2026-05-30 10:56

本文来自微信公众号: 汽车之心 ,编辑:汽车之心,作者:周彦武,原文标题:《比亚迪璇玑 A3 拆解:车企开始争夺 AI 芯片定义权》
过去几年,中国智能汽车行业有一个固化的认知:先进制程来自台积电,高阶架构属于英伟达。而真正有能力自研芯片的,则只有蔚来、理想和小鹏等少数新势力。
5月28日,随着比亚迪发布中国首款4nm智驾芯片璇玑A3,这个认知开始被打破。
对这颗芯片来说,真正值得关注的,不是4nm制程本身,而是另一件事:越来越多车企,正在争夺下一代AI芯片的定义权。

01
比亚迪真能自己造4nm芯片吗?
目前,全球能够量产5纳米以下芯片的晶圆厂,仅有三家,分别是:三星、台积电和英特尔。
中国目前最先进的是中芯国际的7纳米,靠DUV多重曝光能勉强实现,但工艺复杂、良率低、成本高。
众所周知,ASML的EUV光刻机对华出口被荷兰政府叫停。没有EUV,5纳米以下制程理论上走不通。
比亚迪拥有5座晶圆厂:
成都晶圆厂:位于成都市双流区(原紫光成都存储器基地改建),是国内规模最大、专注车规级产品的12英寸晶圆厂。
济南晶圆厂:基于比亚迪收购济南富能半导体后的扩产项目,主要布局8英寸晶圆产能,是比亚迪实现车规级芯片垂直整合的关键基地。
宁波晶圆厂:依托宁波保税区升级改造的重要半导体项目,具备年产24万片的产能。
深圳及其他基地:作为研发大本营及早期晶圆与封测基地,涵盖从Wafer划片、晶圆测试到成品测试的完整配套。
其中,济南、宁波、深圳几座厂主要生产功率半导体元件。真正可能具备逻辑芯片能力的,只有成都工厂。

如果比亚迪这款高算力芯片是自己生产的,只有可能是成都工厂生产的。
成都工厂是比亚迪在2023年1月以15.9亿人民币收购得来,原本是计划生产3D NAND存储器的,与逻辑类芯片差异较大。
3D NAND是一种通过在垂直方向堆叠存储单元(Cell)来大幅提升存储容量的闪存技术,目前主流工艺的物理线宽(纳米)通常在30nm至50nm之间。
相比于平面(2D)闪存,3D NAND不再一味追求缩小平面尺寸,而是通过增加「层数」来获取更大的单颗芯片容量。
也就是说,它的工艺是30纳米到50纳米,如果转型做4纳米,工厂的设备需要全部更换,代价很大。
更符合现有产业条件的推断是:璇玑A3大概率由台积电代工,工艺节点很可能是N4C。
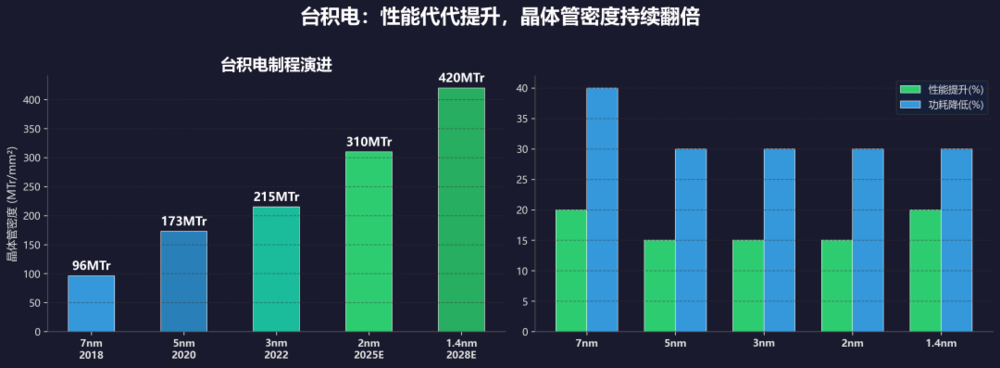
2024年初,台积电推出了N4C工艺,虽然号称是4纳米工艺,但其实是5纳米家族的衍生版,专为高性价比主流市场打造。
通过精简掩膜层数和优化基础IP,N4C相比于N4P可将裸晶(Die)制造成本降低达8.5%,同时保持设计兼容性并提升良率。
对于首次进入这种先进制程的车企来说,这是一条相对务实的路。
当然,公开信息目前尚无法确认代工方身份,以上为基于产业逻辑的推测,并非结论。
02
制程之外,更重要的是什么?
