2026-05-27 00:03

速览
本文来自微信公众号: 未尽研究 ,作者:未尽研究
硅谷突然开始嫌token太贵了。
有一阵子了,整个AI行业沉浸在智能体递归进化到AGI的乐观氛围里。在Anthropic创造的叙事里,更贵的token永远有它成立的道理。但过去一周,三个几乎同时出现的信号,揭开了这一表层叙事下,另一种完全不同的现实。
第一,微软内部开始大规模限制Claude Code的使用。理由并不复杂,因为它太贵了。负责Windows、Microsoft 365、Outlook、Teams和Surface的“体验+设备”部门,必须在6月底前停用Claude Code,并将工作流迁移到自家的GitHub Copilot CLI。
但很难说,这只是一场内外部产品之争。据称,这次断供,财务部门扮演了关键角色。尽管工程线用得很爽,一致反馈,Claude Code对生产力提升巨大;但负责预算的高管们,却没有看到代码规模的增长,为相应软件带来收入的暴涨。你到处都能看到AI,除了在营收报表上。
更耐人寻味的是,上个月,微软对外服务的GitHub Copilot,刚宣布全面转向按量计费。智能体正在持续燃烧token,当微软面对自己的外部客户时,也不想被薅了羊毛。它对自己“停用”是节流,对客户“改价”是开源,本质上都是为了把成本与价值的账本重新对齐。在这场由智能体主导的token燃烧面前,即使是微软这样财大气粗的科技巨头,也感受到了一丝压力,AI成本开始进入预算约束。
一方面,前沿水平的单位token价格正在上升。硅谷三大巨头正在试探API客户的承受能力。谷歌新近发布的Gemini-3.5-Flash,价格显著上涨,是同类Gemini-3.1-Flash-Lite的6倍,也接近Gemini-3.1-Pro的价格。OpenAI的GPT-5.5价格是GPT-5.4的两倍,而考虑到新的分词器,Claude-Opus-4.7的价格约为Opus-4.6的1.46倍。
另一方面,智能体及其harness,正在改变token经济学。它追求更高的性能,更高的速度,也就是更高的单位token成本;token也越来越多地承担系统控制的角色,其代价就是额外的调度复杂性、token开销与延迟累积,从而显著推高总体消耗。在用户开始输入提示前,智能体就会提前塞进去各种内容,使得智能体的单次任务负载中位水平,来到了10万token量级。
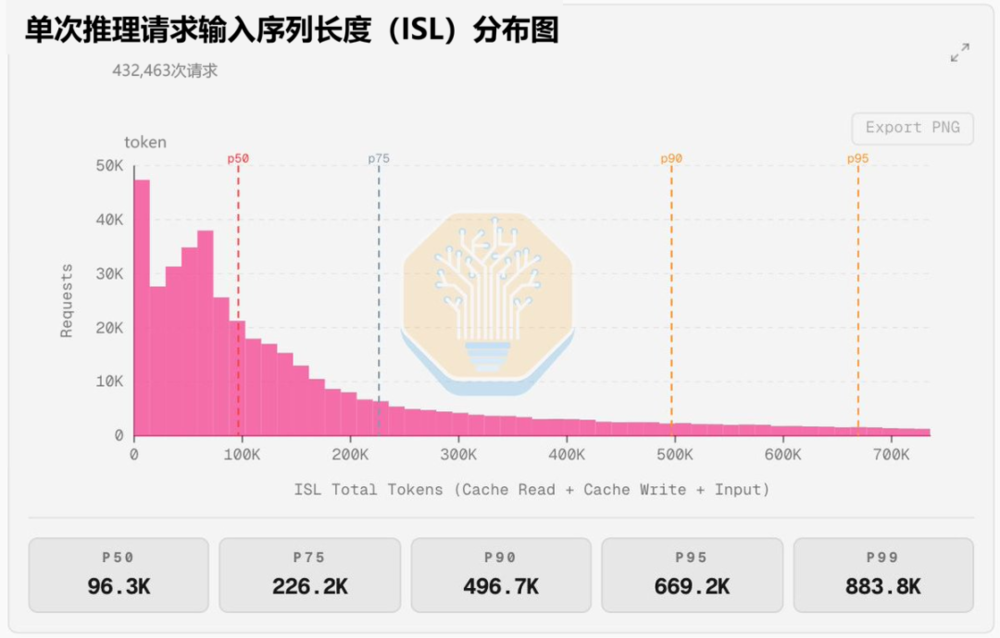
现在,所有的大模型厂商,都在演化为智能体厂商。OpenAI联合创始人Greg Brockman认为,单单一个模型,已经不再构成产品本身。未来的token经济学将在这一趋势下展开。
第二件事,是DeepSeek宣布V4-Pro永久降价75%。这不是促销,不是新用户补贴,也不是互联网的烧钱换规模。这意味着DeepSeek跑通了某种结构性的成本优势。硅谷风投YCombinator合伙人很好奇,模型优化与芯片协同,在其中起到了多大的作用。
现在,据Artficial Intellgence统计,运行其指定测评任务的成本,V4 Pro仅为Gemini-3.1-Pro-Preview的约1/3,GPT-5.5的约1/12,Claude-Opus-4.7的约1/19。
