2026-06-03 19:34

本文来自微信公众号: 海豚研究 ,作者:海豚君
22年底ChatGPT横空出世以来,从算力(GPU)、存力(存储),指挥调度力(CPU)……AI已经带动了一个又一个的半导体超级产业机会、一个又一个的万亿美金市值公司。
如果说在AI基建中,还有一个板块尚待出现一个万亿市值“待爆帝”的话,海豚君接下来最为看好的就是AI时代的超级连接了。如果说算力解决了AI“智商”问题,存力解决了AI“记忆力”问题,那么运力要解决的就是如何将长、短期记忆“坐上火箭般的速度”高速出入脑力中心。
或者借用AI教皇黄仁勋的说法,随着算力、内存瓶颈的逐步缓解,能源又是一个十年级的持续难度,下一个核心卡点是AI时代网络的高速互联,因为传统云时代的网络基建完全无法匹配Agentic AI时代下,数万亿模型参数、混合专家(MoE)、局部激活下,对网络带宽的传输需求。
本篇,就接着AI网络传输速度下逐步切换的光电传输技术方向——CPO来探索一下AI时代的网络传输。海豚君对于CPO的研究分为:
一、什么是CPO,它真的能替代传统的铜连接吗?
二、它是否又能完全替代当前主流的可插拔光模块?
三、在此趋势下,产业内上下游公司的竞争格局又将如何变化?
在本篇文章中,我们首先对产业链的基本问题做一个梳理。
以下是详细分析
一、什么是CPO?
在传统数据中心架构当中,有一个重要的部件即“光模块”,它的作用是将光线传输过来的光信号转化为电信号传递给数据中心,或者将数据中心内产生的电信号转化为光信号并且传递给光纤,在数据传输中起到“桥梁”和“翻译”的作用。
从作用上讲,CPO(即共封装光学)架构当中,包含了传统光模块的功能,但有以下两个明显差异:
1、结构不同
传统的光模块是可插拔的,表面看起来就像家里网线端口上的水晶头,但CPO完全不同,它将负责光电转换的光引擎,和芯片(这里主要是交换机的ASIC芯片)直接集成在同一封装基板或者中介层上。
2、应用场景不同
光模块通常应用于机柜间(即Scale-out);而CPO既可以应用于机柜间,也可以应用于机柜内(Scale-up),应用于机柜间,替代的是传统的光模块,应用于机柜内,替代的则是目前主流的铜连接。
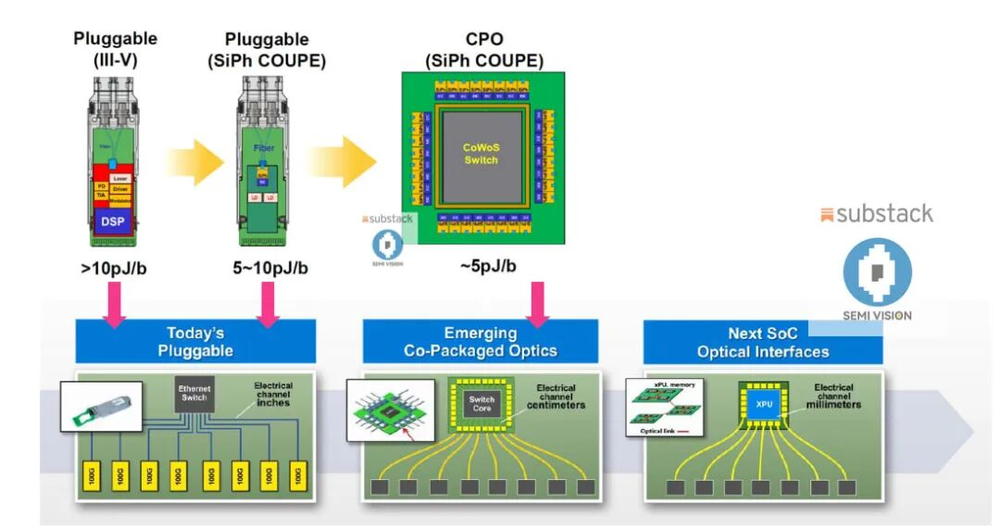
图:传统可插拔模式与CPO方案示意
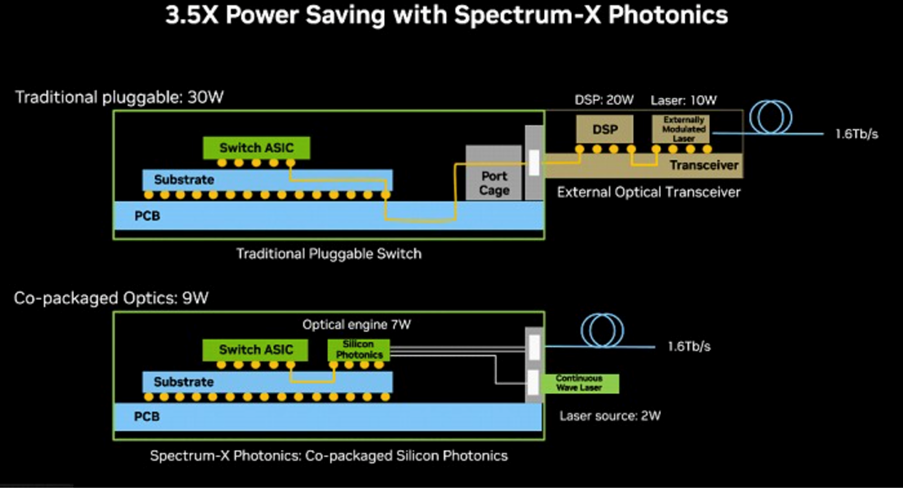
资料来源:GTC 2025,Dolphin Research
