2026-05-14 09:07

本文来自微信公众号: 叶小钗 ,作者:叶小钗,原文标题:《AI 知识库技术演进拆解:从 RAG 到 NotebookLM,再到 LLM Wiki》
NoteBookLM是我比较推崇的一款AI知识库产品,他是一款基于用户上传资料的AI笔记与研究助手。
与ChatGPT或Gemini直接回答不同,它的核心逻辑是:只根据你喂给它的资料来回答,极大地降低了AI幻觉。
根据我的测试,NoteBookLM无论从内容检索精准,还是输出精准都已经勉强达到了数字分身/同事.skill的最低要求:
严格来说,一套好的AI知识库大概率是一套RAG系统,但在NoteBookLM这套工具上我又看不到RAG存在的痕迹,作为AI知识库专研者,我一直对其技术路径非常感兴趣,于是揭秘者就出现了:
Karpathy在2026年4月4日发布了GitHub Gist《LLM Wiki》
他的核心观点是:传统RAG/NotebookLM/ChatGPT文件上传,大多是:
上传资料→查询时召回相关片段→临时综合回答
但问题是:每次问问题,模型都在重新从碎片里现拼答案,知识没有持续沉淀。Karpathy提出的LLM Wiki则是:
原始资料不动→LLM读取资料→增量维护一个结构化Wiki→不断更新实体页、主题页、交叉引用、矛盾点和综合结论
也就是说,它不是查询时拼答案,而是提前把知识编译成一个可持续演化的知识结构,这就跟我们之前做深度AI知识库所用到的知识很类似了:
NotebookLM的技术路径
这里需要说明的是Karpathy并没有Google内部技术路径图,他也是在自己做推衍,但其文档是有一定价值的,提供了一些思路。
更进一步Google官方其实已经公开过一些关于NoteBookLM非常关键的技术线索:
NotebookLM是一个基于用户上传sources的AI笔记与研究助手,它可以根据用户提供的资料进行摘要、问答、生成study guide,并且回答会带有引用,方便用户回到原文核查;
然后在2025年10月,更关键的信息产生了:
Google明确提到了NotebookLM内部存在一个Retrieval and Ranking过程,会从不同角度探索用户的sources,再综合生成回答
这几个信息已经足够关键了。因为它基本说明NotebookLM不是一个简单的文件上传+大模型回答工具,而至少包含了几层能力:
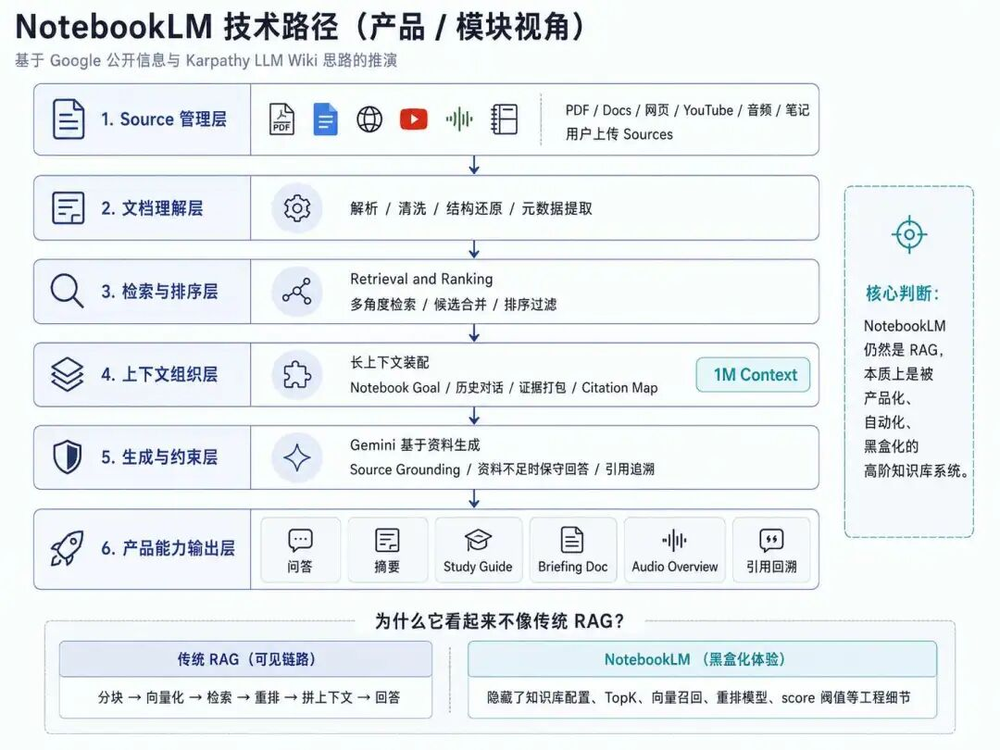
Source管理
↓
文档解析
↓
检索与排序
↓
长上下文组织
↓
基于资料生成
↓
引用与可追溯
所以NotebookLM其本质也是RAG,只不过他不是我们常见的低配RAG,而是一套被长上下文、检索排序、上下文工程、结构化笔记、source grounding包装过的高阶知识库系统。
传统RAG的存在感很强,因为它的链路暴露得很明显:
分块→向量化→检索→重排→拼上下文→回答
但所有可以配置RAG的产品,比如Coze、Dify,其数据处理(包括数据清晰、分块)都是很复杂,很令人头疼的存在,于是大家在NotebookLM的产品体验里,你看不到这些东西了,包括:
知识库配置
TopK
向量召回
重排模型
score阈值
...
