2026-07-01 10:08

本文来自微信公众号: InfoQ ,作者:冬梅,原文标题:《Anthropic 突发 Sonnet 5,但大家更期待 Fable 5 和 Mythos 5 明天解禁》
昨夜凌晨,Anthropic突然祭出Claude Sonnet 5。
按照官方说法,这是迄今为止“最具智能体能力”的Sonnet模型,重点提升方向不是单轮问答,而是计划制定、工具调用和自主执行。它可以使用浏览器、终端等工具,在编码、知识工作和多步骤任务中持续推进。
Anthropic在博客中称,这类能力在几个月前还需要更大、更昂贵的模型才能实现。
这次发布的核心,并不是Anthropic又推出了一个更大的旗舰模型,而是把过去主要集中在Opus系列上的智能体能力,向更低成本的Sonnet档位迁移。
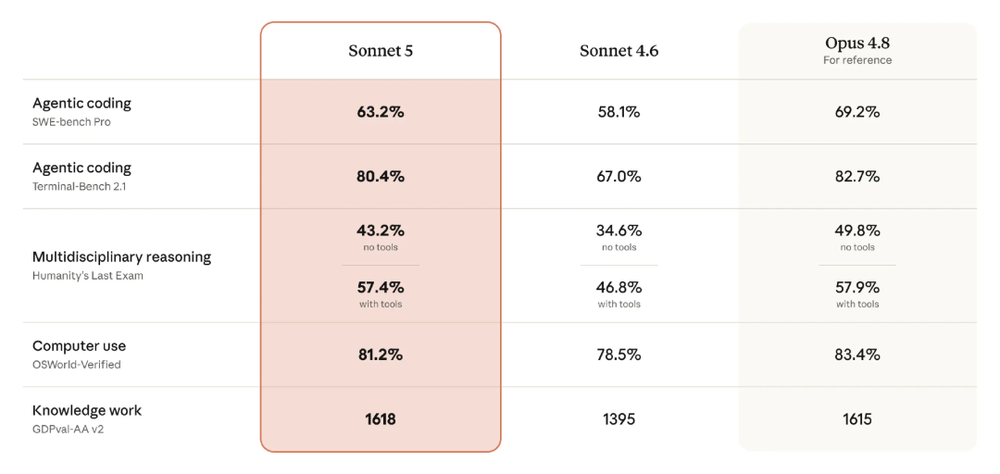
Anthropic明确表示,Sonnet 5正在缩小与Opus 4.8的差距:其表现接近Opus 4.8,但价格更低;相比前代Sonnet 4.6,则在推理、工具使用、编码和知识工作等关键智能体能力上有明显提升。
从产品定位看,Sonnet 5更像是面向开发者和企业日常工作流的“执行层”模型。它不一定承担最极端、最高精度任务,但要在成本、速度和完成度之间给出更实用的平衡。
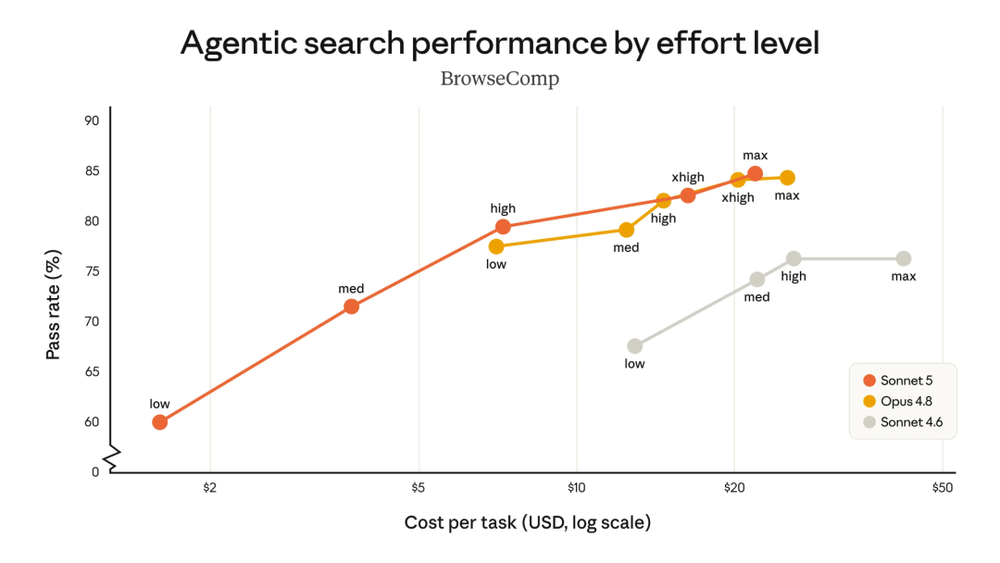
Anthropic在官方博客中提到,在BrowseComp智能体搜索评测和OSWorld-Verified计算机使用评测中,Sonnet 5相比Sonnet 4.6是严格提升;在中等努力程度下,成本效率明显改善;在更高努力程度下,部分任务可以匹配Opus 4.8。
价格也是这次发布的重点。Sonnet 5已面向所有套餐开放,并成为Free和Pro用户的默认模型,也向Max、Team和Enterprise用户开放。同时,它已上线Claude Code和Claude Platform。
API侧,Sonnet 5的限时介绍价为每百万输入token 2美元、每百万输出token 10美元,有效期至2026年8月31日;之后将恢复为每百万输入token 3美元、每百万输出token 15美元。相比之下,Anthropic在同一篇博客中标注的Opus 4.8价格为每百万输入token 5美元、每百万输出token 25美元。