我们可以看到,近期无论是英伟达,还是博通,都在积极推动他们CPO交换机方案。
那么CPO技术为什么会得到如此重视呢?因为数据中心对算力需求持续提升,数据中心对数据传输的带宽需求也呈爆发式增长,且数据中心正在往超大规模算力集群的方向发展,那么在此过程中,旧有的传统数据传输技术会形成诸多阻碍:
1、带宽瓶颈
对于机柜间场景,由于传统交换机面板空间有限,而传统可插拔光模块尺寸又难以缩小,导致单台交换机能够提供的端口受限,无法支持越来越高的带宽要求。
目前可插拔模块最高可支持1.6Tbps单模块带宽,单个交换机面板最多可支持51.2Tbps带宽,未来有可能推出3.2Tbps模块,交换机最高支持102.4Tbps,这几乎已经达到可插拔光模块的极限。
2、信号完整性瓶颈
在机柜内场景,随着传输速率提升,如果使用传统的铜缆,那么电信号在长距离传输时会面临严重信号衰减和失真,并且传输距离也会越来越受限。
目前铜缆最高可支持1.8TB/s带宽(如英伟达的NVLink铜缆),且距离被严格限制在2米以内,但单GPU对带宽需求正在向3.6TB/s迈进。
3、散热和功耗瓶颈
随着传输速率提高,传统通讯链路的功耗大幅上升,同时散热也越来越面临困难。我们知道目前美国数据中心建设面临极大的能源障碍,所以功耗问题会带来显著的成本压力。
CPO理论上可以较好地解决上述几项问题,根据英伟达,应用CPO后功率效率可以提升3.5倍。
二、具体而言,数据中心的数据传输场景有哪些?
这里我们对数据中心在不同场景和不同环节中的数据传输技术路线进行拆分:
图:Scale-out和Scale-up示例
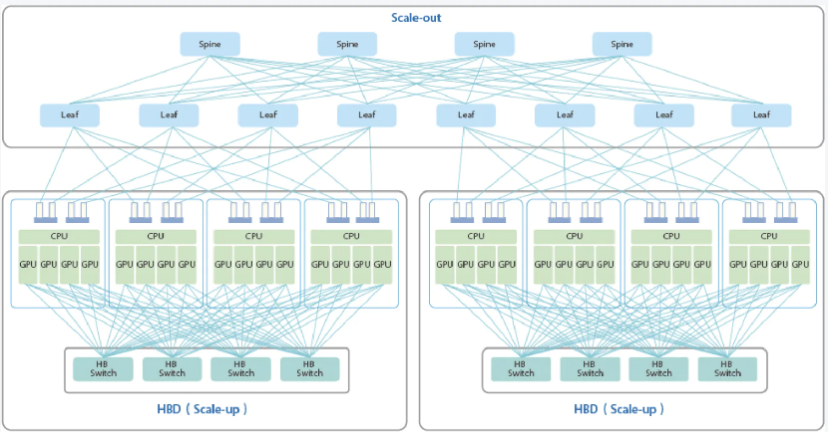
资料来源:NADDOD,Dolphin Research
1、Scale-up,主要涉及机柜内互联
主要涉及机柜内,尤其是服务器内的硬件互连,包括但不限于CPU、GPU、网卡、DDR内存以及硬盘之间的互连。
目前这部分连接主要以铜为主要连接介质,包括用来连接CPU、GPU以及网卡的PCle插槽以及内存插槽(PCB铜走线),SATA线等各类铜缆等。而CPO有可能颠覆目前的主流方案。
2、Scale-out,主要涉及机柜间互联
主要涉及机柜或者服务器以及交换机之间的互连。
这部分连接就需要以光作为连接介质了,目前主要以光纤和可插拔光模块为主要方案。同样,CPO是重要发展趋势,且比机柜内场景进展更快。
3、更进一步地,还有数据中心之间以及数据中心与外部的互连,这部分不是本文的讨论重点。
