2026-06-01 15:04

本文来自微信公众号: APPSO ,作者:发现明日产品的,原文标题:《英伟达掀桌,Windows 终于迎来真 AI PC》
过去四十年,这个市场的基本分工相对稳定:微软定义操作系统和软件入口,Intel与AMD长期把守x86处理器平台,英伟达则从图形计算出发,后来又把AI加速推到更高的位置。
而就在黄仁勋刚刚结束的2026年COMPUTEX主题演讲上,英伟达沿着AI基础设施这条主线,进入更多产业的核心环节。
除了GPU、AI工厂、物理AI等老生常态的话题,还有被微软和ARM提前预热、打着「A new era of PC」旗号的RTX Spark。所有产品背后,都围绕同一个关键词展开:
Agent、Agent,还是Agent。
联手微软,英伟达要重新定义个人PC
在Agent(智能体)叙事里,PC被放到了一个新位置。
四十年来,Windows、开放BIOS、芯片组、驱动、多媒体API一起塑造了个人计算。Windows 95让PC从企业设备变成消费电子产品,几乎每个人都需要一台电脑。
现在,微软和英伟达将重新定义AI PC,目标是要让PC原生运行智能体,让个人电脑从传统应用入口变成个人AI平台。
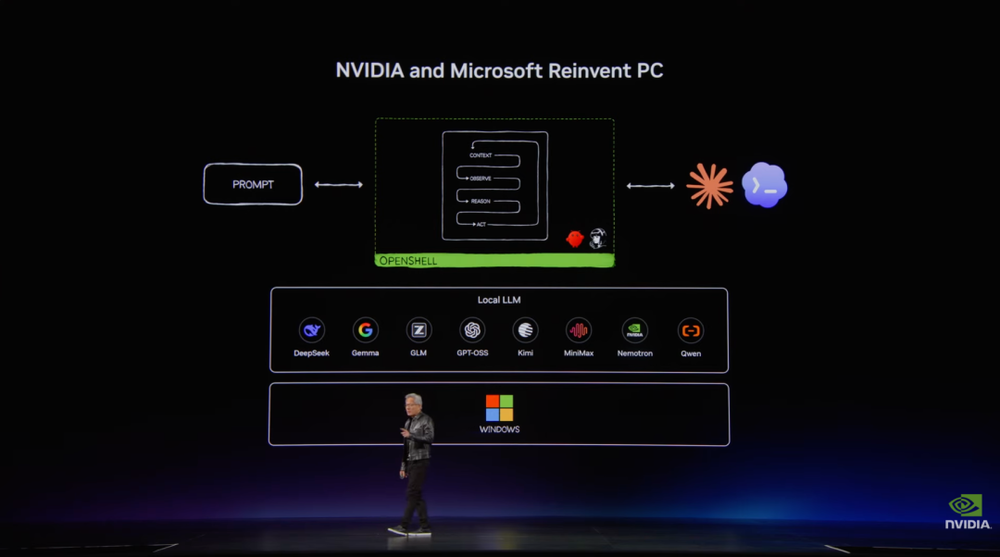
今天推出的英伟达RTX Spark处理器是这套新PC体系的核心。

它搭载Blackwell RTX GPU,FP4 AI性能达到1 petaflop;CPU部分是与联发科合作定制的20核Grace CPU;内存为128 GB统一内存,并通过NVLink C2C提供600 GB/s带宽。软件层面,完整栈包括CUDA、TensorRT、NVFP4、RTX Ray Tracing、DLSS、Reflex和G-SYNC。

