2026-05-25 17:36

速览
本文来自微信公众号: APPSO ,作者:发现明日产品的,原文标题:《DeepSeek 要用蜜雪冰城的打法,做中国版 Claude Code》
DeepSeek之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。
最近,DeepSeek官方宣布,DeepSeek-V4-Pro模型API将永久降价。同时,DeepSeek表示,API已完成输出提速与服务扩容,速度更快,服务更稳定,默认支持500并发,企业用户可以在线申请更高并发。
发布模型,再给出折扣,接着降低缓存命中价格,最后把临时优惠变成长期价格。大模型API的价格基准正在被重新改写,而低价模型背后的下一站,很可能是Agent。

DeepSeek永久降价,梁文锋把Token价格打骨折了
让我们先来简单梳理一下DeepSeek的降价时间线:
4月24日,DeepSeek V4预览版正式发布。
4月25日,DeepSeek宣布V4-Pro开启2.5折优惠。
4月26日,DeepSeek宣布缓存命中价格调整为首发价的十分之一。
4月28日,DeepSeek宣布V4-Pro的2.5折优惠延期至5月31日。
5月22日,DeepSeek宣布V4-Pro永久降价为原价的四分之一。
时间线的关键之处,在于临时折扣变成了永久降价。调整之后,DeepSeek-V4-Pro输入缓存命中价格从0.1元每百万Tokens降至0.025元,输入缓存未命中价格从12元每百万Tokens降至3元;
输出价格从24元每百万Tokens降至6元。叠加默认500并发和服务提速后,官方API对开发者和企业的吸引力进一步提高。
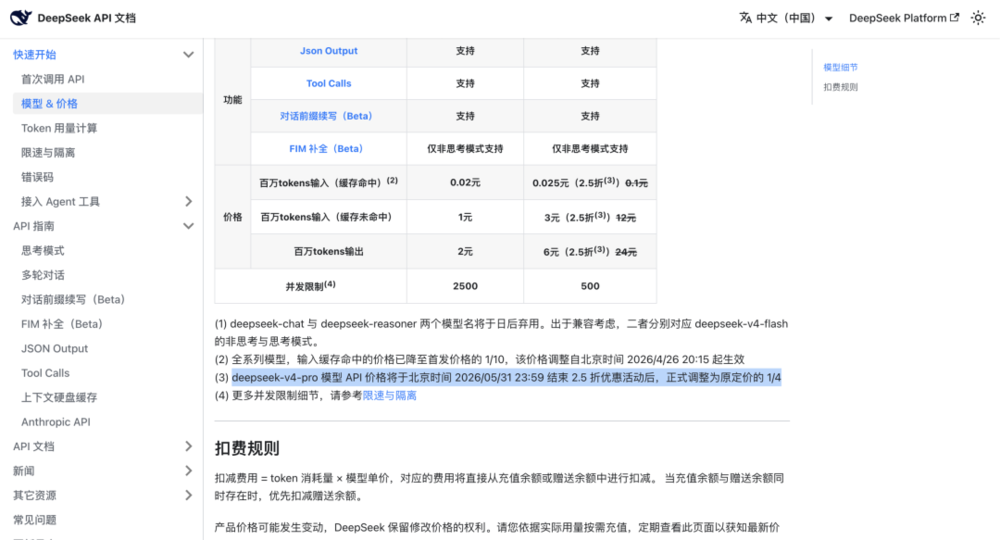
🔗https://api-docs.deepseek.com/zh-cn/quick\_start/pricing
而价格下调最直接的影响,是把任务成本推到开发者决策的更前端。
在代码场景里,一次任务可能要读取项目文件、分析日志、多轮修改、反复运行测试,Tokens消耗很容易放大。
长上下文、代码库分析、批量重构、自动测试、Agent多轮执行这些高消耗场景,开始更接近个人开发者和小团队的预算范围。