但这并不代表它没有这些东西,而是因为Google把这套工程链路自动化、黑盒化了,但如果将他隐藏的工程化部分打开,应该是这么一套系统:
用户上传资料Sources
↓
文档解析与结构化
↓
多粒度索引
↓
Retrieval and Ranking
↓
长上下文装配
↓
Gemini基于资料生成
↓
引用、摘要、问答、报告、音频
接下来,我们继续做展开:
RAG产品化
既然NotebookLM本质上仍然是RAG,为什么我们使用的时候完全感受不到RAG的存在?
这里我只能根据很多文档以及自己这三年的实践做猜测了:
传统RAG是一套开发者工具链,而NotebookLM更像一套被高度产品化之后的知识系统
传统RAG是什么感觉?
你要自己准备资料,自己清洗,自己分块,自己选择embedding模型,自己建向量库,自己决定TopK,自己决定是否上BM25,自己决定是否上rerank,自己写prompt约束模型,自己处理资料不足时的拒答逻辑。
这一整套链路非常工程化,也非常折磨人,比如一个最普通、也是最恼火的问题:怎么分块?
你按固定长度分块,可能会把一个完整观点切碎;
你按标题分块,遇到结构不清晰的文档又会崩;
你按段落分块,可能chunk太碎,语义不完整;
你chunk太大,召回不准;
你chunk太小,回答没有上下文;
......
这里单单还是技术层面的问题,还不说数据怎么集合的问题,所以现在很多企业根本玩不起知识库,全部还在工作流的范畴左右横跳,原因无他,AI知识库的工程细节过多了。
所以,如何将这套RAG工程链路产品化、黑盒化就是NoteBookLM类知识库产品在思考的问题了:把各种复杂的工程配置项变成系统默认能力。
从用户视角,只需要关心三点:
我上传了哪些资料?
我想问什么问题?
我是否能回到原文核查?
至于背后的:
怎么解析?
怎么清洗?
怎么切块?
怎么建索引?
怎么召回?
怎么排序?
怎么拼上下文?
怎么做引用?
全部由系统完成,整个黑盒是把知识库工程收进系统内部了。
那问题来了,如果NotebookLM把这些复杂工程都藏到了产品后面,那它背后的系统到底可能是什么样?