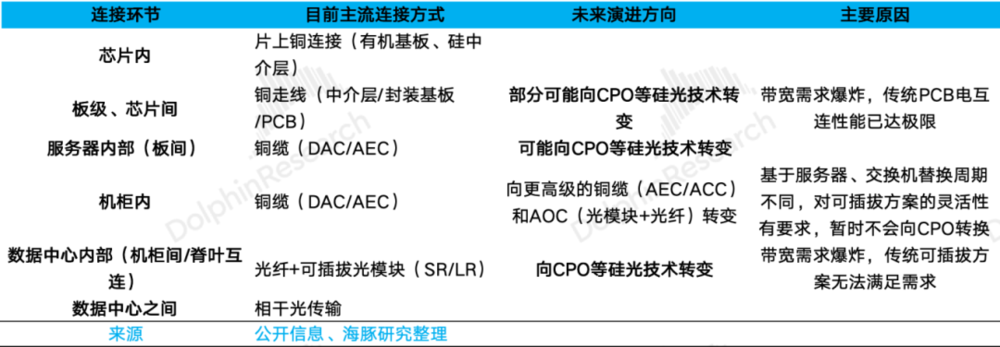
从巨头布局来看,CPO现阶段在场景上主要面向机柜间,但未来可能面向机柜内场景。
三、CPO目前还处在初步的推广阶段,面临的主要瓶颈是什么?
1、先进封装技术的成熟
从底层技术来看,CPO与诸如可插拔光模块这类传统方案相比完全不同。传统光电子零部件从生产技术上与广义的光电子元器件及模组差异不大,但CPO需要将光引擎封装到基板或中介层,主要依靠的却是先进封装技术如CoWoS。
与此同时,相对于我们通常所理解的先进封装,CPO也有所不同,因为它不只要集成电子集成电路,同时还要集成光子集成电路,那么这种异质集成需要通过诸如台积电COUPE技术进行混合键合。
问题在于,一方面,上述先进封装技术工艺难度极大,无论是英伟达还是博通,都依赖台积电产能,但产能是有限的,除此之外,包括所需的光耦和设备、混合键合设备、测试设备,以及ABF基板等材料的供应也可能存在障碍;
并且,现阶段上述先进封装技术,尤其是异质集成的生产良率还存在很大提升空间,导致成本远高于可插拔方案。目前台积电正努力提升先进封装良率,但仍需要一定的时间。
2、检修和维护问题
对于传统可插拔方案而言,由于它们是“可插拔”的,所以检修和维护很方便。但CPO完全不同,它的光电模块与基板、中介层甚至芯片直接封装在一起,那么检修和维护难度会显著大于传统方案。
但以上问题也是可以解决的,比如从设计上提高一定的容错率,或者在运营层面布局一定的冗余等等。
3、热管理问题
光引擎与芯片进行高密度封装,在运行时会导致局部升温明显,甚至超过激光器的耐受极限,所以热管理也是一个大问题。为了解决以上问题,需要引入更高效的散热方案,但这同样会涉及成本。
4、标准化问题
目前英伟达、博通等为了抢占市场先机,积极推出自己完整的独立的CPO交换机方案。但与此同时,行业标准(接口标准、封装标准等)还暂未形成,如此一来,上下游难以基于统一标准进行研发、生产和配置,这也是商业化推广的难点所在。
总之,可以看到,以上问题均存在解决方案,只不过要依靠技术的成熟、标准的制定等,但这都需要时间。
另一方面,从根本上讲,CPO技术在综合成本上需要形成优势。
那么这就延伸出一个问题:无论何种方案,成本总是核心考量因素,但除CPO外,也有其他更先进,或者更保守的路线在推进当中,它们之间呈现怎样的关系呢?这里我们先区分下不同技术路线的差异。
四、技术路线比较
1、CPO