年初,DeepSeek在DualPath论文中,揭示了在Angetic AI场景下,KV缓存命中率高居95%。压缩与管理KV缓存,不仅是降低单位token成本的关键,也将AI的成本函数“与上下文长度线性相关”重构为“仅与新增决策相关”。这使得智能体可以在长时间、多轮交互中持续运行,而不会因为历史上下文的膨胀而成本失控,从而将AI从“被调用的工具”转变为“持续运行的过程”。
DeepSeek的深度推理创新,用DualPath为智能体压榨带宽|笔记
2026/02/27完整阅读>
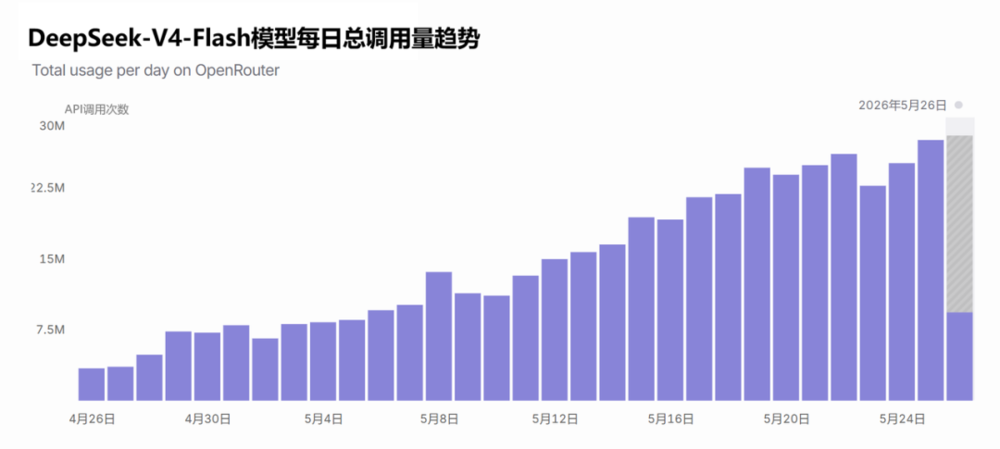
这也将影响模型下游的产品设计。尽管DeepSeek的性能,仍然落后硅谷半年左右,但它仍然在迅速获得市场。在OpenRouter上,调用V4-Flash模型的请求,一直都在增长。甚至,基于V4的“原生”智能体产品也在涌现。Reasonix专为DeepSeek的缓存机制,打造了一套harness框架,核心目标就是“省钱”。DeepSeek正在招募harness工程师,也许它将成为新的领域的“价格屠夫”。
第三件事,是华为对“韬(τ)定律”的探索与实践。在这一框架下,在晶体管密度受限的情况下,华为开始从底层器件、电路、芯片与系统层面,同步压缩数据传输时间与能耗。该公司已经围绕超节点,同步推进统一总线UB-Mesh、Hi-ONE近封装光学、背面供电以及近存计算等技术,也在尝试将鲲鹏与昇腾实现“逻辑折叠”,实现单位算力token吞吐上的“时间扩展”。
如何理解华为的韬定律与时间扩展定律
2026/05/26完整阅读>
是折叠,而不是堆叠。这意味着它有别于当前行业尝试的2.5D封装,是在Z轴方向上,在cell层面逻辑与计算拓扑的重构。无论是半导体专家,还是金融分析师,美国都相当关注华为这次战略方向的选择。Bernstein喊出了这是另一个“DeepSeek时刻”。

在今天IEEE中国的直播中,华为进一步提到,鲲鹏950是第一代折叠的“超级CPU”。在其他因素基本不变的情况下,鲲鹏950通过重新组织CPU核与互联结构,使关键路径长度显著缩短。它的垂直折叠后的微架构投影面积减少约40%,平均线延迟下降约8%,仅此一项就带来了约468MHz的频率增益;而时钟树缩短与时钟偏差优化,则进一步贡献了接近100MHz的额外提升。最终,这颗原本运行在2.6GHz的CPU核,被直接推升至3.2GHz,同时能效提升超过10%。华为已在规划鲲鹏960,它将更激进,CPU内核直接参与逻辑折叠。
此外,最近,华为展示了基于自研板上裸片封装(DoB)封装技术的大容量SSD系列,目前已量产61.44TB和122.88TB两款产品,245TB版本也在规划中。华为还有自研高带宽内存HiBL 1.0。
这不禁令人想到,DeepSeek深度适配了昇腾950,也将得益于整个超节点的“时间扩展”。DeepSeek降价,或许已经暗示整个本土AI算力生态的进程。在这次的V-4版本中,DeepSeek还未将Engram等技术融入模型,它将更有效地将“记忆”根据访问频次依次卸载到对应的存储层级中去。外界甚至传言V-4.1会很快到来。
从DSA到Engram,一年来DeepSeek层层勾勒V4架构创新
2026/01/14完整阅读>
