2026-06-19 12:34

本文来自微信公众号: 歪睿老哥 ,作者:歪睿老哥
俄勒冈州,STEEL实验室。一台透射电镜(TEM)正在对一颗华为Mate 80 Pro上的麒麟9030做横截面扫描。这是SemiAnalysis第一个公开的芯片拆解报告,也是中芯国际N+3工艺第一次被完整地、赤裸地摊在阳光下。
距离中芯被曝出量产7nm级芯片(N+1)已经过去四年。四年后,N+3来了,搭载在华为最新的旗舰上。
没有EUV光刻机,中芯国际到底走到了哪一步?付出了什么代价?这份报告给了我们一个极其清晰的答案。
一个被精心挑选的“胜利”
先看最抓眼球的数据:中芯N+3的M0 pitch(最小金属间距)只有32.5nm,比Intel 18A在Panther Lake上量产的36nm还要小大约10%。
消息一出,不少人大呼“反超英特尔”。但SemiAnalysis的结论很冷静:这是一个被精心挑选的指标,以偏概全了。
M0是芯片最底层的局部互联层,相当于摩天大楼的地基管线。但芯片从M0到M13有十几层金属,每一层的间距都很重要。只拿M0说事,好比比较两辆车的最高时速来断定谁更好——避开了油耗、操控性和可靠性。
更何况,Intel 18A的M0之所以大,是因为它用了背面供电(PowerVia)。电源线翻到背面后,正面金属层全部解放出来走信号,布线压力大大减轻。Intel是主动选择做松一点,换取更简单的工艺和更好的良率。
这是取舍,不是落后。
那么,抛掉这个“精神胜利法”,N+3真实水平如何?
中芯N+3的最小金属间距M0 pitch只有32.5nm,确实比Intel 18A在Panther Lake上量产的36nm还要小大约10%。
这个数据本身是真的,但单独拿这一个指标出来说事,就有点以偏概全了。
M0是芯片里最底层的局部互联层,就在晶体管上面,负责标准单元内部的信号连接。芯片里从M0到M13有十几层金属,每一层的间距都很重要。只拿M0 pitch对比,就好像比较两辆车的最高时速来断定谁更好——避开了油耗、操控性、可靠性和安全性。
而且Intel 18A的M0 pitch之所以大,有一个重要原因:它用了背面供电PowerVia。电源线翻到芯片背面后,正面金属层全部解放出来做信号走线,布线压力大大减轻。所以Intel是主动选择把M0做松一点,换取更简单的工艺和更好的良率,这是一种取舍。
那么,中芯N+3的真实水平到底是怎样的?我们一项一项来看。
Die布局分析:面积没变,但塞进去了更多
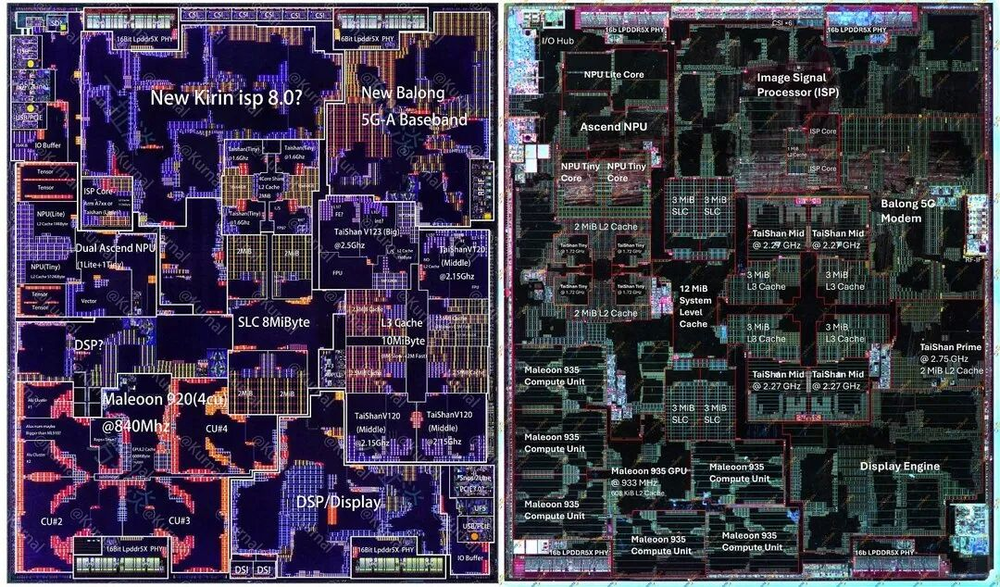
图01/40:Kirin 9020 vs 9030 die标注对比