这意味着,Anthropic正在把模型竞争从单纯的能力比拼,进一步推向“努力程度+成本曲线”的组合竞争。对于开发者来说,同一个任务不再只有“用大模型”或“用小模型”的二选一,而是可以在Sonnet 5与Opus 4.8之间,通过不同effort level调节成本和效果。对企业客户来说,这类设定更接近真实部署场景:并不是所有任务都值得调用最贵模型,更多时候,能否用较低成本稳定跑完复杂流程,才是关键。
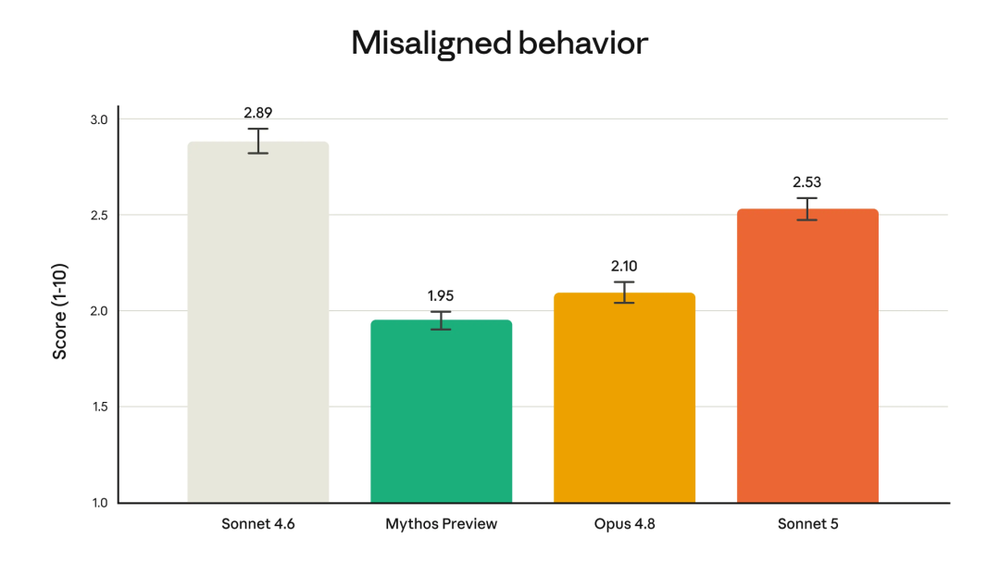
安全部分同样值得关注。Anthropic称,部署前评估显示,Sonnet 5整体上比Sonnet 4.6更安全:它更擅长拒绝恶意请求,更能抵抗提示注入攻击中的劫持尝试,幻觉率和迎合倾向也低于Sonnet 4.6。
在自动化行为审计中,Sonnet 5的总体不良行为发生率低于Sonnet 4.6。不过,Anthropic也承认,在同一项审计中,Sonnet 5的不一致行为发生率仍高于能力更强的Opus 4.8和Claude Mythos Preview。
在网络安全能力上,Anthropic的表述相对谨慎。
官方称,Sonnet 5并未被刻意训练用于网络安全任务;它可以完成一些常规、无害的网络安全任务,但在潜在危险网络安全能力评测中,例如开发软件漏洞利用,其表现明显弱于Opus 4.8和Mythos 5。
在一项与Mozilla合作开发的Firefox 147漏洞利用评测中,两个Sonnet模型都没有成功开发出完整可运行的漏洞利用程序,得分均为0.0%;但Sonnet 5的部分成功率略高于Sonnet 4.6。Anthropic将这种变化归因于通用智能能力提升,而非专门训练。
因此,Sonnet 5发布时默认启用了网络安全防护。这些防护用于实时检测和阻止危险网络安全用途,与Claude Opus 4.7和4.8中的防护相同。不过,Anthropic称,由于判断Sonnet 5的整体网络安全风险较低,其防护强度低于Fable 5,后者会阻止范围更广的网络安全任务。
值得注意的是,Claude Sonnet 5的发布意味着Anthropic正在把“能自主跑任务”的模型能力从高端Opus档位继续下放,这对开发者是很大的利好,这可能带来更便宜的Agentic Coding和自动化执行;对企业来说,则意味着AI Agent的成本账开始变得更现实。
不过,博客中的主要结论仍来自Anthropic自有评测和早期合作伙伴反馈,Sonnet 5在真实生产环境中的稳定性、长任务完成率和成本表现,还需要更多外部实测来验证。
网友评价如何?
