2026-05-18 20:13

速览
本文来自微信公众号: 甲子光年 ,作者:周悦,编辑:王博,原文标题:《DeepSeek还有多少个“郭达雅”?扒完27篇论文,我们发现了一群“多边形战士”|甲子光年》
过去一年,围绕DeepSeek的人才流动消息一直没有停。从早期罗福莉离职,到初代大模型作者王炳宣、多模态骨干阮翀、R1核心作者郭达雅,相继跳槽。
核心作者接连被挖,DeepSeek的技术壁垒会不会松动?
我们决定换一种方式来看这个问题。
我们用Codex和Python,梳理了DeepSeek近两年发布的27篇核心论文和技术报告,逐篇拆解署名作者。对DeepSeek V2、V3、V3.2、V4这类可拆分角色的大型技术报告,只保留Research&Engineering名单;其余论文使用原始署名名单。最终,得到一份包含328人的研发作者池。
「甲子光年」发现,DeepSeek的研发团队和内部架构有以下特点:
没有部门墙。328位研发作者中有168人形成了稳定、重复的合作关系,累计产生了319条合作连接。
“兵团+小组”高效突破。1个基模大兵团与系统效率、数学与推理、多模态、缓存与系统、垂类数学、OCR视觉等6支精锐特种小队高效配合。
顶级高校背景研究者云集。DeepSeek Top25研发作者,近四成来自北京大学。
研发不设限。DeepSeek超半数研发作者在跨界,横跨3个及以上方向的有79人。研究员会根据兴趣和问题动态集结。
论文更关注底层问题。怎么更好利用算力,处理长上下文时如何降低缓存成本,模型变大之后怎么训练得稳。