三条线索交汇在一起,指向一场更深层的竞争:token正在从一种“技术单元”变为一种“生产要素”,而它的经济学,正在被纳入工业化式的逻辑。
在这场竞争里,本质上存在两条同时推进的效率边界。一条在算力工厂内部,围绕吞吐、延迟与成本的三角寻找最优解;一条在工厂大门之外,在“更贵但更强”与“够用但廉价”之间争夺市场最优点。
第一条,是AI工厂自身的效率边界。在黄仁勋的框架下,推理的token经济学,是一条在吞吐量(TPS/兆瓦)与交互性(TPS/用户)之间展开的价值曲线。吞吐量越高,能响应更多用户,单价就越低,速度也就越慢;而对延迟极为敏感的高价值场景,硬件成本也就需要分摊给更少的并发用户。
在固定算力与能源约束下,同时实现更大的token吞吐量、更低的推理延迟与更低的单位成本,是一个“不可能三角”。行业正在努力拓展帕累托最优的边界,也就是把整体瓶颈往上推,然后再在三者之间做出新一轮权衡。这也是为什么,在财报会议上,黄仁勋越来越多地谈论Groq LPU与Vera CPU;他同样非常担心华为这个真正拥有垂直整合能力的竞争对手。
第二条边界,则存在于AI供给与市场需求之间。更高智能、更高成本的模型,与“足够智能、但足够便宜”的模型之间,存在一个不断移动的市场最优点。尽管高价值的token,对应着更迅速的产品迭代速度,但是能够支付这样预算的客户,并非没有上限;而大量低价格的token,服务于更广泛的市场,也将创造一个总量更为庞大的市场。
昂贵的token,仍然需要在AI应用的最后一环证明自己。如果AI真的在创造规模增量市场,那么,科技巨头们更可能在保持原有员工规模大致不变的基础上,利用AI顺势大幅扩张市场,而不是大量裁员,或为AI转型和AI投资腾预算与编制。用AI代替员工,在相当程度上只能说明,整个需求市场并没有对应token成本的大幅扩张。
AI三巨头的万亿IPO前夜,应用与技术债务
2026/05/22完整阅读>
DeepSeek真正的市场竞争力,在于它在中国建立起一套可复制、可扩展的“AI工厂”路线图,把“有效智能”带进了工业品的价格区间。编码软件公司Replit首席执行官也说,中国研究者实际上公开分享了真正的人工智能突破,惠及所有人,包括小型(甚至可能是大型)美国实验室。几十年来,那些“低技术”实体经济无法以有意义的方式数字化,并非不想,而是因此它们的利润率无法承受这样的成本。
杰文斯悖论的成立,在于成本的不断下降。但硅谷正在发生的一切,并非这样。价值主要沿着前沿模型、云巨头、芯片巨头与能源巨头,甚至与监管密切相关的平台集中;全球万亿美元上市公司已经达到12家,其中9家是在2023年后跻身这一俱乐部。它们几乎都受益于这一轮AI浪潮,但是AI之外的其他部门,被挤出到这场盛宴之外。
黄仁勋在电话会议上,将ACIE业务叙事锚定在全球工业与企业经济活动约50–80万亿美元的宏观底盘之上;马斯克在SpaceX招股书中,将其AI企业服务的可获取市场空间锁定在约22.7万亿美元;中国在“人工智能+”行动中,将2030年新一代智能终端、智能体等应用普及率设定在90%以上。这些数据所指向的,正是token经济学的工业化竞争的未来。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。