从die布局看,麒麟9030的面积和9020几乎一样大。但N+3的密度提升,让华为在相同空间里塞进了更多功能:
CPU:多了一个中核(3核→4核),大核L2缓存从1MiB翻倍到2MiB;
GPU:计算单元从4个增加到6个,新增硬件光追;
NPU:从1Lite+1Tiny回到1Lite+2Tiny,重回多核路线;
缓存:L3从10MiB增至12MiB,SLC每bank从2MiB增至3MiB。
作为对比的台积电N6工艺联发科Helio G99,面积只有29mm²,大约是麒麟9030(140mm²)的五分之一。这辆“基准车”虽然小,却提供了一个极好的性能参照系。
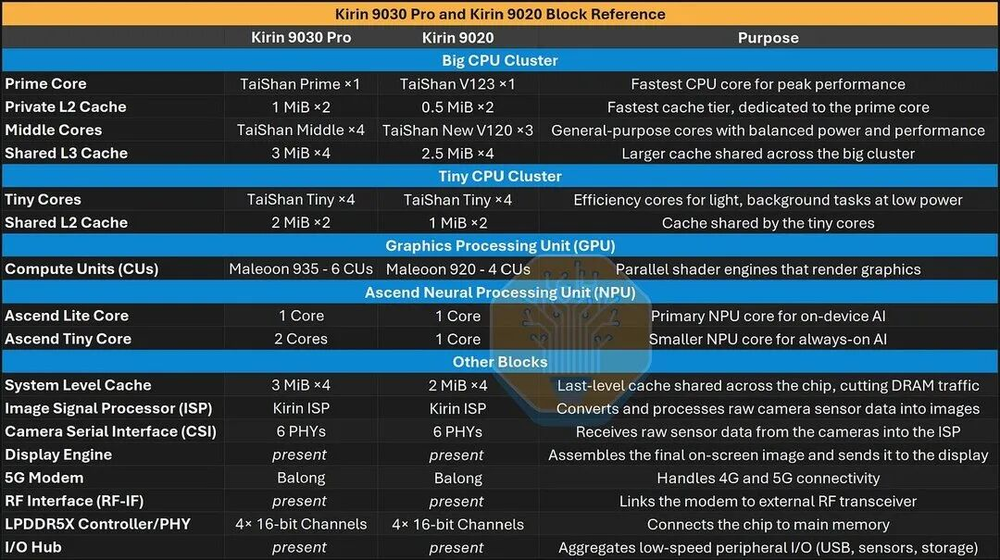
图02/40:Kirin 9030与9020 block功能标注
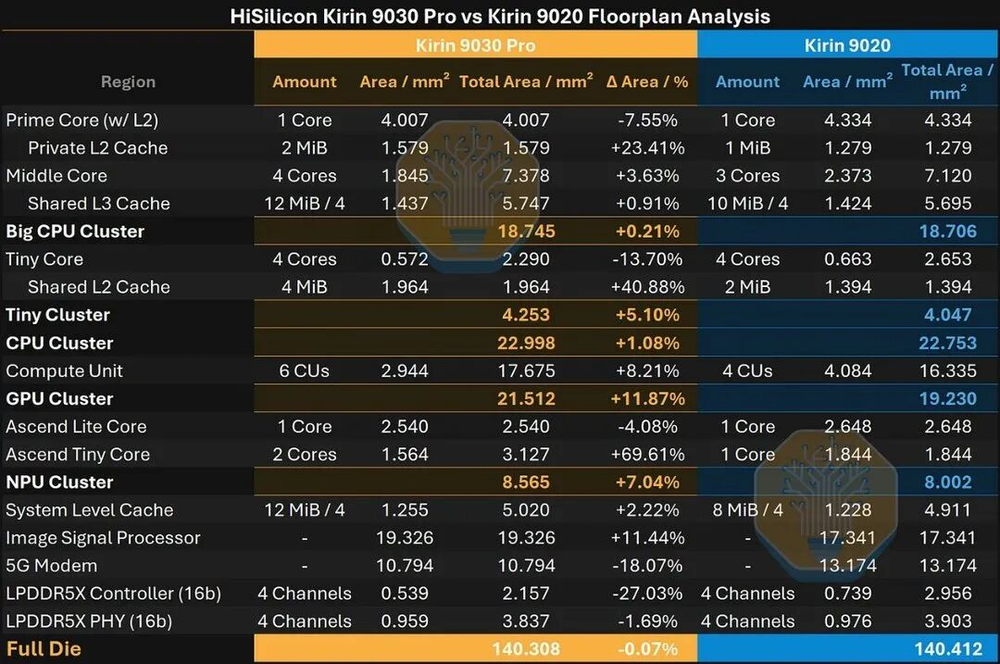
图03/40:Kirin 9030 vs 9020 floorplan分析
通过die shot可以清楚看到麒麟9030和9020的floorplan差异。每个功能区块的面积分配反映了华为在受限条件下的设计权衡:CPU集群面积基本不变但核心更多,GPU集群明显扩大,NPU也回到了早期多核设计。
作为对比的Helio G99只有大约29mm2,是麒麟9030约140mm2的四分之一到五分之一。但G99用的是台积电N6工艺,提供了一个极好的N6性能基准。

图04/40:MediaTek Helio G99 die标注
CPU核心:进化迭代,性能仍有差距
麒麟9030的大核(Prime)频率从2.5GHz提到2.75GHz,L2翻倍。即便缓存增加,核心面积反而缩小了7.6%。除去私有L2,核心面积缩小了21%——对于增量节点来说,相当不错。
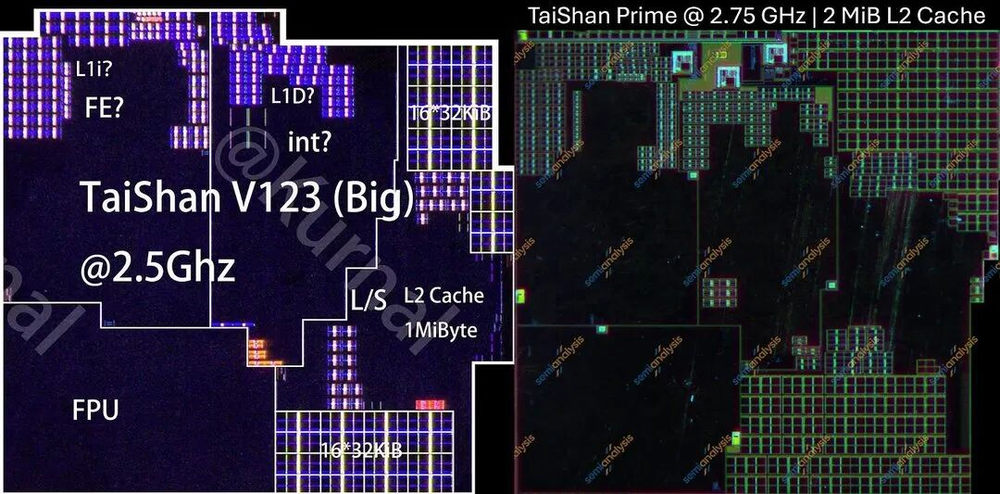
图05/40:TaiShan V123 Prime核心对比
中核架构几乎没变,每个核心缩小约22%,大部分来自N+2到N+3的工艺进步和布局优化。
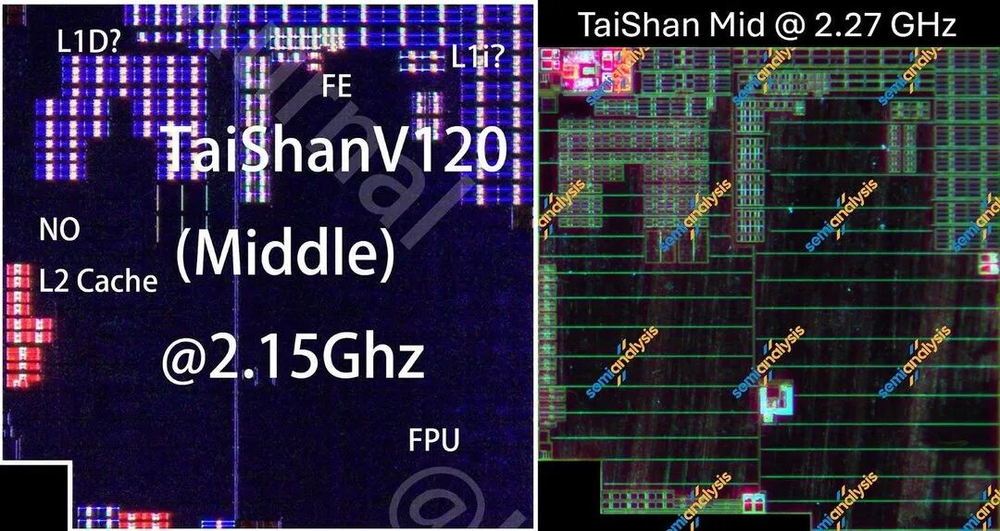
图06/40:TaiShan V120 Middle核心对比
最明显的变化是中核从3个增加到4个,大核集群的共享L3缓存增加了20%。每个核心面积省出来的部分,正好被用来增加核心数量和缓存容量,所以大核集群总面积基本不变。
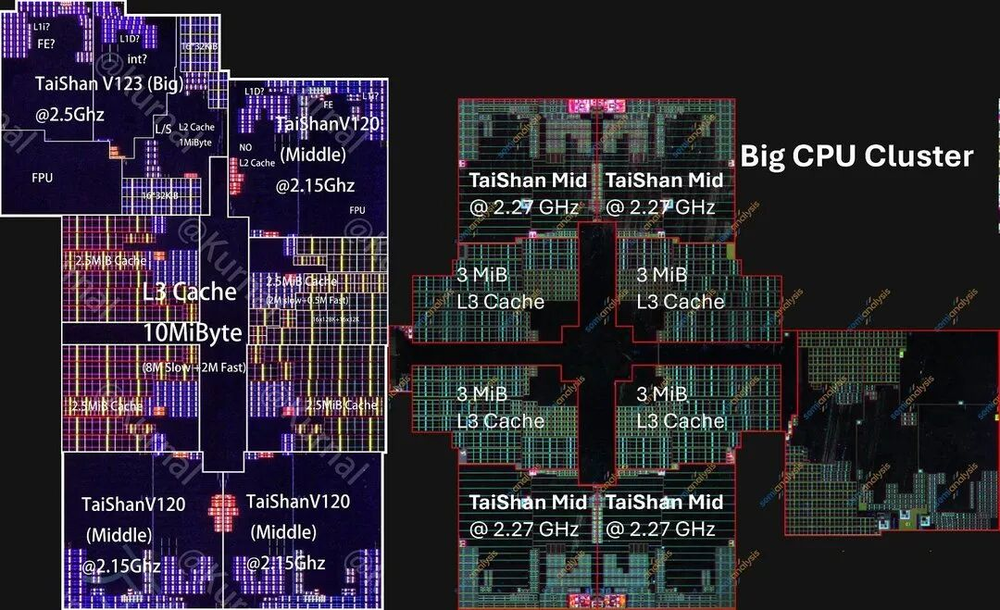
图07/40:CPU大核集群对比