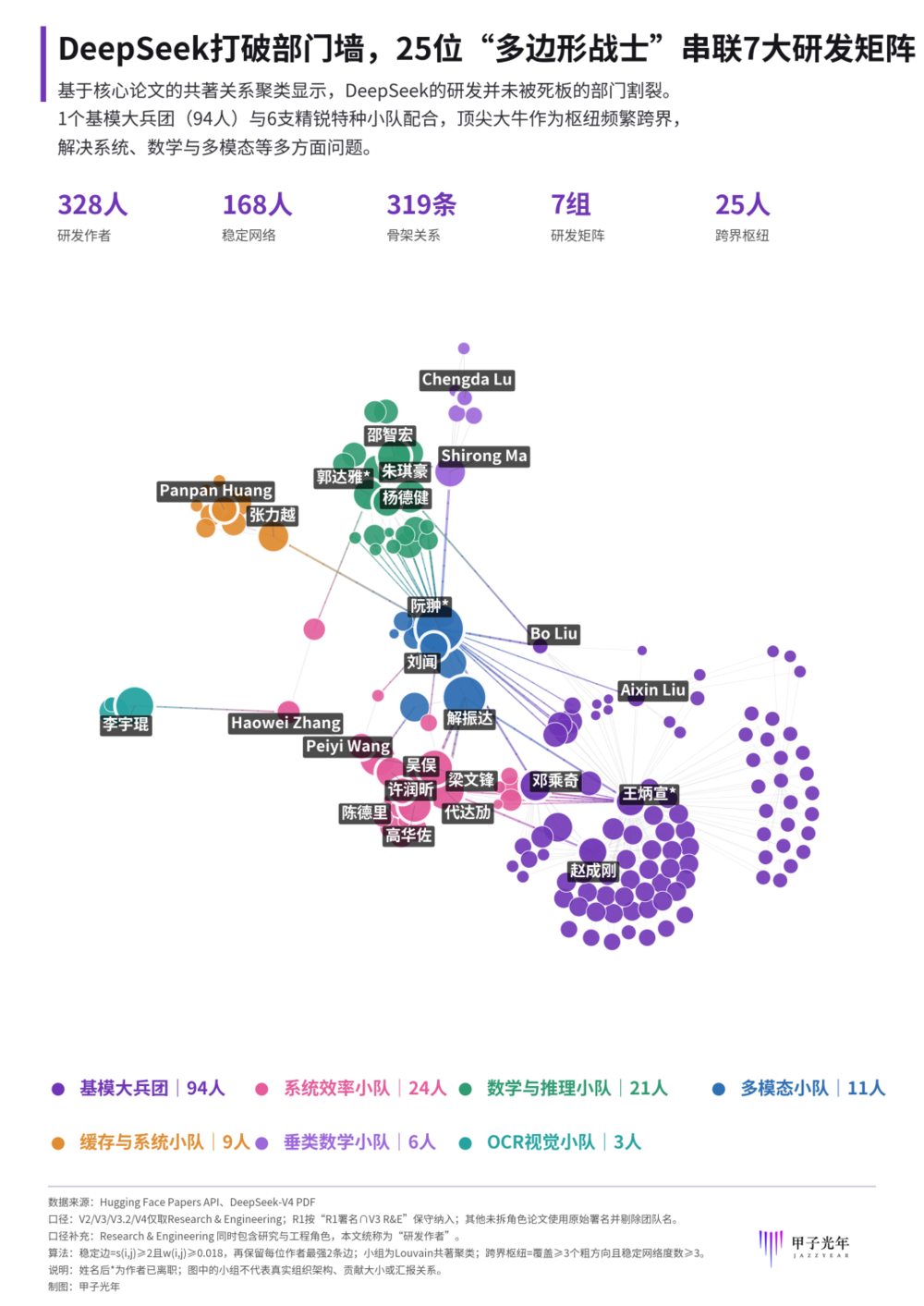
DeepSeek核心论文共著关系网络,图中每个节点代表一位研究作者,连线代表共同署名关系,「甲子光年」制图
扒完DeepSeek的27篇论文后,「甲子光年」认为,DeepSeek的思路可以概括为:不堆卡,不打榜;先验证,再集成;死磕系统效率,突破算力限制。值得一提的是,这27篇论文里几乎没有围绕benchmark刷分的工作,全都在解决具体的工程瓶颈。
1.被挖走的那几位,到底排第几?
DeepSeek的27篇论文,主要覆盖7个技术方向:基座模型、系统/效率、数学/证明、多模态、代码、OCR、推理/强化学习。
我们考察两个维度:参与论文的数量,以及覆盖技术方向的广度。需要说明的是,这两个指标都来自论文署名统计,不代表贡献大小或组织层级。我们把同时覆盖3个及以上技术方向的研发作者,称为“多边形战士”。
这个数字是多少?79人。
再看那些传闻中被重金争抢的名字,在网络里排在哪。
阮翀确实是Top 1——覆盖18篇论文、6个方向,从MoE架构到数学证明到多模态,几乎无处不在。
他本硕均毕业于北京大学,早年从事NLP研发,2023年加入DeepSeek,参与了DeepSeek-VL、V3和R1等工作,是VL2的通讯作者,今年1月,他加入元戎启行并担任首席科学家。
郭达雅参与11篇论文,覆盖4个方向,在高频研发作者中并列第12位。王炳宣参与10篇论文,覆盖5个方向,并列第17位。
他们的确是核心人员,离开当然是损失。但关键问题是:DeepSeek还有多少个“郭达雅”“王炳宣”?