在产品形态上,英伟达把RTX Spark放进了更接近主流Windows PC的尺寸里:
笔记本厚度可做到14毫米,重量约3磅,覆盖14英寸到16英寸机型;机身采用精密加工铝合金,屏幕部分则配备色彩准确的tandem OLED,并支持NVIDIA G-SYNC,既服务创意工作,也兼顾游戏和高帧率视觉体验。
换言之,RTX Spark面向的场景不只是端侧语音助手或轻量办公场景,它试图把部分数据中心AI能力、游戏图形能力和专业创作能力,放进个人电脑形态里。
黄仁勋说,这台电脑要运行「所有东西」。传统Windows应用要能跑,CUDA软件栈要能跑,图形工作流、数字生物、地震处理、天体物理、基因组学和AI应用也要继续运行,它既可以连接本地模型,也可以连接云端模型。
在现场演示视频中,用户给出场地、草图、风格参考和需求后,运行在RTX Spark上的智能体会调用Rhino完成建筑与室内方案设计,并导入Blender结合Flux 2生成多角度渲染图,过程中用户可随时修改。
演示传递的信号不言而喻,PC将从人手动操作软件转向智能体围绕目标调度工具,而典型案例是,Adobe Photoshop、Premiere等应用也正为RTX Spark优化,并通过MCP接入本地智能体,成为自动化工作流的一部分。
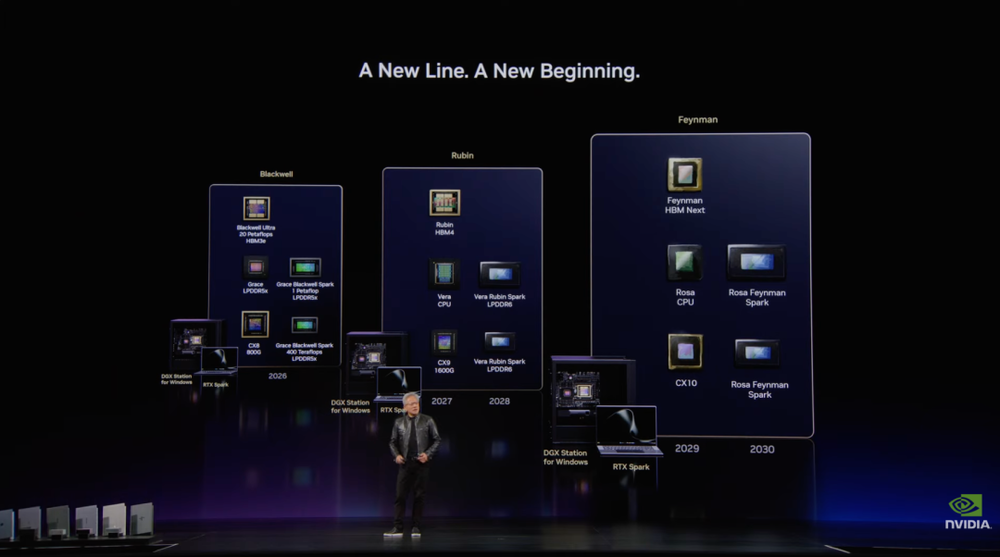
RTX Spark只是新PC产品线的起点。黄仁勋还展示了三种形态:笔记本、台式机和工作站。它们共同兼容Windows、CUDA和AI软件栈,面向的使用场景各不相同。
笔记本对应移动办公、游戏和创作。
