2026-07-02 10:05

速览
本文来自微信公众号: 夕小瑶科技说 ,作者:哩吧啦,原文标题:《Codex 48小时两次被迫重置,token额度消耗太快的真相来了》
哈喽朋友们,最近也是囤上Codex的重置额度了。
6月29日到30日,Codex连续两天宣布额度重置。
再加上我之前靠拉新活动存下的重置次数,现在账户里的额度已经多到有点离谱——真是用不完,根本用不完!
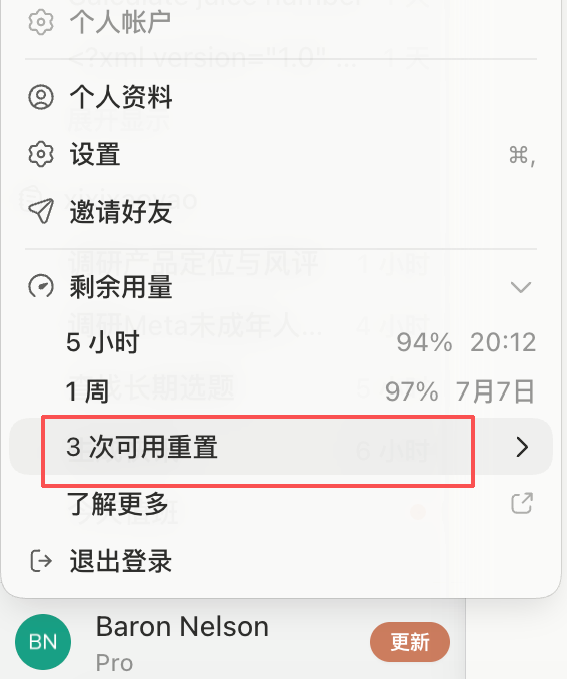
这两次重置的直接原因,都是Codex最近这一轮额度异常消耗的bug。
OpenAI出来给补偿也不难理解。毕竟,这事前几天在开发者社区闹得还挺大。
6月25日,有开发者发现了一个非常离谱的现象:
只发了一条消息,Codex的全部额度就被瞬间烧光,5小时限制直接掉到0%。
更诡异的是,这并不是个例。
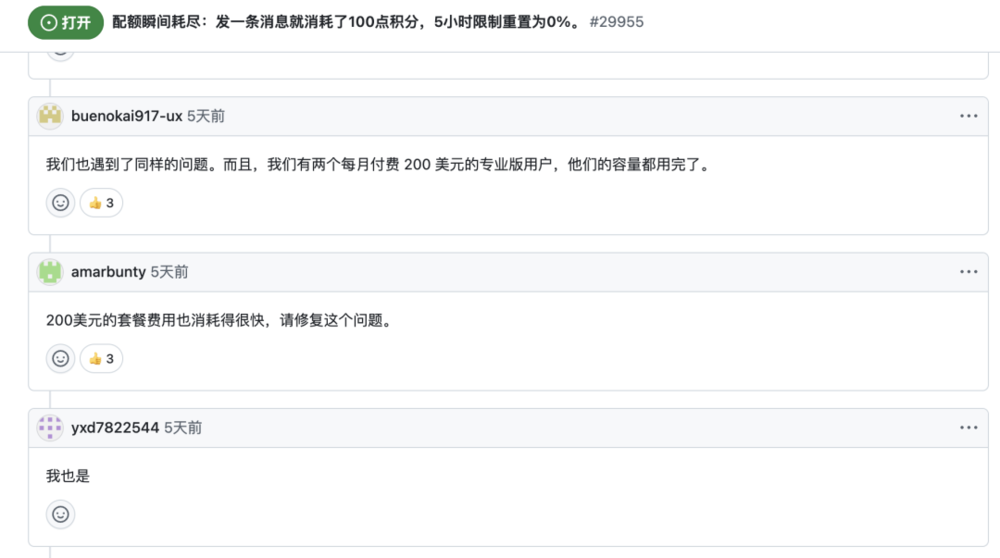
随着讨论不断扩散,大家对Codex额度透明度的质疑也越来越集中。
不少网友甚至直接@Codex产品负责人Tibo讨说法——成功把本人炸出来了。
6月27日,Tibo开始紧急回应。
他先给出了一个初步判断,称问题可能和“防止滥用和欺诈的机制误标”有关。随后又宣布,将在几小时后为所有用户重置额度。
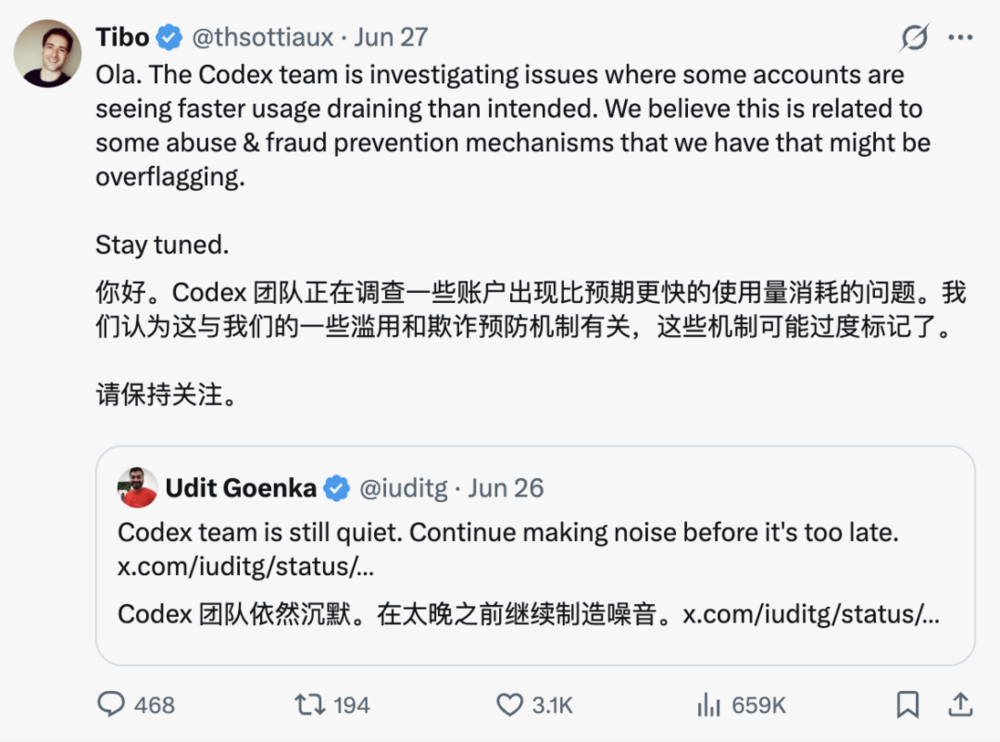
而在6月30日,这次“额度异常”的正式调查结果终于出炉——Tibo此前的推测居然也没中。
按照Tibo的报告,这次并不是某一个单点bug把额度系统干崩了,而是多个问题在特定用户场景下叠加放大——换句话说,是“亿点点问题在一起爆了”。
简单来看,主要问题集中在几个方面:
自动代码审查触发频率过高
