2026-06-03 21:25

本文来自微信公众号: 极客公园 ,作者:Cynthia,编辑:郑玄
能力固然耀眼,但这次主要想聊一聊的,是它的价格。
过去在Chatbot时代,很多人可能对这种性价比没什么概念。毕竟用户问一句,模型答一句,成本还比较温和。到了Agent时代,模型开始学会读仓库、扫文件、跑测试、看日志、修bug、跑测试。一次任务背后,可能是几十次、几百次模型调用。
于是,模型变聪明了,但成本也没多少人扛得住了。
而一个聪明又有足够性价比的模型,对很多个体以及企业而言,有时候往往就是AI真正走向落地的临门一脚。
01
从Agent经济学的痛点,
过去大家讨论AI替代人、解放人,常常默认AI一定更便宜。
但这句话成立,是有限制条件的。
特别是Coding Agent场景,前段时间,一篇关于Agentic Coding成本的研究,分析了8个前沿模型在SWE-bench Verified上的运行轨迹发现一个有意思的现象:
Agentic Coding类任务,token消耗不是线性增长,甚至可以达到普通代码问答的1000倍。更麻烦的是,有时候,token烧得更多,准确率并不一定继续变高,很多任务的准确率会在中等成本区间达到峰值,然后趋于饱和。
背后逻辑在于,Coding需要用户把完整的项目文件、代码上下文喂给AI,才能产出真正可用的代码。是典型的输入token远大于输出token的场景。越是生产级场景,上下文成本就越是贵得离谱,有时候,甚至会超过人力成本本身。
这也就解释了为什么很多过去在AI使用上非常激进的企业,从今年开始,出现了态度反复横跳:
一个极端案例是OpenClaw。其创始人Peter Steinberger曾晒出30天消耗约130万美元OpenAI API token的账单,覆盖6030亿token、760万次请求,背后是约100个Codex agent在跑自动化开发任务。
