2026-06-11 14:51

本文来自微信公众号: 集智俱乐部 ,作者:白龙驹,原文标题:《AI agent 能算清自己的账单吗?一次关于 token 消耗的系统分析|白龙驹》
| 论文题目:How Do AI Agents Spend Your Money?Analyzing and Predicting Token Consumption in Agentic Coding Tasks论文地址:https://arxiv.org/pdf/2604.22750发表时间:2026年4月24日论文来源:arXiv |
引子:一笔看不见的账单
想象这样一个场景:你雇了一位助理帮你修复一个软件bug。他埋头工作,翻阅文档、反复试错、运行测试,几个小时后交出成果,然后递给你一张账单。而在此之前,你完全不知道这次要花多少钱,要花多长时间,甚至不知道他能不能把这个任务成功完成。更糟的是,即便他最终没修好,这笔钱你也得照付。
这正是今天我们与AI智能体打交道的真实写照。从Claude Code、Codex到Cursor,这类能够自主读取代码库、调用工具、迭代修改的智能体,已经迅速渗透进真实的软件工程流程。过去一年里,它们在权威评测SWE-bench Verified上的准确率被一路推高到78%以上,进步之快令人侧目。
但伴随能力跃升的,是一笔越来越沉重、也越来越难以看清的账单。任何用过这类工具的人都熟悉那几句抱怨:“为什么这么简单直接的一个问题都要反复调试,调用工具这么多轮?”,“换了一个backbone模型之后怎么效率和能力差别这么大?”,“我的额度怎么又用完了?”
这些抱怨背后,藏着一个尚未被系统研究的问题:AI agent到底把钱(也就是token)花在了哪里?不同的backbone模型在效率和能力上有哪些差异?我们能不能在它动手之前,就预知这笔开销?