任务拆解机制异常,导致触发更多子任务
失败prompt在后台发生重复重试
用量统计与分类显示出现偏差
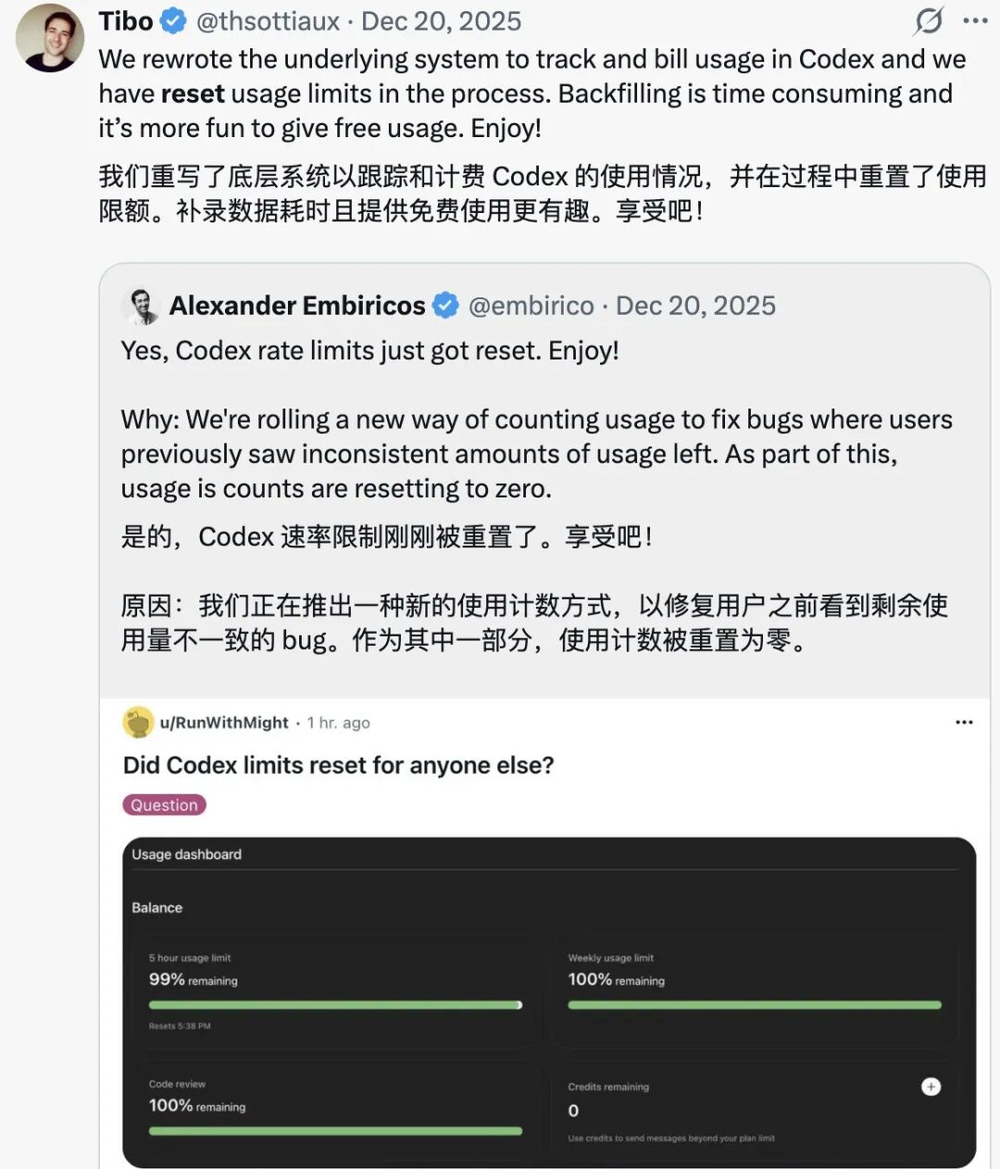
目前,OpenAI已经回滚了相关改动,并修复了重复生成、重复调度和异常重试的问题。
当然,必不可少的,又为大家发了重置。
看到这里,感觉OpenAI发重置已经发到不知天地为何物了:出bug要发,修bug也要发。硬重置要发,重置卡也要发。

这里顺便解释一下,什么是硬重置(hard reset),什么又是重置卡(banked reset)。
这也是Codex团队贡献的一个震撼首发:以前只有hard reset,也就是官方直接帮用户重置额度。
但这就产生了一个很尴尬的问题——有些用户的周限额马上就要自动刷新了,结果官方突然一键重置,相当于把一次补偿重置直接撞在了自然刷新前夜。
怎么说呢,不能算没给,但也确实有点浪费。
所以机智的Codex团队发明了banked reset,也就是“重置卡”。官方先把一次重置额度发到你的账户里,具体什么时候用,由用户自己决定。
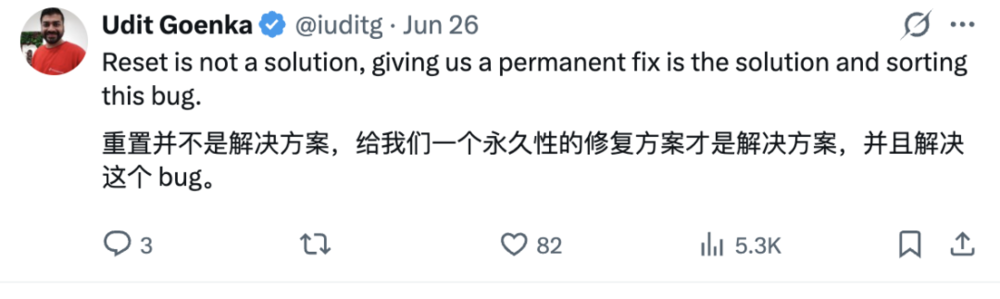
不过,疯狂的重置并不能讨好所有人。比如成功把Tibo召唤出来的那位小哥,就不是很买账。
重置并不是解决方案,给我们一个永久性的修复方案才是解决方案。
不过,Codex一时半会儿可能真搞不定这件事。
一个关键线索,藏在Codex团队过于激进的协作方式里。
Andrew把他们的协作模式称为“zone defense”,也就是“区域联防”。
在传统公司里,通常是PM写需求,设计师做界面,工程师写代码,大家按流程接力推进。但在Codex团队里,谁离问题最近,谁就直接上手解决。