过去,开发者选择Claude、OpenAI或Gemini,主要看模型能力、稳定性、生态和使用习惯。DeepSeek打骨折的永久降价,也意味着在绝对的性价比面前,开发者使用习惯也是可以轻易改变的。
顺着这条线,DeepSeek一贯的市场角色也更清楚了:用低价、开源和强推理能力,持续建立大模型市场的价格优势。对国内模型厂商来说,V4-Pro永久降价相当于重新划了一条API定价线。
智谱、MiniMax、月之暗面这类同样依赖API收费、又面向开发者和企业客户的模型,压力可想而知。反观Claude、OpenAI、Gemini等海外头部模型,由于市场、客户结构和生态位置不同,短期冲击则相对有限。
但如果DeepSeek后续推出类似Claude Code的编码工具,再用低token成本支撑高频调用,价格敏感的开发者群体会更容易被吸引过来。
梁文锋此前对DeepSeek定价哲学的解释,也能放到今天理解。
早在2024年DeepSeek V2降价时,梁文锋就提到,DeepSeek只是按照自己的节奏做事,核算成本后定价,原则是不贴钱,也不赚取暴利。他还说,降价一部分来自下一代模型结构探索带来的成本下降,另一部分原因是API和AI都应该是普惠的、人人用得起的东西。
比起把API当成高毛利收费入口,DeepSeek则更像是在用过硬的Infra实力压低推理成本,再用低价吸引开发者、应用和下游生态进入自己的轨道。
X平台博主@bookwormengr最近在一篇题为《DeepSeek's 10 trillion USD grand strategy(DeepSeek的十万亿美元棋局)》的长文中,给出了一个更激进的解释。
他认为,DeepSeek的真正目标未必是和智谱、月之暗面、MiniMax竞争,也不是急着补齐多模态、语音、视频这些产品线,而是通过持续降低训练和推理的资源需求,推动一套更便宜、更分散的AI硬件生态成形。
在他看来,DeepSeek的长期价值不只在模型本身,而在于让更多国产存储、GPU、ASIC、网络芯片和异构硬件进入大模型训练与推理体系。
这个判断未必能完全兑现,但它解释了DeepSeek一系列选择背后的方向:
MoE、MLA、DSA、GRPO、RLVR、KV Cache压缩、Dual Path、TileLang,表面上看是模型架构和推理工程优化,往深处看,都是在降低对高端HBM、顶级GPU和CUDA生态的依赖。