Uber更是CTO与COO先后公开下场吐槽,公司到2026年4月已经花完了全年Claude Code预算。
Agent不能试错就做不了复杂任务;但试错太贵,企业就会关止步不前,个人开发者也会变得保守。
以前模型竞争的核心的是智力上限,agent时代,单位成本下的有效工作量才是真正的重点。
但支撑这个性价比的根源在于哪里?性价比背后,产品的体验又究竟如何?
02
为什么行业发展到现在,
需要更强的Coding和长程自主迭代
价格解决的是敢不敢用,下一步用户关心的,是值不值得用。
先看看Hopper FP8 GEMM kernel优化案例。
在这个任务里,M3的起点只有任务描述、benchmark脚本和一个不能直接运行的Triton骨架,没有reference高性能实现。
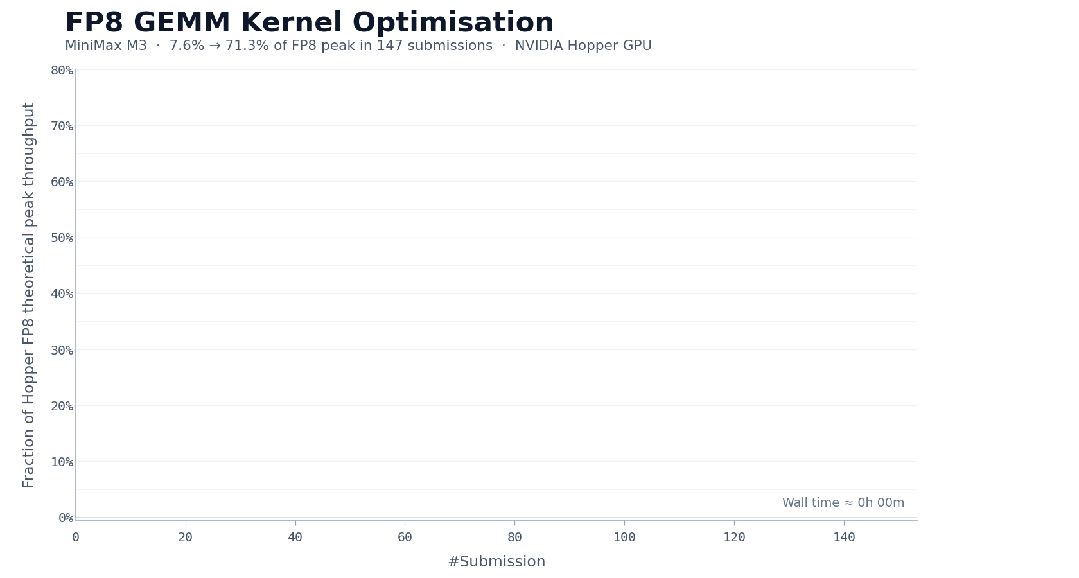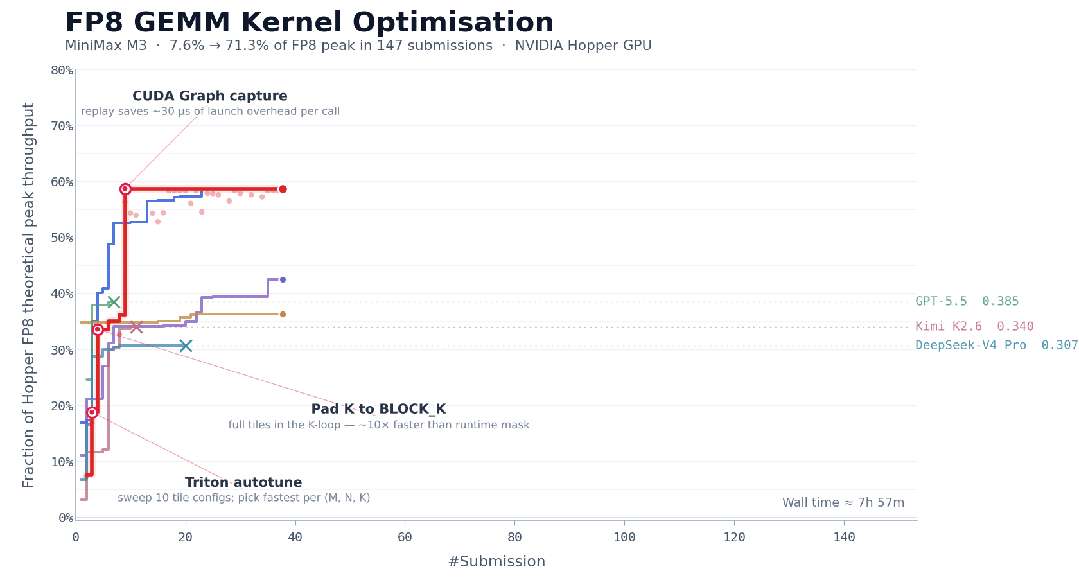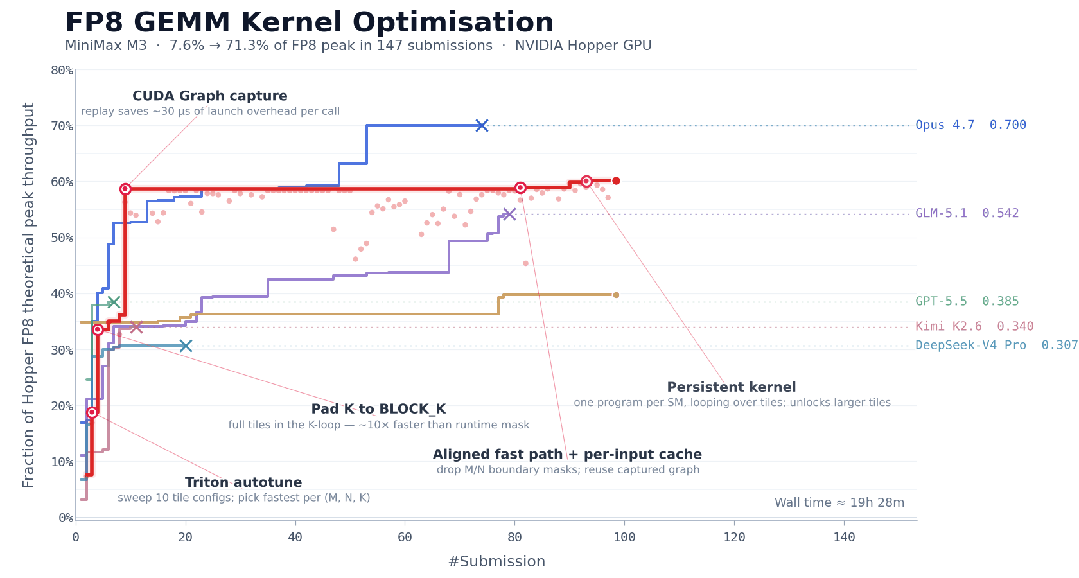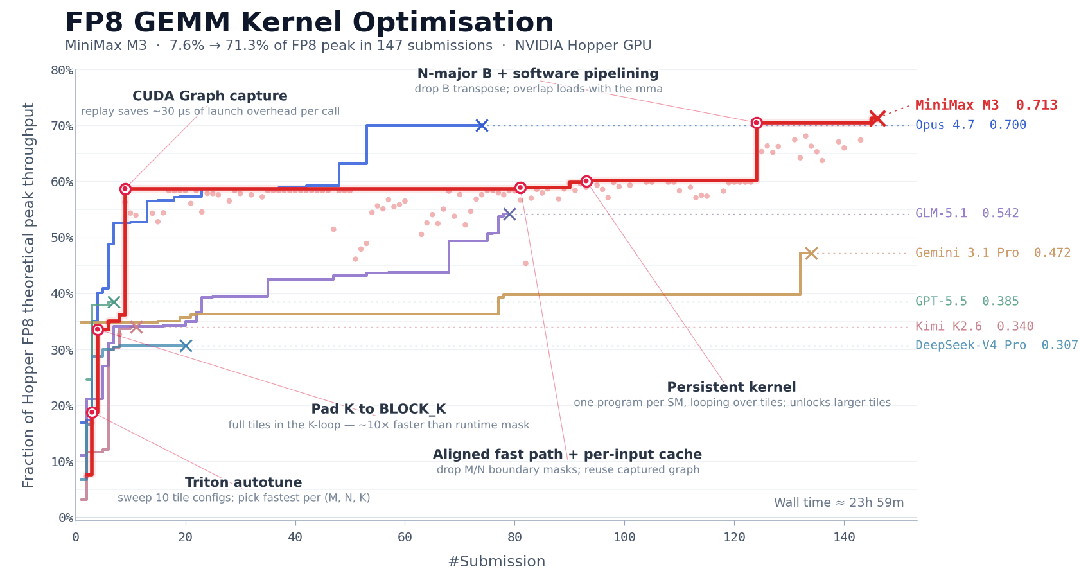
也就是说,模型并不是前几轮灵光一闪就完成任务,而是在多个平台期里继续诊断、尝试、验证、推翻,再尝试。
这个过程里,模型需要需要维持目标、记住历史、理解benchmark反馈,还要避免在多轮改动中把系统搞乱。
这也是Coding Agent和代码补全工具的分界线。一个普通vibe coding群体可能没意识到的现实在于,真实的生产级环境中,无论AI还是人类,产出代码第一次跑不起来很正常;跑起来之后性能差也很正常;优化完引入新bug也很正常。而工程任务的大部分时间,都花在诊断、验证、回滚、再尝试。
这也是为什么我在前面说,benchmark结果漂亮固然很重要,但不能直接将其平移到生产环境。今天很多coding benchmark仍然是single-turn task,但真实协作一定是multi-turn、multi-file、multi-tool、multi-objective。谁能把训练和评测从一次性解题推进到持续协作,谁才更接近下一代Coding Agent。