不同于Anthropic过去几次模型发布时的高关注度,Sonnet 5上线后的第一波用户反馈显得相对平淡。
Reddit上,有用户把Sonnet 5形容为“未来更强Sonnet的垫脚石”,而不是一个真正值得现在投入使用的新模型。
该用户表示:
“Sonnet 5更像是一次新的预训练底座切换:Anthropic为了给未来模型铺路,不得不在一些方向上做取舍,并尽量降低由此带来的性能损失。”
换句话说,它可能是Sonnet 5.x继续微调和改进的基础,但Sonnet 5.0本身并没有让他觉得非用不可。
此外,他认为,未来基于这个底座继续微调的Sonnet 5.x版本,可能会明显更好,尤其是当Anthropic进一步打磨“削弱危险网络安全能力”的方法之后。但就当前版本而言,他的判断很直接:Sonnet 5.0可以暂时忽略。
也有用户给出了更具体的测试反馈。
一位Reddit用户表示,虽然Sonnet 5的价格并不算有吸引力,但也不能简单把它和GLM 5.2之类的模型直接对比。他在openmark.ai上用自己已有的生产评测流程跑了一轮测试,任务主要是回答SaaS相关业务流程中的逻辑问题,每个模型运行5次,以观察回答波动。结果显示,在他的工作流里,Sonnet 5的表现明显更好。
不过,这位用户也特别强调,这不是Artificial Analysis那类通用基准测试,而是高度绑定他自身商业项目的内部评估。也就是说,Sonnet 5到底值不值得用,仍然取决于具体场景。
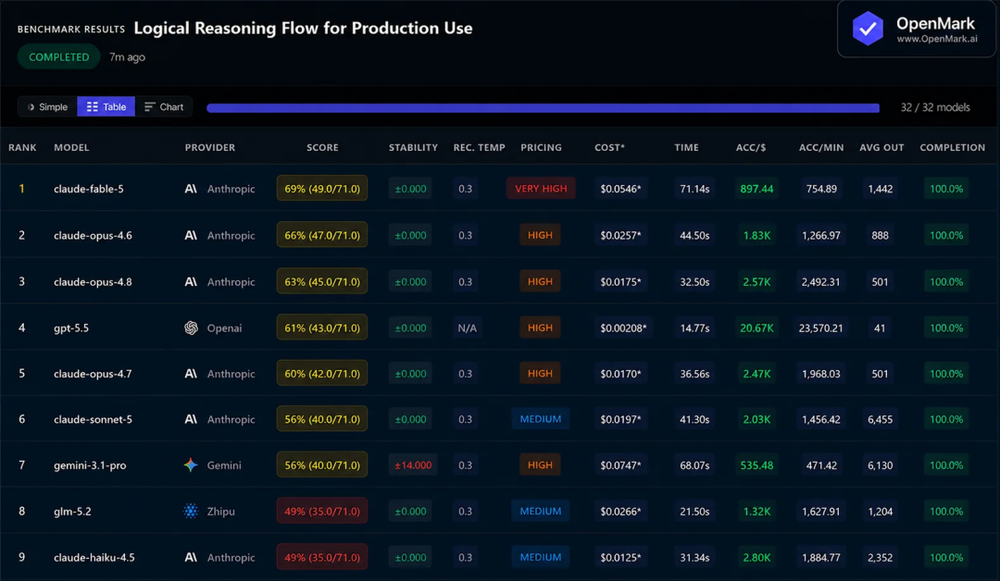
对于某些流程型、逻辑型任务,它可能比看起来更有价值。但他也补了一句:Fable 5确实很强。
还有用户直言,Claude似乎正在走错方向。在他看来,Claude的高光时刻是3.7和4.6。
Opus 4.8在代码推理和复杂指令执行上很强,但“品味”不佳;Fable令人印象深刻,但总需要用户反复引导,才能把它推到真正想要的方向。至于Sonnet 5,他的评价更不客气:上下文承载能力不足,难以支撑大块复杂思考;同时继承了Opus 4.8一些不够讨喜的表达和判断风格,却没有继承后者更强的推理能力。他甚至怀疑,Sonnet 5是否真的比Haiku 4.5更值得用。
这些评论并不能代表所有用户,但它们反映出一个值得Anthropic警惕的信号:Sonnet 5的问题不只是“够不够强”,而是用户有没有感受到清晰的产品进步。