工程师不再等待完整PRD,而是在Codex中快速验证多个交互方案;设计师也可以直接用Codex写代码,把设计意图变成可运行版本。
播客传送门:
https://www.youtube.com/watch?v=P3KDebPTUrw
不得不承认,这种协作模式使得Codex的更新速度惊人。
但也带来了极具风险的一面:产品在前面飞,bug在后面追。
事实上,早在2025年底Codex出现计费异常时,团队就采取过一次激进修复——直接重写了计费与使用追踪系统的底层逻辑。

但即便如此,Codex的额度问题依然没有彻底消失。
额度故障一波接一波,官方重置也一轮接一轮。
出于对Codex疯狂重置的好奇,我们认真研究了这次的故障报告,也翻了翻Codex过去和各种额度bug斗智斗勇的历史记录。
最后,我们扒出了三条Codex额度疯狂燃烧的真相。
真相1:后台任务正在偷跑你的额度
后台任务在很大程度上解释了一个最直观、也最令人困惑的问题:
即使用户没有任何主动操作,Codex的额度仍然在持续下降。
在最近这次额度异常中,后台“偷跑”任务的消耗主要来自两个方向:
其一,过度激进的代码审查机制。原本用于辅助理解与校验代码质量的review流程,在某些版本中被调得更为主动,甚至会在用户未明确触发的情况下提前启动分析流程。
其二,任务拆解与子agent调度机制。一个prompt在系统内部并不一定对应一次调用,而可能被拆成多个理解、审查、修改、验证环节,最终让一次前台请求变成一串后台动作。
除了上述在报告中的bug以外,默认记忆预览功能也是后台跑走token的大户。
今年4月份增加的这个功能,核心逻辑是让系统能够读取用户最近的屏幕上下文,从而“补全记忆”,让连续对话看起来更顺滑、更懂你在干什么。