来自密歇根大学、斯坦福大学等机构的研究者,借助开源的OpenHands coding agent框架,分析了8个前沿大模型在SWE-bench Verified上的完整运行轨迹,首次就“agent成本从何而来、不同模型有何不同、成本能否预测”3个问题给出了系统性的答案。
一、为什么agent任务如此昂贵?
要理解这笔账单,首先得知道它和其他任务场景有哪些不同。
研究者比较了三类与代码相关的任务:代码推理(针对单个代码问题的一次性推理)、代码聊天(围绕代码的多轮对话),以及agentic代码任务(agent在真实代码库中自主解决SWE-bench问题)。这三类任务对应着能力递进的三个层次,所要应对的问题也越来越复杂:代码推理往往只用于预测某个函数的输出,代码聊天则辅助人类理解设计、调整代码,而coding agent已经能够全自动地解决问题。能力上的层层递进,也最终反映到token消耗上,三类任务在数量级上拉开了惊人的差距:无论是平均token消耗、平均花费,还是输入与输出token的比例,agentic任务都呈指数级地高于另外两类。一个典型的agentic编码任务平均消耗约417万token,而一次代码推理任务只需约1200 token——相差近千倍。
更让人好奇的是这些token花在了哪里。人们直觉上会认为,AI的成本主要来自它"说"的话,也就是生成的输出。但数据揭示了相反的事实:真正吞噬成本的是输入,而非输出。在agentic代码任务中,输入与输出的token比高达154:1。
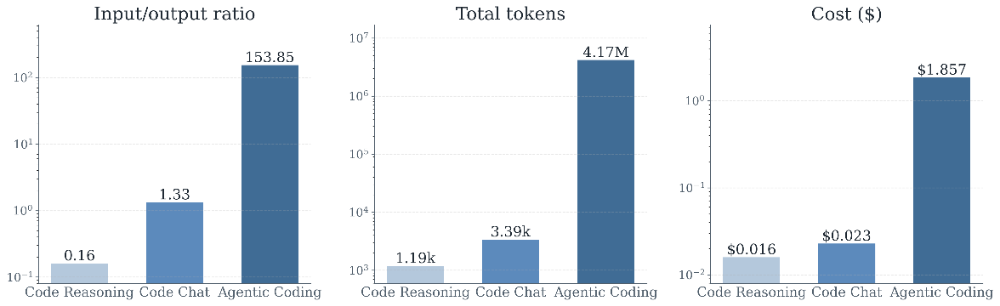
图1:Agentic Coding任务所消耗的token数量明显多于代码推理(无工具交互的单轮问题求解)和代码对话(关于编程问题的多轮对话)任务,这一差异主要由输入token数量的增加所驱动。
