2023-12-14

AI时代,生物学能从物理学中学到什么?
1. 生物学领域可以构造出通用型的预测模型吗?
2. 生物学领域还有哪些基础问题没有被正确提出来?
3. 生物学领域需要大规模协作的 “登月计划” ( 破解基础问题,以及大力出奇迹 )吗,还是更多小且精确的技术开发?

上一篇文章《黑洞与智能爆炸:用物理学可以理解 AGI 吗?| Dan Roberts, 美国红杉 AI 研究学者》讨论了物理学家视角当中的人工智能科学研究,是一个当下的缩影,跨学科的物理学家和数学家们正在尝试找到人工智能和计算领域突破性的 “新方法” ,同样的事情也发生在生物学 / 生物技术领域。
AI x Bio 会是革命性的,但是进化和涌现出来的(经典)生物学,不像物理学有公认的定律( laws of physics ) 以及数学世界清晰的公理,也不像计算机科学发展的那么完备,生物学是现实世界的复杂科学和自然界的 “反向工程”,在现实世界它远比物理和数学复杂。
但是,生物学 / 生物技术确实站在下个时代的分水岭,也就是计算驱动将会替代过去机制不明,数据不清的 “手工艺” 时代。如果你相信生物学依然受物理定律的规范,那么它不应该是永远特殊的,生物学应该不断引进学科外颠覆性的思想和方法。

我同意生物技术领域的研究者 Vega Shah 的这段观点:
但是同时,我相信生物领域的进步不会完全按照物理学走过的路,以及当下人工智能发展的路线。除了在科学上生物学是极其复杂的,在现实世界中,它还不是科技圈的主流,承担的历史任务也不一样 ( 比如当下首要是解决疾病和健康问题,可持续性发展问题如化学品/食品/材料生产等等 )。
不过有一点我敢肯定,物理学家和数学家首先推动人工智能的发展,而人工智能再去推动生物学/生物技术的发展,一定是正确的选择。生物学可以继续像物理学学习 “模型预测 + 实现验证 + 工程创造” 的范式,物理学/人工智能也可以向生命科学 ( 包括神经科学 )学习创造力,复杂智能系统的构建以及如何用更少的资源创造更多( build more with less )。
在生物学找到它的 “牛顿” 和 “爱因斯坦” 之前,或者造出来生物 AGI 之前,还需要很多默默通过实验发现科学突破的 “开普勒” 们。
希望今天分享的一篇文章可以引出对以下问题的思考:
1. 生物学领域可以构造出通用型的预测模型吗?
2. 生物学领域还有哪些基础问题没有被正确提出来?
3. 生物学领域需要大规模协作的 “登月计划” ( 破解基础问题,以及大力出奇迹 )吗,还是更多小且精确的技术开发?
如果你有自己的见解,也希望可以通过公众号后台或者微信告诉我。
今天分享的这篇英文博客文章,来自 Erika DeBenedictis 和 Niko McCarty,发表在 Codon 博客上。Erika DeBenedictis 有生物学 x 物理学 x 人工智能多学科背景,她在 2014 年从加州理工学院计算机科学本科毕业,在 2021 年在麻省理工学院获得生物工程博士学位,随后在蛋白质设计领域的领先实验室 David Baker's Lab 进行 “机器学习/蛋白质设计” 的博士后工作,也曾经在 NASA 喷气推进实验室进行研究工作。
目前 Erika DeBenedictis 在英国弗朗西斯-克里克研究所( Francis Crick Institute )负责 The Biodesign Laboratory, 在谷歌前总裁 Eric Schmidt 的基金会支持下,运营非营利性生命科学研究组织 Align to Innovate, 这个组织的目标是创建生命科学领域自动化的云端实验室,以及 “ 基因序列到蛋白质功能 ” 的开源数据。

生物学能从物理学中学到什么?