小核缩小幅度较小(约5%),因为固定开销在小核中占比更大。共享L2缓存从2MiB翻倍到4MiB,小核集群总面积反而略大。

图08/40:TaiShan Tiny小核心对比
从性能数据来看,情况就没那么乐观了。麒麟9030的大核单周整数性能大约等于2021年的Cortex-X2水平。对比苹果M1上的Firestorm核心(2020年设计),单周高35%,绝对性能高57%,功耗还差不多(~4.5W)。而现在的苹果M5 P核心单周高60%,绝对性能高2.7倍。
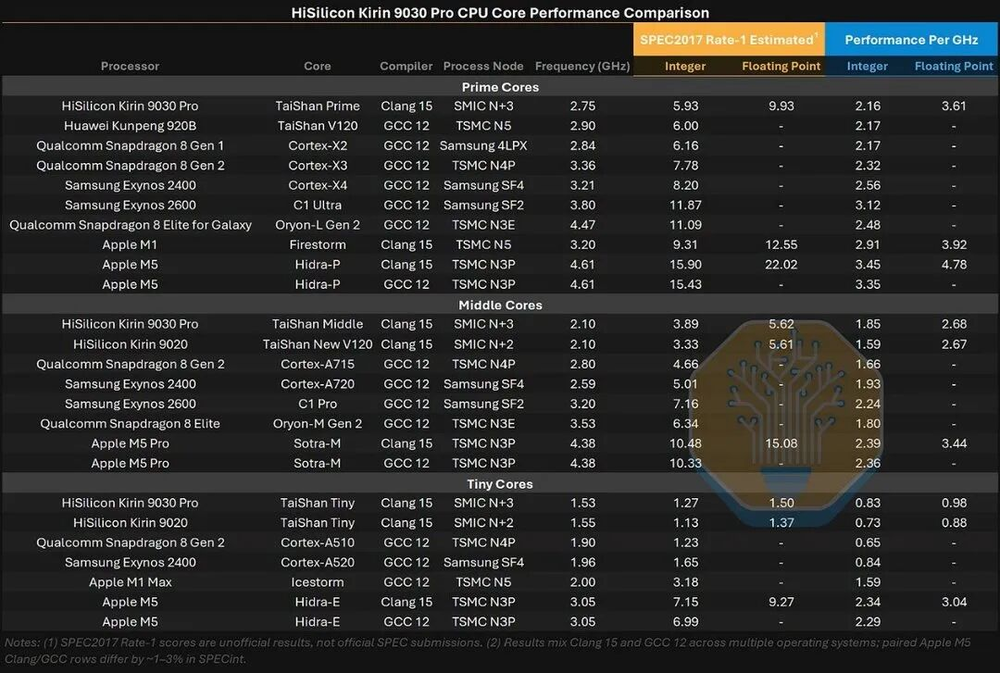
图09/40:CPU单周性能对比数据
最扎心的对比是这个:苹果的E核心——也就是它的低功耗小核——整数性能比华为的大核心还高了20%,功耗只有1W,而华为大核要4.5W。E核心单看效率,已经把华为的大核踩在地上了。
麒麟9030的中核和小核在单周性能上有明显提升:中核整数+17%,小核整数+14%。小核的效率提升很干净——性能上升,功耗下降,整数效率+45%,浮点效率+24%。但中核出现了整数效率反而-7%的情况,因为功耗增长比性能更快。
这些单周性能提升说明华为对核心做了微架构优化,而不仅仅是工艺缩小。但麒麟的核心设计——无论是频率还是功耗——都被N+3的电压-频率曲线卡住了脖子。领先工艺的晶体管可以在更低的电压下跑更高的频率,这是中芯没有EUV的硬伤。
GPU:最大的进步
GPU是这代最大的亮点。
3DMark测试中,Wild Life Extreme提升70%,Steel Nomad Light提升79%。它超过了骁龙8+Gen 1和天玑9200,甚至超过了苹果A16在WLE上的表现。
Maleoon 935已经进入了上一代旗舰GPU的水平,这是麒麟有史以来GPU进步最大的一代。
但和最新旗舰比,差距依然惊人:骁龙8 Elite Gen 5快2.4倍,天玑9500快2.6倍。硬件光追方面,最新旗舰快了3.7倍。

图10/40:Maleoon GPU计算单元对比
GPU计算单元(CU)从4个增加到6个,每个CU面积缩小28%,同时增加了硬件光线追踪支持。但CU外部的控制逻辑和路由面积扩张了33%,所以整个GPU集群反而比9020大了约10%。
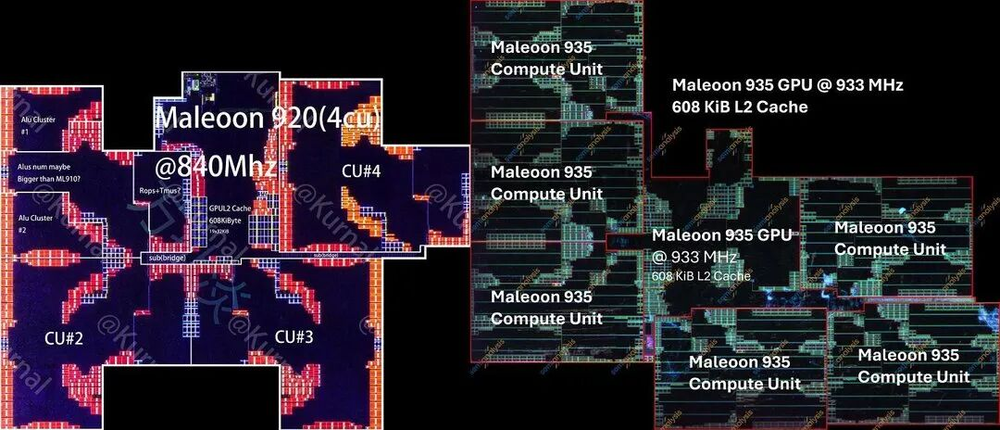
图11/40:Maleoon GPU集群对比

图12/40:GPU性能对比数据
在3DMark测试中,Wild Life Extreme提升70%,Steel Nomad Light提升79%。