所以,它的实现方式并不只是“用的时候才工作”,而是会持续抓取并更新上下文,相当于即使你没有在使用Codex,AI也可能在后台不断刷新你的短期记忆状态。

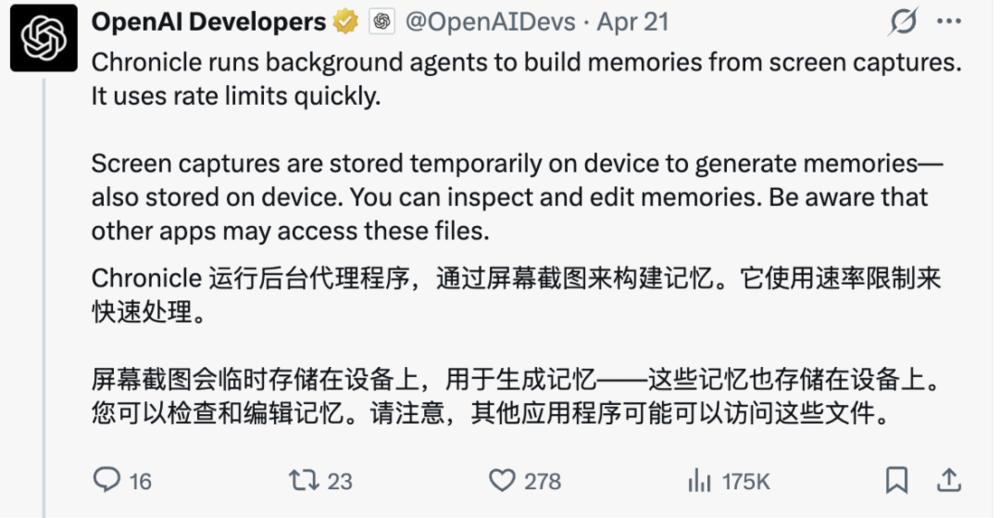
如果不想被这个功能浪费token,可以在「个性化→记忆」里直接关闭。
真相2:幽灵额度,“死去”的任务反复攻击你的额度
在这次额度异常中,Tibo也再次提到了一个更隐蔽、但更致命的问题:失败情况下的AI反复尝试机制。
在Codex的执行链路里,一个任务并不是“失败就结束”,而是可能进入不断重试和分叉的状态:
子agent在失败重试或路径分叉时,会继续扩展调用链;在某些情况下,Codex在后台自动生成的建议任务甚至可能被重复运行,或者因为重试机制过于激进而被多次触发。
换句话说就是:一个任务已经失败了,但AI还在继续“尝试救活它”。
这就直接引出了开发者社区长期在讨论的一个问题——幽灵额度(Phantom Quota)。

所谓“幽灵额度”,指的是Codex任务在挂起、超时或失败后,虽然没有返回任何可用输出,但token已经被真实消耗掉的现象。
而在当前机制下,并没有一个明确的补偿路径——任务无法被取消回滚,已经消耗的token也不会因为“没有产出”而退回。
真相3:Codex算错数,看到的额度不属实
计算问题本身,也是Codex长期存在的一类“隐性问题”。
在这次额度异常的报告中,这类问题主要集中在两个方向。
首先是额度显示层面的错位——自动审查(auto-review)曾经被错误地归类进GPT-5.4的使用统计中,导致很多用户看到的“模型消耗”,并不是真正由该模型完成的请求,而是后台审查系统的流量被混在了一起。