What Biology Can Learn from Physics
作者:Erika DeBenedictis,Niko McCarty
编辑:范阳
写作时间:2023年12月11日
生物领域的登月计划
Moonshots
物理学发展,长期以来一直由独立的名人科学家主导的。牛顿制定了运动定律( laws of motion ),爱因斯坦发展了相对论理论 ( theory of relativity ),狄拉克则提出了量子力学的一般理论( general theory of quantum mechanics )。
但是,第二次世界大战改变了这一格局。曼哈顿计划雇佣了 130,000 人,花费了 22 亿美元,相当于今天的 250亿 美元以上。随着资金涌入战时研究项目,物理学从一个由杰出个人组成的领域,转变为一个由良好管理的团队组成的领域。当然,仍然有独立的名人( 比如萨根、霍金和索恩 ),但今天的伟大发现似乎大多来自于标价数十亿美元的大型项目。
希格斯玻色子( the Higgs boson )是在欧洲核子研究中心( CERN )发现的,这是一个庞大的粒子物理实验室,耗资超过 100 亿美元。LIGO( 激光干涉引力波天文台 ) 通过激光束的微小波动检测引力波,耗资超过10亿美元。詹姆斯·韦伯空间望远镜 ( James Webb Space Telescope ),哈勃空间望远镜的继任者,耗资近 100 亿美元建造。生物学曾经有一些大规模的研究计划,比如人类基因组计划( Human Genome Project ),但远远不及物理学研究 “登月计划” 的数量。为什么呢?
原因有几个。首先,生物学研究范围本身就很宽泛。动物学家( zoologist )、生态学家( ecologist )和蛋白质工程师 ( protein engineer )都可以称自己为 "生物学家"( biologists ),但他们很少参加共同的会议。生物学的发现是有机进行的( biological discoveries are made organically ),成千上万的团队在解决不同的细分问题,直到其中一个或少数几个团队发现了金矿。生物学研究是不透明的( biology research is opaque );研究团队在论文发表之前不会分享他们的成果。所有这些 “奇怪的做法” 都使得生物学家们在大型问题上很难进行协调。
自然科学( natural science )可以从物理学中学到很多东西,物理学的进步是通过提出新的模型,然后通过实验证明其真实性来实现的。爱因斯坦在 1916 年就预言了引力波的存在,但 LIGO 直到 2015 年才探测到引力波。凯瑟琳-约翰逊( Katherine Johnson )根据牛顿在 1678 年设计的力学原理,计算出了 1962 年将人类送上月球的飞行路线。
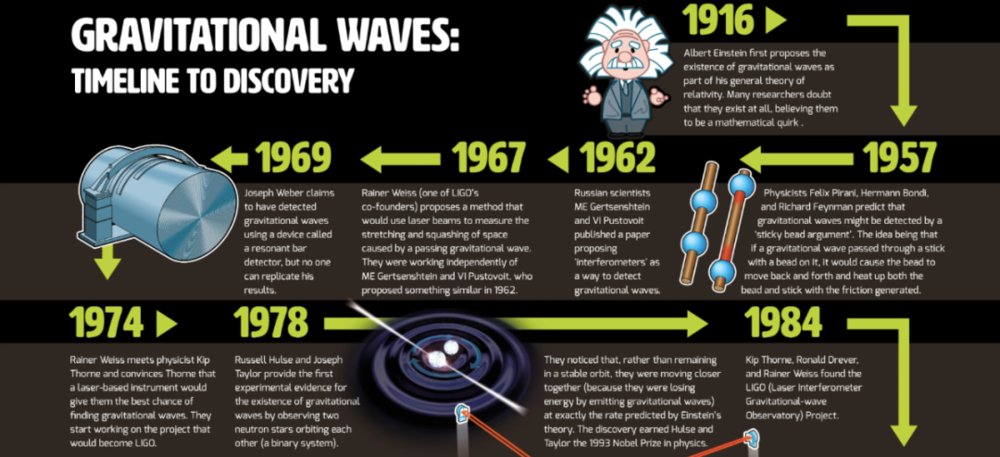

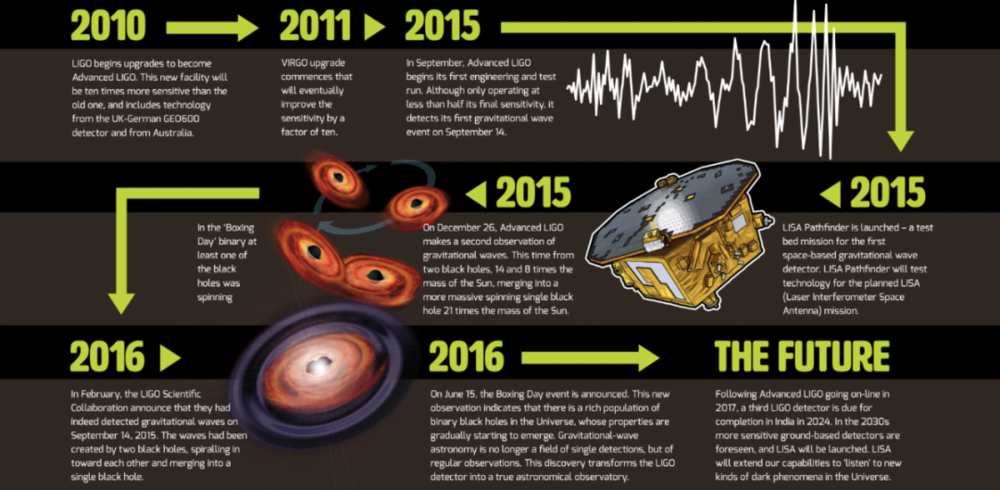
由于理论与实验之间不断来回对话( a constant back-and-forth dialogue between theory and experiment ),物理学的大厦基础已经建立了几个世纪。一旦生物学领域建立起能够在实验之前准确预测实验结果的预测模型( predictive models ),生物学的进步同样将会加速。
生物学领域的范式转变已经开始。
