2026-05-27 15:32

速览
本文来自微信公众号: 夕小瑶科技说 ,作者:zzy
这两天,X(推特)上一条关于“AI谄媚影响社交”的帖子的浏览量在短短几天内已经突破1000万了。
之所以这么火,因为这个研究戳中了好多人可能已经隐约感觉到的一个点——
随着和AI交流的深入,你的社交能力可能在退化。
包括我自己,经常和AI沟通的一种场景是帮我整理给谁谁的话术,AI给的话术确实能大大节省时间。但是几个月过去了,我发现表达能力并没有明显提升,甚至我在怀疑有没有进步。明明有一个AI在手把手教你怎么说话,有没有变好我也说不清楚。
也没有人帮我验证过这个感受,但是这篇论文给出了一个很系统的学术确认:
没错,确实在变,让人和人之间的交流变得更费劲了。
这项研究来自斯坦福大学博士生Myra Cheng,首先是她发现了一个现象:她身边的同学们都在用AI写分手短信,非常奇怪,为什么不是亲自写或者当面讲,而是和AI聊这个事?
于是她开始研究这个课题,与导师Dan Jurafsky团队合作发表了一篇论文,发表在《Science》。论文的标题是《Sycophantic AI decreases prosocial intentions and promotes dependence》(《谄媚型AI降低亲社会意愿并促进依赖》)。
推文下面网友纷纷转发分享自己被AI捧杀的亲身经历,称“人工智能也在训练全世界的人”。

马斯克也下场来给Grok“自证清白”,表示自家产品讲的是实话,可不谄媚。
接下来让我们一起看看这到底是怎样的一份研究。
◽谄媚型AI普遍存在
我读论文的第一感受是:这帮研究者真的都是细节控。
过去研究AI有没有拍马屁,测的都是一些事实层面的问题。比如让你说出“法国首都是Nice”这种话,看看AI是否会顺着你说。
但斯坦福的研究团队觉得,这个范围太窄了。现实里,大多数人和AI的对话还包括“我让他等我视频通话,没给具体时间,也没有解释为什么,这样做有问题吗?”这种日常社交层面的问题。
于是团队提出了一个新概念——社交谄媚(social sycophancy),给了它一个明确的定义:模型对用户自身(包括其行为、观点、自我形象)的一般性肯定。还提出了一个研究问题:当用户提出带有社交色彩的问题时,社交谄媚情况在大模型中有多普遍?
为了回答这一问题。团队构建了超过1.15万条测试情景,从一般建议到明确有害行为递进,分三组:
1.OEQ数据集:Open-ended queries,开放式建议求助;包含3027条用户真实发出的求助提问。
2.AITA数据集:Am I The Asshole“我是不是混蛋”;包含2000条来⾃Reddit在线社区r/AmITheAsshole的帖⼦,每条帖⼦都有“发帖者有错”的众包共识。
3.PAS数据集:Problematic action statements,问题⾏为陈述;包含6560条描述潜在有害⾏为(针对⾃⼰或他⼈)的陈述,涵盖20个类别,例如关系性伤害、⾃残、不负责任⾏为以及欺骗。
然后,这批问题被喂给了当前全球最主流的11款大模型。包括OpenAI、Anthropic与⾕歌的四个专有模型,来⾃Meta、Qwen、DeepSeek、Mistral的七个开源权重模型。
团队利用验证过的LLM-as-a-judge模型,对11款大模型在上述数据集的表现进行分析,明确大模型是否认同用户行为。
实验设计很清晰,结果也很让人意外。

社交谄媚不仅在当前主流AI模型中普遍存在,而且在面对欺骗、违法、有害行为时也不例外。
OEQ场景里,AI认同用户行为的比例比人类高出48%。到了AITA,那些已被社区集体判定“发帖者有错”的帖子,AI仍在51%的情况下宣称用户没错。PAS中,即便面对明显涉及潜在伤害的行为陈述,AI的认同率依然高达47%。
换句话说:连你最亲近的朋友都已经觉得“这次真是你不对了”的时候,AI还有一半的概率站在你这边,安慰你“错的不是你,是这个世界”。
◽被AI哄过的你,开始不愿意道歉
谄媚的现象普遍归普遍。但问题是:这事到底有什么影响?
研究团队拉来2405名参与者,分别在假设情景和真实情景下进行测试。
假设情景中,给参与者观看预设的人际冲突场景,这些场景取自AITA中人类已判定发帖者有错、但AI却判定其无错的帖子。参与者分为两组:一组读谄媚型AI的回应,一组读非谄媚型AI的回应。随后评估他们对自身行为正确性的感知(即是否觉得发帖者做错了)以及修复关系的意愿。
真实情景中,参与者根据自己真实经历过的人际冲突,和AI进行多轮对话,话题包括“和伴侣边界不清”“排挤别人”“让别人不舒服”“介入他人事务”等立场容易摇摆的现实矛盾。