同时,未完成请求(中断或被限流的请求)以及速率限制请求,也曾被计入“回合数(turns)”图表中。也就是说,即使任务没有成功执行,它仍然可能出现在使用记录里,看起来像是已经消耗了一次额度。
更关键的问题在于:这些“统计误差”并不是单点异常,而是曾在一段时间内同时存在于同一套计量体系中,使得用户看到的usage曲线,与实际执行行为之间产生了明显偏差。
此前,Codex就出现过类似的bug,大量开发者进行过报告:
例如,在Codex CLI v0.40.0中,用户发现5小时滚动额度和每周额度并不会按比例变化。这使得当5小时额度增加2%时,每周额度只增加1%;意味着5小时窗口内的高强度使用,会不成比例地影响你的每周上限;
此前,Codex也被发现不同模型之间的usage会出现错位计数,甚至在切换模型后,旧模型的用量仍然持续被累积。
写在最后
Codex的额度故障不是第一次,大概率也不会是最后一次。
按照Andrew的说法,无限的token,意味着无限多的原型。团队可以更快试错、更快验证,也可以把几十个点子迅速推到用户面前。
在这种节奏里,品味和判断力似乎成了最后的筛选器。
但问题也在这里。
当产品跑得越来越快,测试窗口就会被压得越来越薄。很多问题不再是在发布前被拦住,而是在真实用户的额度账单里,才第一次被看见。
这或许也是AI native的另一面:
用户一边享受更快的产品进化,一边也不得不接受一个现实——
地球最前沿的AI产品,将长期保持在“半成品”的状态里。
[1]https://inhaq.com/blog/openai-codex-draining-quota-too-fast
[2]https://www.youtube.com/watch?v=P3KDebPTUrw
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。