它超过了骁龙8+Gen 1和天玑9200,也超过了苹果A16在WLE上的表现。
但和最新旗舰比,差距仍然很大:骁龙8 Elite Gen 5快2.4倍,天玑9500快2.6倍(WLE)。
在硬件光追方面最新旗舰快了3.7倍。
总体上Maleoon 935已经进入了上一代旗舰GPU的水平,这是麒麟系列有史以来GPU进步最大的一代。
NPU:结构调整最大
NPU从1个Lite+1个Tiny变成了1个Lite+2个Tiny核,这是一个有意思的变化。
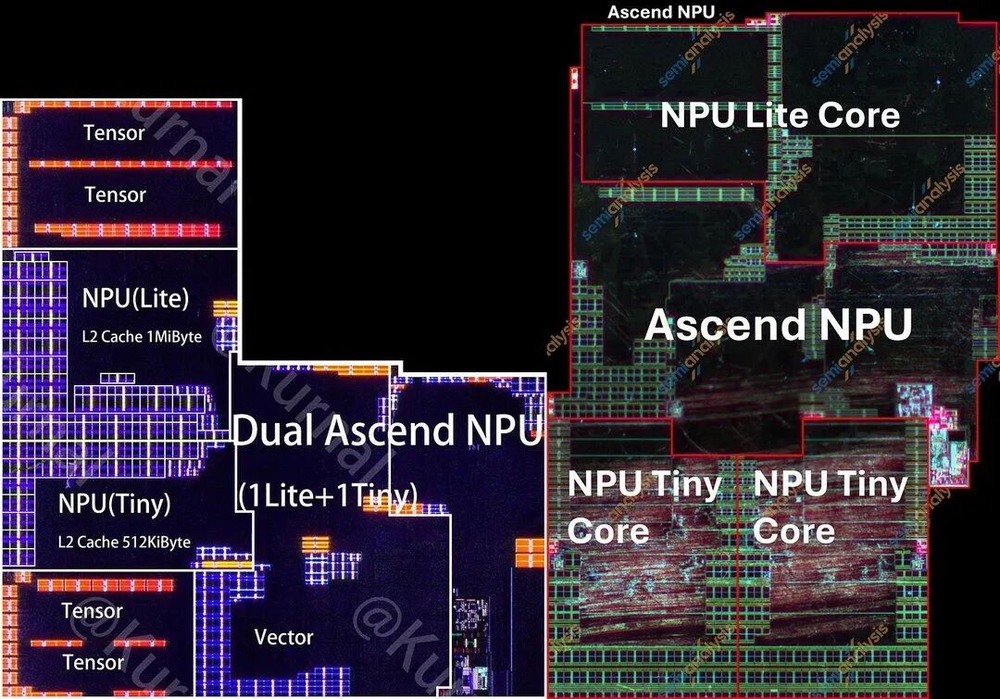
图13/40:Ascend NPU对比
回溯历史,麒麟9000 5G(TSMC N5时代)用的是2Lite+1Tiny。
到了N+2的9000s/9010/9020,华为砍成了1Lite+1Tiny,很可能是为了省面积。
现在N+3上又加回了1个Tiny核,说明华为在面积约束略微缓解后,优先选择了重回多核NPU路线。
内存和封装
麒麟9030 Pro配备了12GB三星LPDDR5X-9600,采用4+4的die堆叠结构,是三星1a工艺(第四代10nm级DRAM,2022年开始量产)。
16GB Pro Max版本则发现了两种封装来源:三星和长鑫存储(CXMT)。长鑫封装标记为CXDD7JEDM,2025年第45周封装,推断为G4工艺,密度约0.3 Gib/mm2,相当于其他厂商的1z工艺水平。这说明长鑫的DRAM存储器已经进入华为旗舰手机的量产供应链。
封装采用集成封装上封装(iPoP)——LPDDR5X DRAM堆叠芯片通过有机RDL中介层封装在SoC上方,再整体焊接到PCB上。整个堆叠全部使用有机材料,没有硅中介层。这么做降低热膨胀系数失配,减少翘曲,也节省了硅中介层的成本。
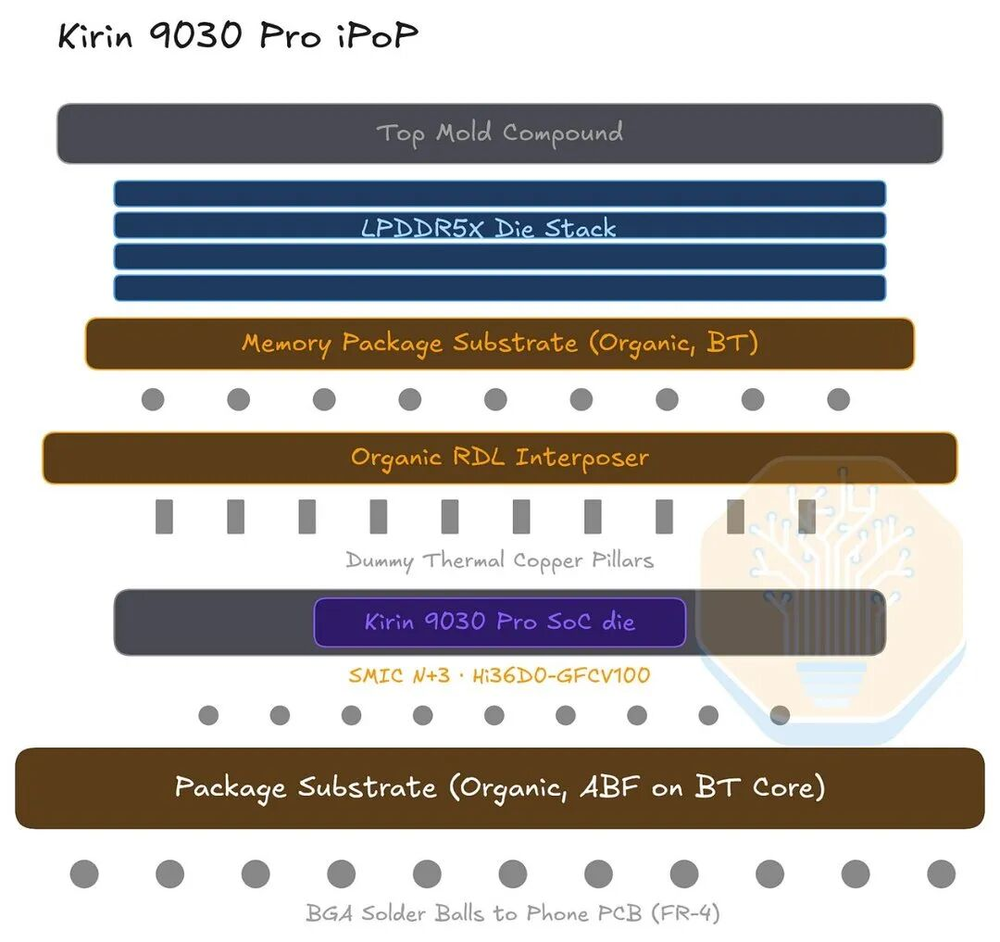
图15/40:Kirin 9030 iPoP封装结构

图16/40:Mate 80 Pro vs Pro Max封装对比

图17/40:封装侧面剖面(DRAM移除后)
鳍片分析:中芯最亮眼的单项
FinFET工艺中,鳍片形状至关重要。理想鳍片应该又高又窄、近乎垂直。更高的鳍片意味着更大的有效沟道宽度和电流驱动能力,更窄的鳍片意味着更好的静电控制。但两者都加大了制造难度——太高容易倒,太细容易断。

图18/40:Intel FinFET架构演进历史
透射电镜图像显示,中芯N+3的鳍片做得相当不错。鳍片高宽比达到了9.5:1,而台积电N6只有7.8:1。N+3的鳍片更窄、更高、顶部更尖锐(顶部圆角半径约2nm,N6是2.8nm)。顶部圆角与鳍片宽度之比N+3是0.37,N6是0.44,比值越低越接近理想矩形。