这个任务的特点在于任务本身够复杂,需要的能力也够多。模型要读论文正文,理解公式和图表,写实验代码,跑训练脚本,检查结果是否对齐论文结论,再根据偏差调整实验设置。这就需要,模型的智能上限、长上下文、编程、多模态、工具调用、事实纠偏各种能力必须同时成立。
我在测试里直接让AI根据《西游记》小说,制定一个交互地图。
完成这个任务的难点在于,首先模型要自己找到《西游记》原文共100回,60余万字并通读理解。
在此基础上,做西游交互地图最难的是原著地名散乱、虚实空间混杂:行程描述只写里程但没有坐标,所有的动线、事件跨百回分布,必须全本上下文统筹梳理空间关联;而仙界洞府等多层平行空间中的各种虚构场景没有现实GIS参照,同时一些凡间位置,虽然有现实世界原型,但又并未在书中明说。
要把这些文字描述转成地图画面、自动生成开发代码,对模型的上下文能力、工具调用能力、多模态能力、agent协作能力,甚至审美都是不小的考验。

向上滑动查看
这是最终的生成HTML页面的截图,可以看到,不仅路线图与剧情完全吻合,甚至不同地点可能对应的现实世界方位,也基本一致。
比如五行山对应现实世界河北五指山,法门寺在陕西西安,通天河在青海玉树附近,而流沙河对应现实世界新疆塔里木的开都河,与现实世界原型的参考方位几乎一一对应。

03
稀疏注意力搞定1M上下文已经不新鲜,
但如何保证命中率?
长上下文现在已经不稀奇。很多模型都在宣传200K、1M,甚至更长。问题在于,窗口长不代表模型会用。
Agent不可能每一步都从零开始思考,它必须把过去的失败、用户偏好、项目结构、工具反馈沉淀进上下文。相应的,模型的上下文中会堆满了超长的代码文件、终端日志、失败记录、benchmark输出、用户反馈、历史工具调用和中间推理痕迹。