像他们这样参与10篇以上论文的研发作者有24位。即便离开了三位,后面还有21位参与强度相当的人。
如果把DeepSeek看成一支球队,虽然被挖走的是几位核心球员。但这支球队的人才密度,比想象中更厚。
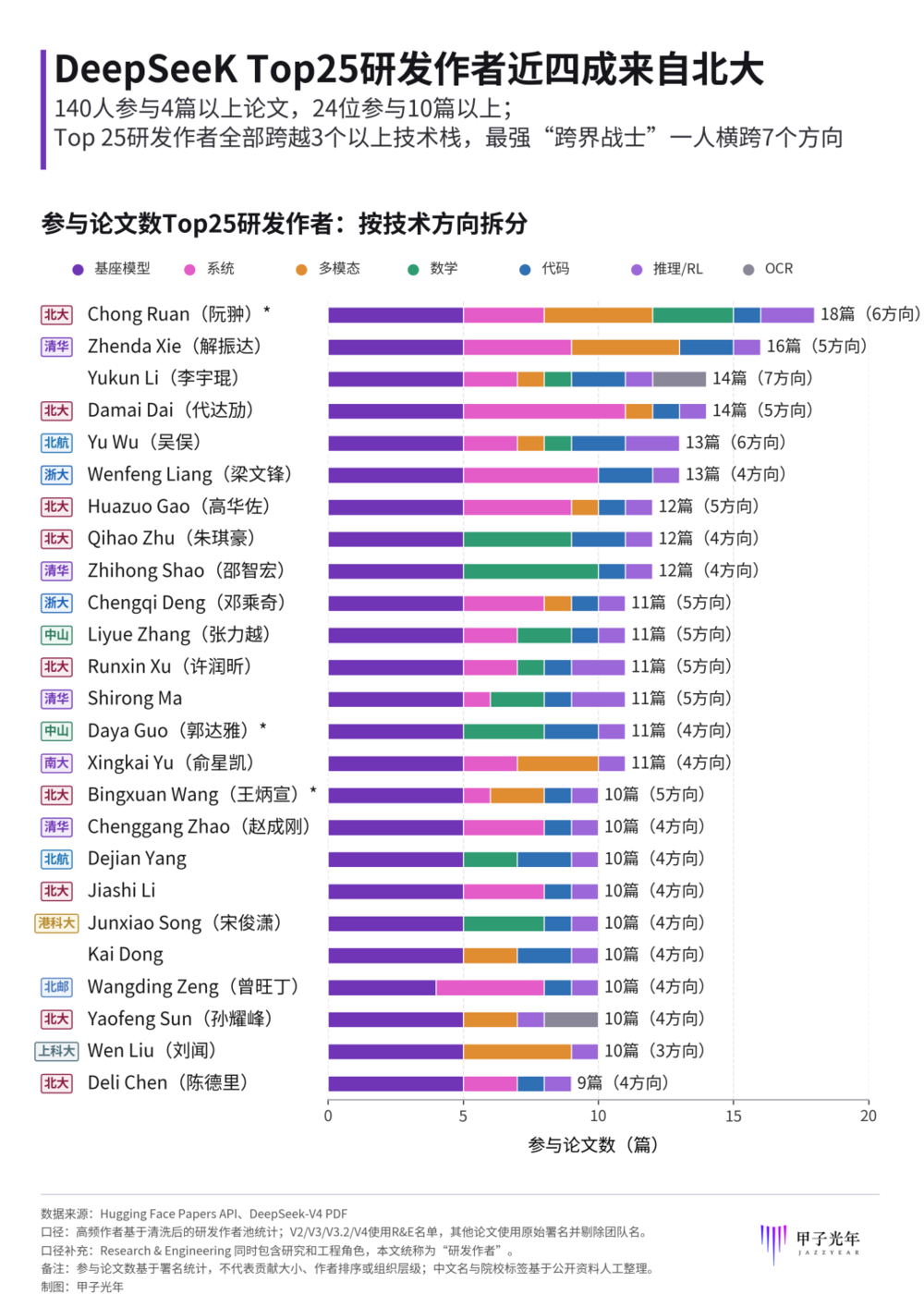
Top25高频研发作者,统计口径为研发作者池,参与论文数和方向数不代表贡献排序,「甲子光年」制图
更值得关注的是“跨界”这件事。328位研发作者中,只在1个方向出现过的有158人。剩下170人,至少跨过两个方向。其中,横跨3个及以上方向的,有79人。