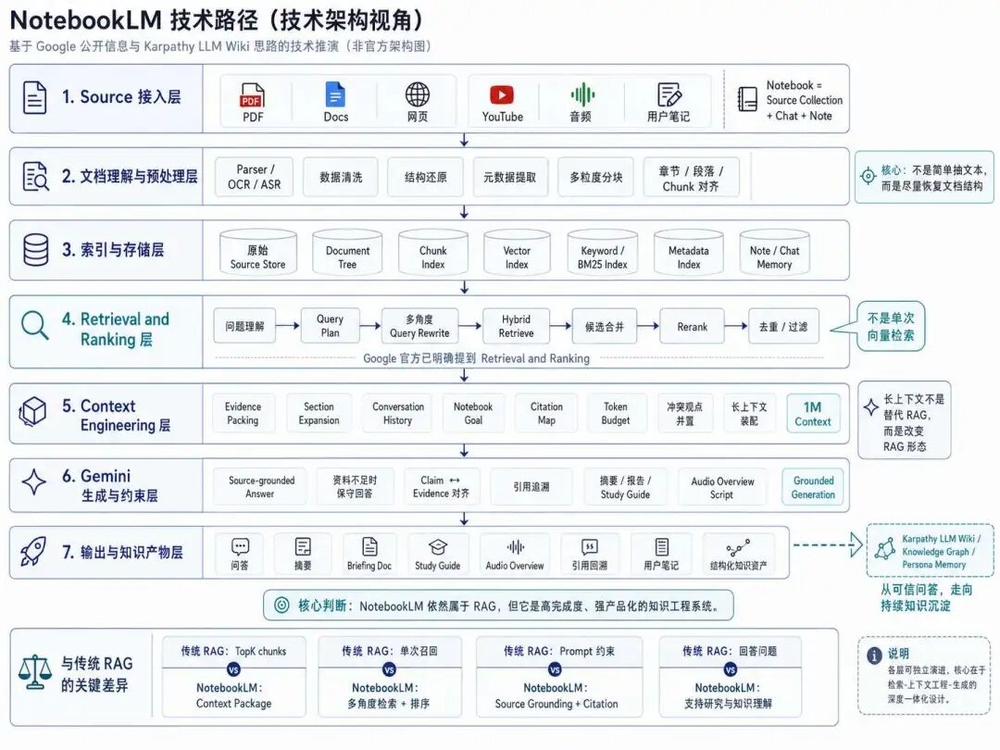
我认为可以先用一张整体技术架构来理解,可以将整个链路分为七层:
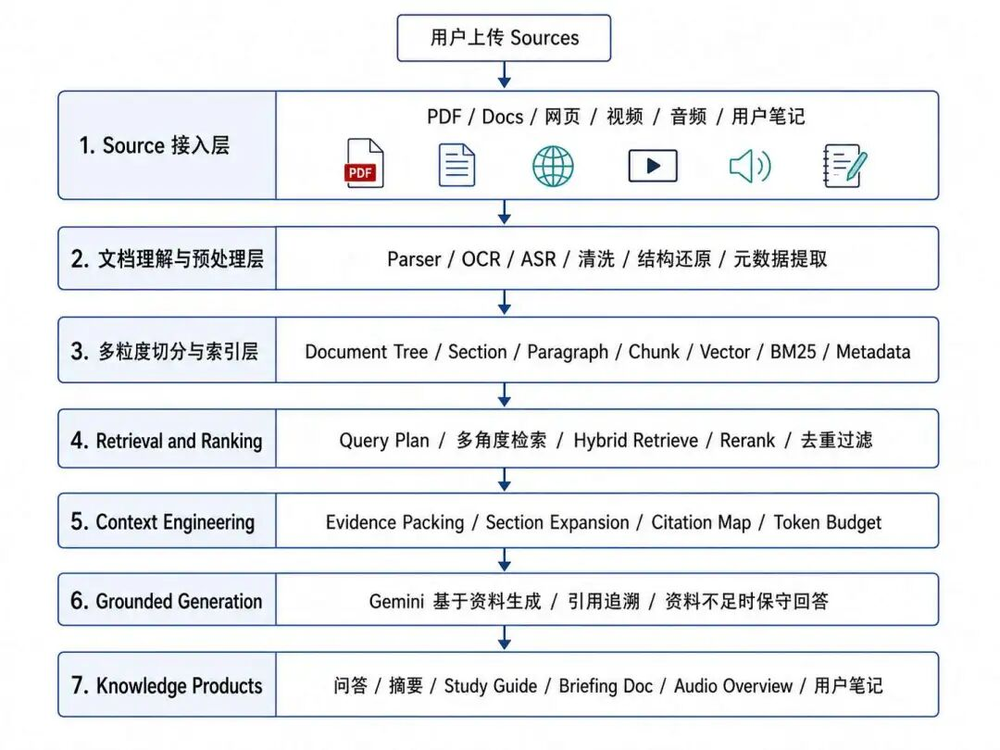
一、Source接入
NotebookLM的入口是sources,这背后是有点逻辑的,名字不同意义就不同。
普通文件上传是:
我给模型一些上下文,让它临时读一下
sources的话,意味着:
我把这些资料加入一个Notebook,后续所有问答、摘要、报告都围绕这些sources展开
所以,NoteBookLM的对象展开就不是单个文件了,而是一个资料节点:
Notebook
├──Sources:用户上传的资料
├──Notes:用户笔记
├──Conversations:历史对话
├──Indexes:索引系统
└──Settings:Notebook配置
这里的核心是产品抽象,也就是把资料当成可以被引用和追溯的事实来源。
二、文档理解
很多RAG的第一步都是PDF转文本,但如果你真做过企业知识库就知道,这一步工作量非常大,也容易处理得很粗糙。因为一份资料里真正有价值的不只是正文,还有:
标题层级
章节关系
页码
表格
图片
图注
目录
脚注
参考文献
时间
作者
来源
而我们在整理的时候,很容易把这些弄丢,于是我们糊弄文档后,就轮着AI来糊弄我们了,比如一份报告里有一个结论:
企业落地Agent最大的风险不是模型能力,而是业务流程不可观测
这句话如果单独切出来,模型就不可能知道它属于哪个章节、对应哪个案例、是不是作者结论、有没有限定条件。
如果要做RAG产品的话,在文档理解层就要下功夫,要做的不只是抽文本,而是恢复结构:
原始文件
↓
文本抽取
↓
版面分析
↓
标题层级识别
↓
表格/图片/图注处理
↓
章节树构建
↓
元数据绑定
这一步决定了知识库的上限,因为后面的chunk、索引、引用、上下文扩展,都依赖这里的结构。
如果这里做得很差,后面就只能在一堆碎片里硬搜。