AlphaFold2 是一种预测蛋白质结构的模型,其准确性可以媲美甚至超过实验方法( a model that predicts protein structures with an accuracy that matches or exceeds experimental methods )。根据《自然》杂志上的研究,它是第一个 "即使在没有已知类似结构的情况下,也能正常以原子精度预测蛋白质结构 " ( regularly predict protein structures with atomic accuracy even in cases in which no similar structure is known ) 的计算方法。AlphaFold2 的重要性不仅在于它的结构预测,还在于它是生命科学史上第一个减少生物学家实验次数的模型。
那为什么要止步于此呢?人工智能的能力正在迅速增长,现在是开发更广泛的预测模型( broader predictive models )的时候了,这些模型可以在生物学的各个尺度上提供未解之谜的答案:从分子、整个细胞( whole cells ) 到细胞在宏观尺度上的行为( behavior of cells at the macroscale )。但要使这些模型成为现实,生物学家首先应该向物理学学习。
生物学领域的预测模型
Predictive Models
"序列到功能( sequence-to-function )" 预测模型: 一种仅通过查看编码蛋白质的 DNA 序列,就能确定蛋白质可能具有的功能的算法,是 AlphaFold2 的天然继任者。有了这种预测模型,就有可能通过搜索元基因组数据库( metagenomic databases )发现蛋白质的功能,或者创造出具有自然界中不存在的功能的蛋白质。
序列到功能模型( sequence-to-function model )的训练数据集仅需要三个变量:氨基酸序列 ( amino acid sequence),定量功能得分( a quantitative functional score, 反映蛋白质在实验中表现得有多好的数字 ),以及功能定义( function-definition ),或者说是用于衡量蛋白质功能的( benchmark what the protein does )实验的严格描述。最后一个变量可以是任何东西;有结合其他蛋白质的蛋白质( 如抗体 ),切割其他蛋白质的蛋白质( 蛋白酶 ),或结合 DNA 的蛋白质( 转录因子 )。
目前已经存在大约十几个序列到功能数据集( 参见 2022 年的研究中的附录表1,论文链接:https://www.nature.com/articles/s41587-021-01146-5 ),每个数据集都有超过五千个数据点。但即使将所有这些数据集合并在一起,它们仍然远远不足以构建一个粗略的预测模型。
非营利科研组织 Align to Innovate ( alignbio.org ) 的开放数据集计划 Open Datasets Initiative(本文作者之一,Erika DeBenedictis 是 Align to Innovate 的创始人)为生物学中的高影响数据集制定路线图( roadmaps high-impact datasets in biology ),然后聘请自动化工程师 ( automation engineers ) 来收集这些数据集。他们通过运行基于增长的混合实验 ( running pooled, growth-based assays )构建了一个庞大的序列到功能数据集:首先,成千上万的基因变体( gene variants )被合成,然后将它们添加到细胞中。然后,将每个基因变体的活性与细胞的生长能力联系起来( the activity of each gene variant is linked to a cell’s ability to grow ),并在试管中培养细胞。几小时后,对细胞丰度( cellular abundances )进行测量,并用生长情况来代表每种蛋白质的功能。机器人可以在一个试管中测试 100,000 多种基因变体,每种蛋白质的测试费用不到 0.05 美元。