举个最极端的例子,李宇琨参与14篇论文,横跨全部7个方向,从初代DeepSeek LLM一路到最新V4,谷歌学术引用量超过两万。他是DeepSeek的“首位员工”,2023年从字节跳动搜索团队离职后加入,负责预训练数据的相关工作。
这印证了一个常被外界忽略的事实,在AI行业,人才一直是多向流动的,DeepSeek也在从别处挖人。
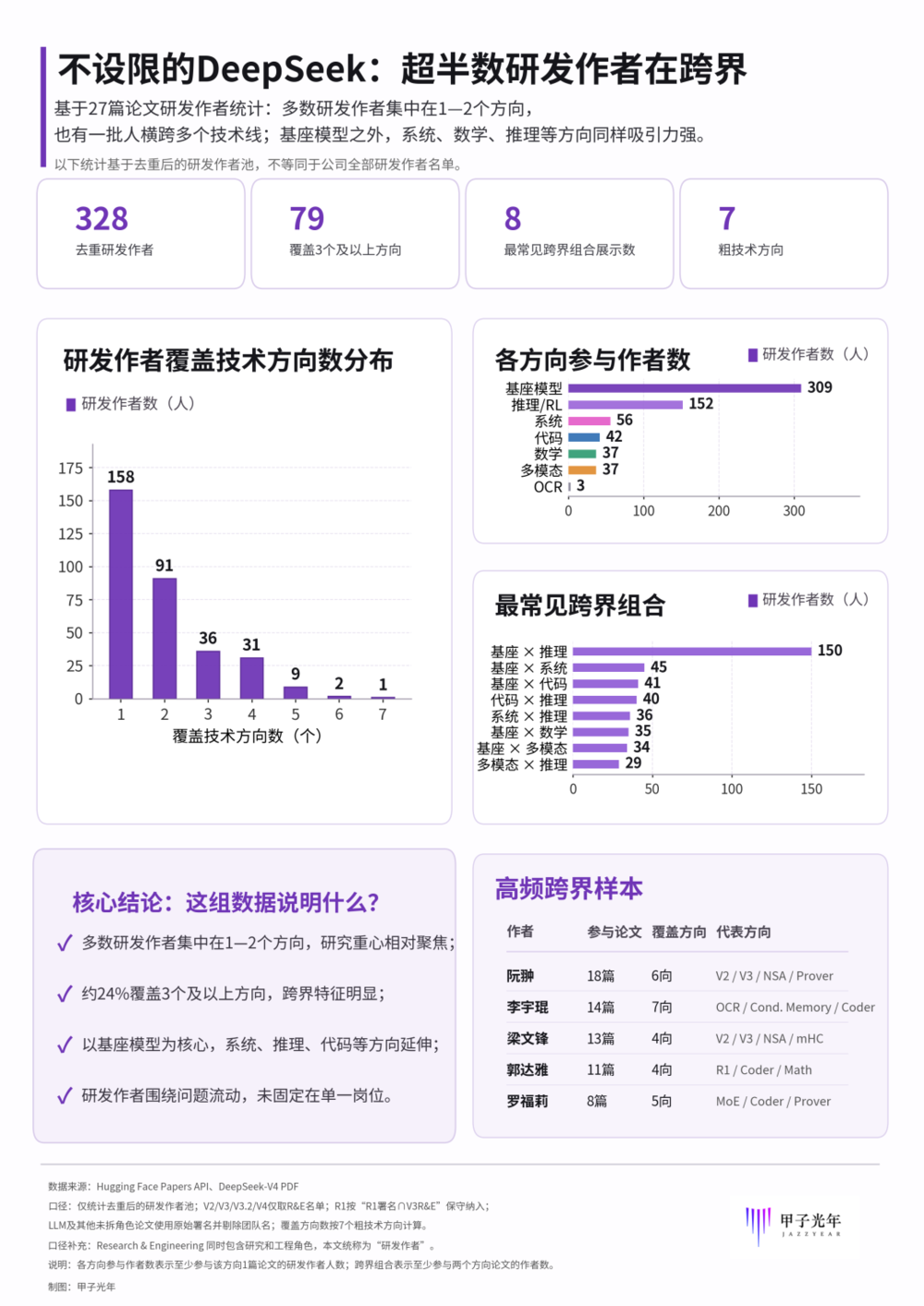
DeepSeek研发作者覆盖技术方向数分布,覆盖方向数按7个技术方向计算,「甲子光年」制图
2.多边形战士怎么长出来?
