2026-06-11 21:00

本文来自微信公众号:AIGC从0到1,作者:王零壹,原文标题:《AI 的token账单,终于藏不住了》
过去三年,很多人讨论 AI,还是习惯问一个问题:
谁的模型最强?
谁的 benchmark 更高?
谁的上下文更长?
谁的 coding 能力更接近“自动程序员”?
但最近几条新闻放在一起看,我觉得这个问题已经不够了。
6月9日,Claude Fable 5 发布之后,市场的反应很有意思。
它当然更强,支持更长上下文,面向更复杂的长时间 agent 任务。但与此同时,它也带来了更高价格、更严格限制、usage-based billing、数据保留、安全回退、企业合规顾虑,以及开发者对“限额、降级、回退不透明”的反弹。
这件事像一个现场样本,把 AI 行业下一阶段的矛盾一次性暴露出来:
模型越来越强,但调用最强模型的成本、风险和治理压力,也越来越无法被忽略。
所以这篇文章想讨论的是:AI 正在从能力竞赛,进入 Tokenomics 竞赛。
也就是,智能不再只是“能不能做到”的问题,而是“用多少 token、多少算力、多少时间、多少重试、多少人工兜底,才能把一个真实任务稳定完成”的问题。
一、Claude Fable 5 是一个很好的引子
Claude Fable 5 之所以适合做引子,因为它把前沿模型的经济问题直接摆到了台面上。
Fable 5 支持 1M token context、最高 128k 输出,价格为每百万 input tokens 10 美元、每百万 output tokens 50 美元。
这已经不是“便宜问答工具”的价格结构。
它更像一种高端生产资料。
更关键的是,Fable 5 还伴随着一整套限制:
-使用额度。
-安全分类器。
-fallback。
-billing credit。
-task budgets。
-effort control。
-30 天数据保留。
-不支持 zero data retention。
这些词放在一起,说明前沿模型已经不再只是一个 API。
它更像一个需要预算、审批、调度和审计的智能资源。
以前很多人使用 AI 的方式是:既然我买了,就尽量多用;既然最强模型效果最好,那就默认用最强模型。
但 Fable 5 这类模型正在提醒企业和开发者:最强模型不是免费的水电煤。
它是一种昂贵、稀缺、需要分配的能力。
二、Citadel 说的 Tokenomics,到底是什么意思
这几天,一份 Citadel Securities 的 “Tokenomics” 报告在华尔街广泛传播。
我没有看到完整公开版报告,但根据公开转述和 Citadel 相关公开文章,可以把它的核心意思压缩成一句话:
AI 采用的瓶颈,正在从“模型原则上能做什么”,转向“企业能不能负担每次真实任务的智能成本”。
过去大家看 AI,经常看模型能力曲线。
比如:
-它能不能写代码?
-能不能推理?
-能不能读长文?
-能不能做 agent?
-能不能替人完成一部分工作?
这些问题当然重要。
但当模型真的进入企业工作流之后,另一些问题会变得更重要:
-做到一次要多少钱?
-失败重试要多少钱?
-长上下文会烧掉多少 token?
-多轮 agent 会不会无限循环?
-工具调用失败后谁兜底?
-是不是每个任务都必须用最贵模型?
-账单能不能预测?
-合规风险能不能接受?
我会把 Tokenomics 的核心公式写成这样:AI 任务经济性 = token 单价 × token 消耗 × 重试率 × 模型路由组合 ÷ 真实业务产出。
注意,这里真正关键的不是“每百万 token 多少钱”。
而是“每完成一个成功任务,到底花了多少钱”。
一次客服工单。
一次代码合并。
一次销售线索判断。
一次法律合同审查。
一次财务报销审核。
一次代码迁移。
这些任务会包含上下文读取、计划、工具调用、检查、修改、重试、验证、人工复核。
这时,token 成本就不再是后台小数字,而是直接进入业务毛利、产品定价和企业预算。
三、企业不能再无限量试用
企业的心态也变了。
早期很多公司用 AI,更像创新预算:先试,先上,先让员工用起来。
今天越来越多企业开始问:这个东西进了生产系统以后,账怎么算?