所以这里RAG产品第一个难点也可能是最大的难点也就来了:把原始资料还原成机器可处理、可切分、可索引、可引用的结构化文档。
这也是很多企业知识库效果差的根源。大家太早进入了向量库和embedding,却忽略了前面的document understanding。
这里我也补一句:
就算我们知道了这是NoteBookLM技术路径的核心,但我们其实也是做不出来的
因为Google本来在信息搜索这块就是世界T0级别的,所以他们在文档处理这边会很屌,一般的公司技术力没有那个位置
比如同样的知识库产品腾讯IMA,他们技术路径应该是类似的,但效果就会差很多,原因就出在文档理解这里
最难:文档理解
这里可以再展开一点,因为我现在越来越觉得,文档理解可能是整个RAG产品里最难的一层。
很多人以为RAG的难点在向量库,在embedding,在rerank,但这些东西更多是检索算法层的问题;真正决定知识库上限的,往往是前面的资料有没有被正确理解。
因为他们本质上都是在已经被处理好的材料上做优化
如果文档理解做得不好,后面就会进入一种很尴尬的状态:
垃圾解析
↓
垃圾切块
↓
垃圾向量化
↓
垃圾召回
↓
模型一本正经地基于垃圾回答
这也是为什么很多企业知识库一开始demo看起来还行,但一进入真实资料就崩。
因为真实企业资料不是干净的Markdown,而是PDF、Word、PPT、扫描件、表格、合同、财报、产品手册、培训材料、客服记录的混合体,他们会烂到你看不下去...
人类读文档的时候,会天然理解页面结构。我们知道哪个是标题,哪个是正文,哪个是脚注,哪个是表格,哪个是图注,哪个是附录,哪个是引用来源。
这里的所谓文档理解其实就是要去模拟着整个部分,但现阶段用AI做文本抽取,很容易把这些结构全部打平:
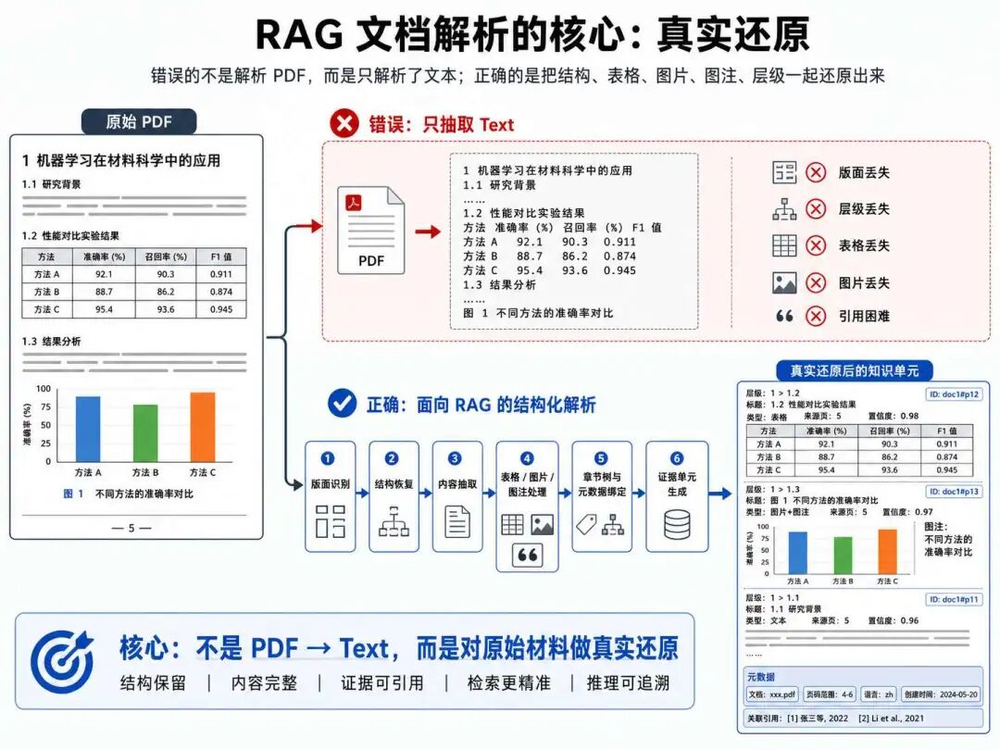
这里最核心的是两个字:还原。不是把文档转成文本,而是尽可能还原文档原本的知识结构。比如一份公司年报里写:
7经营情况讨论与分析
7.2收入与成本
7.2.1毛利及毛利率
如果系统只抽出了
2024年公司毛利率为38.4%