这一现象,源于agent独特的多步工作方式。它并非一问一答,而是在多轮交互中不断累积上下文。尽管学界已有不少关于agent记忆管理的探索(如智能记忆压缩、记忆检索、滑动上下文窗口等),但当前产品级的coding agent大多仍采用最朴素的"全盘累积"策略:每一次代码查询、每一份文件内容、每一条工具返回的结果,都会被追加进对话历史,并在下一轮原封不动地重新喂给模型,直到逼近上下文长度上限,才开始压缩记忆。任务越长,这个雪球就滚得越大。即便厂商普遍启用了上下文缓存(caching)来削减重复处理的成本,输入端依然是开销的绝对主力。
这意味着一件重要的事:agentic任务的成本结构,与我们熟悉的聊天、推理任务有着本质的不同。理解agent的开销,不能照搬旧有的经验。
二、花得越多,做得越好吗
既然agent这么烧钱,一个自然的期待是:多花的钱总该买来更好的结果吧?研究的第二个发现,却给这个朴素的直觉泼了一盆冷水。
首先,token消耗本身就极不稳定。研究者统计了500个问题的平均消耗并排序后发现,最贵的任务比最便宜的多消耗约700万token;而且越贵的任务,消耗的波动也越大。更让人注意的是同一任务的重复运行——同样的问题、同样的模型,跑四次,最贵的那次仍可能是最便宜那次的两倍左右。换句话说,agent的开销带着一种内在的随机性,哪怕面对完全相同的问题,你也无法笃定它这次会花多少。
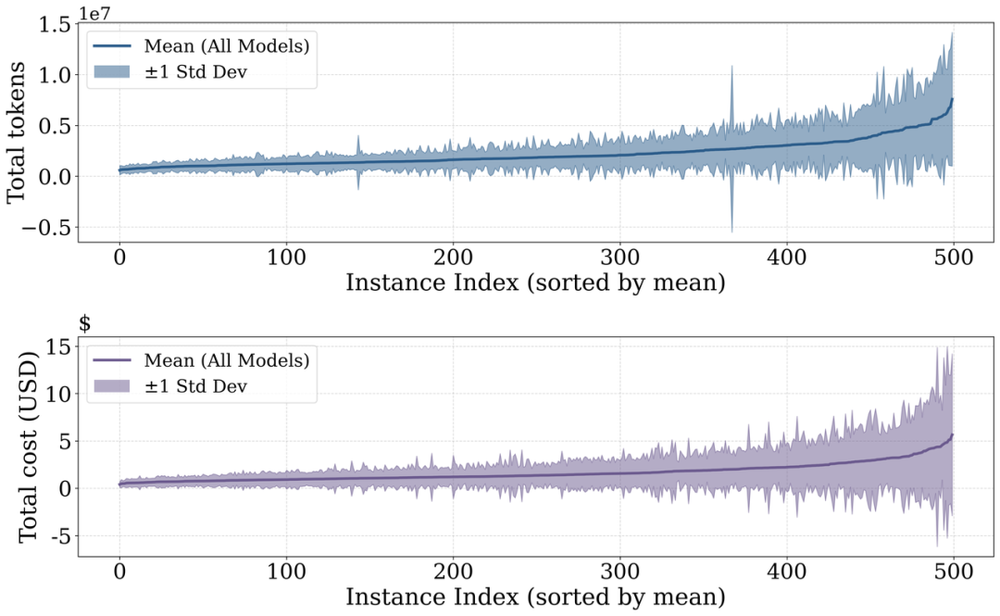
图2:跨四次运行和八个模型的逐实例均值±1个标准差,实例按均值成本排序;右侧的重尾分布表明,高消耗问题同时也具有最大的跨运行方差。
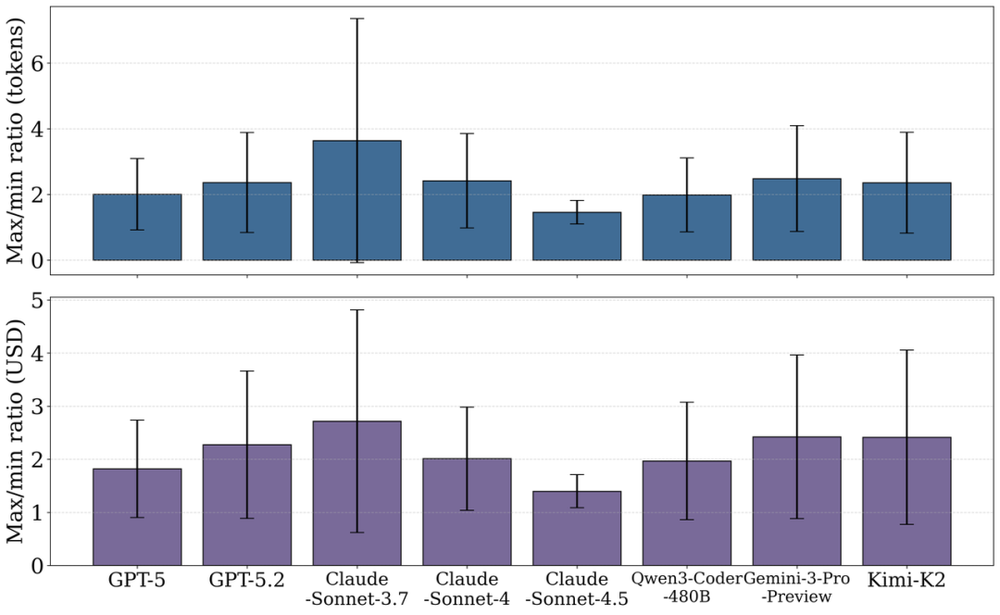
图3:跨500个实例平均的逐模型最大/最小消耗比,误差棒显示跨实例的±1个标准差。综合来看,这些结果表明Token消耗具有高度变异性,使得预先预测成本在本质上十分困难。
那么,花得多是不是至少意味着做得对?答案依然是否定的。