Deloitte 给 CFO 的观点很典型:AI tokenomics 不只是技术成本,而会进入 P&L、资本配置、TCO、运营模式和风险管理。
CFO 不一定要盯每一个 token,但必须知道:AI 支出增长背后有没有清晰的价值链,是否对应明确业务场景。
Bain 的调研也能说明这种矛盾。
很多 CFO 仍计划提高 AI 支出,但很多企业实际获得的成本节省低于预期。也就是说,预算没有停,但“只要用了 AI 就一定降本”的叙事变弱了。
真实案例已经开始出现。
Uber 的 AI coding 工具预算快速超支。
Priceline 续约 Cursor 时成本大幅上升。
JPMorgan 有员工的 token 花费甚至高过工资。
这些案例说明企业要把 AI 纳入成本治理。
未来企业不会再简单给所有员工开最强模型,然后任由大家随便烧 token。
实际上,现在很多的企业都开始在实行一种策略:
不同岗位不同额度。
不同任务不同模型。
低风险任务走便宜模型。
高价值任务才升级到前沿模型。
敏感数据进入合规模型或私有部署。
长程 agent 设置预算上限。
每个任务都要有成本、成功率和人工兜底指标。
企业方的真实观点可以概括为一句:AI 必须用,但不能再按“无限云资源 + 无限上下文 + 无限试错”的方式用。
四、开发者不是反对强模型,而是反对不可预测
开发者可能是最愿意为强模型付费的一群人。
问题是,开发者需要稳定性和可预测性。
模型行为不能悄悄变。
默认 reasoning effort 不能今天 high、明天 medium。
system prompt 不能偷偷改,导致 coding quality 下降。
缓存策略不能出错,让模型忘掉之前的 thinking。
安全回退不能静默发生,让用户以为自己还在调用同一个能力水平的模型。
限额不能模糊。
账单不能失控。
这些并不是小抱怨。
对于开发者来说,AI coding agent 不是玩具,而是工作流的一部分。一个模型如果今天表现很好,明天突然变懒、变笨、变啰嗦、变得不敢做,开发者会立刻感受到。
Claude Code 之前的争议就说明了这一点。
Anthropic 自己在 postmortem 中承认,质量问题来自几类变化:默认 reasoning effort 从 high 降到 medium、缓存优化错误、减少 verbosity 的 system prompt 伤害了 coding quality。
这件事本质上就是 token economics。
更高 reasoning effort 通常意味着更高 token 使用、更高延迟、更高成本。
厂商想控成本。
用户想要质量。
开发者想要稳定。
这三者之间天然有拉扯。
还有一个更具体的成本黑洞:agentic coding 的 token 消耗并不只发生在“写代码”那一步。
很多 token 会花在 review、test、retry、tool calling、修复、再验证上。
也就是说,真正贵的不是模型回答一次,而是 agent 在复杂工程里来回跑。
所以开发者真正要的不是“永远无脑用最贵模型”。
他们要的是三件事:
第一,模型行为稳定。
第二,账单可预测。
第三,限制透明。
开发者可以接受安全限制、预算上限、模型回退。
但不能接受“表面上还是同一个模型,实际上已经被降级、改写或隐性节流”。
五、模型厂商正在变成智能电网运营商
站在模型厂商角度,这件事更矛盾。
他们必须不断推出更强模型。
因为资本市场、开发者、企业客户都在问:你是不是还领先?
但他们又不能让所有用户无限调用最强模型。
因为前沿模型的推理成本、数据中心压力、安全成本和合规成本都是真实存在的。
所以模型厂商正在做一件事:
把智能拆成不同服务等级。
OpenAI 的价格阶梯、cached input、Batch API、Flex processing,本质上都是这种趋势。
Anthropic 的 usage credits、effort control、task budgets、fallback,也是在做同一件事。
未来模型厂商会越来越像“智能电网运营商”。
它们不只是卖一种电。
它们会卖:
-高峰电。
-低谷电。
-缓存电。
-批处理电。
-高优先级电。
-低延迟电。
-合规专区电。
-前沿智能电。
-便宜日常电。
这听起来像比喻,但方向很真实。
未来企业买 AI,不会只买“一个最强模型”。
而是买一整套智能调度系统:
什么任务用便宜模型。
什么任务用中端模型。
什么任务升级到前沿模型。
什么时候用缓存。
什么时候批处理。
什么时候必须人工复核。
什么时候因为合规原因不能调用某个模型。
这就是 AI 模型产品的第二次产品化。
第一次产品化,是把模型能力包装成聊天框、API、copilot、agent。
第二次产品化,是把模型调用变成可预算、可审计、可路由、可降级、可缓存、可解释的生产系统。
六、投资者看到:估值锚变化
从投资角度看,Tokenomics 也不等于“AI 没戏了”。
更准确地说,是 AI 估值逻辑正在变化。
过去市场更愿意为能力突破买单。
谁模型强,谁叙事强。
谁训练规模大,谁融资顺。
谁发布新 benchmark,谁获得市场关注。
但接下来,投资者会越来越多问:
-收入能否覆盖推理成本?