我们讨论的CPO,也就是共封装光学(Co-Packaged Optics),如上文所述,指的是将光引擎和芯片封装在同一基板上,这里的芯片既可以是交换芯片(Asic),也可以是GPU等计算芯片,但通常指的是交换芯片。
2、NPO
NPO是近封装光学(Near-Packaged Optics),比CPO初级一点,还没有打到封装在同一基板甚至中介层这样的尺度,而只是封装在同一块PCB母板上。
中国国内包括阿里、华为等都在推动NPO方案,这更多可看作是缺乏先进封装产能下的一种妥协方案,但可能在一段时间内成为中国市场的主流方案,这一定程度上会影响到英伟达方案在中国市场的渗透。
图:不同集成方式展示:(从上到下分别为可插拔方式、NPO、CPO(集成在封装基板)、CPO(集成在中介层),以及下面要说的OIO)
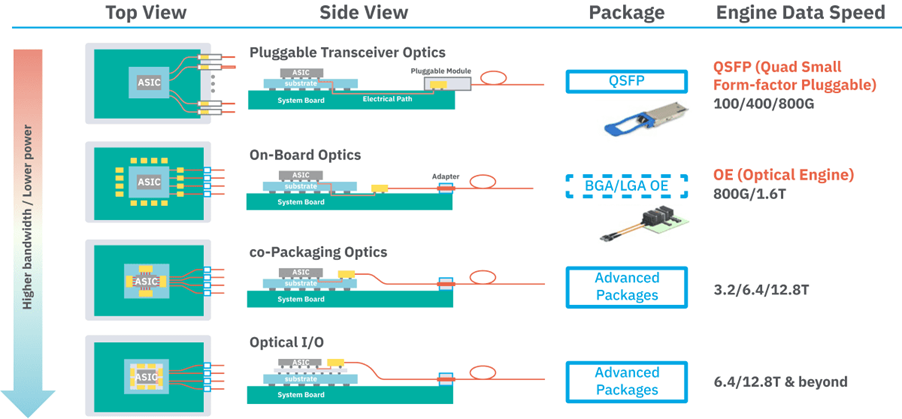
资料来源:ASE,Dolphin Research
3、OIO
OIO(Optical I/O)可看作是CPO的进阶,这里就没有交换芯片的事情了,主要跟计算芯片相关,指的是将光引擎与计算芯片封装在一起,甚至是直接在芯片层面上结合在一起,这面向的完全是机柜内场景。
图:不同集成方式展示:可插拔、CPO、OIO
资料来源:台积电,Openlight,Dolphin Research
谈到这里,我们再来明确一下数据中心的架构:
数据中心,可以看作是以下几个部分互相连接:
服务器专注于计算任务,内部装载GPU、CPU等计算芯片,内存、硬盘等;
交换机则负责服务器之间以及服务器向外部的网络通信,通过ASIC芯片实现数据交换;
除此之外还有存储系统,在目前主流数据中心架构当中,存储器主要分散布置在服务器节点,并放置于在服务器内部,与服务器结合在一起。
基于上述架构,我们就能可以想象CPO的应用场景。那么在此基础上,我们讨论下,为什么CPO率先从交换芯片开始?
这里我们对交换机的作用做个类比——交换机可以看作是数据中心内部的立交桥,那么可以想象,交换机所承担的数据传输带宽压力、端口密度以及与之相伴随的功耗瓶颈是最大的,那么自然对CPO的需求更迫切。
4、CPC
CPC,是共封装铜互联(Co-Packaged Copper),指的是把高速铜连接器直接集成在封装基板上。
这种技术路线的成本优势是非常明显的,但仍然解决不了铜介质的带宽瓶颈和衰减问题,所以应用场景比较受限,可以部分应用在机柜内部的GPU/CPU节点与交换机及存储芯片之间的连接。目前英伟达机柜内方案仍采用铜连接,但未来可能将向光互连切换。
5、LPO