图19/40:N+3与N6鳍片剖面对比TEM 321.4nm
从几何学角度看,N+3的鳍片确实比N6更接近理想的长方形截面。这算是中芯N+3的亮点。但这个优势并不一定能转化为性能和效率优势,因为还有其他因素在发挥作用。
为了搞清楚N+3的鳍片图案化方案,SemiAnalysis花了大量功夫。CPU核心区鳍片间距约32nm,结合8T SRAM更复杂的重复单元,他们反推出了N+3的图案化流程:一个128nm间距的单一CD掩模版,经过自对准四重曝光SAQP后,产生全芯片约32nm的网格。
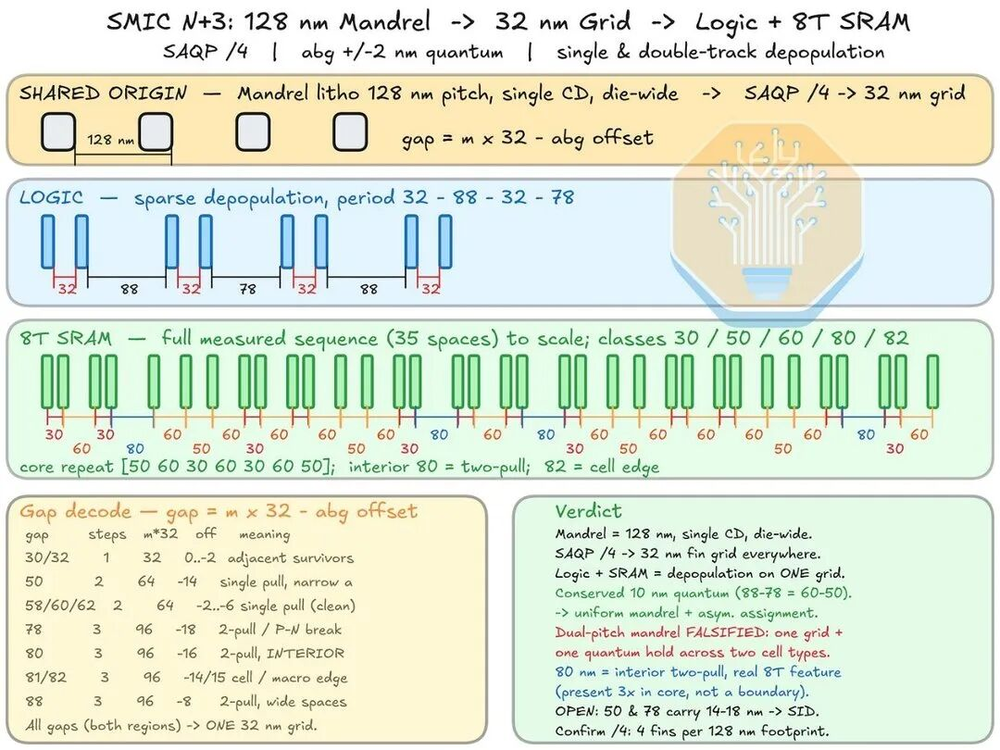
图20/40:SMIC N+3鳍片图案化方案
标准单元:没有EUV,靠DTCO追上密度
标准单元是芯片布图的基本积木块。衡量密度的核心指标有两个:接触栅极间距CGP和单元高度。在Helio G99的Cortex-A55核心中,标准单元高度为240nm,采用了高密度HD库。

图21/40:Helio G99标准单元fin-cut
麒麟9030三个CPU核心的单元高度都是228nm,比N6小了5%,比中芯上一代N+2的252nm缩小了9.5%。接触栅极间距两边都是57nm。
中芯N+3用了两项关键DTCO技术才追上了N6的密度:第一是接触有源栅极(COAG),把栅极接触直接落在有源栅极顶部而不是旁边的隔离区,单元高度因此下降。透射电镜图像确认N+3集成了COAG而N6没有。第二是单扩散断裂(SDB),N+3和N6都用了,只占一个CGP的间距,比传统双扩散断裂省了一半。

图23/40:Gate profile gate-cut对比
通过COAG+SDB两项技术加上更激进的DUV多重曝光,中芯N+3实现了113.4 MTr/mm2的晶体管密度,略超过台积电N6的107.7 MTr/mm2。没有EUV,纯靠DTCO和工艺优化追上了这个密度目标。
金属互连层:多重曝光带来的代价
N+3的M0间距32.5nm,比N+2和N6的40nm缩减了19%。这个尺度已经超出了单次DUV自对准双重曝光(SADP)的能力极限,必须上自对准四重曝光(SAQP)。

图24/40:Lower metals fin-cut对比
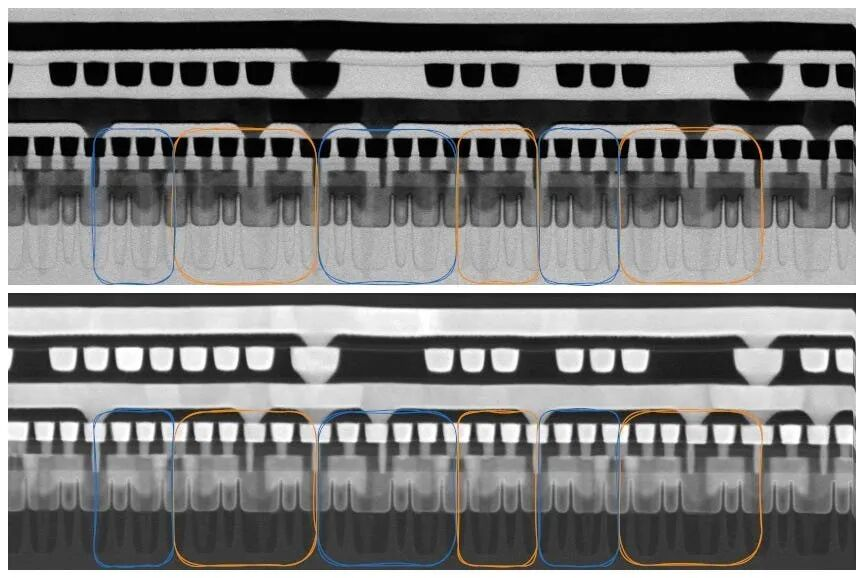
透射电镜图像清楚地显示了SAQP的代价:M0沟槽的侧壁明显更倾斜,底部比顶部窄,沟槽底部与刻蚀停止层的交界处有一层亮色的barrier-rich foot。