它可以本地运行Nemotron 3 Ultra,也可以连接Claude、Codex或其他云端模型。台式机更像家庭里的个人AI主机,可以24小时运行智能体,连接笔记本、显示器、摄像头、安防系统、家电和其他设备。
工作站面向模型开发者和智能体开发者。
DGX Station for Windows配备748 GB内存、20 petaflops算力和8 TB每秒内存带宽,可以在桌面环境中运行万亿参数模型。开发者可以在本地完成模型开发、调试和测试,再部署到云端。
黄仁勋把这一变化类比为手机变成智能手机,打电话已经不再是今天智能手机最重要的功能。他认为,10年后的PC也会经历类似变化。它会从打开应用、点击和输入的工具,变成家庭和个人工作流里的AI超级计算机。
而我们能感受到最直接的变化,大概就是未来的Windows电脑,或许会是一台真正的AI Agent电脑。
对于想在本地跑LLM、又需要大内存和较强AI算力的人来说,RTX Spark的出现,可能会成为除Mac之外的另一个选项。
有用AI时代到来,一切为Agent而生
如果把过去两年的行业变化归纳为一句话,那就是有用的AI(useful AI)已经到来。而Agentic AI的第一批应用场景,正是软件开发。
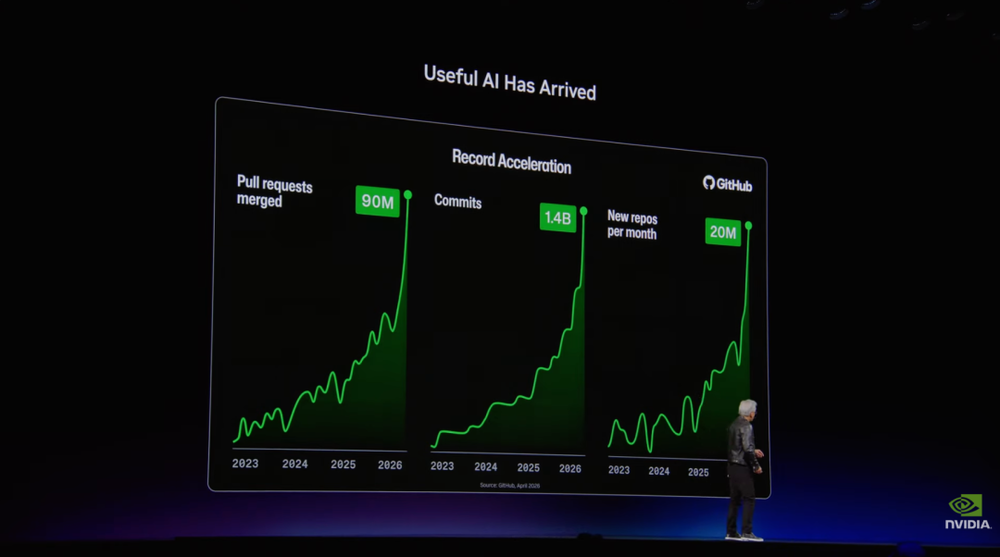
全球有3000万到4000万职业开发者,GitHub commit数量也在持续增长:2023年约3亿,2024年约4亿,2025年前几个月达到5亿,2026年前几个月接近翻了三倍。
黄仁勋借此反驳了「AI会减少就业岗位」的说法。在他看来,AI提高了工程师的产出,企业反而更愿意招聘更多工程师。究其原因,同样的人力成本可以创造更高生产力,软件开发的价值也会继续扩大。
更深层的变化发生在应用形态上。