LPO,则是线性驱动可插拔光学(Linear-Drive Pluggable Optics),是一种瘦身版的可插拔光学,通过去除内部的DSP/CDR芯片,仅保留并强化模拟芯片Driver和TIA(这些部件的作用我们后面会讲),实现信号直驱。
说白了,就是在光模块中直接踢掉功耗大的DSP芯片,放弃信号纠错;同时强化模拟芯片,无论信号准确与否,通过模拟放大,直接让交换机ASIC的电信号来冲进来驱动激光器。
图:传统模式与LPO结构对比示意
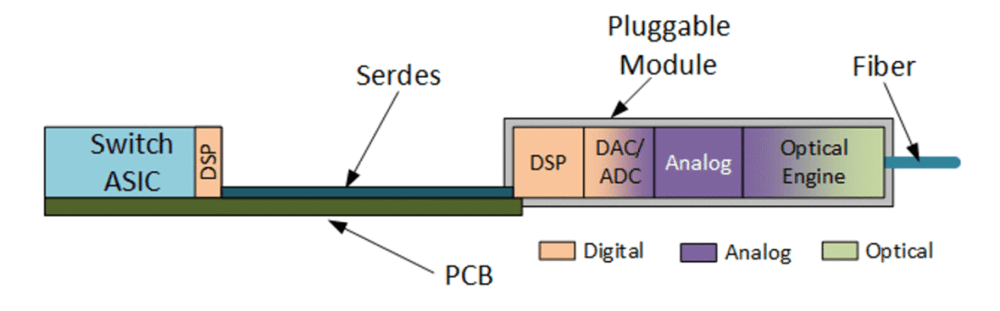
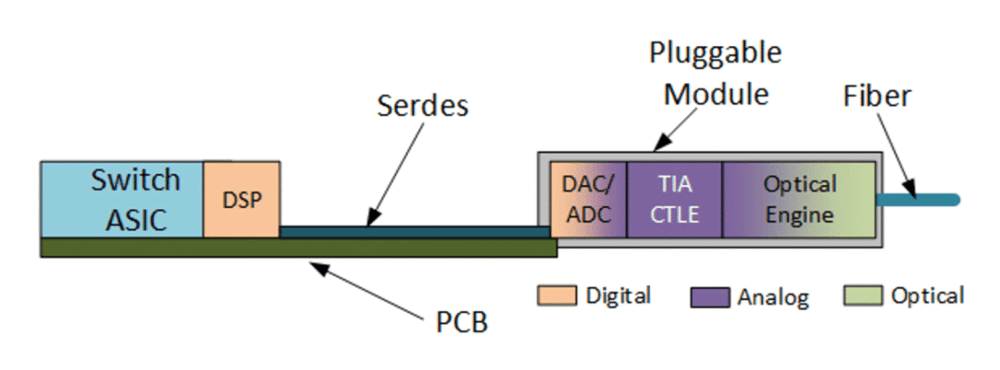
资料来源:Bryon Moyer,Semiconductor Engineering,Dolphin Research
但这里同样存在问题,由于PCB走线并没有省略(会造成信号衰减),同时对信号质量要求又更高,于是长距离传输还是受限,并且当速率迈向更高维度(1.6T以上)时,信号完整性问题会格外凸显。也就是说,简化结构的同时,性能上也会有所牺牲。

综上我们可以看到,尽管存在NPO、CPC、LPO等折中路线,但随着数据中心迈向更高速率和更大集群,这些折中方案总归会面临瓶颈,CPO是未来必须要突破的下一代方案。
6、光电路交换机(OCS)又是什么,会威胁到CPO的地位吗?
谈到这里,无可回避地会涉及到OCS(Optical Circuit Switch)。OCS这种交换机的核心特点是全过程没有光电交换,通过光开关矩阵,直接在光域内建立物理光路。
图:OCS示意
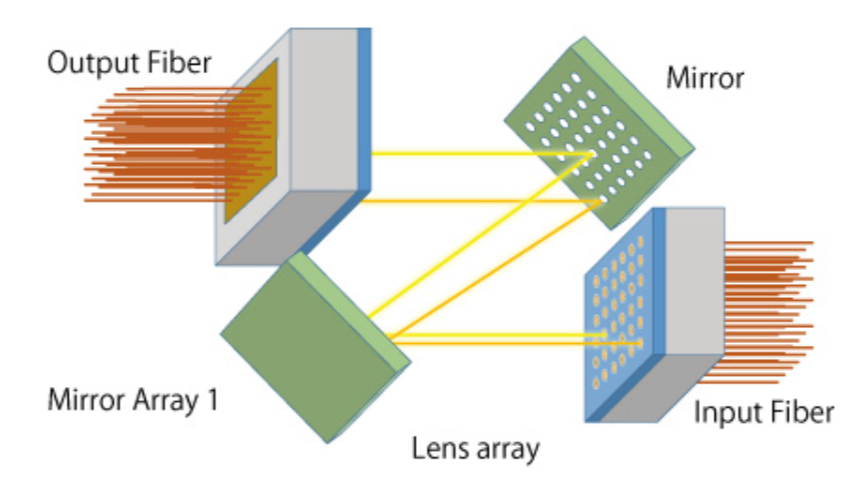
资料来源:Orbray,Dolphin Research
可以直观地想象,它就像是由一排排反射镜(微镜阵列)组成,可以根据指令调整反射镜的角度,向不同的角度反射光线。
表面上看起来,OCS是直接转发光信号,替代传统交换机光-电和电-光转换过程,似乎用这种技术路线,就不需要CPO了(至少不需要交换机环节的CPO)。但实际并不是这样的。
这里我们梳理下,在数据中心当中,交换机的架构是如何构建的:
(1)主板内:首先我们知道数据中心内最核心的计算是通过GPU实现的,GPU计算完毕后,需要将数据传递给CPU,CPU经过处理后再传递给网卡(内含ASIC),或者也可以由GPU直接传输给网卡。
那么以上环节可以在一块主板上实现,或者至少可以在一台服务器内实现。