外界总在讨论DeepSeek还有没有天才。
每个AI公司都有明星。DeepSeek不同的地方,是能让一批很年轻的人,迅速在多个技术方向之间组队、探索、获得资源,较少受到约束和限制。
辛华剑在DeepSeek实习期间,主导开发了专注于数学证明DeepSeek-Prover系列模型,他也是DeepSeek-Prover-V1.5论文的一作。他曾告诉「甲子光年」,Prover在内部最初只是一个独立探索项目,初衷是验证能否通过形式化系统构造出更严格的推理数据。
大多数大厂会先设部门、定KPI、分预算,再启动项目。DeepSeek的顺序是反过来的:先有人觉得一个问题值得做,再围绕这个问题找人和资源。
在论文合作网络里,这种“组队”方式留下的痕迹很清楚。按署名关系聚类,能看到4个相对集中的小组:基模大兵团、系统效率、数学与推理、多模态,以及3个更小的协作簇。需要说明的是,这些“组”不对应DeepSeek真实部门,只反映谁更常和谁合作。

DeepSeek研发作者合作网络分布,合作小组按稳定共著关系识别,「甲子光年」制图
有趣的是,这个结构和梁文锋描述的组织方式高度吻合。
梁文锋说过:“我们一般不前置分工,而是自然分工。每个人有自己独特的成长经历,都是自带想法的,不需要push他。当一个idea显示出潜力,我们也会自上而下地去调配资源。”
晚点LatePost报道过,DeepSeek的组织层级很薄,研究团队大体只有梁文锋和研究员两个层级。“有时开始一个新方向,就是因为有三五个人都觉得一个idea不错,然后就一起做了。”梁文锋更接近一个导师:组织研发、协调资源,在共同成果上署名为通讯作者。
这套组织方式还有一个在AI行业里极为罕见的特征:不加班。平日多数成员6到7点离开公司,不打卡,没有明确绩效考核。梁文锋的逻辑是:“一个人每天能高质量工作的时间很难超过6到8小时。加班疲劳下的昏庸判断反而会浪费宝贵的算力资源,得不偿失。”
「甲子光年」梳理发现,DeepSeek论文作者中,多为2023年前后毕业的清华、北大、中科大等高校本硕博生。排名前25的高频研发作者里,近4成毕业于北大。
但这不应该被理解成简单的“名校人海战术”。「甲子光年」了解到,不少AIlab的招聘取向都在变化,在校博士比大厂老兵更受青睐。
