2026-05-26 23:41

速览
本文来自微信公众号: 甲子光年 ,作者:卫琳聪,原文标题:《精读华为“韬(τ)定律”论文:逻辑折叠、AI提速与投资转向|甲子光年》
2026年5月25日召开的国际电路与系统研讨会上,华为公司董事、半导体业务部总裁何庭波正式提出“韬(τ)定律”,迅速成为业界焦点。
在5月25日当天,何庭波还向中国科学院科技论文预发布平台提交了题为《A Time Scaling Theory for Multi-Layer Electronic Systems(多层电子系统的时间缩放理论)》的英文论文,系统阐述了“韬(τ)定律”。
「甲子光年」深入拆解这篇论文,从“韬(τ)定律”底层技术路线客观来看它对AI、半导体产业将带来哪些真实影响。

1.以τ为尺度
何庭波在论文开篇直指摩尔定律面临的物理极限,宣告“几何时代的终结”。
过去近60年,半导体行业都在摩尔定律的驱动下,以纳米为单位来衡量进步。每十八个月晶体管尺寸缩小、频率上升、每逻辑门的成本下降,整个半导体行业都建立在这个“契约”之上,目标只有一个:把晶体管做得更小。
但随着晶体管越做越小,摩尔定律逼近物理极限,边际收益急剧递减。何庭波在论文中直观点明了摩尔定律在边际收益上的失效:
到了7nm以下,纯粹靠缩小晶体管尺寸带来的回报已经趋于平缓,2nm节点的领先芯片设计预算超过了每颗芯片十亿美元,成本不降反升。
由于获取最先进光刻设备的途径受限,华为更早面临这个行业性难题,也催生了韬(τ)定律。
何庭波在论文中阐述了韬(τ)定律的核心思想,也就是把时间而非几何大小作为首要度量标准,追求时间缩微而非几何缩微。
这篇论文认为,从对最终用户的核心影响来看,摩尔定律从来就不是关于几何本身的。晶体管变小、互连变集、集成度变高等等之所以能提升芯片性能,本质上都是对时间的压缩,让信号传递更快,摩尔定律追求的几何缩微只是压缩时间的工具之一。
基于此,这篇论文提出,在整个技术栈的每一层——晶体管、电路、芯片、系统——定义一个特征时间常数τ,并将缩短τ作为统一的优化目标。这正是韬(τ)定律的核心策略。τ被视为一个分层结构,可以分解为:
也就是晶体管层、电路层、芯片层、系统层有各自的τ,每一层的τ都由其下层τ以及该层所引入的组织开销和通信开销共同构成。
论文中强调,τ的适用范围在时间上跨越大约十二个数量级(从皮秒到秒),在空间上也覆盖了相当的范围(从纳米到公里)。这意味着,τ作为衡量标准可以用于描述从最小晶体管到最大数据中心的一切事物,是一个底层、通用的物理量。
针对每一层的τ,论文中提出了不同的机制来缩短:
晶体管层:通过提升迁移率、应变工程、高k金属栅极和GAA架构来解决本征开关延迟,并且越来越依赖减少局部互连的寄生电阻和电容。论文指出,这些寄生参数现在已超过本征传输时间数倍。
电路层:通过更低电阻率的导体、低k电介质,尤其是通过垂直集成来缩短导线长度,来降低信号路径上的RC传播延迟。
芯片层:通过架构选择、流水线深度、内存层次结构和片上网络来解决计算和内存访问延迟。
系统层:通过互连拓扑、协议栈和网络结构设计来缩短端到端的消息传递和同步时间。
整体来看,这些机制追求的是在晶体管大小不变的前提下,通过系统性缩短信号传递的物理距离和逻辑距离实现τ的缩减,进而提升芯片性能。
在这一策略框架下,华为提出的核心技术手段是“逻辑折叠”(LogicFolding)。
论文介绍,数字系统的性能上限由相邻触发器级之间的关键路径延迟决定,而这一延迟又主要受限于该路径上的互连RC和门级数量。
传统的优化方式是将门级放在一个平面上,然后通过上方的金属堆栈来布线;导线越长,寄生RC越大,关键路径就越慢。
逻辑折叠抛弃了传统平面假设,将关键路径上的门级分布到两个或更多垂直堆叠的有源层上,通过超细间距的混合键合技术连接起来。