那么这个片段本身当然有用,但它的语境已经丢了一半,它属于哪个章节?是不是管理层讨论?是不是财务报表注释?有没有同比解释?有没有影响因素?这些信息都需要通过章节结构才能找回来。
再比如表格,很多企业知识库真正有价值的信息都在表格里。合同金额、项目周期、产品参数、财务指标、医学推荐等级、实验结果,往往都不是自然段,而是二维结构。如果表格被解析成一串混乱文本:
年份收入毛利率2023 100亿35.2%2024 120亿38.4%
模型虽然可能猜出来,但这就已经进入不稳定状态了,更好的做法是把表格转成结构化对象(markdown或者HTML都行):
Table
├──title:经营指标
├──columns:年份/收入/毛利率
├──rows:2023/100亿/35.2%
├──rows:2024/120亿/38.4%
└──page:46
这样后面无论是检索、引用,还是回答2024年毛利率是多少,都会稳定很多。
所以我猜NotebookLM这类产品,在文档理解层一定不是简单OCR,而是会做非常重的document understanding。它至少要知道:
这一段属于哪个source
属于哪个章节
在第几页
前后文是什么
是不是表格
是不是图注
是不是脚注
是否能作为引用证据
这也是为什么Google做NotebookLM有天然优势。因为Google本来就是搜索、OCR、文档解析、网页理解、多模态理解领域最强的公司之一。它在文档理解这层的积累,普通创业公司很难复刻。
至于说如何实现,我觉得PageIndex这种技术思路也值得关注:
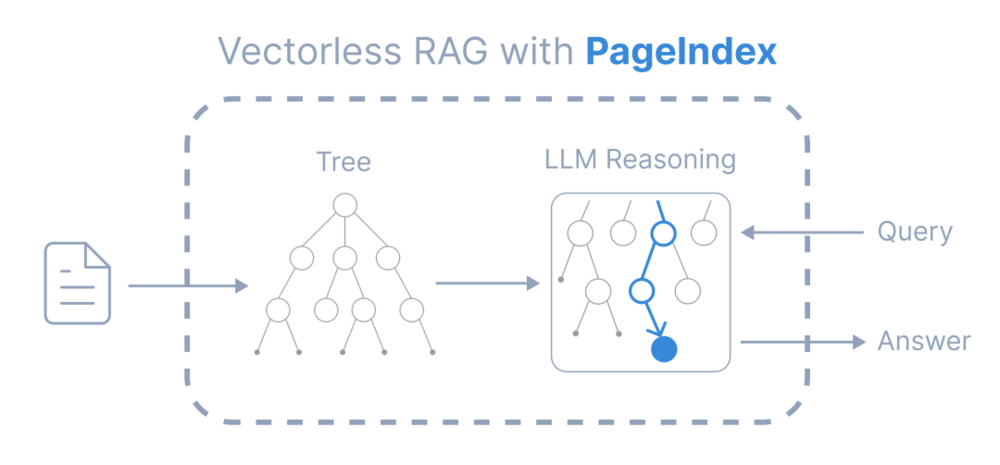
它的核心不是直接把文档切成一堆chunk,而是先把长文档解析成类似目录树的结构,再基于树搜索去定位相关章节,这个思路其实很接近人读文档的方式:
#7经营情况讨论与分析(MD&A)
##7.2收入与成本
###7.2.1毛利及毛利率
...2024财年,公司毛利率为**38.4%**(见合并利润表注释3)...