蛋白质功能的预测模型( predictive model for protein function )将是一场革命,但最有用的是它所创建的蛋白质能在活细胞中实际进行表达。
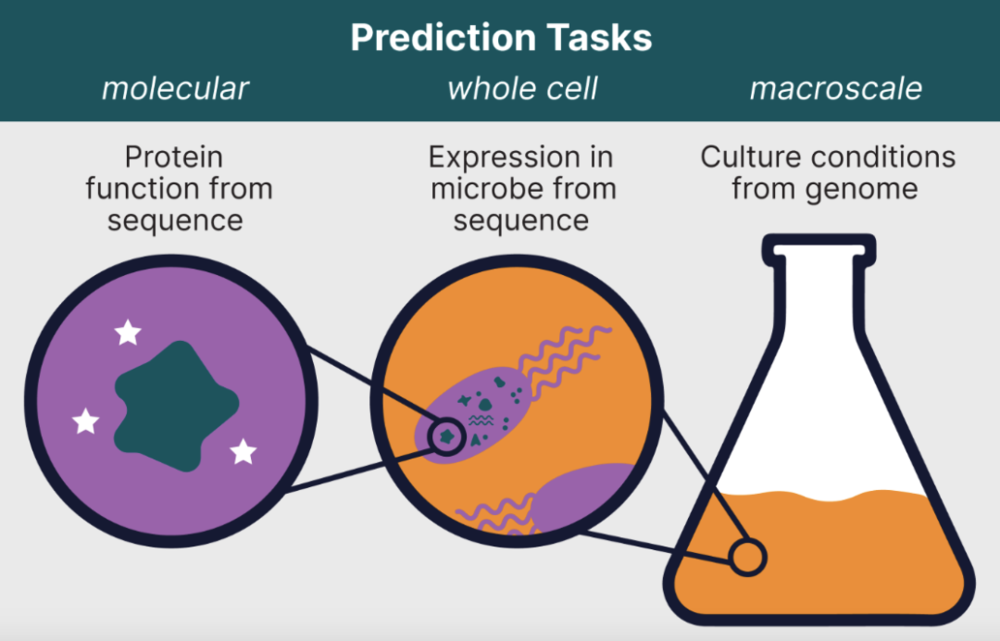
生物学的预测模型将跨越所有生物学尺度,从单个蛋白质到细胞生长的培养条件( culture conditions in which cells grow )。
大规模实验表明,小于 50% 的细菌蛋白质和小于 15% 的非细菌蛋白质在大肠杆菌内以可溶形式进行表达,这样的低 "命中 "率减缓了生物学研究进展。这也是许多生物制剂( biologics, 由活细胞制成或从活细胞中提取的药物 )无法上市的原因。序列到表达的预测模型( predictive model for sequence-to-expression )将提高 "命中 "率 ( raise the “hit” rates )。
最近的实验已经可以在一次实验中,对成千上万的蛋白质突变体( protein mutants )进行了蛋白质表达水平的量化,因此完全有可能收集大型数据集来训练这样的预测模型。此外,如今的密码子优化器( codon optimizers )可以微调基因序列( tweak gene sequences ),提高它们在大肠杆菌、酵母菌和其他类型生物体中表达的几率。密码子优化器已经有效地解决了蛋白质表达的一部分问题;通过增加关于蛋白质稳定性、pH、盐、温度、分子伴侣、蛋白酶和其他因素的额外数据,这些因素是每个细胞内部环境的独特因素,可能被用来构建第一个真正的序列到表达模型 ( sequence-to-expression model )。
可以通过在工业相关的微生物中表达数十亿个蛋白质来构建机器学习训练数据集,例如大肠杆菌( E. coli )、枯草杆菌( B. subtilis )和毕赤酵母( P. pastoris )。然后,这些数据将用于训练一个预测表达的模型,该模型将表达作为语言模型嵌入的函数。有了以上基本的实验结构,然后可以扩展数据集以处理更多的蛋白质或更多样化的细胞类型(more diverse cell types)。
构建这个模型,最大的挑战将是获取编码数百万种不同蛋白质的 DNA。合成这么多 DNA 的成本是高昂的。如果您的研究实验室中有蛋白质文库,请将它们发送给我们( datasets@alignbio.org )进行分析。我们将分析这些蛋白质并免费为您提供表达数据。我们特别感兴趣的是来自微生物的序列多样的蛋白质( sequence-diverse proteins from microbes ),例如宏基因组文库。更多社区伙伴的参与,和更多的 DNA 数据最终将提高最终模型的预测能力。
即使有了蛋白质功能和表达的预测模型( predictive models for protein function and expression ),生物学家仍然受制于实验室中可以处理的生物体种类。假设的梦想是让生物学家在任何生物体中表达具有任何功能的任何蛋白质( to express any protein, with any function, in any organism )。因此,预测模型的最终尺度,是“序列到生长(sequence-to-growth)” 预测模型;生物学家应该构建这样一个算法,通过仅查看微生物的基因组序列,就能推断出任何一种微生物的最佳生长营养物质。这可能是最难训练的模型,但它的影响将是巨大的。