如果说Anthropic官方想讲的是“接近Opus、价格更低、Agent能力更强”,那么开发者社区的部分反馈则更冷静:它可能更便宜,也可能在某些工作流里更好用,但它没有带来当年Sonnet 3.5、3.7或4.6那种明显的代际跃迁感。对一家依赖开发者口碑的模型公司来说,这比单项benchmark输赢更麻烦。
除了性价比,Anthropic讲不出新故事
这也是为什么,Claude Sonnet 5的发布看起来更像一次“止血”。
过去一段时间,Anthropic身上几方压力同时压过来。
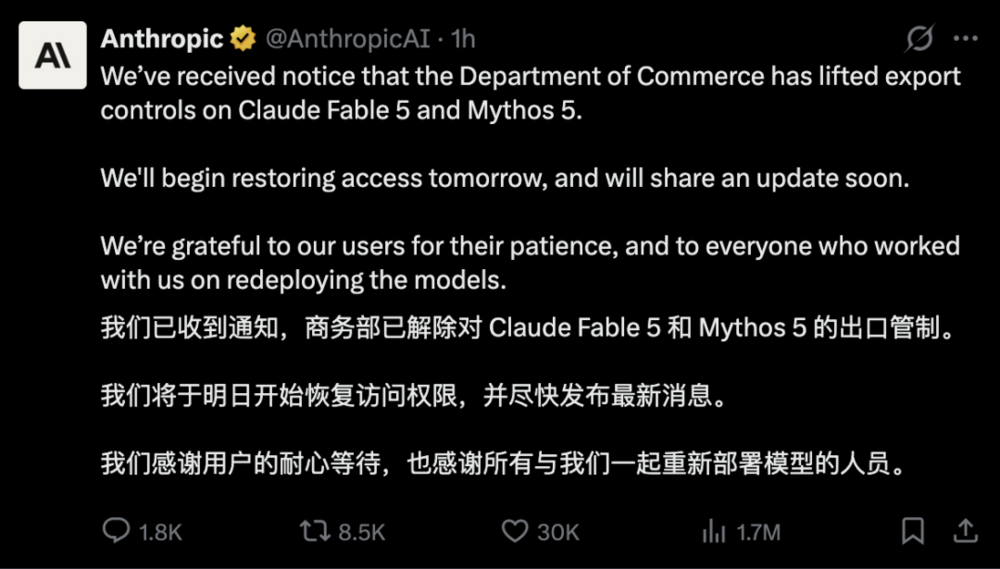
一边是高端模型线受阻。6月中旬,Anthropic发布声明称,美国政府基于出口管制指令,要求暂停所有外国国民访问Fable 5和Mythos 5,公司因此必须突然禁用这两款模型,以确保合规。这意味着,Anthropic刚刚推到前台的高端模型能力,至少在一段时间内被迫从市场上撤下。
虽然刚刚,Anthropic称已经接到美国商务部通知,Fable 5和Mythos 5的出口管制限制将被解除,相关模型访问也将恢复,但这更像是一次监管危机的暂时缓和,而不是问题的彻底消失。
路透社报道称,美国商务部已撤销对Anthropic Fable和Mythos模型的出口控制,未来访问不再需要相关许可。同时,Anthropic也承诺将继续识别和处理安全风险,并与美国政府协调模型协议、报告恶意活动。
换句话说,高端模型虽然可以重新上线,但Anthropic已经被迫经历了一次非常现实的提醒:越是前沿的模型,越不只是技术产品。对于一家正在用Fable、Mythos、Opus维持能力天花板的公司来说,这种不确定性本身就是压力。
另一边,是围绕Claude访问控制的争议不断升温。Anthropic近期公开指控阿里巴巴通过近2.5万个虚假账号、超过2880万次Claude交互,非法抽取Claude能力用于模型蒸馏;与此同时,围绕中国用户绕过Claude地区限制、账号转售、API中转站、封号风控的讨论,也在开发者社区和媒体报道中持续发酵。
这类问题本质上都指向同一个矛盾:Claude越有用,越难管。它越被开发者依赖,越会被灰产、中转、转售和蒸馏盯上。它越接近Agent工作流核心,监管、安全和合规成本就越高。
Anthropic原本最擅长讲“安全”和“前沿能力”的故事,但当高端模型被出口管制牵住,开发者又开始抱怨账号、限制和可用性时,这套叙事的说服力就会打折。
所以Sonnet 5这次最明确、也最现实的卖点,反而不是“革命性突破”,而是性价比。