这种形状部分是有意为之——略微收窄的底部有助于无空洞的铜填充——但N+3上这种效应的程度远超M1和M2,说明工艺余量已经被压缩到极限了。
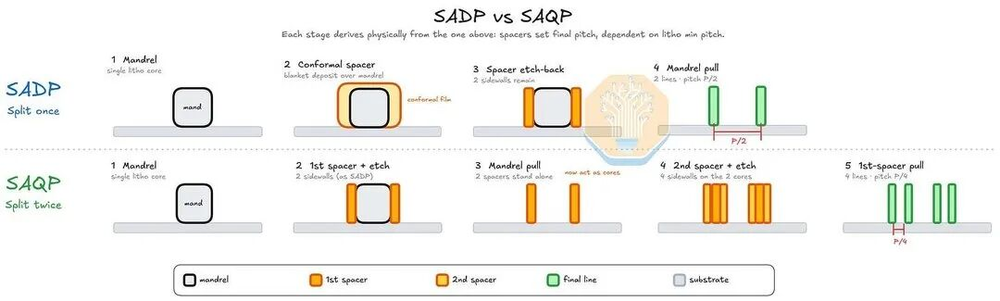
图25/40:SADP vs SAQP多重曝光对比
M1间距38nm,比N+2缩小9.5%,比N6小33%。
这背后的原因是中芯采用了3:2的M1-栅极比例,而N6是1:1。
3:2比例意味着每两个栅极对应三条M1走线,给了单元内更多的布线自由度,但布图和图案化也更加复杂。
这个3:2比例在业界并不流行——TSMC只在N7+和N5家族用过,Intel只在10nm/Intel 7上用过。
目前还在用的除了三星SF4/SF3家族,就是中芯了。
M2间距40nm,和N+2缩5%,和N6持平。M3间距44nm,和N+2一样,但比N6大了10%。M4到M11分布在80nm到148nm的范围。最顶部是M12和M13两个巨厚金属层,间距分别为1920nm和4600nm。
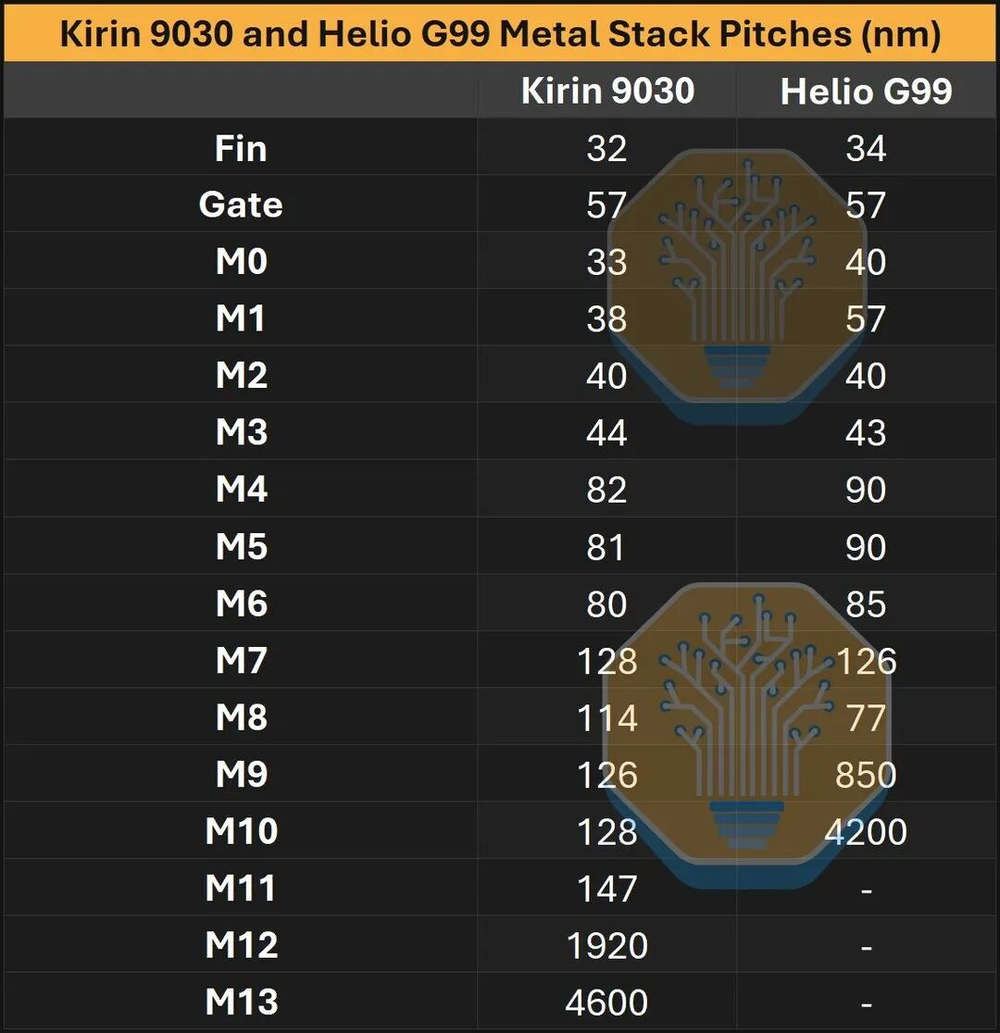
图28/40:金属层间距汇总数据
有趣的是,N+3的金属层栈比N6要多——Helio G99到M9就走到了850nm的间距,而麒麟9030一直到M11才达到这个级别。这反映了旗舰SoC对高性能布线资源的更大需求。
SRAM:意外的8T发现
在分析GPU计算单元时,SemiAnalysis有了一个意外发现。GPU旁边的SRAM不是普通的6T结构,而是8T SRAM。8T比6T多了两个晶体管,构成专用的读端口,彻底消除了读干扰问题,读稳定性更好。
这个8T SRAM的单元结构是1:2:2-2:2——上拉PMOS管1个鳍片,下拉和传输门NMOS管各2个鳍片,再加上各2个鳍片的读下拉和读传输门NMOS管。
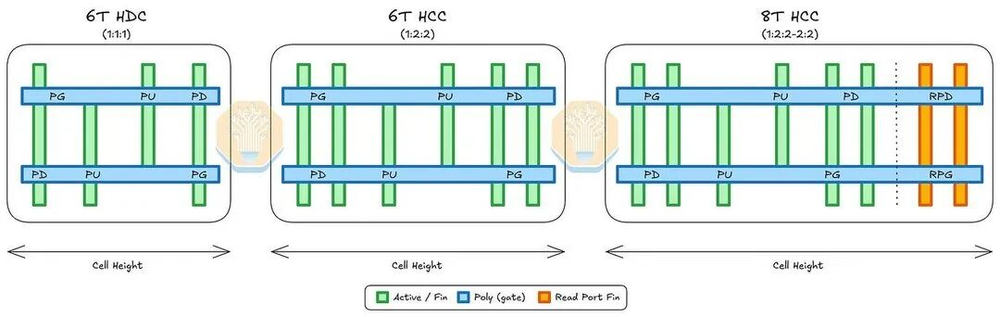
图31/40:6T/8T位单元电路结构对比
测得的单元高度406nm,位单元面积0.0463平方微米。理论上如果改用6T高密度单元(HDC),可以做到0.026平方微米,达到每平方毫米3845万比特的密度——正好和逻辑标准单元高度228nm一致。这个数字和三星7LPP/5LPP差不多,略低于台积电N7/N6的水平。
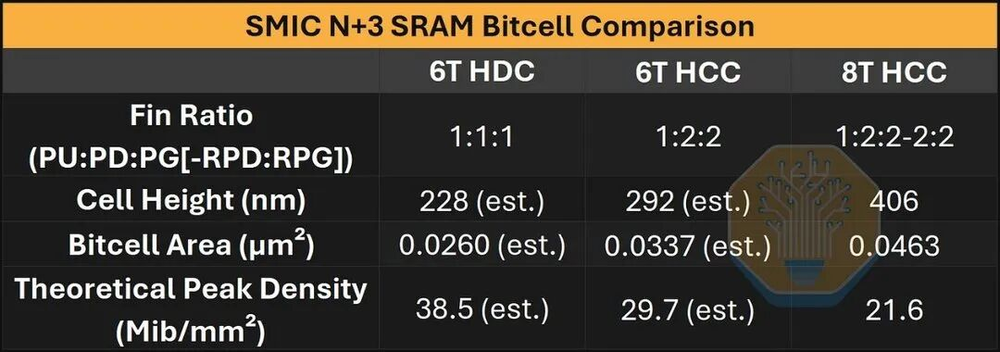
图32/40:SMIC N+3 SRAM位单元对比
从N+2到N+3,SRAM面积缩小了大约19%,接近逻辑部分的理论缩小比例。不过需要说明的是,N+2的SRAM位单元本身就异常偏大,比同类的7nm节点都要大,所以部分改进实际上是追赶补课。
