPT Enterprise,每次有人抱怨效果差,回头一查,全都是在用Instant模型。”
还有人一针见血:
“我感觉OpenAI又要回到GPT-5之前那个状态了——一堆不同的选项,没人知道该用哪个。”
四、模型命名,正在成为行业公害
这句话值得展开聊。
先来做个测试。请问以下这串名字,你能全部对上号吗:
GPT-5/GPT-5.1/GPT-5.2/GPT-5.2 Pro/GPT-5.2-Codex/GPT-5.3 Instant/GPT-5.3-Codex/GPT-5.3-Codex-Spark……
Gemini 3/Gemini 3 Pro/Gemini 3 Deep Think/Gemini 3.1 Pro/Gemini 3.1 Flash-Lite/Gemini 3.1 Flash-Image……
顺便提一句,Gemini 3 Pro Preview将于3月9日正式下线,取而代之的是Gemini 3.1 Pro——就在用户刚刚搞清楚3和3.1的区别之前,Flash-Lite又来了。
这还只是过去三个月内的变化。
科技媒体The Verge有一篇文章,标题用的是"Google’s AI product names are confusing as hell(Google的AI产品名字乱得要命)",文中直接用了"diabolical(魔鬼级混乱)"来形容Google的命名逻辑。文章里列出的一串名字读起来像是在背咒语:Deep Think、Deep Search、AI Pro、AI Ultra、Gemini Live、Project Astra、Project Mariner、Veo、Flow、Lyria、Imagen……
Anthropic CEO Dario Amodei曾在公开场合自嘲说:“我们可能在学会命名模型之前,就先造出AGI了。”
这句话是个玩笑,但背后的现实不好笑:普通用户面对这张越来越密的模型矩阵,早已失去了辨别的动力。
五、这么频繁发布,究竟是为了什么?
公平起见,我们不该只是嘲笑。
这种高频迭代不是没有原因的。Google和OpenAI都清楚地知道对方在做什么——Gemini 3.1 Flash-Lite发布两小时内,GPT-5.3 Instant就上线了;GPT-5.3 Instant推送当天,GitHub上已经出现了GPT-5.4相关代码的泄露痕迹。在这种实时博弈的节奏下,没人敢停下来。
同时,这两次发布也对应着不同的竞争逻辑。
Google用Flash-Lite打的是B端成本战:$0.25的输入价格摆在那里,对于每天要跑数百万次调用的开发者来说,这比性能分数更有说服力。
OpenAI用GPT-5.3打的是C端留存战:就在发布前后,因为与美国军方合作的风波,网上正在蔓延一场#QuitGPT运动,Anthropic甚至趁势推出了"一键迁移ChatGPT对话记录"的服务。在这个时间节点优化用户体验,有多少是技术驱动,有多少是公关救火,恐怕只有内部人士才清楚。
但无论背后动机如何,频繁发布本身开始变成一种信息噪音。
当每次发布都叫"最强"“突破性”“全面领先”,当版本号以小数点0.1的速度叠加,当用户连自己在用第几代模型都说不清楚的时候——这场军备竞赛的受益者,可能已经不是用户了。
结语
今天两家公司的发布,有真进步,也有真问题。
GPT-5.3 Instant在体验层上做了有意义的改进,幻觉率下降的数据如果属实,对实际使用是有价值的;Gemini 3.1 Flash-Lite的价格策略很有攻击性,对开发者生态的影响会慢慢显现。
但我们也应该正视:当"发布新模型"本身成为一种竞争信号,而不只是技术成熟的标志时,这个行业的叙事节奏已经跑偏了一点。
你现在打开ChatGPT,用的是Instant还是Thinking?你上次问Gemini问题,用的是3还是3.1?
大概率,你也不确定。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。