过去的软件由应用、代码和操作系统组成,但智能体时代的计算方式则换了一套流程:用户给出目标,模型理解意图,运行环境调度流程,工具执行任务,记忆系统保存上下文,最后产出结果。
整个过程包含观察、理解、推理、规划、行动和工具调用。
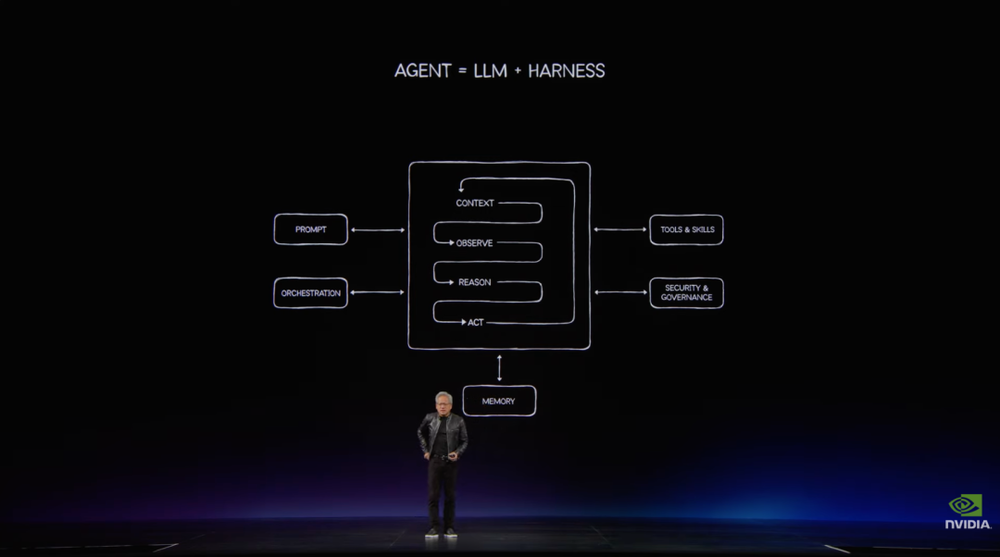
在这个框架下,LLM只是Agentic系统中的「思考模块」。完整的智能体还需要harness,也就是调度和编排层;需要浏览器、电子表格、数据库、编译器、CAD软件和数据处理引擎等工具;也需要短期记忆、长期记忆和运行环境。而这种LLM+harness=Agent,再加工具、记忆和运行环境的模式将会是未来十年的应用基础。
智能体成为新的应用形态后,支撑智能体运行的计算底座也要重新设计。
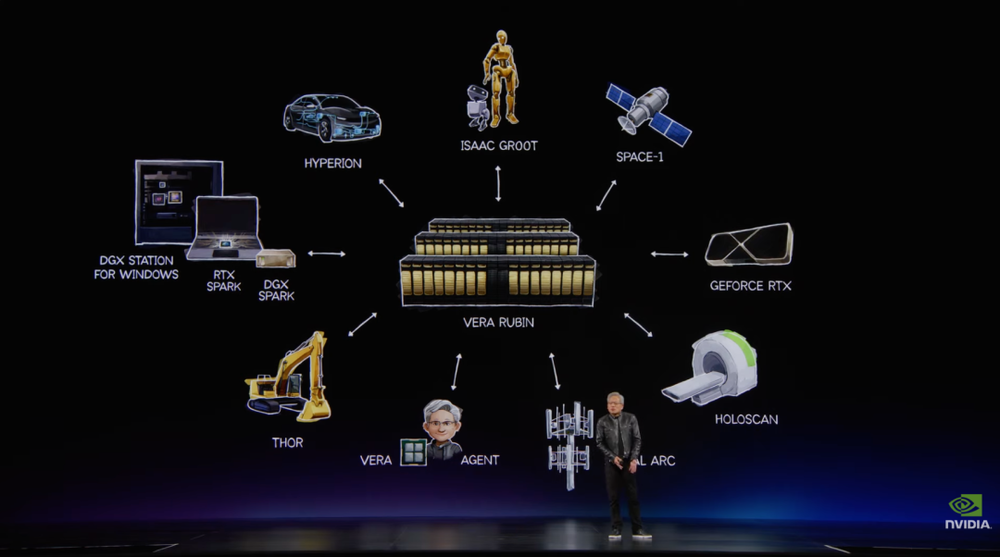
发布会上,黄仁勋宣布,英伟达下一代AI超级芯片平台Vera Rubin已进入全面投产阶段。它是英伟达迄今规模最大的POD级平台之一,也是面向Agentic AI设计的新一代AI工厂核心系统。

Vera Rubin由Rubin GPU、Vera CPU、NVLink 72、BlueField、ConnectX 9、Spectrum X以太网、存储处理系统、安全处理系统和完整软件栈共同组成,目标是支撑AI工厂级别的系统运行。
它面向的是智能体从输入到执行的完整流程。
智能体处理提示词、理解上下文、推理规划、调用工具、访问数据库、运行代码和检索长期记忆时,会同时牵动GPU、CPU、网络、内存、存储和安全系统,因此Rubin GPU负责主要计算,Vera CPU负责调度和数据管线,BlueField 4处理安全隔离与存储,Spectrum X负责大规模联网。
Vera Rubin之后,黄仁勋还单独讲了Vera CPU。