奥地利的一位大胡子医生 Theodor Escherich 于 1885 年首次分离出 E. coli 大肠杆菌( 是从他自己的粪便中分离出来的 )。因此,大肠杆菌可能就是科学进步的终极生物(end-all be-all microbe for scientific progress)吗?大肠杆菌可能作为一种模式生物具有 “仍未耗尽的潜力”( 仅在 2022 年就有近 15000 篇生物医学研究论文对其进行了研究 ),但还有其他生长在海底热泉环境中或在太空真空中也能存活的微生物,这些微生物具有生物学家可以利用的迷人的机制。
一个序列到生长( a sequence-to-growth model )的模型将扩大生物学研究中使用的生物体( organisms )种类。这将使人们有可能调配一种 “最佳培养基”(optimal broth)来培养更多的生物体( organisms )。小型模型已经可以解决这个问题的一个简单版本,但要收集足够的数据构建一个广泛通用的模型将是一个艰巨的任务。
范阳注:利用机器学习建立 “小型模型” 研究细菌种群生长要素和环境动态关系的研究,可以参考2022年这篇文章
https://elifesciences.org/articles/76846
细胞基本上是由 1013 个相互作用的成分组成的袋子,浸泡在一个混沌的环境中;破译这些条件如何控制生物体的生长是一项智力上引人入胜的挑战,但也是一项令人费解的挑战。
AI x Bio 起飞
Lift Off
用于训练 AlphaFold2 的数据估计花费了约 100 亿美元才收集起来,并且得益于无数晶体学家( crystallographers )的不懈努力,他们解决了数万个蛋白质结构并将其上传到公共数据库。
( 注:抱歉此段忘记删除了,请看下段 )构建进一步减少我们对实验依赖的模型时,“存在一个悖论,即为了摆脱湿实验屏幕的限制,实际上必须进行更多的湿实验来改善模型性能”,据Lada Nuzhna和Tess van Stekelenburg在《自然·生物技术》中的说法。换句话说,要减少生物学对湿实验的依赖,首先需要生物学家进行更多的湿实验。而这将面临两个挑战。
Lada Nuzhna 和 Tess van Stekelenburg 在《 自然-生物技术 》( Nature Biotechnology )杂志上指出,进一步建立模型以减少我们对实验的依赖的悖论在于,“要摆脱湿实验室筛选的限制,事实上必须进行更多的湿实验室实验,以建立好的模型性能。换句话说,要减少生物学对湿实验室实验( wet-lab experiments )的依赖,首先需要生物学家进行更多的湿实验室实验。而这将很有挑战性,原因有二。
首先,生物学受到规模的限制。构建准确模型所需的数据量超出了任何单个实验室的财政上限。其次,生物学实验并不总是能够复现。每个实验室以略微不同的方式收集数据,通常很难协调它们之间的数据(共享和处理)。
但许多研究团队现在正在努力开发生物学的预测模型。已经取得了一些进展。今年九月,陈·扎克伯格倡议( Chan Zuckerberg Initiative )宣布了一个新的计算集群,拥有超过 1,000 个 GPU,将 “为科学界提供对健康和疾病细胞的预测模型的访问权限”。