这样一来,信号线大幅缩短,寄生RC显著下降,时钟偏斜得到改善,芯片在相同的器件节点上能实现更高的时钟频率。
打个比方来说,传统芯片设计是盖平房,一间屋子连着一间屋子。逻辑折叠则是盖高楼,每层之间用电梯相连。这样原本从第一间屋子走到第十间屋子的路程可以缩短成坐电梯从一楼直达十楼,花费的时间随之减少。
逻辑折叠的效果如何?这篇论文公布了在麒麟2026上测得的结果。
其中,晶体管密度在一代之内从155 MT/mm²阶跃式提升到了238 MT/mm²——这样的提升幅度以往需要三年的几何缩放才能实现。
SoC性能核心的能效提升41%,最大时钟频率提升近13%,SRAM操作频率提升了40%以上,时钟缓冲区减少50%以上,时钟偏斜减少25%

逻辑折叠性能提升概览
论文强调,麒麟2026上采用的逻辑折叠是保守方案,只在关键路径上选择性使用。即便如此,CPU性能核心的频率2026年仍然回到了3.1 GHz。
未来十年,逻辑折叠预计将从局部的关键路径折叠,发展到全面的多层折叠——每个封装三个、四个甚至更多的有源层,而这意味着更大的性能提升。
论文公布,从2026年到2035年,晶体管密度预计将向400 MT/mm²及以上迈进,CPU核心频率迈向4 GHz。
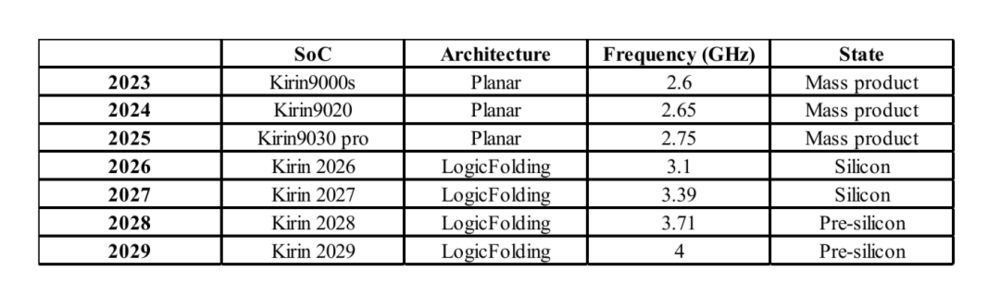
麒麟CPU性能核心工作频率趋势
2.AI10秒完成的任务,一年内能缩短到1秒
外界对韬(τ)定律的一大关注点是期待这一突破能在提升AI算力上发挥作用。不过,韬(τ)定律是在智能手机上发展起来的,放到AI训练和推理上能否奏效?毕竟,手机只有一颗芯片、功耗毫瓦级,AI则是成百上千颗芯片协同工作,功耗高达吉瓦级。
何庭波在论文中直接回答了这个问题,“答案是肯定的。”
论文分析,AI系统有两个特点。其一是系统持续扩大,芯片甚至能多达上万颗。其二,AI系统的各项消耗主要是在数据上而不是计算上。大型AI集群中,超过80%的能耗用于数据移动;超过70%的系统成本分配给了数据存储。
这意味着减少数据在传输中花费的时间至少和减少计算本身花费的时间同等重要,也决定了“韬(τ)定律”能在AI领域发挥作用。甚至在AI领域,τ的缩减速度将远远快于移动设备和自动驾驶。
这一判断源于论文中基于τ的分层缩减得出的代际法则:
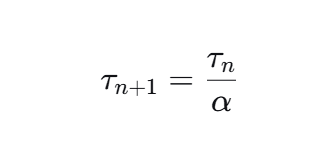
其中α是特定于应用场景的缩放因子。基于迄今为止的生产经验,这篇论文提出,移动设备的α约为每年1.3倍,自动驾驶约为每年1.5倍,AI工作负载α最高可达每年10倍。
也就是说,每一代的τ会缩短为上一代的1/α,移动设备的τ每年缩短到上一年的约77%(1/1.3),AI系统的τ每年可缩短到上一年的仅10%(1/10)。这意味着,AI完成同样任务所需的时间在一年内最快可以从10秒压缩到1秒。
为什么τ在AI上的缩减可以这么快?论文给出的解释是“因为在这些场景下,吞吐量直接转化为经济价值。”
换句话说,在AI训练和推理中,算力就是经济价值。AI系统不存在手机、电动车那样的物理约束和体验约束,速度越快越能吸引资金涌入。只要技术能跑通,带来的效果会更充分的发挥。
这篇论文强调,在AI系统中需要把τ当作一个系统级目标,应用到整个链条上,而不仅仅是在单个加速器内部。τ缩放在AI中的实现需要通过三个层面相互配合:系统互连架构(灵衢总线Unified Bus)、近封装光引擎(Hi-ONE)、封装本身的拓扑重组(3D折叠)。
其中,灵衢总线(UB)用一个单一的协议取代传统多节点、多加速器架构的堆叠结构。实现在主要通信路径上,系统τ能降低约500倍。