一系列降价公告里,最值得关注的不只是输出价格下降,还有缓存命中价格下降。
在大模型推理过程中,KV Cache是一个关键成本项。模型处理长上下文时,需要把历史tokens对应的Key和Value存起来,后续生成时反复使用。上下文越长,需要保存和读取的缓存越多,对显存、带宽和存储系统的压力也越大。
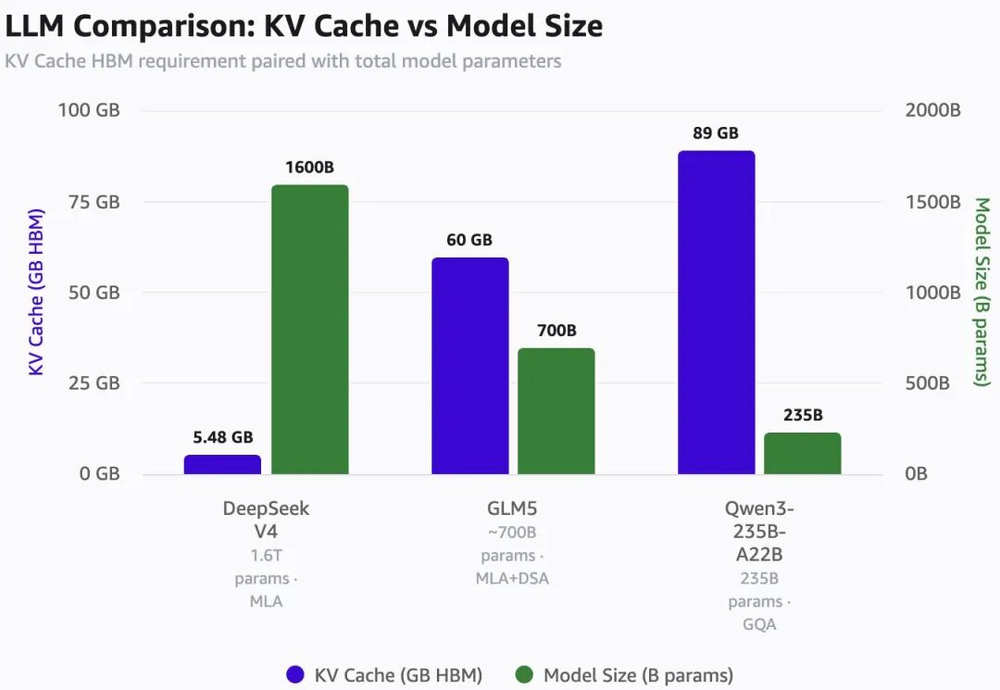
普通聊天里,缓存压力不一定明显,但在进入代码、长文档和Agent任务后,成本结构会迅速变化。@bookwormengr在长文里专门算了一笔KV Cache账。
他以100万tokens上下文、8 bit KV精度和16 bit索引精度为前提,估算DeepSeek V4只需要约5.48GB HBM,而GLM5约为60GB,Qwen3-235B-A22B约为89GB。
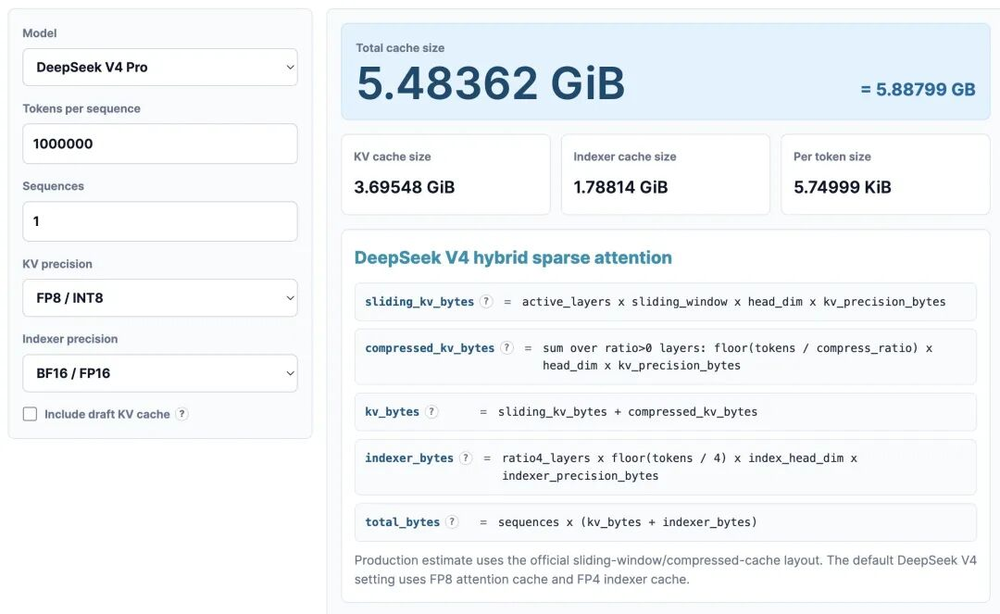
长上下文和Agent任务真正贵的地方,不只是模型生成本身,还有缓存、显存、带宽和重复上下文搬运。
一个Code Agent处理项目时,可能要反复读取同一个代码库结构、同一批文件、同一段任务历史、同一套系统提示词和同一批测试日志。若每一轮都按完整上下文重新计费,长任务很快会变贵。缓存命中价格下降后,重复上下文的成本会明显变低。
DeepSeek近年来在MoE架构、长上下文、KV Cache压缩和推理效率上持续投入的表现有目共睹。降价是技术迭代后的必然结果,也将彻底搅动AI编程市场格局。
为什么必须做中国版「Claude Code」?
最先被牵动的,是AI编程工具的订阅模式。
市面主流AI编程工具均推出Coding Plan月付订阅,为用户提供代码补全、模型调用、Agent执行等权益。在轻量化补全时代,单次调用消耗极低。
但AI编程已从单次补全迭代为全流程Agent自动化编码,模型可独立完成代码修改、测试运行、报错修复,单次任务Token消耗大幅提升。
当底层API又同时大幅降价,Coding Plan也必须找到新的支撑点。这个支撑点,更可能落在工程能力上——比如能不能更好地读懂项目结构,能不能精准选择上下文,能不能控制tokens消耗,能不能稳定修改代码,能不能处理Git、终端、CI/CD,能不能在企业环境里管理权限和审计记录?