一位AI公司董事长曾告诉「甲子光年」,自从ChatGPT出来后,他开始挤出午饭的时间,面试有潜力的在读博士生,再小的项目都会问上至少1小时,从基础公式推导到工程细节把控,筛出真正的创新者。他提到,大多数人都是在2023年才开始转向GPT相关的架构研究,相当于站在同一个起跑线上。“这一时间点后毕业的博士,还未被行业惯性束缚,常带来意想不到的突破。”
梁文锋自己也说过:做出DeepSeek V2的,“都是一些Top高校的应届毕业生、没毕业的博四博五实习生,还有一些毕业才几年的年轻人。”
那DeepSeek团队稳定性如何?我们交叉比对从论文署名:初代模型论文(2024年1月)的86位作者中,到V4(2026年4月)仍然出现在署名里的有75人。两年半过去,初代团队近九成仍在。
V4的Research&Engineering名单,269名研发工程作者中,论文标注已离职者为10人,占比约3.7%。而据Z Finance报道,截至今年4月,过去一年,约有60—70名字节Seed成员流向各大模型公司。
这些数字不等同于DeepSeek真实流失率,但说明核心研发网络并没有因为几位明星出走而散架。
3.两年27篇论文,死磕系统效率
只看外界声量,V3、V4这些基座模型报告最引人注目。
但论文主题分布给出的结果有点反直觉:27篇中数量最多的,不是基座模型,而是系统/效率类论文(7篇),超过基座模型(5篇)和数学(5篇)。
这7篇分别是:DeepSeekMoE、ESFT、NSA、Insights into V3、mHC、Conditional Memory和DualPath。没有一篇是在刷benchmark,全都在解决同一类问题:怎么用更少的算力做更多的事。
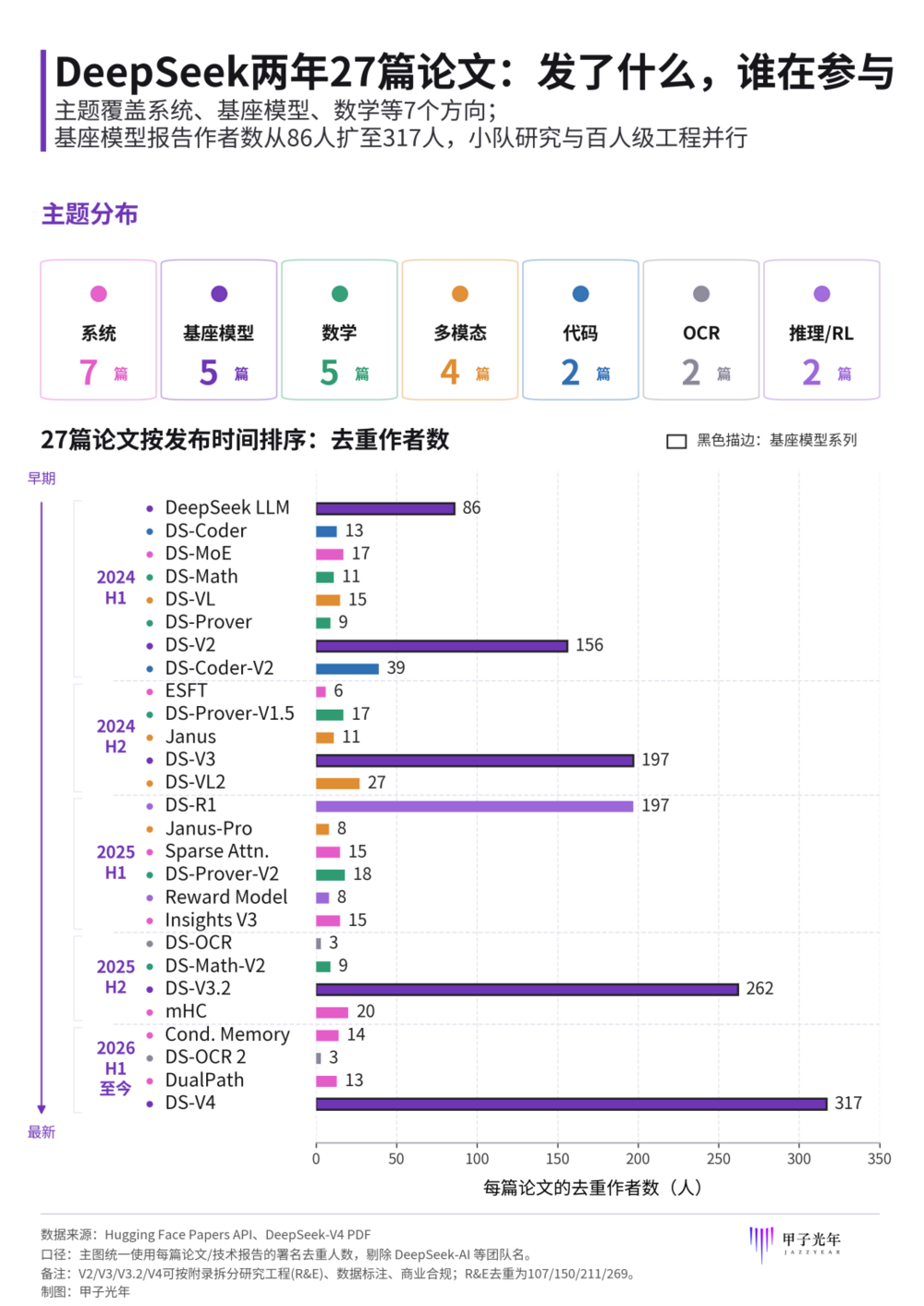
DeepSeek近两年27篇论文时间线,横轴表示每篇论文或技术报告的去重作者数,颜色表示技术方向,「甲子光年」制图
逐一拆解这些论文,会看到三类底层问题:
第一类,怎么更好利用算力。ESFT关注的是如何更经济地完成模型微调,Insights into V3则复盘如何在大规模集群训练中提高硬件利用率和稳定性。