在不同任务之间,研究者按平均token消耗将任务分组,发现消耗更多的任务组反而准确率更低。这或许还能用"难题本来就更费token"来解释。但真正出人意料的是同一任务内部的规律:研究者把同一问题的四次运行按开销从低到高分成四档,统计每档的准确率,结果发现准确率并非随开销单调上升——它在较低开销时就达到了峰值,此后非但不再增长,反而在最高开销的两档里掉头向下。
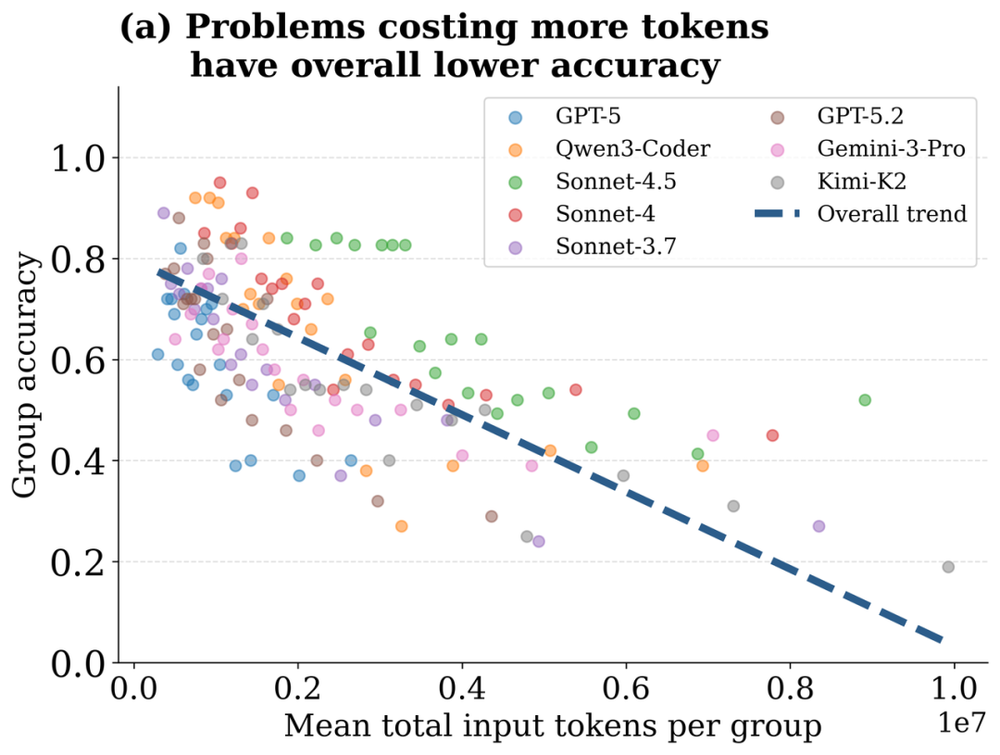
图4:各开销/模型分组的组级准确率与平均输入Token数;虚线显示整体趋势。
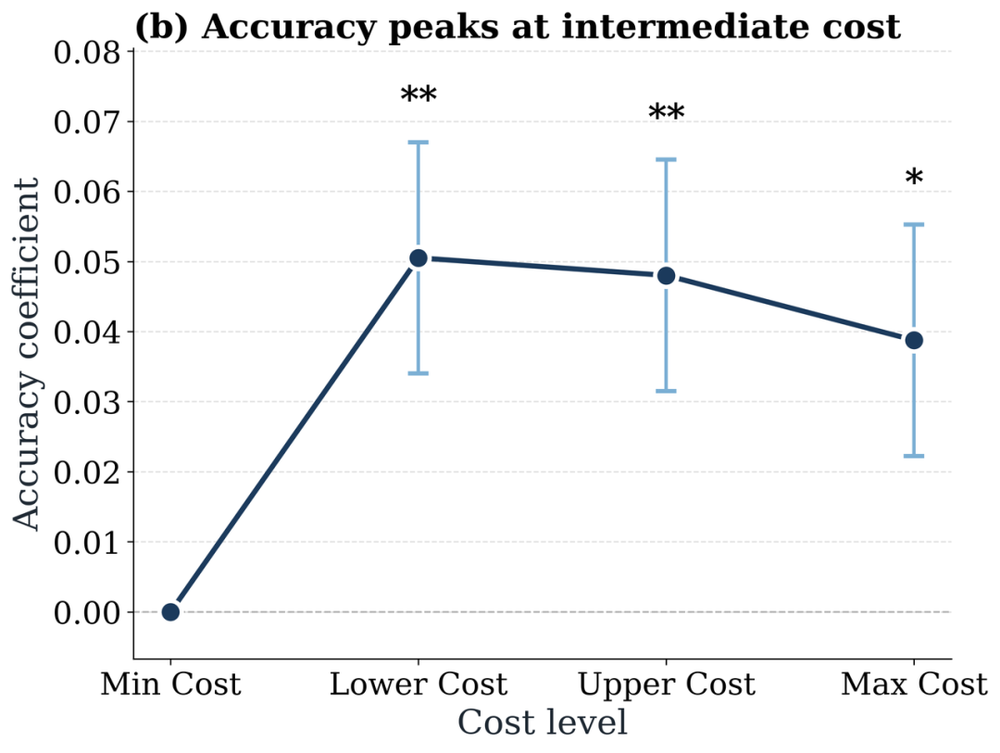
图5:跨消耗四分位数的相对智能体准确率,以最低消耗设置为基准,通过混合效应回归估计。在处理同一问题时,智能体性能在中等消耗的运行时达到峰值,随后在更高消耗下趋于饱和。
这背后可能是什么原因?作为初步的探索,研究者观察了agent的两类行为:查看文件与修改文件。一个值得注意的关联浮现出来:开销越大的运行,重复查看、重复修改同一个文件的次数也越多。虽然这只是一种相关性观察,而非经过验证的因果解释,但这一线索提示我们,昂贵的运行未必对应着更深入的思考,反而可能伴随着大量来来回回的重复操作,把上下文越堆越长却没有实质进展。它也把我们的目光引向一个更关键的问题:agent的效率。
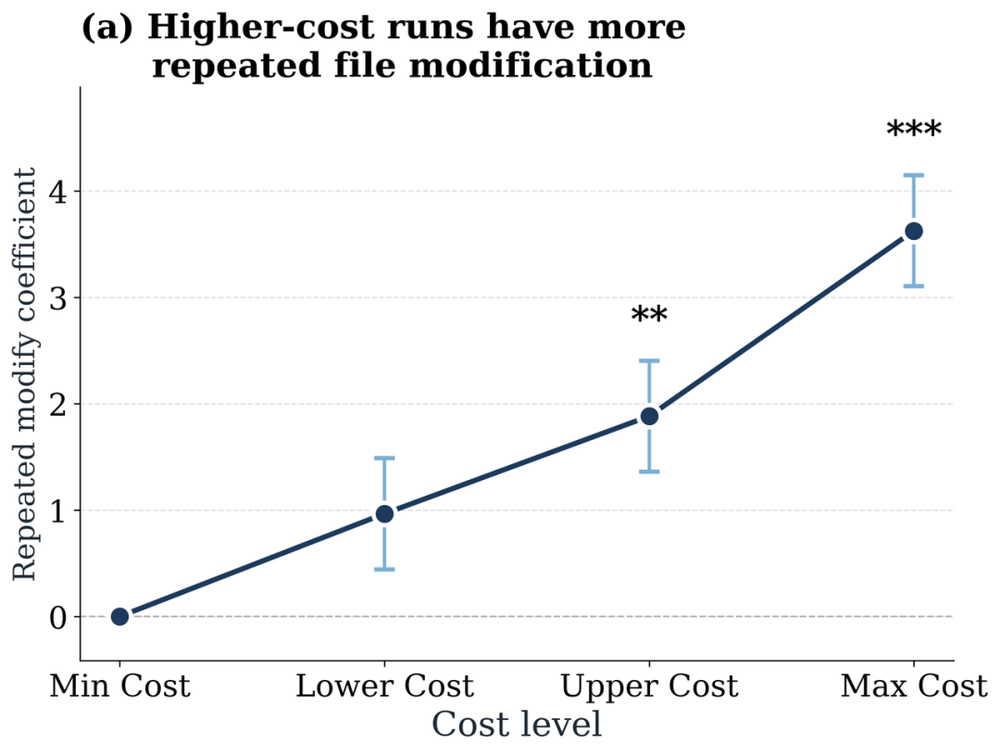
图6:跨消耗四分位数的文件重复修改相对频率,以最低消耗设置为基准,通过混合效应回归估计;高消耗运行与对同一文件的反复修改显著相关。
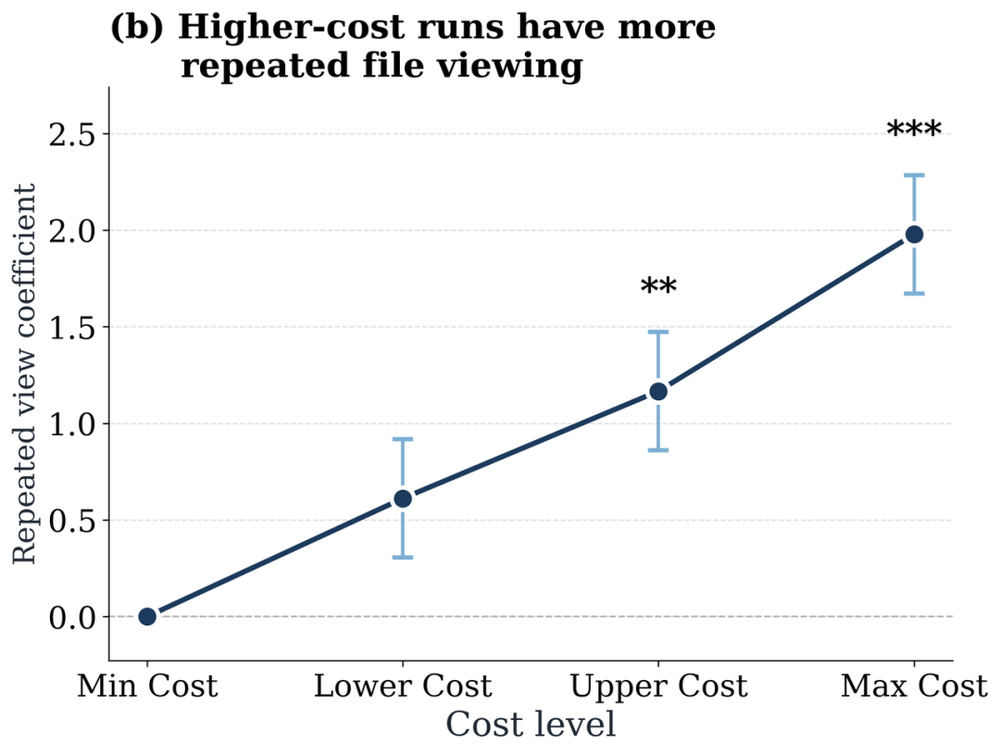
图7:跨消耗四分位数的文件重复查看相对频率,以最低消耗设置为基准,通过混合效应回归估计;高消耗运行与对同一文件的反复查看显著相关。
这个发现与近期不少关于测试时缩放的研究遥相呼应:更多的计算、更长的思维链,并不必然换来更好的答案,有时反而放大了干扰与无效循环。对agent而言,一味地堆token,并不是通往更好结果的捷径。
三、哪些模型贵,哪些模型省?