再采用高密度光互连节点引擎Hi-ONE将所需的SerDes传输距离从约100厘米缩短到约5厘米,消除笨重的布线,并将传输距离从不足1米扩展到100米,使得分布式、吉瓦级数据中心的高密度互连在物理上成为可能。
此外,采用3D折叠将原本束缚在边缘的资源重新迁移到垂直表面上,解决2.5D扇出困境。形成垂直集成的堆栈,其中内存、互连结构、让电源和逻辑都能一起扩展。
论文表示,到2035年,硬件集成度预计将增加超过100倍,τ的缩减将分布在整个技术栈的每一层,而不是集中在器件级别。

AI系统规模下的τ
3.“下一个美元应该投向τ”
韬(τ)定律是系统级工程路线,它带来的影响不仅是技术上,也是产业上的。当半导体产业不再只着眼于将晶体管做小,而更注重从系统层面提升性能,整个产业链的价值也会重新分配。
论文中分析,在8086时代,整个行业通过标准化的内存总线,有意地将处理器和内存解耦,使得两个产业独立发展。但AI时代这种解耦正在被逆转。
如今计算密度的持续提升,正将内存带宽、延迟、功耗和封装推向极限。对于现代AI工作负载,数据移动与计算本身同样关键,逻辑和内存正再次被推向紧密的物理集成。随着它们的融合,供应链中的影响力平衡正在向内存和封装供应商转移。
「甲子光年」认为,先进封装、混合键合设备、EDA工具、高速互联、散热等相关环节的价值都可能得到提升。未来半导体产业链的价值不再仅集中在单点晶圆制造,而要看谁能在系统层面让数据传输路径变短、速度变快。
正如论文中所说:“下一个美元应该投向τ,而不是工艺节点——有竞争力的性能不再需要永远停留在光刻技术的最前沿,封装、内存带宽和互连结构设计,现在占据了此前仅由领先逻辑节点独自拥有的战略权重。”
客观来看,“韬(τ)定律”目前还只是基于华为实践经验的技术路线,真正成为共识还需要更广泛的行业参与和更长久的时间验证。
何庭波在论文中直言:“如果把τ缩放描述成一个已经完成的体系,那将是一种误导。仍有几个实质性的问题尚未解决,在此指出它们,既是为了突出正在进行的工作,也是为了邀请各方合作。”
具体而言,“韬(τ)定律”的实践需要τ原生的工具链支持。全面的逻辑折叠要求工具链将多个堆叠的芯片视为一个单一的连续设计实体。在这一路径上,垂直互连的寄生参数、KOZ排除区域以及晶圆间的工艺变异相互作用,传统的二维EDA工具无法充分处理。
论文中披露,华为已经开发出初步的内部工具,能够产生有用的结果,方法学细节将在未来几个月内公布。并且强调,“一个τ原生的工具链——开放的、多物理场的、三维原生的——是未来十年最重要的赋能投资。”
并且,“韬(τ)定律”也面临能量问题。论文中表示“τ是一个时间定律,而不是焦耳定律。”这意味着性能翻10倍功耗也会翻10倍,这样一个“超级节点”可能会超出电网容量,像摩尔定律遭遇物理极限一样遭遇能量极限。
此外,晶圆间工艺变异、垂直互连的额外代价、适配“韬(τ)定律”的基准测试等都是有待完善和解决的问题。
但方向是清晰的:在“后摩尔时代”,需要从系统整体而非单一晶体管层面着手,提高数据移动效率,进而提高性能。在这一点上,华为和英伟达、台积电的技术逻辑是一致的。
“韬(τ)定律”最大的贡献在于方法论。论文中阐述,这是自Dennard缩放以来,第一个为整个技术栈提供统一优化目标的缩放原理。它向工艺技术专家、电路设计师、架构师、系统工程师和软件团队发出了信号:这些领域的人们现在正在用相同的单位优化同一个量,任何单一层面的改进,只有传播到系统τ才算数。
何庭波在论文最后颇具感情地写道:“未来十年的工作范围已经划定。许多开放性问题依然存在,没有任何一个组织能够独自解决它们——工具链、标准、基准测试、器件物理、经济模型,都需要来自任何一家公司之外的贡献。因此,本文既是一份来自实践一线的报告,也是一份邀请。”
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。