(2)机柜内:之后,数据就要从服务器传递到机柜的交换机上。一个机柜内可以有多台服务器高速互联,但机柜顶上必须有一个交换机,用来与外部通讯,将机柜内的数据与外部的数据做交换。这里这个交换机叫做ToR(Top of Rack)交换机。
而以上环节是在同一机柜内实现的。
(3)机柜间:数据中心是由多个机柜组成的集群,机柜和机柜间的通讯如何调度呢?这里就需要Spine交换机发挥作用了。Spine交换机负责管理所有Leaf交换机之间,以及向数据中心外部的高速连接,它是数据中心内整个交换机网络的枢纽。
图:在数据中心中,Spine交换机和Leaf交换机示意
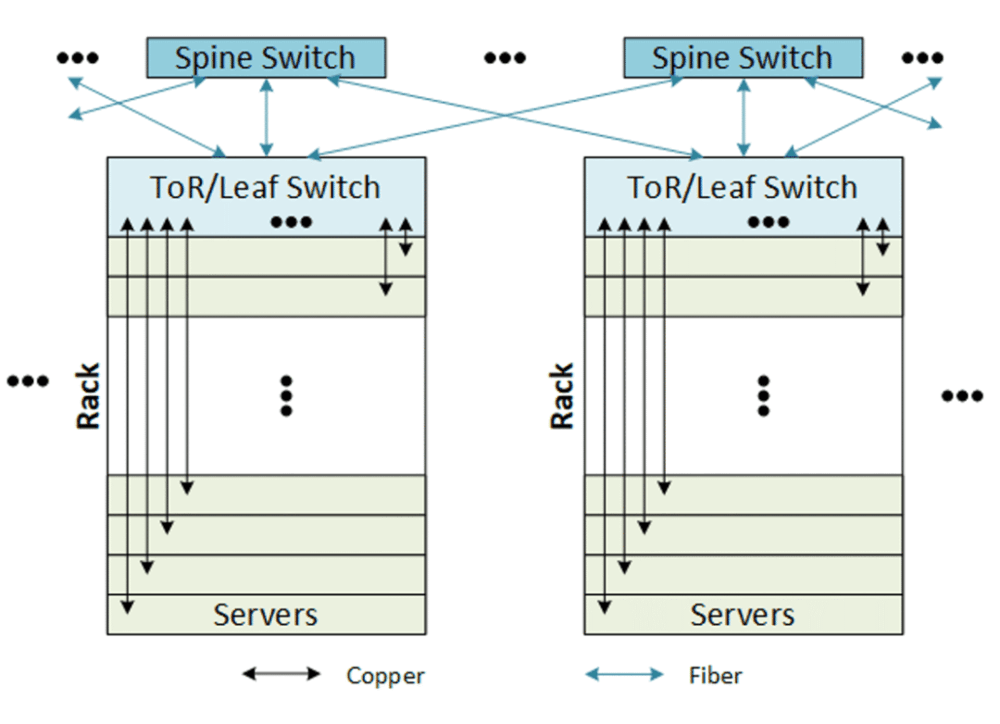
资料来源:Bryon Moyer,Semiconductor Engineering,Dolphin Research
而OCS主要用来替代的是Spine交换机。
首先,Spine交换机价格高且功耗高,替代方案的需求最迫切。
其次,OCS作用是有限的,它只能转发信号(反射光线),就像反光镜。但传统交换机功能更完整,它需要拆数据包,看IP地址,然后决定往哪里转。所以说,由于OCS只能执行指令,没有判断能力,那么在这种情况下,它只被用来充当Spine交换机是可行的,但要是想把Leaf交换机也替代了,那就需要新增别的部件来执行“封包处理”功能,比如智能网卡(SmartNIC),那么这个架构就复杂了,它不一定是最好的方案。
这么看下来,架构就很清楚了:
虽然现阶段,英伟达推出的Quantum X800-Q3450、博通等推出的Tomahawk 6-Davisson等CPO路线的交换机,都是Spine交换机,而Google推动OCS交换机,替代的也是传统Spine交换机,两者之间的确存在直接竞争关系。
但终局来看,虽然OCS有机会替代Spine交换机,但再往下,对于用量更大的,Leaf交换机上光引擎与ASIC芯片之间的电光转换,到服务器内主板与主板之间的连接(通过网卡ASIC或NVSwitch等),再到主板上计算芯片与计算芯片之间&计算芯片与网卡ASIC之间的连接,仍然需要使用CPO。所以未来两者更多是相辅相成的关系。
五、涉及到的产业链环节有哪些?
(一)首先我们解析下CPO的原理和架构
CPO可看作是升级版的光引擎,而光引擎的作用是进行光电转换,它主要包括以下几个部分:
1、光子电路部分
(1)调制器:通过控制光的强弱和信号,把电信号(0/1数字)写成光信号。
(2)探测器:是PD(Photodiode,光电二极管),把光信号转换成电信号.