奥克岭国家实验室( Oak Ridge National Laboratory )有一个整个团队致力于预测生物学 ( predictive biology ),伊利诺伊大学的赵惠民 ( Huimin Zhao ) 正在领导一个利用三台液体处理机器人的生物铸造厂( www.igb.illinois.edu/iBIOFAB ),收集将用于训练酶功能预测模型的数据。

伊利诺伊大学香槟分校的生物铸造实验室( biofoundry )有三个液体处理机器人。照片由尼科-麦卡蒂 ( Niko McCarty ) 拍摄。
在未来几十年,我们可能真的会看到帮助生物学家在任何生物体内表达任何功能的任何类型的蛋白质( predictive models that help biologists express any protein, with any function, in any organism )。如果能达成这样的成就是不可思议的在今天看来,因为当前生物学研究类似于工业革命之前的制造业:有许多小型生产的工匠,每个都通过定制的过程手工制作产品( creating hand-made products, through bespoke processes )。
生物学研究的手工艺性质 ( the artisanal nature of biology research )减缓了这个领域的进展。研究人员不断重新发明技术( constantly reinventing techniques )。收集的数据集通常规模有限,并且以 “同样的方式” 收集更多数据并不总是可能,因为这个实验方法可能在 “你的手中不起作用” 。手工艺性质的生物学 ( artisanal biology ) 是精致的,但也不可能快速发展。
即使在五年前,统一的生物学模型( unifying models of biology )听起来像是一个白日梦。大多数科学家都渴望建立与指导物理学和计算机科学的数学证明一样具有理论确定性和可解释性 ( theoretical certainty and interpretability of the mathematical proofs )的模型。相反,大规模数据集和机器学习的结合可能为生物学成熟发展为一个具有一定可预测性的工程学科铺平道路,尽管没有完全的可解释性。实际上,无论底层的数学是什么,只要预测模型与实验一样好,就可以为建立更复杂的理解奠定基础。预测性生物学模型( predictive biology models )有可能在历史上首次为这一领域奠定坚实的基础。
而上个世纪的生物学看起来像是一种有机的探索过程,许多研究小组在发现和重新发现奇异之处( small groups discovering and rediscovering curiosities ),而下一个世纪的生物学将类似于一个协调的、整个领域的努力,将生物学划分为一系列预测任务( divide biology into a series of prediction tasks ),然后逐个解决这些任务。
作者简介:
艾丽卡-德贝内迪克蒂斯( Erika DeBenedictis )是英国伦敦弗朗西斯-克里克研究所( Francis Crick Institute )的计算物理学家和分子生物学家,同时也是非营利组织 Align to Innovate 的创始人,该组织致力于通过可编程的实验改进生命科学研究。
尼科-麦卡蒂( Niko McCarty )是一名科技作家和前合成生物学家。他是阿西莫夫出版社( Asimov Press )的创始编辑、Ideas Matter 的联合创始人,也是麻省理工学院的遗传工程课程专家 ( genetic engineering curriculum specialist at MIT )。
原文链接:

范阳