第二类,处理长上下文时降低缓存成本。当模型需要处理更长文本,或者执行复杂Agent任务时,注意力计算和KV Cache(模型保存历史上下文的中间记忆)会迅速变贵。NSA、Conditional Memory和DualPath都在试图压缩模型“记住历史”的成本。
第三类,模型变大之后怎么训练得稳。DeepSeekMoE探索的是参数规模变大时,只激活更少的专家网络;mHC则试图增强深层网络中的信号传播,降低超大规模模型训练时的不稳定性。
梁文锋曾抛出过一个假设:“能不能用现存的一部分算力,就实现现在所有的智能?”这7篇系统相关论文,可以看作DeepSeek团队一直在回答这个问题。
还有一个细节值得注意,27篇论文的作者规模,呈现“大小搭配”的节奏。基座模型报告动辄200到300人的全员参与,系统、数学、多模态方向的论文通常只有6到20人。
前者像大兵团作战,后者像特种小队的单点突破,先用小团队低成本验证,跑通了再集成进下一代旗舰。
4.从R1到V4,攒出底牌
如果把DeepSeek的研发看成一场长跑,V4不是突然出现的爆发,更像是几条技术路线在两年后集中收束。
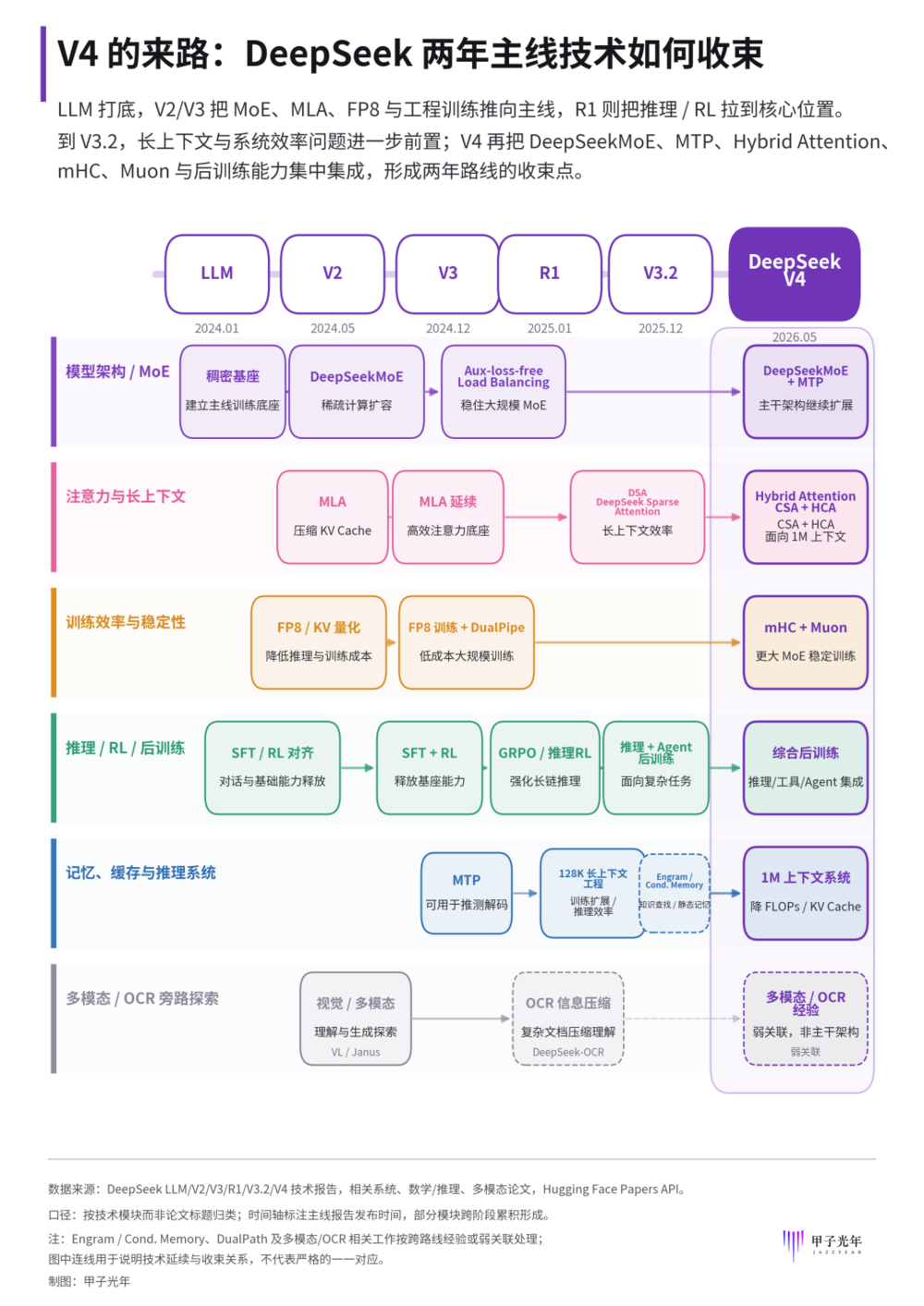
DeepSeek技术模块演进,图中展示的是论文中可追溯的技术路线和模块关系,不等同于严格代码复用率,「甲子光年」制图
第一条主线是参数效率。从V2引入MoE(稀疏混合专家架构),到V3延续并强化多Token预测策略,再到V4在MoE框架上继续压低激活参数和推理成本。一路都在往“激活更少参数、完成同样任务”的方向走。
第二条主线是长上下文效率。模型处理的历史越长,需要保存的中间记忆越多,成本越高。
用一个比喻来理解,传统大模型像把整本书摊开,每回答一个问题都要从头翻一遍。DeepSeek从V2开始就在想,能不能把近处内容保留原文、远处内容做成目录、更远处内容压成章节摘要?
这个想法从V2的MLA(多头潜在注意力),到V3.2的NSA(原生稀疏注意力),一直演化到V4的Hybrid Attention(混合注意力系统)。
V4技术报告显示,在100万Token的长上下文场景下,V4-Pro的单Token推理计算量约为V3.2的27%,KV Cache占用约为其10%。
第三条主线是后训练整合。R1证明了大规模强化学习可以显著激发模型推理能力。到了V4,思路延伸为在数学、代码等领域分别练强,再统一“毕业”——通过同策略蒸馏(OPD)将能力合并进统一模型,减少混训时的相互干扰。