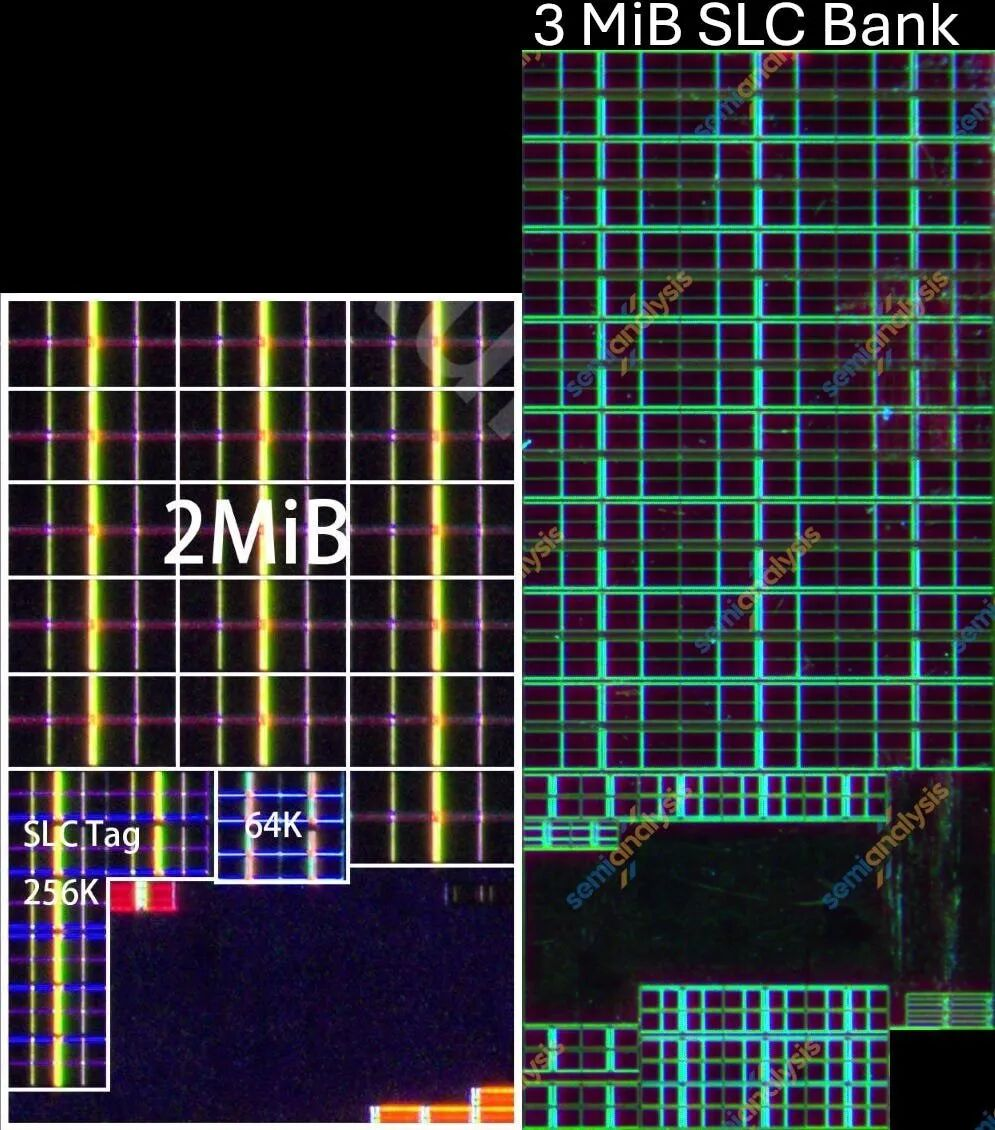
图33/40:SLC缓存bank对比

图34/40:L3缓存bank对比

图35/40:大核私有L2缓存对比
SLC从2MiB增加到3MiB每bank,一共4个bank。L3缓存从10MiB增加到12MiB,同样分4个bank。9020的L3 bank用了16x128KiB+16x32KiB阵列,9030改为48x64KiB结构。归一化到容量后,9030的64KiB阵列比9020的128KiB阵列缩小18%,比32KiB阵列缩小31%。
未来路线图:N+4,N+5和背面供电
N+3已经在多个金属层上接近DUV多重曝光的极限了。再往下走,每一步都会更难。
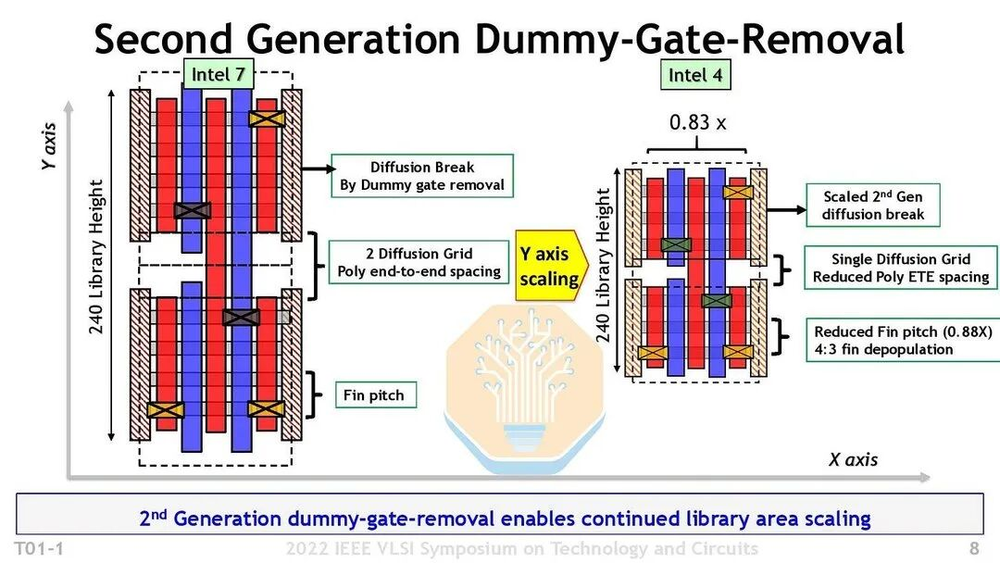
图36/40:Intel 4 Single Diffusion Grid
理论上的N+4可以从几个方向推进:
一:p-to-n隔离间距从两个扩散网格缩减到一个——Intel 4和TSMC N3家族已经用了这个技术。
二:接触栅极间距从57nm压到54nm,单元高度从5条M0轨道减少到4条,降低约15%。这样密度可以达到约137.8 MTr/mm2,和台积电N5或三星SF4相当。
但问题在于,M2要向35nm走,又得进SAQP。M1如果保持3:2比例,得压到36nm,同样需要SAQP。每个步骤单独看都可行,但全部加在一起,难度就比N+2到N+3的过渡大得多。
理论上的N+5需要更大的整合跳跃——背面接触(BSCon)。把电源和源漏接触翻到背面,正面金属层全部解放出来做信号。M0可以放宽到34nm,M2和M4也都可以放宽。CGP不太可能再大幅缩小——48nm被普遍认为是业界实践的极限。
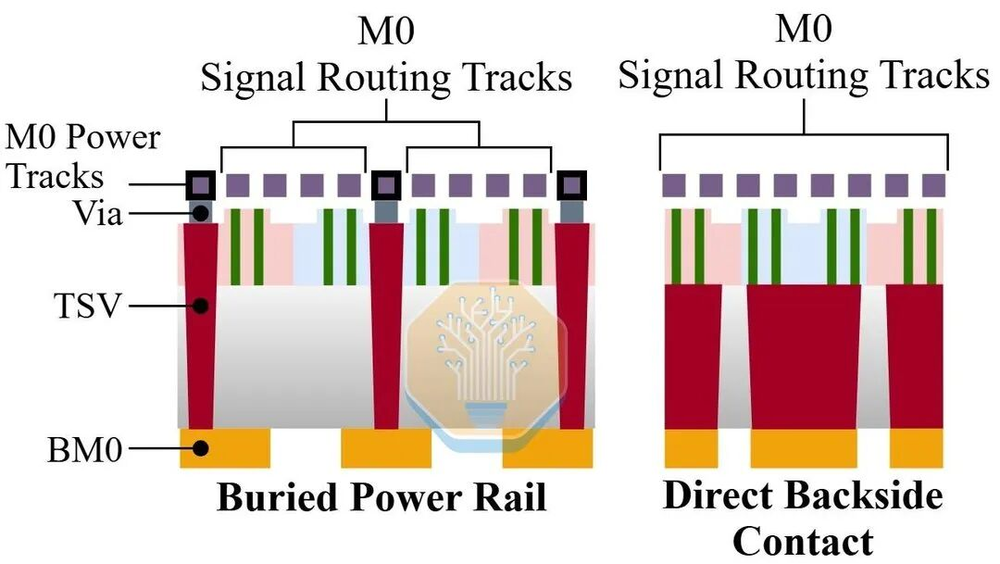
图37/40:背面供电方案对比
这样单元高度可以降到170nm,CGP到53nm,Bohr密度约163.6 MTr/mm2,和Intel 18A的高性能库差不多。但代价极高——背面工艺涉及晶圆减薄、接触孔暴露、背面金属化,每一道都是全新的工艺挑战。
华为的τ缩放定律和LogicFolding
华为在ISCAS 2026上公布了自己的缩放理论——τ缩放定律。τ代表数据移动和处理的时间成本总和:晶体管开关延迟、RC传播延迟、计算延迟、内存延迟和网络延迟的总和。
核心理念:既然平面晶体管密度追不上台积电和Intel,那就把逻辑电路竖着叠起来。