(3)波导:可以理解为芯片内部印上去的微型光纤。
2、电子电路部分
(1)Driver(驱动器):将交换机或者服务器传来的微弱电信号放大成能精确控制激光器发光的电信号,所以Driver的下一个环节就是调制器。
(2)TIA(跨阻放大器):将PD产生的极其微弱的电信号,放大并转换成可供后续电路处理的电压信号,所以TIA是PD的下一个环节。
3、光源,也就是激光器
调制器自己是不能发光的,但它能控制光,所以这里就需要一个发光的部件与之配合,也就是激光器。
资料:光引擎结构示意
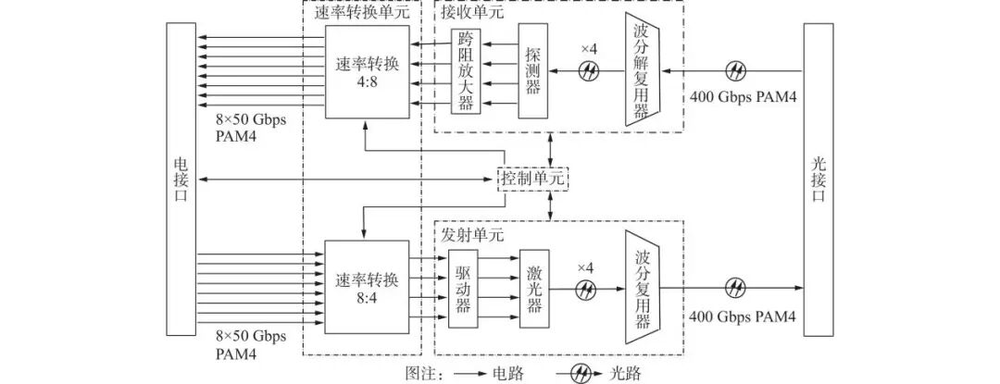
资料来源:宗泽国等,《400G FR4硅光收发模块的研究》,Dolphin Research
另外还有两个部件:
4、DSP和CDR,它们都是用来修复电信号的。一个用来补偿电信号的物理损伤,一个用来从受损信号中提取精确时钟,并重整数据时序,其中DSP芯片通常集成CDR功能。
CPO与LPO类似的一点是,它们都将高功耗、高成本,延迟源的DSP从光引擎中移除。但CPO方案下,DSP部分功能集成到了交换ASIC中,而LPO是用模拟芯片放大硬刚的方案),另外CPO会将CDR集成到高速SerDes。
而什么是高速SerDes呢?高速SerDes包括Ser串行器和Des解串器,它们位于Asic芯片内部,分别用来将芯片内部并行数据打包成高速串行数据流,或者将高速串行数据流解包还原成多路低速并行数据。
(二)再看整个CPO产业链涉及到哪些环节:
1、首先是CPO整体
CPO中的光引擎包含了上述提到的光子电路部分和电子电路部分,然后光引擎与ASIC芯片构成CPO交换机主体部分。这里先说一个核心问题谁来做这个CPO?
传统的光模块作为由光学组件、分立器件等组成的独立模块,可以由专业性生产厂商来完整提供,比如我们耳熟能详的中际旭创、新易盛、Coherent,那么CPO呢?显然不可能再由它们来主导了。
我们倾向于认为,CPO下的产业价值走向会是这样的:
(1)掌握核心技术的交换厂商和平台商:掌握英伟达/Google/博通/Marvell这样的数据中心系统平台方&交换芯片厂商来定义架构和标准+卖整套产品;
(2)代工厂:台积电/日月光/Amkor这些Fab厂/封测厂来进行晶圆制造/光电集成/先进封装代工;
(3)上游供应商:Coherent/Lumentum这些器件厂继续进行光电器件的生产和供应。
(4)传统光模块厂商:中际旭创/新易盛等过渡期内提供NPO、LPO等中间路线,以及基于可维护性考量的折中CPO设计方案下,继续提供光引擎模块。
2、除了CPO的核心光引擎之外,还有几个组件需要关注
(1)激光器
CPO只能够集成光电转换部件,直接集成激光器还存在难度,因此仍然需要外置激光器。与此同时,CPO对激光器的功率要求大幅增加(至少增加3-4倍),对应性能和可靠性要求也大幅提高,因此价值量也会大幅增加。