在他看来,过去的CPU主要服务于人类用户和传统云计算租赁,计算资源按核心、按时间出租,响应速度以秒为单位衡量。但智能体的运行节奏完全不同:
它们会频繁调用工具、访问数据库、运行代码、检索记忆,每一步都要求更低延迟。
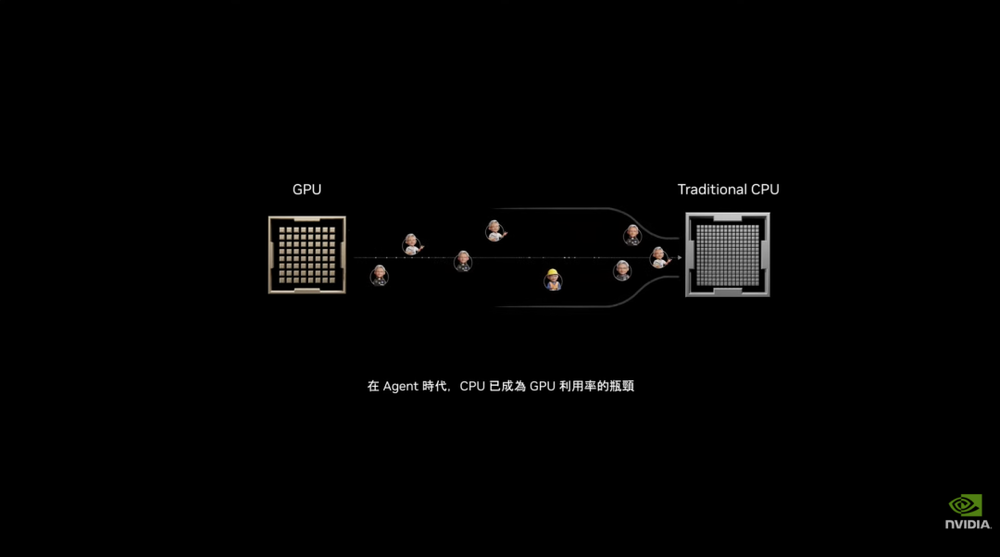
这也让CPU在AI工厂里的角色变得更关键。智能体数量越多,工具调用和数据流转越频繁,CPU越容易成为瓶颈。尤其是GPU已经成为AI工厂最昂贵的资产,CPU的延迟和吞吐会直接影响GPU利用率,最终影响Token产出。
Vera CPU的设计逻辑正在于此。
过去CPU为人服务,Vera CPU则面向数量远多于人类的智能体。它采用自研Olympus Core,重点放在单线程性能、核心间带宽、总带宽和能效。它有神经分支预测器、10路解码引擎、大型乱序执行引擎和先进预取机制。内存部分采用LPDDR5X,并支持多错误校正。

这颗CPU包含88个Olympus核心,使用单片网格结构连接,没有把核心分散到多个chiplet上。这样的设计减少了跨芯片通信带来的延迟。它支持PCI Express Gen 6,内部通信能力达到3.6 TB每秒,内存带宽达到1.2 TB每秒。
相比x86 CPU,Vera在部分场景中峰值内存延迟降低40%,智能体sandbox性能达到1.8倍,SQL性能达到3倍,实时流处理性能达到6倍。
Agent是新的工作负载,CPU的角色也随之变化。它不再只是云计算里可出租的通用核心,而是AI工厂里调度模型、工具、内存、数据库和安全系统的关键部件。
现在买电脑,是用来打造AI工厂
黄仁勋反复强调,AI的商业逻辑已经改变。过去算力常被视为成本,现在token是可以带来收入的单位。只要token能产生收入,算力就成了生产能力。