此外,Prover系列服务于数学与形式化推理,OCR路线为视觉输入压缩提供低成本方案,mHC与Muon是更底层的训练稳定性优化。每个关键模块先在小规模论文里反复试验,随后进入旗舰,最后沉淀成整个团队的工程实践。
「甲子光年」看来,V4的重点不是更大或更强,而是让模型不仅能想得更深,也能在更长、更复杂的任务中,以更低成本持续运行。
DeepSeek的思路可以概括为:不堆卡,不打榜;先验证,再集成;死磕系统效率,突破算力限制。27篇论文里几乎没有围绕benchmark刷分的工作,全都在解决具体的工程瓶颈。
梁文锋说过:“如果目标是做应用,沿用Llama结构短平快上产品也合理。但我们目的地是AGI,需要研究新的模型结构,在有限资源下实现更强的模型能力。”
值得注意的是,DeepSeek甚至把底层算子库从主流的CUDA和Triton换成了北大团队开源的TileLang,V3.1的数据压缩格式也是针对下一代国产芯片设计的。在追求极致效率的同时,他们还在做一件更长远的事:基于国产生态来做大模型。
5.挖走人,带不走体系
人才流动不会停止。在AI行业,顶尖研发作者被高薪争抢几乎是常态。DeepSeek也不会例外。
但如果用挖人来判断一家公司的稳定性,这个框架本身就有问题——尤其当这家公司的竞争力,根本不依附于几个明星个体。
大众总爱看天才的故事,但27篇论文的数据讲了一个更难被概括的故事。数据呈现的DeepSeek是:79位多边形战士、24位参与10篇以上论文的骨干、两年半前的初代成员87%仍选择留下来。
更重要的是,这张网络里有25位跨界枢纽,把研发串联在一起,没有固定部门墙,研究员根据兴趣和问题动态集结。
而那两年积累下来的技术路线——从MoE到MLA到GRPO到mHC——每个模块都经过前序论文的反复验证,早已内化在整个团队的工程实践里。
梁文锋说过:“我们把价值沉淀在团队上,同事在过程中得到成长,积累很多know-how,形成可以创新的组织和文化,就是我们的护城河。”
这可能才是500亿美元估值背后,最值得被重新定价的东西。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。