前面的规律是8个模型的整体画像。当研究者把镜头对准每一个模型,又发现了一层更微妙的差异——在完全相同的智能体框架(harness)和完全相同的500个任务下,不同模型的行为竟可以相差悬殊。由于任务本身和agent框架被固定,剩余差异只能来自模型本身在搜索、阅读和决策上的不同策略。
先交代一下这8位"选手"。它们来自五家不同的公司,既有闭源的API模型,也有开源模型:OpenAI的GPT-5和GPT-5.2,Anthropic的Claude Sonnet-3.7、Sonnet-4和Sonnet-4.5,Google的Gemini-3-Pro Preview,Moonshot AI的Kimi-K2(开源),以及阿里巴巴的Qwen3-Coder-480B(开源)。这样的阵容,既能做跨公司的横向观察,也能在Claude、GPT等家族内部做不同代际的纵向观察。
与其说这是一场模型优劣的比拼,不如说它揭示了一个更基础的现象:当外部条件被完全固定下来——同样的harness、同样的任务——模型之间在token使用上的行为差异,依然可以非常显著。把每个模型的token消耗与准确率画在一起,这种差异一目了然:GPT-5和GPT-5.2能以较低的成本取得不错的准确率,而Kimi-K2的成本高昂,准确率却并不出众。在同样的500个任务上,Kimi-K2和Claude Sonnet-4.5平均要比GPT-5多消耗约150万token。
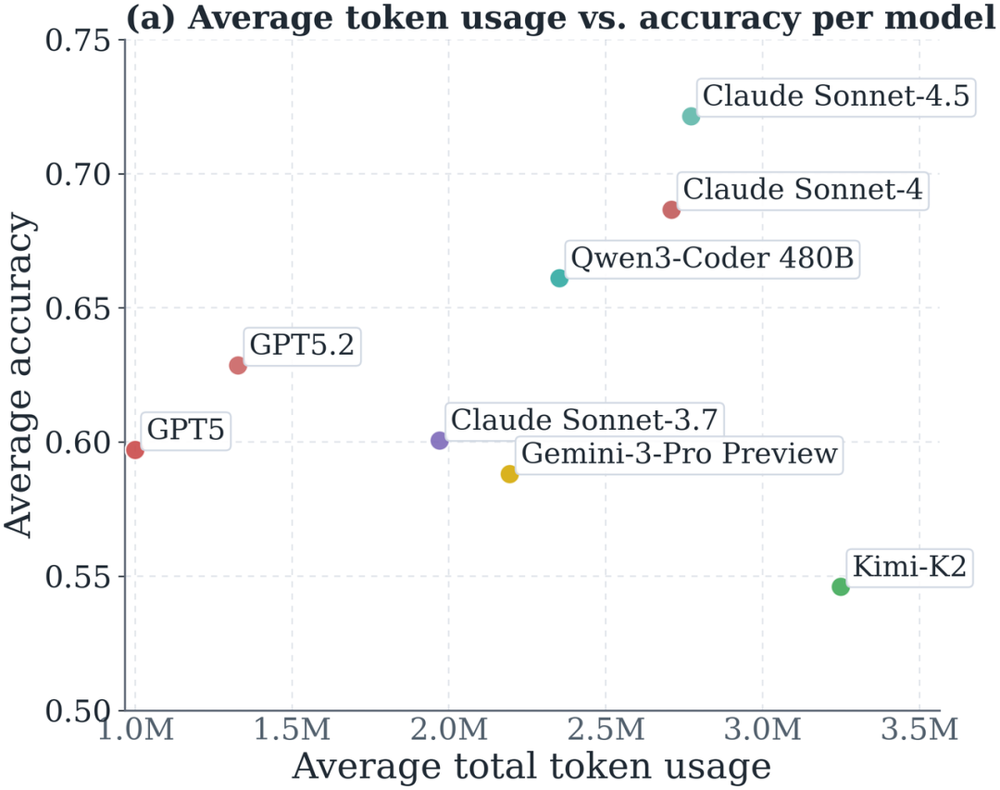
图8:跨全部500个SWE-bench实例的平均总Token用量与平均准确率;每个点代表一个模型。高Token用量并不必然带来更高准确率,Token效率因模型而存在显著差异,反映的是模型自身的行为特性而非任务难度。
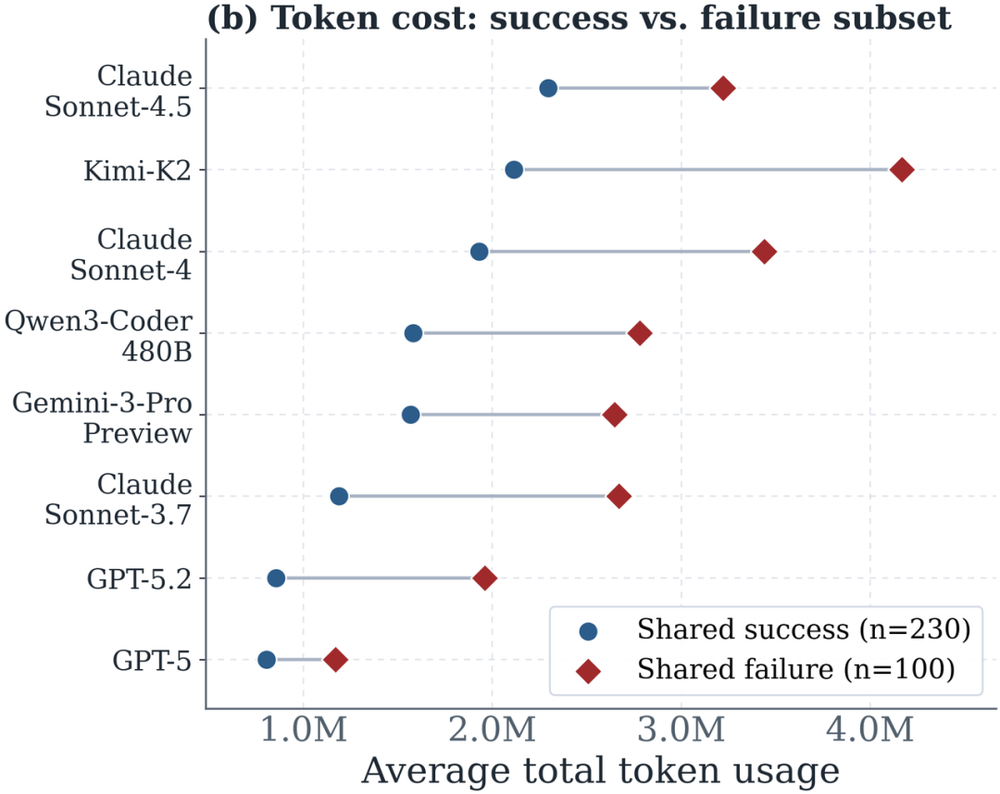
图9:各模型在共同成功与共同失败任务上的Token用量,蓝点表示共同成功子集(n=230,所有模型均解决)的平均Token用量,红色菱形表示共同失败子集(n=100,所有模型均未解决)的平均Token用量。各模型的相对Token用量在两个子集上保持一致,表明Token效率是模型的内在特性。
