
No.13
2024-03-24

AI精选(13)-人工智能领域内的最新进展
一、Viggle.AI

阿里那个被截胡了,这个直接能用
可以直接通过文字描述让任何静态图动起来,而且能做各种动作,跳舞什么的都是小case...
最牛P的是,他们的模型能能理解真实世界的物理运动原理,所以出来的视频很真实。
不仅如此,它还能直接文字生成视频,进行各种角色混合和动作替换...
其核心技术基于JST-1模型。JST-1是首个具有实际物理理解能力的视频-3D基础模型,能够根据用户的需求,让任何角色按照指定的方式进行运动。
核心功能:
1、可控制的视频生成:用户可以通过文字描述指定角色的动作和场景的细节,Viggle将根据这些指示生成视频。
2、基于物理的动画:JST-1模型的一个显著特点是其对物理原理的理解,这意味着生成的视频不仅看起来真实,而且角色的动作和互动符合实际物理规律。这提高了视频的质量和真实感。
3、3D角色和场景创建:Viggle不仅限于传统的2D视频制作,它还能够创建3D角色和场景。
可以去他们discord免费体验:https://discord.gg/5kk5SKwTWd
二、Gatekeep:一个新型的文本转视频 AI,专注与教学

它可以通过文本提示将数学、物理问题转换成视频内容 它会自动生成包括图表、图示、动画原理,还包含讲解内容的2分钟左右的视频。 能非常直观的帮助你了解一些知识和原理。 Gatekeep 特别强调其在数学学习中的应用,通过 AI 生成的视频,可以将复杂的数学问题和概念用更简单、更直观的方式呈现给学习者。
例如:“教我贝叶定理以及它与条件概率的关系”/“如何用二次公式求解二次方程。显示图表。/ “解释为什么勾股定理是正确的” 可以去他们discord频道体验:https://discord.gg/36PTEgY892
三、Synclabs发布新版的唇型同步模型:Sync-1.6.0
新版模型进行了唇形同步升级 能够产生平滑、准确的唇形 同时减少视频帧之间的闪烁现象 SyncLabs构建了基于给定音频条件生成视频的音视频模型。 用户只需提交音频和视频,SyncLabs会同步视频至音频,并同步口型,无需训练,最终返回一个口型同步的视频。 你可以通过以下两个方法来获得其服务
Playground:Synclabs提供了一个直观的浏览器界面,让你可以直接体验Sync的功能。
API集成:你还可以通过API将其模型集成到自己的应用、平台或服务中,开发相应的产品。
四、OpenAI在与电影制片厂、导演的会议中吸引好莱坞
OAI正在推广其新的AI视频生工具:Sora。
- OpenAI的CEO在奥斯卡周末期间参加了洛杉矶的聚会。 正文内容提到,人工智能初创公司OpenAI希望打入电影行业。该公司安排了下周在洛杉矶与好莱坞制片厂、媒体高管以及人才代理商的会议,目标是在娱乐产业中建立合作伙伴关系,并鼓励电影制作人将其新的AI视频生成器整合到他们的作品中。这一消息来自于对此事情有了解的人士。
- 分析: 这则新闻透露出OpenAI正在积极进军电影产业,并且他们对此抱有很高的期望。通过其AI视频生成工具Sora,OpenAI不仅看到了技术创新的机会,还看到了与传统娱乐巨头结盟的潜力。这种跨界合作可能会导致两个行业之间前所未有的协同效应。
五、最新的 DepthFM 深度模型现在可以在 ComfyUI 中使用
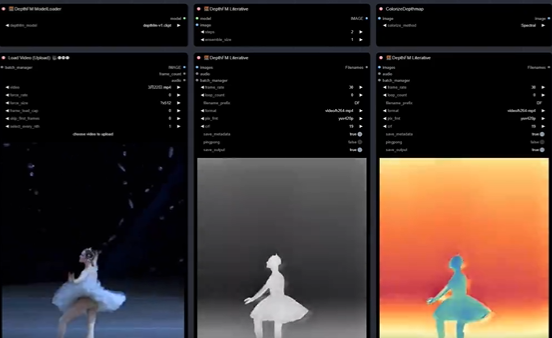
DepthFM 深度模型现在可以在 ComfyUI 中使用了! 同时支持生成 图像+视频 的深度图,方便用于重绘或控制,模型又快又好,云上T4,512 60帧视频 2 步深度图生成只需 53s! 还可搭配 YoloWorld-EfficientSAM 灵活分割特定对象高效转绘!
项目地址:https://github.com/ZHO-ZHO-ZHO/ComfyUI-DepthFM
六、一个效果非常好的只使用深度模型就实现的复杂手部动画
具体工作流: 在这个视频创作过程中,使用了多种技术和工具。其中包括 vid2vid 技术,结合了 animatediff 工具,可能还用到了 koikatsu 或类似软件来制作底层视频。此外,还运用了大约2-3个控制网络(controlnet)和 ipadapter。 Koikatsu 软件能够直接导出深度图和 openpose 数据。在导出过程中,可能以某种方式单独处理了手部,或者使用了像 meshgraformer 这样的预处理工具。 视频制作过程中可能使用了基于 ipadapter 的 animatediff lightning 技术,这是根据视频的一致性判断得出的。同时,如果使用非常低的去噪技术,也能使任何版本的 animatediff 保持视频的一致性。
项目地址:https://t.co/4mFJpoIRwB