2026-05-29 23:10

速览
本文来自微信公众号: 01Founder ,作者:一直在路上的Max
昨天,大名鼎鼎的Claude 4.8发布了。
科技圈照例是一片欢呼。
看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
但如果你去一线程序员的圈子里转转,会发现大家极其冷静。
很多人尝鲜之后的体感是:写个单点代码确实强,但一旦把它接入真实的业务系统,让它去排查个稍微复杂点的线上Bug,
它依然会卡壳、兜圈子,甚至一本正经地胡说八道。
这就引出了当下AI行业最大的一个魔幻现实:
大模型的跑分越来越高,但在真实的干活场景里,大家总觉得它们像个高分低能的应试生。
这个其实很简单,因为很多人没搞明白,会修单点代码和会在系统终端(Terminal)里排查故障,根本是两个维度的生存能力。
遗憾的是,现在的绝大多数大模型,依然被牢牢困在考场里。
PART.01
做题家干不了真活
THUMB
STOPPING
要想弄明白这些估值千亿的模型为什么不好用,得先回到过去两年的历史里,看看那些曾经决定大模型生死的榜单,到底在测什么。
在人工智能狂飙突进的前半段,整个行业其实是陷入了一场声势浩大的应试教育。
那时候,科技巨头们用来证明自己比别人聪明的工具,是几个著名的静态代码榜单,比如早期的HumanEval,以及名噪一时的SWE-bench。
这个游戏的规则非常古典:
题库是既定的,给你一段来自于GitHub开源仓库里的代码,明确告诉你这里有一个Bug,或者需要增加一个具体的功能,
请大模型生成一段代码补丁。

明白人都知道,这就是驾校里的科目二考试。
场地是画好白线的,没有行人,没有加塞的社会车辆,连风向和摩擦力都是设定好的。
更残酷的现实是,当所有人都知道考卷长什么样的时候,内卷就不可避免地发生了。
各大厂商没日没夜地把海量的高质量代码、测试集、甚至是变种的考题喂给模型。
在庞大算力的堆叠下,只要环境是无菌的、上下文是给全的,AI们都能穿上长衫,写出极其工整的八股文。
但真实世界的底色,往往是荒诞和混乱的。
随便走进一家运转了超过两年的互联网公司,去看看支撑他们几百亿营收的底层IT系统,那从来不是什么逻辑严密的艺术品,而是一座座经历了无数轮业务迭代、被无数离职员工缝缝补补的数字废墟。
行业里有个不太文雅但极其精准的词来形容它——
屎山代码。
在这个迷宫里,跑着成千上万个微服务,有些服务连最初写它的人都已经转行去卖保险了。
没有最新版本的探针,没有详尽的说明文档,甚至连抛出的报错日志都有可能是系统底层的陈年Bug误报的。
当一个习惯了在无菌球体里做物理题的状元,被突然剥夺了考纲,赤身裸体地扔进这种没有标准答案的废墟里时,脑子瞬间宕机是它唯一的宿命。
PART.02
用户不是傻子
THUMB
STOPPING
商业世界的法则是冷酷的。买单的企业老板和投资人并不都是傻子。
当老板们花着每年几百万的订阅费,请回一群只会纸上谈兵的理科状元模型。