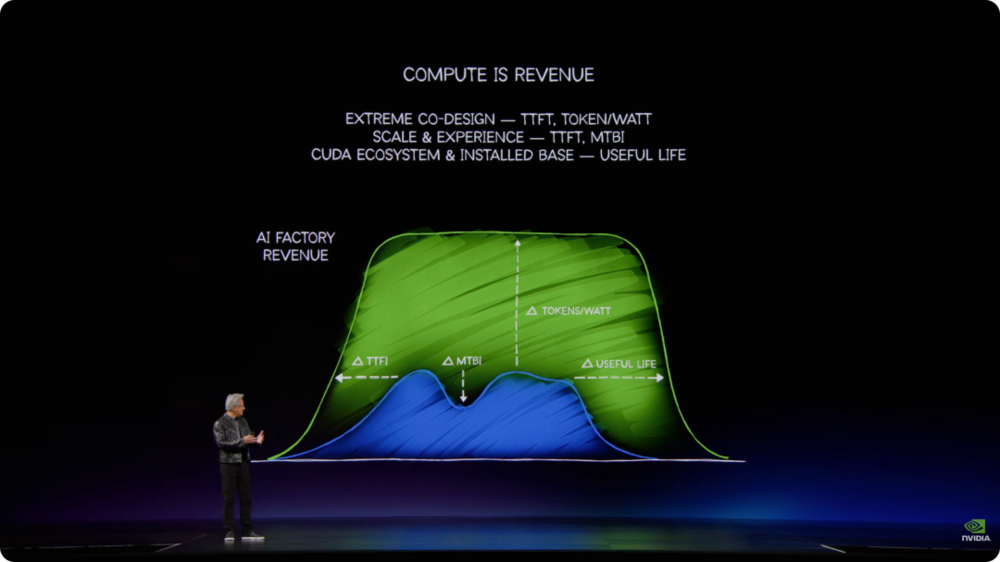
黄仁勋提到,未来1 GW级AI工厂的投资可能达到500亿、600亿美元,甚至进一步上升到800亿至1000亿美元。资本成本越高,系统上线速度、吞吐效率、可靠性和生命周期越关键。

RTX面向我们的GPU,DGX面向我们的系统,而如今,DSX则构成了整个基础设施的核心。
而NVIDIA DSX这套生态系统囊括了一大批的云服务公司和AI基础设施企业,包括CoreWeave、Nebius、Nscale、Naver Cloud等,以及服务的客户包括Cursor、World Labs、Revolut、Shopify、Google等等,帮助所有的企业用户用Token来获得收入。
硬件之外,企业如何真正用上智能体,是另一条线。
黄仁勋把企业构建智能体所需能力分为四类:模型、调度系统、工具与技能、运行环境。对应到产品上,就是Nemotron、OpenShelf、CUDA X libraries和AI平台。
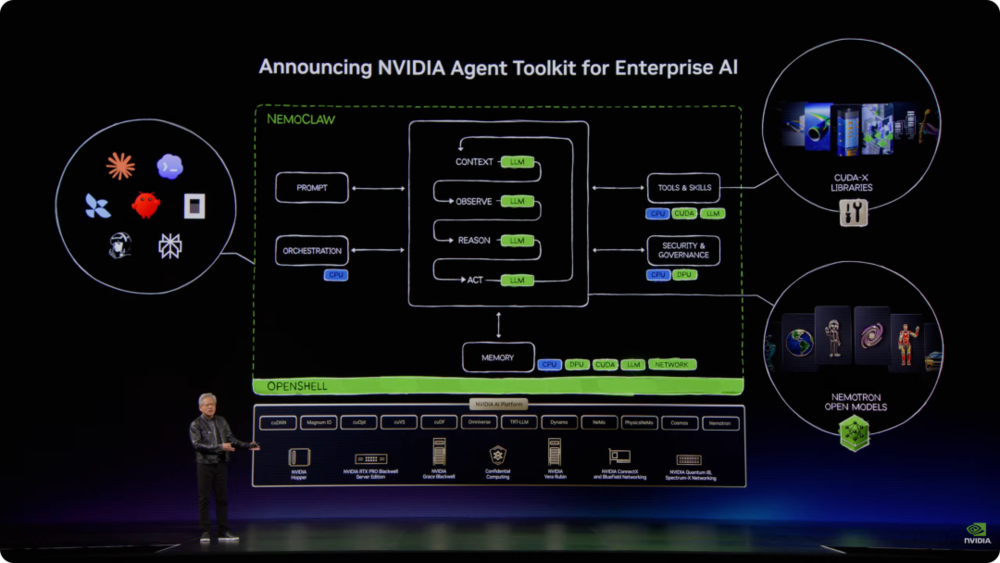
Nemotron 3 Ultra是此次发布的新开放模型。它采用SSM状态空间模型与MoE混合专家架构,目标是让模型跑得更快、推理成本更低。

按照现场说法,相比其他开放模型如Kimi K2.6、Qwen 3.5和智谱GLM 5.1,它速度提升5倍,整体运行成本降低约30%。
黄仁勋还提到,Nemotron 3 Ultra模型、训练脚本和训练数据都会开放,企业可以在此基础上加入自己的行业数据和专有知识。
演讲尾声,黄仁勋把全场内容重新收回到一个核心模式:模型、harness、工具、技能和运行环境。