但这种差异,究竟来自模型本身,还是它们恰好碰上了更难的题?研究者用一个巧妙的设计排除了干扰:他们挑出两个子集:所有模型都成功的题,和所有模型都失败的题,再看各模型的消耗。结果,模型之间的消耗排序几乎纹丝不动。这说明,同一道题对某些模型就是更贵,这是模型自身的行为倾向,而非任务难度使然。此外,所有模型在失败题上的消耗都高于成功题,但"超支"的幅度因模型而异:GPT-5系列只是温和上升,Kimi-K2却暴涨近200万token——它似乎缺乏一种"识时务"的倾向,往往不会在一道注定解不开的题上及时收手,而是继续探索、重试、反复读取上下文,徒然累积成本。
四、能不能在动手前准确报价?
了解了开销的规律,最实际的问题随之而来:在agent动手之前,我们能不能预知这笔账单?这其实和现实中人类工程师在开工前估算预算的程序相同。围绕这个问题,研究者从两个方向做了尝试。
第一个方向,是借助人类的判断。SWE-bench Verified为每道题都标注了人类专家估计的难度,按预期耗时分为"<15分钟""15分钟–1小时"">1小时"三档。一个自然的假设是:人花的时间,约等于agent花的token,那么人类的难度判断,应该能预示agent的开销吧?
然而数据再次出乎意料。研究者计算了token消耗与人类标注难度的相关性,得到的Kendallτ仅为0.32,表明两者只有微弱的关联。更具体地说,有6.7%被标为"简单"的任务,消耗竟超过了"困难"任务的平均值;又有11.1%的"困难"任务,比"简单"任务的平均消耗还低。人类程序员眼中的"难",和AI眼中的"贵",原来是两个并不重合的维度。
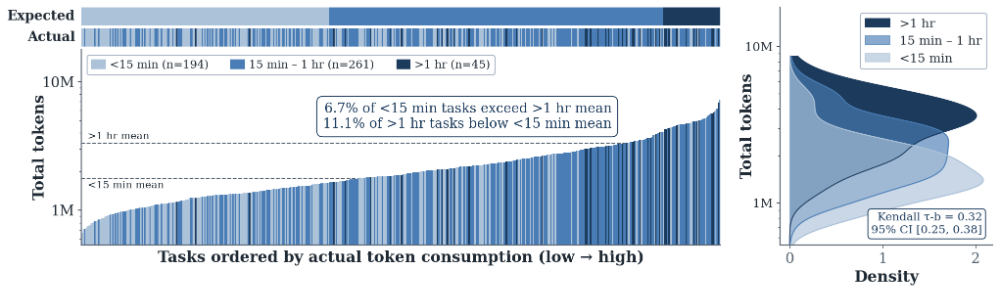
图10:每个竖条代表500个SWE-bench任务之一,按实际Token消耗从低到高排序,并按人工难度评级着色。顶部参考色带显示完全对齐时的预期着色(从浅到深的整洁渐变);其下方的实际着色则呈现出全局混乱的状态。虚线标记了<15分钟和>1小时组的均值。右侧为各难度组的Token消耗密度分布,各组在整个范围内存在大量重叠,表明专家评定的任务难度对智能体Token消耗的预测能力较弱。
第二个方向则更为直接:让agent自己来预测自己。既然外部判断不靠谱,那么最了解agent行为的,不正是agent自己吗?研究者保留了agent全部的工具与运行架构,只是在系统提示词里把任务从"解决问题"换成了"预估开销"。如此一来,agent依然能用同样的工具去探索代码库、运行测试、展开推理,唯独不去真正修复,而是输出一个token估值。
除了预测token消耗本身,这个实验其实也在测试agent的一种"自我意识":一个agent能否在了解自身行为模式的基础上,预判出自己将要付出的代价?