-应用层毛利会不会被模型成本吃掉?
-客户是否愿意为 AI 成果付费,而不是只为 seat 付费?
-模型降价会不会导致收入增长和利润率拉扯?
-数据中心、电力、内存、GPU 需求是否真的能被终端需求消化?
-agent 是否带来 5–30 倍 token 消耗?
这并不是看空 AI。
而是从“能力叙事”进入“单位经济模型叙事”。
J.P. Morgan Asset Management 的态度更像中性偏乐观:AI 交易会更波动,市场担心可持续性,但大规模 capex 仍由采用率和工作负载增长支撑。
Gartner 的判断也能把两边连起来:未来单 token 推理成本可能大幅下降,但 agentic models 每个任务消耗的 token 也可能远高于普通 chatbot。
这就是关键矛盾:
token 单价下降,不代表 intelligence 总成本下降。
因为当 AI 真正进入生产系统后,使用量会暴涨,任务会变复杂,agent 会多步执行,模型会反复验证,企业会要求更高可靠性。
单价下降,可能被总量增长吃掉。
所以投资者会更挑剔。
算力、电力、内存、数据中心仍然有长期需求。
但应用层公司如果把昂贵模型成本内嵌进产品,又无法把成本转嫁给客户,毛利率会受到压力。
模型公司如果靠降价抢客户,也会在收入增长和利润率之间拉扯。
赢家不会只是“模型最强”的公司。
赢家会是能把模型能力变成可控成本、可衡量产出、可持续毛利的公司。
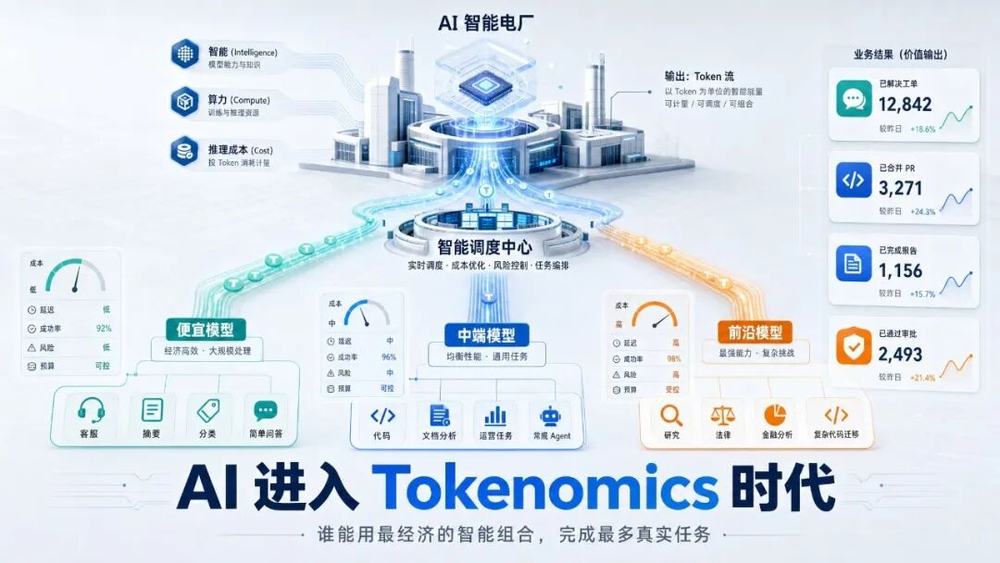
七、未来主流架构:三层模型,而非一个模型打天下
我认为未来 1–3 年,最主流的 AI 产品架构会变成三层。
| 层级 | 负责什么 | 典型任务 |
|---|---|---|
| 便宜模型 | 日常吞吐 | 分类、摘要、格式转换、简单问答、低风险客服 |
| 中端模型 | 大多数生产工作 | 代码补全、文档分析、常规 agent、销售运营任务 |
| 前沿模型 | 高价值疑难任务 | 复杂代码迁移、深度研究、法律尽调、金融分析、关键验证 |
这个架构的核心,是任务分层。
不是所有任务都值得调用最强模型。
不是所有任务都能交给便宜模型。
真正有价值的是中间那层调度系统:
-router。
-evaluator。
-memory。
-budget manager。
-governance layer。
它决定一个任务先用哪个模型,什么时候升级,什么时候停止,什么时候人工接管,什么时候缓存,什么时候因为合规原因换模型。
未来很多 AI 产品的核心竞争力,不会只体现在“用了哪个模型”。
而会体现在:
它能不能把任务切得足够细。
能不能判断任务难度。
能不能估算成本。
能不能控制失败重试。
能不能把前沿模型留给真正值得的地方。
能不能让用户感觉稳定,而不是每天像抽盲盒。
八、模型价格会让位于任务价格
今天模型厂商主要按 token 定价。
每百万 input tokens 多少钱。
每百万 output tokens 多少钱。
但企业真正想买的,不是 token。
企业想买的是结果。
一张客服工单解决多少钱?