同样要重新定位的,还有API中转站。对个人开发者来说,便宜和好用仍然重要。但对企业来说,稳定、可审计、可控、可迁移更重要。
沿着这个逻辑继续看,Coding Plan和中转站的改变只是表层。低价之后更值得追问的,是开发者入口究竟掌握在谁手里。
Google CEO Sundar Pichai最近接受了《Hard Fork》采访,他首次公开承认,Google在文本、多模态、语音、推理和整体智能上都很有竞争力,但在agentic coding这一类能力上,尤其是工具调用、指令跟随和长周期任务,目前还有差距。
他还提到,更关键的是把模型放到真实世界里使用,让数据回流,继续迭代。Pichai特别说到,coding是一个需要接触data flows(数据流)的领域。
终端工具能看到开发者如何提出任务,如何追问,什么时候接受建议,什么时候放弃,什么时候要求模型继续修复。它还可以通过测试结果、终端日志、文件变更和Git提交,判断一次Agent执行是否完成任务。这类数据,对coding model和Agent产品都非常有价值。
从公开招聘动作看,DeepSeek近期围绕Agent的动作也变得密集。
我们也可以看到岗位里出现了Agent深度学习算法研究员、Agent数据策略工程师、产品经理、研发工程师等角色。更关键的是,DeepSeek资深研究员陈德里直接发出招聘信息,提到要从零开始构建Code Harness。
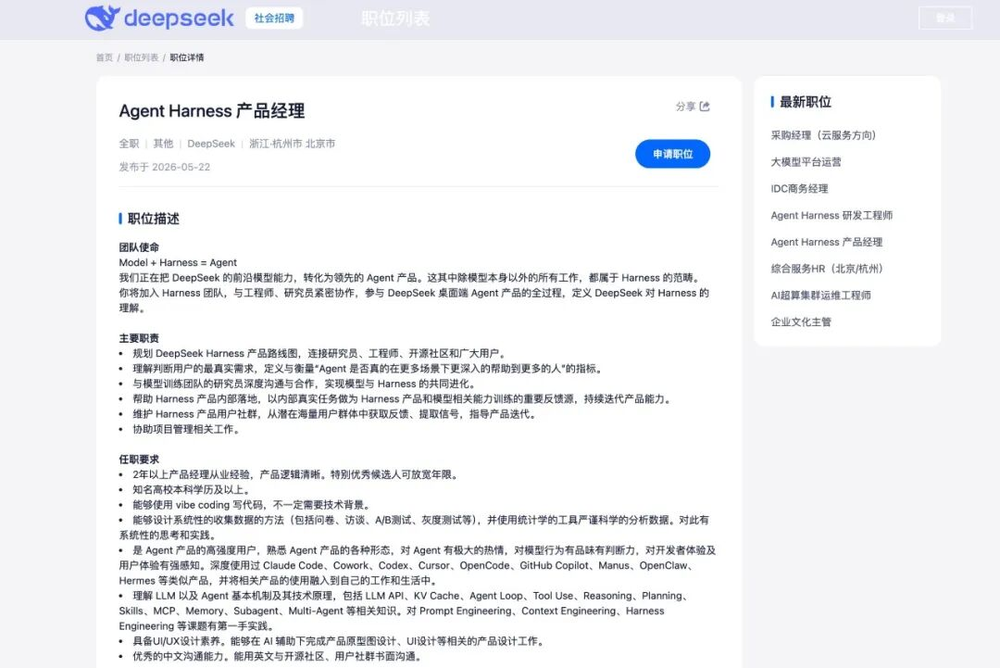
如其所说,Model+Harness=Agent,在Agent产品中,模型负责理解和生成,Harness负责把模型能力带入真实工程环境,相当于模型外面那套「执行系统」。
DeepSeek版Claude Code不能只给开发者一个对话框,而要给开发者一个能持续执行任务的工程系统。
崔添翼加入DeepSeek后受到关注,也和Code Agent的工程属性有关。
公开信息显示,崔添翼本科毕业于浙江大学计算机系,曾因信息学竞赛保送浙大,6次获得ACM亚洲区域赛金牌,之后在Jane Street工作9年,并联合创立TSY Capital。

Code Agent的难点不只是生成代码,还要在真实项目里持续执行任务。量化交易系统长期强调低延迟、稳定性、自动化执行和风险控制,这些经验放到Agent Harness上,至少在工程范式上是相通的。
而Agent工具的产品能力,不只包括写代码,也包括权限、审计、数据隔离和安全策略。
这反过来给DeepSeek这样的国产模型提供了机会。如果DeepSeek能把低成本模型、Code Harness、本地部署、企业级权限控制结合起来,它在政企、金融、制造、能源等对数据敏感的行业里,会有更强的替代价值。
DeepSeek做中国版Claude Code的逻辑也正在于此:低价tokens把更多开发者吸引进来。低缓存价格让Agent任务运行成本下降。Code Harness让模型进入开发环境。真实工作流又会反过来帮助DeepSeek改进模型和产品。
就像滚下坡的雪球,越滚越大,滚得越快。降价只是推下山的第一把力,往后它会自己越滚越沉,谁也拦不住。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。