而结果显示,要做到精准预测,仍有很长的路要走:一方面,agent的自我预测确实捕捉到了开销的粗略趋势,但精度十分有限:预测与实际的相关性最高也只有0.39(Claude Sonnet-4.5对输出token的预测),多数模型徘徊在0.2到0.3之间;而且对输出token的预测要比对输入token准确——这并不意外,毕竟输入token的增长更受上下文累积、检索、工具探索等不确定因素的左右。
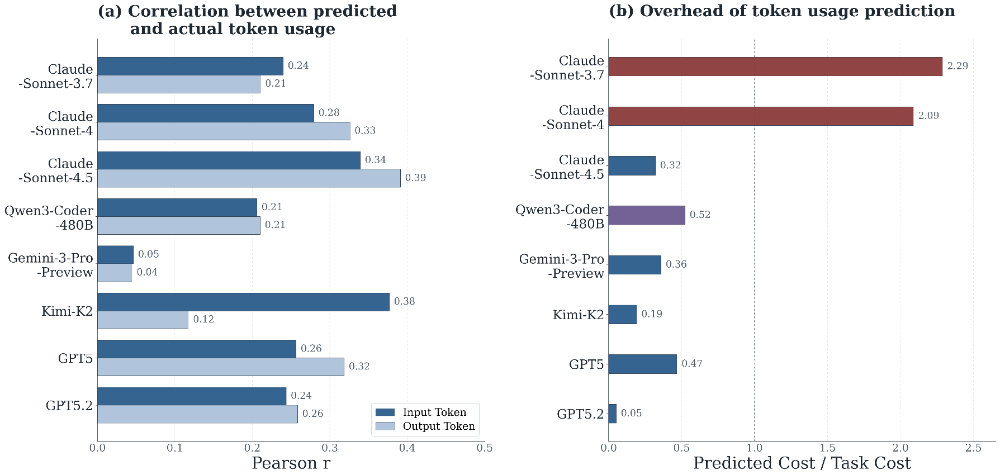
图11:各模型的自预测性能与额外开销。预测Token数与实际Token数之间的Pearson相关系数普遍较低,且自预测的额外开销(以预测成本与实际任务成本之比衡量)不可忽视,表明在执行前预测Token用量对所有测试模型而言均具有较大挑战性,预测效率仍有较大提升空间。
另一方面,几乎所有模型都系统性地低估了自己的真实消耗,对输入token的低估尤为严重。它们仿佛总是过于乐观,料想不到长程任务中上下文会膨胀到何种地步。
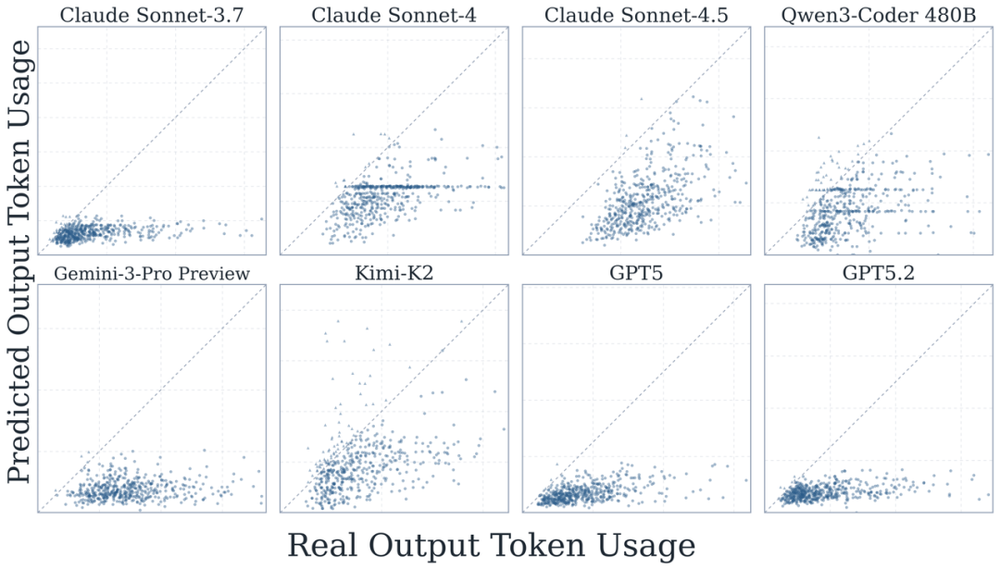
图12:各模型预测输出Token用量与实际用量的对比散点图,对角线表示完美校准基准。各模型普遍存在对输出Token用量的低估现象,但预测值与实际值之间仍具有一定相关性。
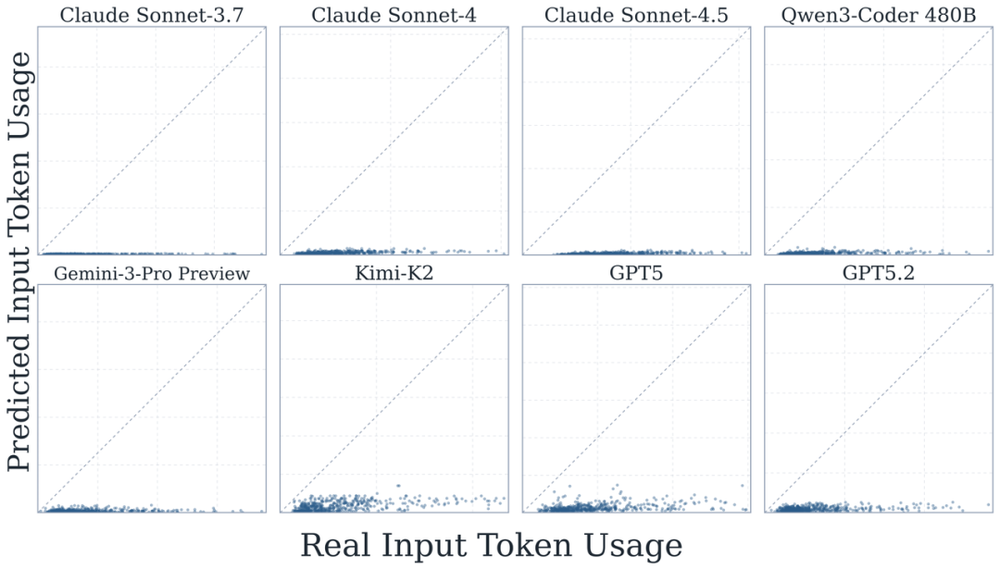
图13:同左图,但针对输入Token用量。与输出Token相比,输入Token的预测表现明显更差:几乎所有模型的预测值均严重偏低,散点高度集中于横轴附近,表明模型对输入Token用量的估计能力极为有限。
至于预测本身的成本,早期的Sonnet-3.7和Sonnet-4一度要花掉超过任务本身两倍的代价去做一次预测——这显然得不偿失,好在较新的模型都没有这种问题,大多数模型的预测开销低于真正执行任务的一半。
无论是依靠人类专家,还是依靠agent自己,目前对token消耗的预测都只能作为一种粗粒度的信号,离精确的"事前报价"还有相当的距离。
延伸讨论:
账单背后,需要的是透明、高效与自知
这些发现,也为未来的研究指向了几个值得探索的方向。