一个 PR 合并多少钱?
一次代码迁移多少钱?
一份合规报告多少钱?
一次销售线索判断多少钱?
每降低 1% churn 要花多少 inference?
这意味着未来 AI 产品会越来越强调 task-level telemetry。
也就是任务级监控:
-cost per resolved ticket。
-cost per accepted PR。
-tokens per successful workflow。
-retry rate。
-fallback rate。
-human-review rate。
-frontier-model usage share。
这套指标会从工程团队内部工具,变成企业采购、CFO、FinOps、业务负责人共同关心的问题。
Linux Foundation 拟成立 Tokenomics Foundation,也说明这件事正在制度化。
token 支出不再只是开发者吐槽账单。
它会变成 AI 基础设施的标准化问题。
九、预算优先,会成为开发者工具的新范式
未来 coding agent 或企业 agent 里,会出现越来越明确的预算控制项。
比如:这个任务最多花 3 美元。
先用 cheap mode,失败再升级。
最多跑 8 次 tool call。
review 阶段最多消耗 20k tokens。
只在 CI failure 后调用高阶模型。
把 reasoning effort 显示出来,不要偷偷改默认值。
这个方向很重要。
过去开发者工具强调的是“能力优先”。
能不能写代码?
能不能理解项目?
能不能自动修 bug?
未来会变成“能力 + 预算 + 可预测性”一起看。
一个 agent 即使很强,如果它每次跑起来都不知道会花多少钱、会跑多久、会不会降级、会不会静默回退,企业也不敢大规模铺开。
因此,未来的好 AI 工具不会只说:
我能完成任务。
它还必须告诉你:
我准备用什么模型完成。
预计花多少钱。
最多花多少钱。
失败后怎么升级。
什么时候需要你确认。
哪些数据会被保留。
哪些动作会被审计。
这才是 production AI 应该有的样子。
十、小模型和私有部署会重新升值
Tokenomics 还会带来另一个结果:
小模型、专用模型、开源模型、私有部署会重新升值。
经济学原因。
高频、低复杂度、低风险任务,不值得每次都调用前沿模型。
企业内部大量任务其实不需要 Fable 5 或 GPT-5.5 级别能力。
它们需要的是:
稳定。
便宜。
低延迟。
可控。
可部署在私有环境。
能接企业内部系统。
这会让很多基础技术变得更重要:
RAG。
知识图谱。
prompt caching。
context compression。
fine-tuning。
distillation。
quantization。
speculative decoding。
KV cache 优化。
多模型路由。
私有化部署。
这些东西听起来不如“最强模型发布”性感。
但它们会决定 AI 能不能进入企业利润表。
十一、AI进入了筛选期
AI 能力扩张还会继续。
模型还会变强。
上下文还会变长。
agent 还会变得更能做事。
但“无纪律地调用最贵智能”的时代正在结束。
未来的赢家,是能把智能拆成不同价格、不同风险、不同延迟、不同可信度层级,并把它们编排进真实业务结果的公司。
所以我对未来模型发展的预言是:
模型会继续变强,但默认使用会变便宜;前沿智能会更稀缺、更受控、更高价;日常智能会更普及、更本地化、更自动路由;真正的竞争核心,会从“谁有最强模型”,转向“谁能用最经济的智能组合,完成最多真实任务”。
这就是 Tokenomics 这条线真正重要的地方。
AI 已经重要到必须进入成本表、预算表、治理表和业务结果表。
当一个技术开始被严肃算账,它才真正进入生产时代。
本文来自微信公众号:AIGC从0到1,作者:王零壹(港大AIBT研究生,ex上市公司CMO,《AIGC从0到1》作者,中文互联网第1个意识到OpenClaw价值的人,专注AI时代的商业模式与产品架构,主张"用AI,不AI"。“AIGC从0到1”由<范式><范性><范本>组成,是浪潮中的真实记录)
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。