Anthropic在官方博客里说得很直接:Sonnet 5的性能接近Opus 4.8,但价格更低。它在Claude Platform上的限时发布价是每百万输入token 2美元、每百万输出token 10美元;8月31日后恢复到每百万输入token 3美元、每百万输出token 15美元。相比之下,Opus 4.8的价格是每百万输入token 5美元、每百万输出token 25美元。
这就是Anthropic这次真正想让市场听到的声音:哪怕高端模型线暂时受限,Claude仍然可以用更便宜的Sonnet档位,提供接近Opus的智能体体验。
但换个角度看,这也暴露了Anthropic当下的尴尬。Sonnet 5当然更强,能调用工具、能跑浏览器和终端、能完成更复杂的编码与知识工作,但这些能力已经不是一个足够新鲜的故事。今天所有头部模型厂商都在讲Agent、讲代码、讲工具使用、讲长任务执行。Anthropic能拿出来形成差异的,最后又回到了“更接近Opus,但更便宜”。
这不是一个坏故事,但它也不是一个新故事。
更微妙的是,Anthropic直接把Sonnet 5设为Free和Pro用户的默认模型,同时开放给Max、Team、Enterprise、Claude Code和Claude Platform。
这个动作很像是在把Sonnet 5推成Claude生态的“主力维修队”:既要接住普通用户和开发者的日常使用,又要稳住Claude Code的口碑,还要用更低价格告诉企业客户,Claude的Agent能力没有因为高端模型受限而断档。
所以,Sonnet 5的关键词不是“惊艳”,而是“补位”。
它补的是Fable 5、Mythos 5暂停访问后留下的能力缺口,补的是开发者对Claude Code可用性的焦虑,补的也是Anthropic在模型竞争里越来越难讲出新叙事后的市场预期。
过去,Anthropic可以说自己更安全、更会写代码、更适合Agent,但现在,这些标签都被竞争对手追上来了。到了Sonnet 5,Anthropic最能说清楚的优势变成了一句话:接近Opus,便宜很多。
这大概就是它最真实的处境。
参考链接:
https://chatgpt.com/c/6a445410-5fb4-83ec-9582-b1f2bcb68968
https://www.reddit.com/r/ClaudeAI/comments/1ujwgqz/introducing_claude_sonnet_5/
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。