却发现服务器宕机时,依然需要半夜打电话把睡眼惺忪的运维工程师叫起来排查问题,资本的耐心就开始耗尽了。
风向大概是从2025年的下半年开始彻底转变的。
大家悄悄把以前奉为圭臬的卷子撕了,换成了车间里沾满油污的扳手。
整个大模型评测行业,开始了一场惨烈的脱虚向实。
为了挽回颜面,早期的标杆SWE-bench赶紧推出了Pro和Verified等进阶版本,试图把那些脱离实际的短代码题目删掉,转向更长程的软件工程测试。
但这还不够。
为了测试AI到底能不能像一个真正的打工人那样解决问题,行业里冒出了一大批非常刁钻的新榜单。
比如OSWorld-Verified,它不再让你写代码,而是盯在电脑桌面上,看AI能不能像人类一样,自己挪动鼠标、点开浏览器、拖拽文件去完成一个跨软件的任务。
比如Terminal-Bench 2.1,它直接把AI关进黑乎乎的命令行终端里,只给一个闪烁的光标,看它会不会自己敲写Linux命令去排查底层逻辑。
甚至还有一个名叫Humanity's Last Exam(人类终极考试)的变态榜单,专门为了榨干大模型的极限推理和多学科工具调用能力而生。
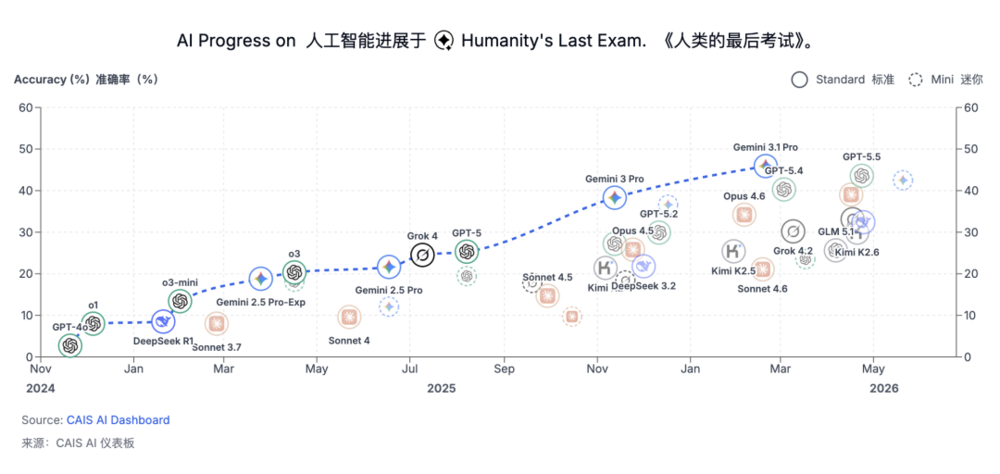
从发考卷到进车间,这些新榜单的核心逻辑只有一个:不再看你的语法有多漂亮,只看你能不能在没有提示词保姆的情况下,自己走完泥泞的最后一公里。
而在这场砸碎考场运动中,走得最决绝的,是前几天刚刚发布的一个新榜单。
IBM软件创新实验室和Artificial Analysis联合推出了一个全新的基准测试:ITBench-AA。
在这张考卷面前,过去所有的荣耀都不值一提。
PART.03
谁在裸泳,谁在干活?
THUMB
STOPPING
ITBench-AA不相信八股文。
它甚至连前置提示都不给,直接把大模型踹进一个真实模拟的企业级Kubernetes(K8s)集群里。
对于不在IT圈的人来说,可能很难理解K8s集群意味着什么。
你可以把它想象成一个拥有几万个集装箱、几十台塔吊同时运作的超级码头。
这里面任何一条网线的阻断、任何一个内存的溢出,都会引发灾难性的连锁反应。
测试方会人为搞死码头里的一个微服务。然后冷冷地告诉AI:
系统瘫痪了,你自己看着办。
在这里,模型必须扮演一个资深的SRE(站点可靠性工程师)。
它需要自己打开控制台,自己敲下kubectl相关的命令,去查看Pod的状态,去翻阅几千行的冗杂日志,去追踪微服务之间的调用链路,最后找出导致崩溃的真正原因。

最体现这个榜单残酷商业逻辑的,是它的评分标准:
采用全量召回下的平均精确率。
用大白话说就是,如果一场雪崩是由三片雪花引起的,你找到了两片,依然是0分。
一分同情分都不给。
因为在真实的商业世界里,问题不解决闭环,服务器照样宕机,用户的资金照样会受损。
只有在这种没有任何安全网的荒野求生里,你才能看出谁在裸泳,谁在真正干活。