不过,这里存在技术路线的选择:
1)EML激光器:传统路线,它将激光器和调制器集成在一起,优势是适合200G以上高带宽和长距离通讯。这个路线被Lumentum、II-VI(Coherent)、住友等巨头垄断。
2)CW激光器:新兴路线,它把激光器完全独立,在成本和功耗上有优势,也更匹配未来的CPO路线。CW激光器供应相对灵活,中国的源杰科技、仕佳光子、长光华芯等厂商已实现70mW/100mW产品量产并获大额订单。
图:EML和CW激光器的区别示意
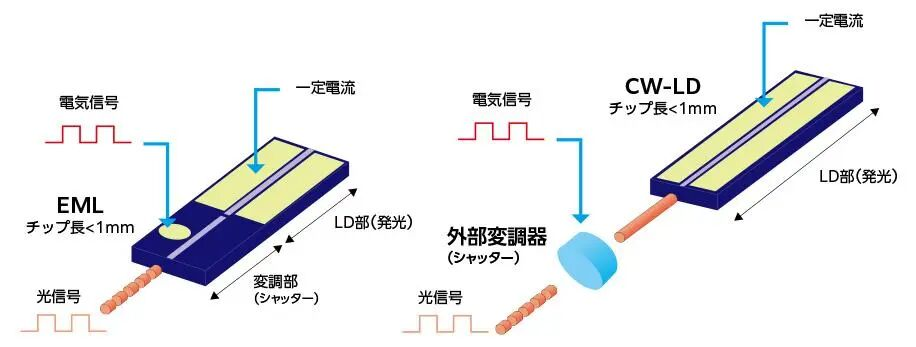
资料来源:住友电工,Dolphin Research
接着是四大光纤组件,这些组件在传统可插拔光模块路线下很少用到:
(2)光纤阵列单元(FAU,Fiber Array Unit):用来将光纤精确地安装,以实现光纤与波导之间的高精度对准。
图:Fiber Array Unit
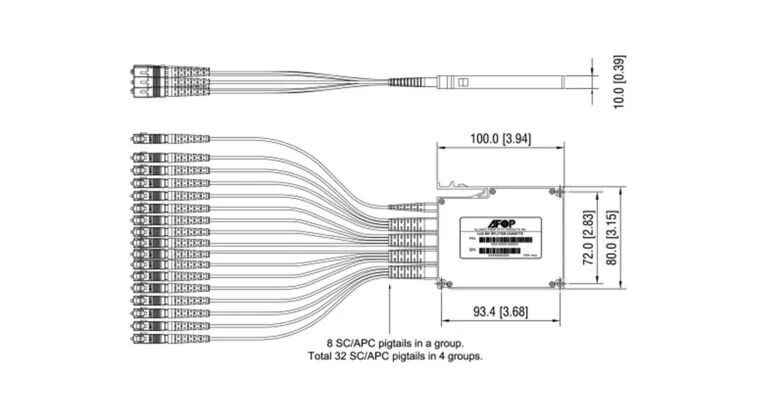
资料来源:Corning,Dolphin Research
(3)保偏光纤(PMF,Polarization Maintaining Fiber):是一种特殊的光纤,用来使得光波的偏振态保持不变。
(4)光纤分配盒(Fiber Shuffle):用来排列光纤,可以将复杂的高密度设备里的光纤的位置顺序重新排列。
图:Fiber Shuffle示意

资料来源:Hyoptic,Dolphin Research
(5)光纤连接器(MPO,Multi-Fiber Push On):用于多芯光纤之间的相互连接。
图:MPO端口示意
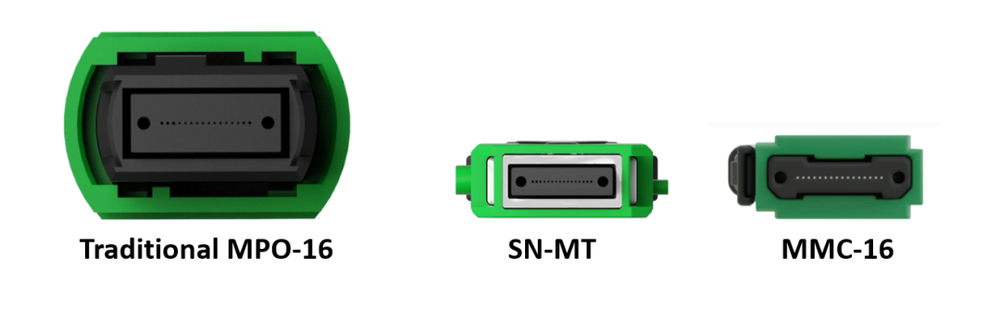
资料来源:Senko,US Conec,Dolphin Research
为什么传统光模块很少用到上述组件?
(1)传统模式下,光纤直接插入标准化接口,但在CPO下,光纤需要与光芯片表面的波导进行高精度耦合,所以需要用到FAU;
(2)传统模式是直接调制,对光波的偏振态不敏感,且此前保偏光纤(PMF)成本又极高,不太适合产业化应用,但CPO通过外部激光器供给光源,激光偏振态会导致巨大能量损耗,所以必须用到PMF;
(3)传统模式通常只有1发1收两路光纤,没有那么复杂的光纤需要连接到背板,所以人工操作就可以,不需要Fiber Shuffle,但CPO下必须使用Fiber Shuffle;
(4)同样,传统模块也不需要很多接口,但CPO下如果达到400G以上,需要8根甚至16跟光纤并行传输,而面板空间又有限,所以需要MPO这种多芯连接器。
那么对于市场空间,以及CPO所涉及到的产业环节投资机会,我们会在下篇中进行分析。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。