长上下文是实现这一切的基础。但有时候,窗口越长,也就意味着各种中间状态、无关内容构成的噪音越多,输出质量越差,成本也越容易爆炸。
在这一背景下,使用稠密注意力,上下文长度的扩张以及输出效率会受到限制,成本也会随之失控。
使用普通稀疏注意力,能省成本,但容易牺牲细粒度信息定位能力。
但偏偏,Agent执行过程中,最怕漏细节。一次工具调用里的关键报错、某个代码文件里的边界条件、某张图里的曲线异常,都可能决定任务能不能继续。
因此,实现长上下文本身不难,真正难的是如何实现成本、效率、命中率的三者得兼。
这其中的难点在于,《国富论》通篇都是定性社科论述,分工、财税、外贸、资本、薪资的经济传导逻辑零散分布全卷,只有百万级上下文才能完整通读全书,提炼环环相扣的量化演算规则,把斯密的文字理论转化成税率、生产率、财富联动的数值公式。
在此基础上,要完成模拟世界游戏的构建,还需要靠Agent不断完成长时序推演,理解玩家减税、修路等政令可能导致的结果,最后还能分短中长期按古典经济学逻辑迭代面板数据,全程不能违背原著底层经济规律。

而长上下文也只有做到这一步,才有意义。
04
Agent时代,最稀缺的不是智能,
而是可负担的智能
复杂任务需要长上下文。长上下文会带来成本、速度和信息命中率问题,所以需要MSA这种更高效的注意力机制。
Coding Agent需要持续迭代。持续迭代会消耗大量token,所以模型既要会写代码,也要能在多轮失败里维持目标、读懂反馈、继续推进。
真实工作环境是多模态的。只会处理文本,Agent就很难处理截图、图表、后台、Excel、PR页面和终端输出混在一起的任务。
高频使用还要足够便宜。否则用户不会让Agent充分试错,企业也不敢把它接入真实流程。
每个点单独看都不是第一次出现,但组合起来构成的,是Agent能力进入开发者和企业日常工作流的敲门砖。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。