从实用的层面看,它直指当前AI agent商业模式的软肋。订阅制之所以能在ChatGPT这类产品上行得通,是因为普通用户的消耗大体可预测、有上限。但agentic任务则正在打破这个前提:哪怕一个看似简单的问题,也可能因为反复的推理与工具调用而烧掉巨额token。研究表明,token消耗既高度多变,又难以预测,这使得纯粹的“事前定价”在短期内难以实现,按量计费很可能仍是最现实的选择。但这并不意味着用户只能被动接受。即便无法精确报价,agent哪怕只能粗略地识别出"这是一个高开销任务",也足以让系统在执行前发出预警、请求用户确认,或提供更经济的备选方案。再配合"预算感知"的工具调用策略,从运行时层面约束token的失控增长,透明与可控就并非遥不可及。
不过,成本预测的意义并不局限于商业定价。更深一层看,它实际上涉及智能体是否能够理解并预测自己的行为模式。这项研究无意间触碰到了一个关于AI本质的问题。让agent预测自己的开销,表面上是个成本估算任务,内里却是一种“行为自我意识”(behavioral self-awareness),一个智能体能否足够清楚地认识自己,以至于能预判自己将如何行动、将消耗多少资源?事实上,这种自我认知有着许多的场景:对成本的感知、对预算和规划的感知、乃至对自身能力边界的感知(能否知难而退及时止损?)。它们共同构成了自主智能体走向成熟的重要标志:一个懂得预估代价、心中有“预算”的agent,也更懂得规划与取舍,知道一个任务是否值得尝试,知道在何时该停下来。
而实验给出的答案,表明这条路还很长:今天最先进的模型,依然不太"认识"自己。它们能感知大致的方向,却看不清具体的轮廓;它们总是过于乐观,低估前路的曲折。这种"自知之明"的缺失,与前面发现的另一个现象彼此呼应,模型往往不知道何时该在一道解不开的题上收手。看清自己要花多少,与知道自己何时该停,或许本就是同一种能力的两面,而这也正是值得深入开掘的研究空间。
随着AI agent从编程走向更广阔的场景,token消耗的问题只会愈发凸显。如何设计更高效的agent,如何建立更可靠的开销预测与管理机制,将成为这一领域绕不开的课题。而在这一切之下,那个更根本的追问始终回响:我们能否造出一个既能替我们高效工作、又能意识到自己账单的AI?
参考文献
arXiv论文:https://arxiv.org/pdf/2604.22750
项目网站:https://longjubai.github.io/agent_token_consumption/
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。