官方公布的实战排名表,像是一份戳破了两年泡沫的做空报告。
前两名依然是全球帝国权杖的持有者:Claude Opus 4.7和GPT-5.5的顶配版。
在绝对的参数体量和算力压制下,老大哥的底子依然是最厚的。
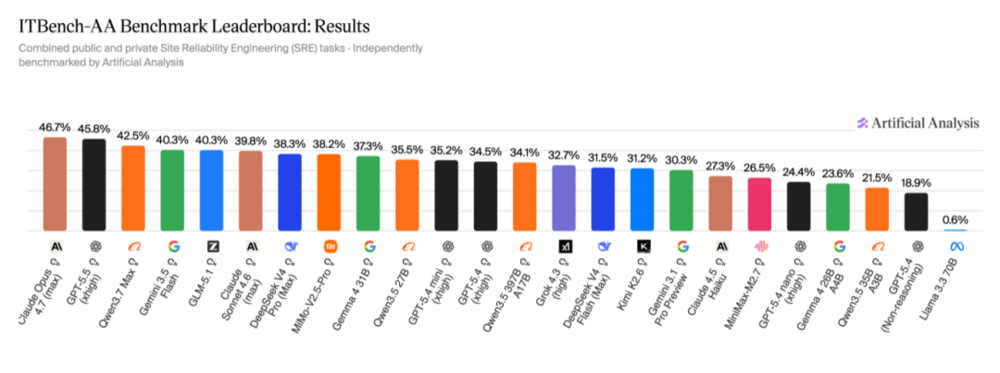
但在这份榜单的众多测试细节里,有些平时以高智商自居的顶级模型,吃相却极其难看。
比如名气极大的Gemini 3.1 Pro。
在这个没有考纲的黑盒子里,它像一个极度焦虑且手足无措的实习生。
面对系统的瘫痪,它慌不择路,在终端里疯狂输入各种探测命令。
根据官方的数据,为了找出一个Bug,它跟系统来回交互了足足83个回合。
在真实的机房里,这种被称为过度调查的行为,是一场比宕机更大的灾难。
一个没有方向的AI在脆弱的系统里瞎敲83次命令,足以把无关的配置改乱,甚至直接把核心数据库清空。
最终,它搞出了一堆误报,只拿到了不到30%的分数。
方向不对的时候,勤奋只是一种掩饰无能的动作。
PART.04
告别考场
THUMB
STOPPING
人类的注意力是极其脆弱的。
一个资深的工程师,在深夜的电脑屏幕前,盯着满屏闪烁的英文报错代码看上两个小时,视网膜就会开始疲劳,大脑会不自觉地遗漏关键的上下文线索。
人类需要抽烟、需要喝咖啡、需要睡眠。
当然,如果你翻开ITBench-AA这份榜单的全局数据,里面还藏着另一个极其残酷的真相。
哪怕是坐在王座上的第一名(Claude Opus 4.7),得分也依然没有跨过50%的及格线。
这意味着什么?
意味着在错综复杂的企业级IT废墟面前,今天所有的AI加起来,依然只是个步履蹒跚的学徒。
硅谷发布会上吹嘘的人工智能马上就能完全接管系统,
在冰冷的现实面前,被狠狠扇了一记耳光。
在真正的生产环境里,大模型距离独当一面,依然有极长的一段夜路要走,还有无数的错要试,无数的坑要踩。
但至少,这大半年来的榜单交替证明了一件事:行业的巨头们终于停止了自欺欺人。
大家不再沉迷于在无菌的考场里刷99分的假象,而是选择用Agent(智能体)的形态,去死磕真实世界里那些残缺、混乱、甚至无解的任务。
哪怕现在依然跌跌撞撞,哪怕最高分还不到一半,但这条从工具走向独立劳动力的大方向,终于对了。
PART.05
脱下大模型的长衫
THUMB
STOPPING
时代的分水岭,往往是在极其安静的时刻出现的。
Claude 4.8依然是一款无可挑剔的伟大产品。
在硅谷的聚光灯下,它像极了一份字体隽秀的满分考卷。
但属于考卷的时代,正在不可挽回地远去。
因为大厂机房里那些长满青苔的屎山系统,从来不相信西装革履的聪明人。
人工智能的下半场决战,早已不是一场比拼小数点后几位分数的算力游戏。
它的残酷在于,谁能率先脱下那件体面的长衫,换上沾满油污的劳保鞋,走进没有标准答案的黑框终端里,去干最脏、最累的活。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。