对数字类芯片来说,制程的优势是压倒性的。
晶体管密度,决定同样面积内能塞进多少晶体管。晶体管越多,算力就越强,存储容量就越大。
同样的面积意味着同样的成本,谁的工艺更先进,谁就可以以同样的成本取得更高的性能。
同时,制程越先进,意味着漏电越低,功耗自然更低。
但制程只是门槛,真正决定胜负的,是架构。
先看一张参数对比:
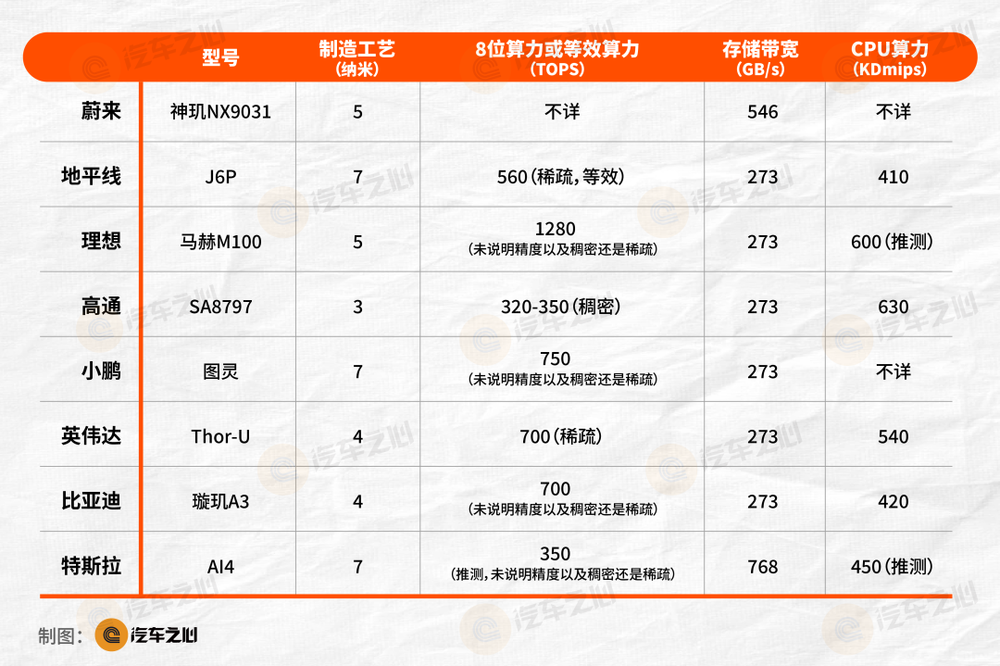
这张表格有一个问题:各家算力的统计口径并不统一。
稀疏算力基本是稠密算力的两倍。英伟达和高通给出的是真实MAC阵列算力,含金量最高。其余厂商大多是等效算力,直接横向比较意义有限。
如上图,CPU是调度中心,AI或NPU只是工具,CPU算力重要程度不比AI算力低,高通遥遥领先,马赫M100则堆了24核心A78AE,又是5纳米,运行频率可以高于7纳米,仅次于高通,但成本较高。
在这里,蔚来值得单独一提:2022年底蔚来发布的神玑NX9031芯片,存储带宽546GB/s,依然是国产最高。
比亚迪则用16核心取得420K DMIPS的成绩,比地平线的18核心还高。
从参数推断,比亚迪大概率用了比较新的ARM Cortex-X720架构,运行频率2.6GHz。
03
世界模型时代,
通用GPU不够用了
过去一颗英伟达Orin可以用五年。
现在半年一变:世界模型、VLA、DiT、端侧Agent轮番登场。通用GPU开始不够用了。
为什么?因为汽车场景的数据,天然是稀疏的。
从比亚迪的功耗和算法利用率两个关键描述看,一种更符合产业逻辑的推测是:比亚迪在NPU架构上押注了小核心路线。
汽车行业与其他领域AI最大不同,是汽车行业的数据非常稀疏(即包含大量的0),因为有大面积几乎没有纹理特征的天空、路面阴影、远处背景等等,大量信息其实是无效数据。
像素值接近0,乘以权重还是0,根本不需要计算。传统大核心GPU/NPU不管这些,照算不误,这相当于在做无用功。
但汽车场景偏偏是稀疏数据的重灾区。
这是新兴车企集体下场造芯片的底层原因之一——买来的芯片,天生就在浪费算力。
早期的解决方案是权重剪枝处理:提前对零值位置编码,让硬件不必重复识别。
这在权重固定的时代还能用。
但Transformer时代不同。
由于整流线性单元(ReLU)激活函数,调频(feature map)中包含大量零值。
问题在于,这些零值的位置不是固定的,它随输入数据实时变化。
这需要专用硬件,来实时感知稀疏结构,动态跳过无效计算。这比权重稀疏复杂得多。
更麻烦的是,当芯片使用非ReLU激活函数(如sigmoid、leaky ReLU、tanh)时,NPU无法获得有效的性能增益。
其次,是刚刚兴起的世界模型背后的DiT架构。