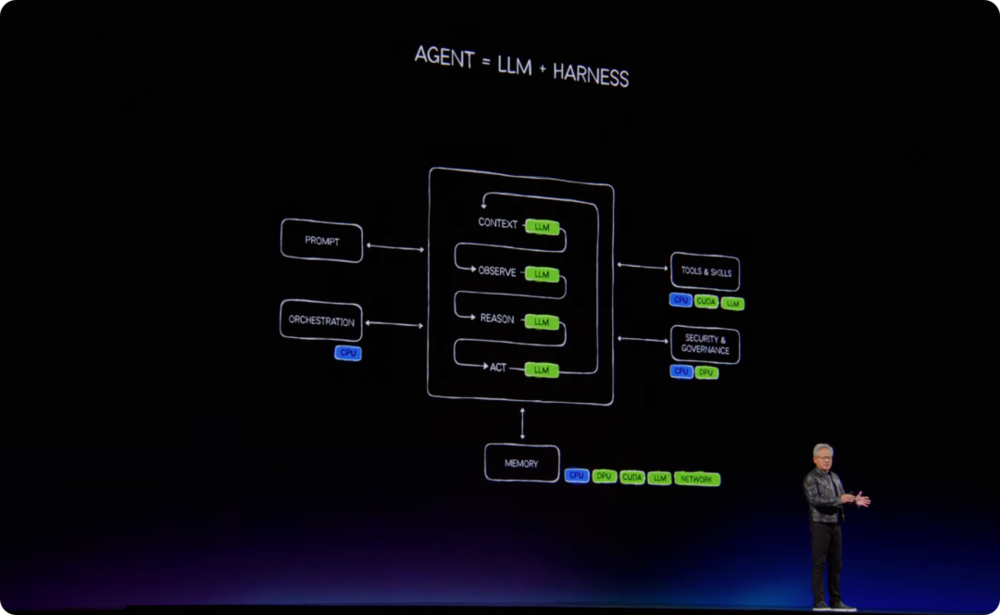
这套模式可以运行在云端,也可以运行在企业本地;可以运行在PC上,也可以运行在汽车、机器人、卫星、通信基站、工厂和边缘设备上。不同场景会使用不同模型、不同harness、不同工具和不同runtime,但计算模式是相同的。
云端需要Vera Rubin和AI工厂。PC需要RTX Spark和Windows智能体平台。企业需要Nemotron、OpenShelf和CUDA X工具链。汽车需要Alpamayo、Hyperion和自动驾驶runtime。人形机器人需要Isaac Groot、Thor、仿真和数据生成系统。
当我们把整场演讲连起来看,将近两个小时的超长发布,黄仁勋讲的主题已经超出常规新品发布。

AI PC和RTX Spark面向个人设备,把智能体带到用户桌面和家庭。Vera Rubin面向数据中心,承接大规模智能体负载。Vera CPU解决智能体调用工具和访问数据时的延迟问题。
DSX面向AI工厂建设,把电力、冷却、网络和运维也纳入系统设计。Nemotron、OpenShelf和CUDA X libraries面向企业智能体开发。Cosmos 3把智能体推进物理世界。Alpamayo 2和Hyperion面向自动驾驶,Isaac Groot则把人形机器人也放进同一套平台逻辑。
NVIDIA过去最核心的身份是GPU供应商,后来变成系统公司,现在又试图成为AI基础设施公司。
黄仁勋在这场大会想讲清楚的,也正是这件事:AI竞争已经从模型扩展到一整套计算体系,覆盖个人电脑、企业软件、数据中心和物理设备。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。