LogicFolding不是像AMD V-Cache那样只堆缓存,而是把同一个逻辑模块的电路拆开,堆叠到不同晶圆上,再用超细间距的面对面键合连接起来。这样能大幅缩短关键路径上的导线长度,减少缓冲器开销。
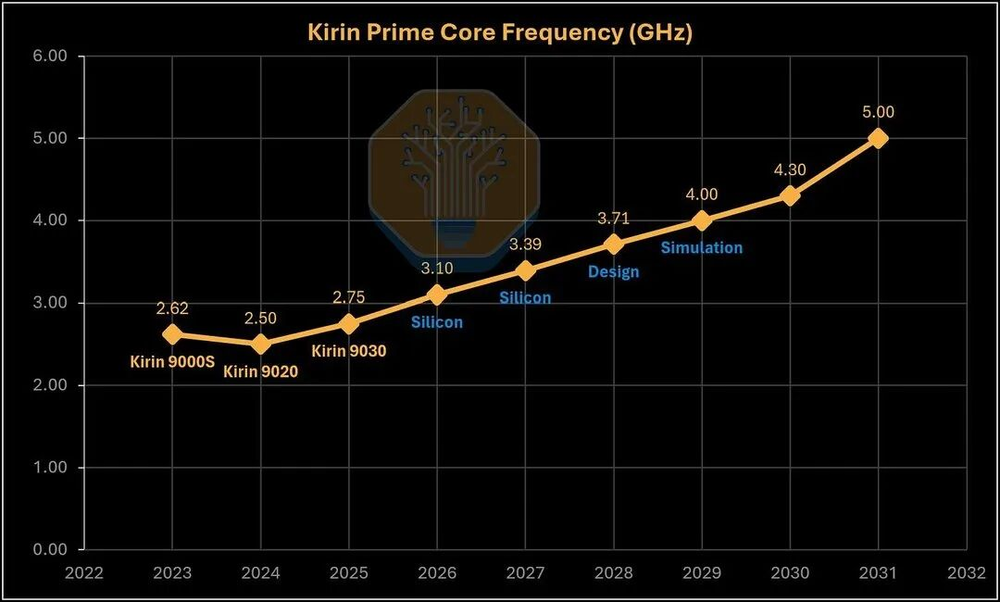
图38/40:华为大核频率路线图
华为路线图显示,大核频率计划从麒麟9030的2.75GHz逐步拉到2031年的5GHz。实验室里已经有3.1GHz和3.39GHz的样品在跑了。按华为自己的口径——把多层晶圆加起来算——到2030年可以达到每封装平方毫米2.15亿晶体管的等效密度,2031年达到2.95亿。
但需要说明的是,这个计算口径和业界标准不一样。按同样算法算AMD MI450X(N2+N3P堆叠),2026年就已经有460.2 MTr/mm2了,比华为2031年的295 MTr/mm2还高。
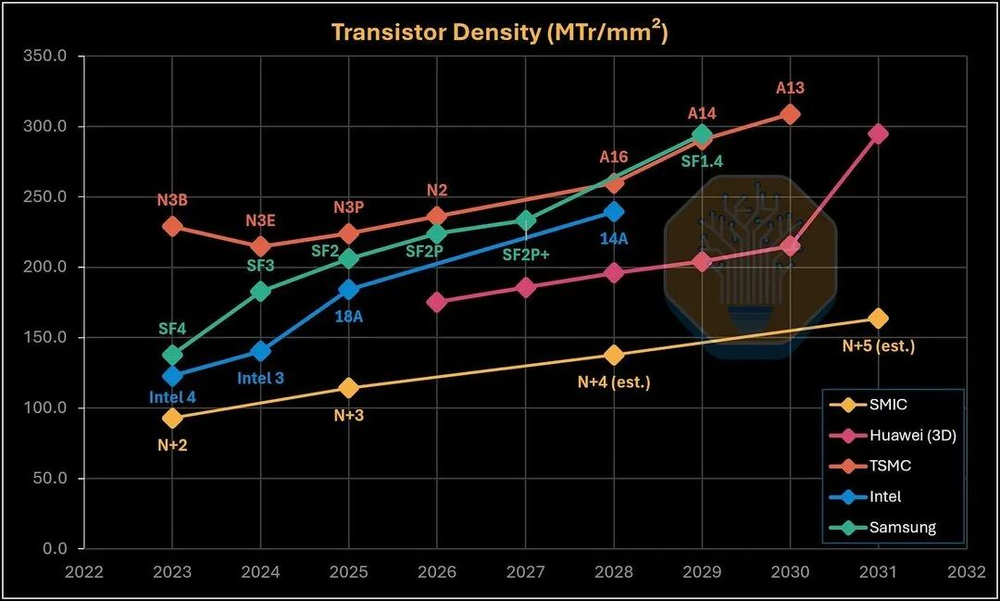
图39/40:工艺路线图密度对比
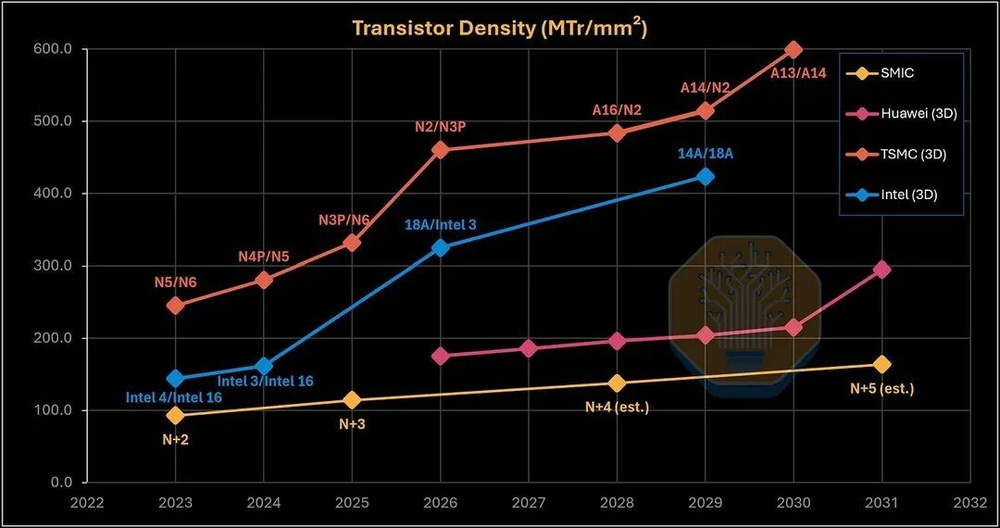
图40/40:Huawei LogicFolding密度路线图
出口管制到底改变了什么?
一句话总结:出口管制没有让中国半导体停滞,但让它走了一条完全不同的路,每一步的成本都比正常路径要高得多。
没有EUV光刻机,中芯就用DUV加四重曝光来凑合。晶体管密度做不过台积电,华为就用LogicFolding来堆叠。拿不到Synopsys和Cadence的商业EDA工具,北大就自己写一个针对LogicFolding的原型EDA工具。
每一次加码,良率都在承受压力。N+3的TEM图像清楚地展示了这一点——M0沟槽侧壁的倾斜、barrier-rich foot的堆积、金属层图案化的复杂度,这些都是没有EUV的代价。
但关键问题是,这个路径是可持续的。中芯已经在政府推动下把N+2和N+3工艺授权给了华虹。一旦制造know-how在代工厂之间扩散开来,美国出口管制的效力就会持续下降。
中国芯片设计公司都能从中受益。
麒麟9030证明了一件事:中国能在没有EUV的情况下,做出有一定竞争力的芯片。
同时,它也清清楚楚地展示了这条路有多贵、有多难。
Kirin 9030不是终点。它只是一个路标。
它告诉我们。
在没有EUV的土壤里,也能长出32.5纳米的硅基森林。
它告诉我们。
限制不会杀死创新,它只会改变创新的方向。
它告诉我们。
平面走不通的时候,还有立体。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。