DiT和当前主流Transformer架构需求差异极大:
串行结构明显,需要多次迭代;
对标量和向量算力要求高;
存储碎片化严重,对存储带宽压力极大。
更关键的是,在Batch=1的真实驾驶场景下,扩散模型跑在GPU上的利用率不到15%。这个效率非常低,需要近似CPU的小核心来对应。
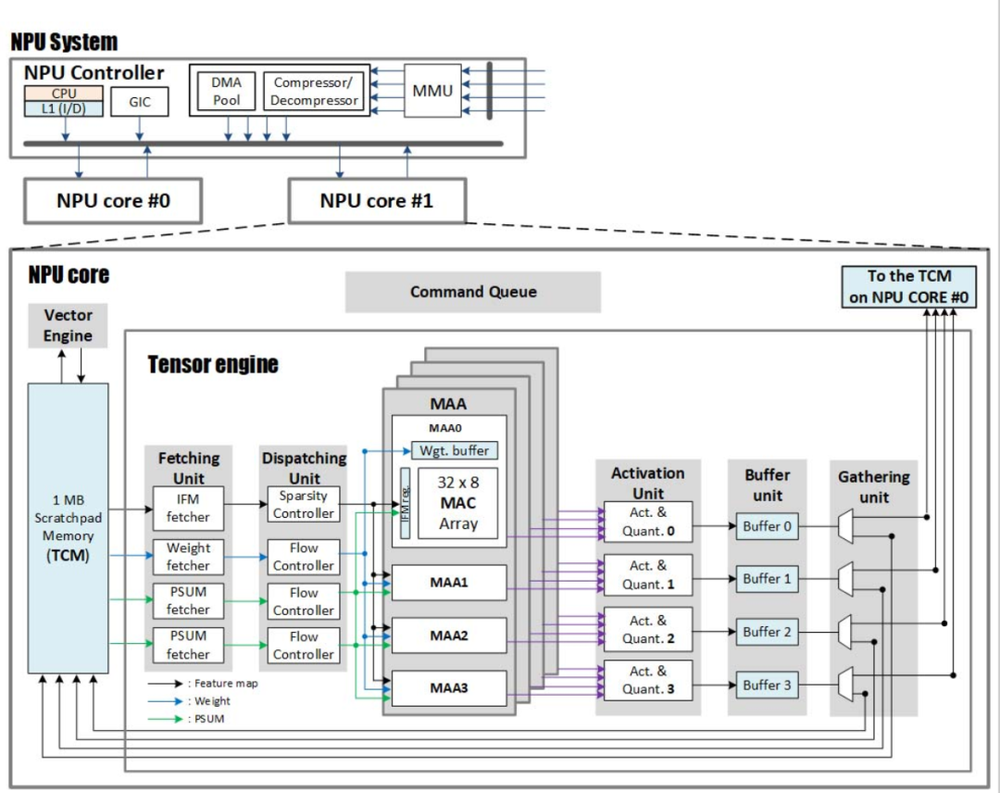
基于公开参数推测,比亚迪璇玑A3的NPU可能采用了这样的设计思路:
每个核心包含张量引擎、矢量引擎和紧耦合片上存储,配有专门的稀疏控制器,在数据发送端就过滤掉零值,避免无效搬运。
整体倾向于多核心、小阵列的分布式结构,而非一个超大MAC阵列。
其32*8的MAC阵列,是比较典型的小核心架构。
小核心实际就是多核CPU,特斯拉的Dojo最为明显,实际就是384核心的CPU,每个CPU是8路解码2路线程4路标量和集成寄存器的超标量CPU。
英伟达的CUDA Core也可以勉强算小核心。
小核心的优势很明显:
高度灵活,对任何shape的数据都能轻松处理;
Batch=1也保持很高的利用率(GPU/NPU要1024 batch才能有90%利用率);
天然适配Decode、MoE expert路由、可变长KV cache也就是Agentic AI最需要的长上下文。
原生支持非结构化细粒度稀疏。官方报告显示:75%稀疏下相对稠密基线可达约2.5倍实际加速。
但小核心也是有代价的。
每个小核都要付出独立取指、译码、寄存器堆、控制逻辑开销。
在同样工艺、同样算力下,纯小核设计比Systolic array(脉动阵列)多付出2至5倍的芯片面积,意味着成本也会提高至2至5倍。
另外,软件生态和编译器工具链也远不如GPU成熟。
以上,是一些大厂不愿意做小核心的根本原因:成本太高,推广太难。
车企愿意押注,是因为他们只需要让自己的算法跑得好。
这是两种完全不同的生意逻辑。
过去,车企做芯片的逻辑是降本和供应链安全。
现在这个逻辑完全变了,算法迭代太快,世界模型、VLA、端侧Agent轮番登场,芯片定义权决定了谁能先跑通下一代架构。
当智驾开始像大模型一样高速迭代,芯片已经不再是「零部件」,而是算法公司的基础设施。
车企自研芯片,就是在争夺下一代计算范式的话语权,这才是比亚迪璇玑A3真正的产业意义。不是中国车企造出了4纳米芯片,而是:主流派也下场了。
越来越多的玩家加入自研芯片的行列,大模型时代,技术路线升级变化很快,车企为了快速迭代,不得不自研芯片。但效果如何,现在下结论太早。
但有一点可以确认:这场战争,已经不再只属于少数玩家。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。