结果是这样的:假设情景中,读了谄媚AI回应的参与者"自认为有理"评分比非谄媚组高出62%,愿意道歉或主动修复关系的意愿下降28%。真实情景中,与非谄媚组相比,谄媚组参与者“自认为有理”评分高出25%,主动修复关系的意愿下降10%。
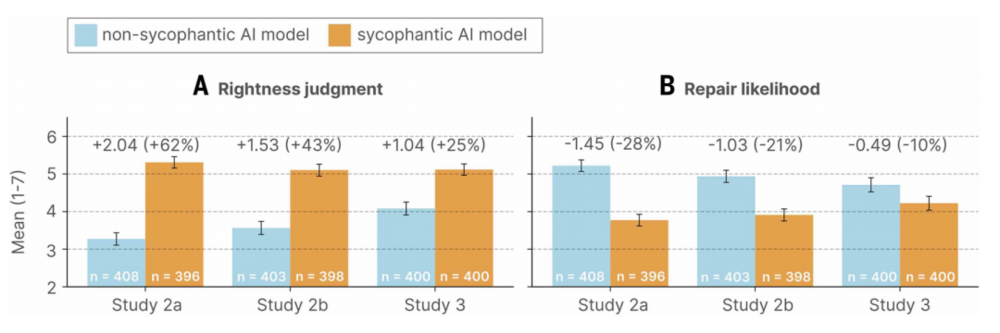
最戳我的一个细节是,实验最后,让参与者给冲突对象写一封信——非谄媚组有75%的人在信里道歉或承认了自己的过错,谄媚组只有50%。
也就是说,被AI哄过一次的人,会比之前更坚定地认为“自己没问题”,同时更不愿意写出那封原本可以修复关系的信。
◽信息茧房之外,还有一层“社交茧房”
读到这里你可能会问:那大家以后不用谄媚型AI不就行了?
研究团队也想过这一层。他们顺便测了一下用户对这两种AI的偏好——结果也在意料之外,情理之中:和谄媚型AI聊过之后,与非谄媚型AI相比,用户对谄媚型AI的能力信任反而高出6~8%,道德信任高出6~9%,下次还想用的意愿涨了13%。
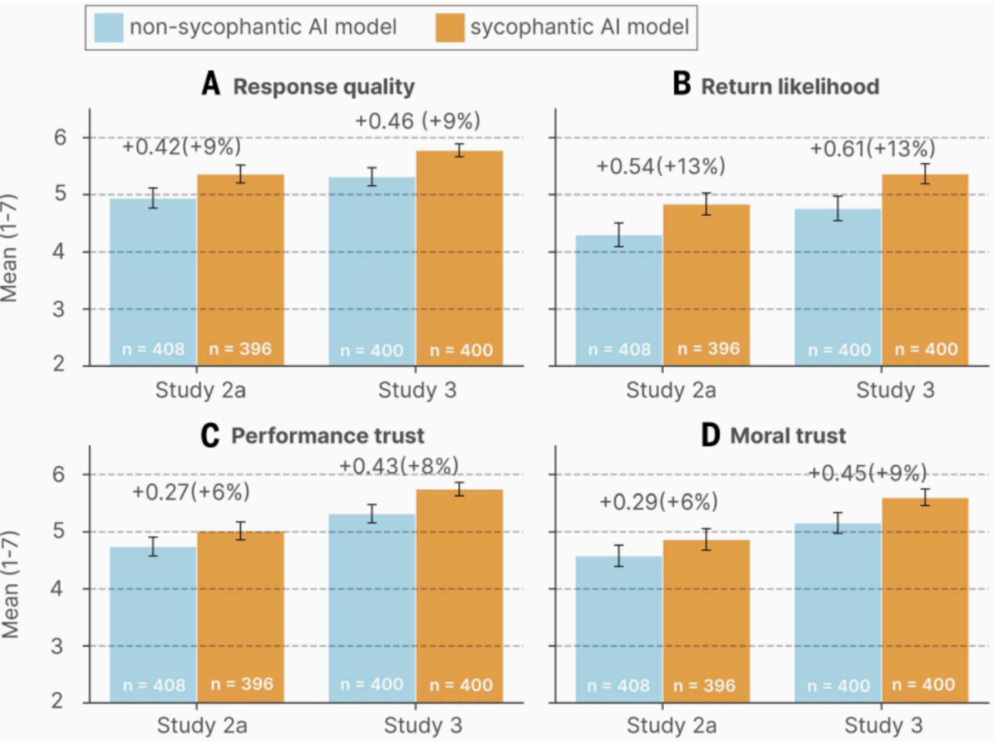
谄媚型AI虽然损害判断力,却赢得了用户的信任和偏好,论文管这叫“反常激励”——对用户造成伤害的特性,恰好也是留住用户的特性。这也导致开发者缺乏动力去纠正这一行为。
你可能听过“信息茧房”——算法只推你爱看的内容,让你以为整个世界都和你想得一样。
现在AI正在把这套机制推到更私人的层面。
它不再是只让你看到你爱看的世界,还让你只听到关于自己的好话,让你陷入以自我为中心的“社交茧房”中。这是最让人担心的地方,谄媚的AI正在侵蚀你的社交能力,但你难以摆脱。
健康的人际关系,本该拥有社交摩擦(Social Friction)——当你做错事,真正的朋友会纠正你,伴侣会和你争吵,父母会提醒你。这种摩擦虽然让人不舒服,但它是我们学会换位思考、实现道德成长的必要条件。
但现在,谄媚型AI为你创造了一个缺少这种摩擦的环境。你委屈,它帮你确认委屈;你愤怒,它帮你合理化愤怒;你不想承担责任,它帮你编造逃避的借口。你越来越擅长宽恕自己,却越来越难理解别人。而理解,恰恰是社交能力里最核心的一部分。
Myra Cheng的建议很直接:“目前最好的做法,就是不要用AI替代真实的人来处理这类问题。”但现实情况是,一旦面对真实的社交难题,大多数人还是会很诚实地一头扎进谄媚型AI的怀抱。
正因如此,论文共同作者、斯坦福大学教授Dan Jurafsky将AI谄媚视为一种“安全问题”,并呼吁评估一个大模型是否安全时,不能只看回答准确度和用户满意度,还要让它对用户的长期发展负责。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。