本身的文档是很大的,他解析出来变成了这样:
{
"title":"Management’s Discussion and Analysis",
"node_id":"0004",
"page_index":35,
"nodes":[
{
"title":"Results of Operations",
"node_id":"0005",
"page_index":40,
"nodes":[
{
"title":"Gross Margin",
"node_id":"0006",
"page_index":45,
"summary":"2024年毛利率及同比变动,影响因素为产品结构与成本控制..."
}
]
}
]
}
思路肯定是对的,但实际使用起来就差点意思了,而且从底层结构来说,它更适合结构化长文档,不一定适合客服记录、聊天记录、碎片化FAQ、短文章合集这类弱结构资料。
真实系统里,更可能是混合策略,这里就能体现出RAG产品的工程复杂度了:
结构化长文档→文档树/PageIndex/树搜索
碎片化知识→向量检索+BM25+Rerank
表格型资料→表格结构化+字段查询
多模态资料→OCR/ASR/图表理解/多模态摘要
好了,我们这里不展开,继续打开NoteBookLM的七层黑盒:
三、Chunk
传统RAG喜欢讨论chunk size,RAG产品一定不会只有一种chunk,它更可能维护多种粒度:
Source级别
Chapter级别
Section级别
Paragraph级别
Chunk级别
Sentence级别
为什么要多粒度?因为不同问题需要不同粒度的证据:
用户问一个细节问题时,需要paragraph或chunk;
用户问一个章节观点时,需要section;
用户问几份材料的整体结论时,需要source summary或chapter summary;
所以系统不可能只存一种chunk。更合理的结构是:
Document Tree
├──Source
│├──Chapter
││├──Section
│││├──Paragraph
│││└──Chunk
这里最关键的依旧是:还原,也就是chunk不能和原文结构脱钩。一个chunk应该知道:
它来自哪个source
属于哪个章节
前后文是什么
页码是多少
原文位置在哪里
能不能回溯引用
这里的chunk就是带结构的逻辑单元了,可以粗略理解成:
Chunk
├──text:文本内容
├──source_id:来自哪个资料
├──section_id:属于哪个章节
├──position:原文位置
├──page_range:页码范围
└──citation_ref:引用回溯信息
这里是可溯源的关键,证据早就准备好了。
四、索引
与之前一样,如果要做RAG产品,那么所有可能的索引形式,什么时候适合什么就全部要熟悉了:
Vector Index
处理语义相似。
Keyword/BM25 Index
处理关键词精确匹配。
Metadata Index
处理来源、时间、类型、作者、页码等过滤。
Document Tree Index
处理章节层级和上下文扩展。
Citation Index
处理引用回溯。
Conversation/Note Index
处理用户笔记和历史对话。
所以这里可以将整个入库流程串起来了:
Source
↓
文档解析
↓
结构化文档树
↓
多粒度切分
↓
生成向量索引
↓
生成关键词索引
↓
生成元数据索引
↓
生成引用映射
↓
写入Notebook
这一步对比传统RAG时候要注意:高阶RAG不是不要向量库,而是不能只有向量库。甚至一轮走下来,可能多数情况下可能真的用不上向量库...
因为向量检索适合找语义相似,但不适合解决所有问题,甚至多数时候都不适合
比如这些场景下,关键词索引往往更稳定:
某个专有名词
某个产品名
某个公式
某个引用页码
某个明确标题
某个用户笔记里的关键词
所以NotebookLM的Retrieval and Ranking,很可能不是单一路径,而是混合检索。
五、Retrieval and Ranking
到了这里,才进入我们熟悉的RAG核心环节。
但NotebookLM和低配RAG的相比,肯定不可能把用户问题直接丢给向量库搜一下。
它大概率会先做问题理解,这里又是一连串RAG工程改写了,比如用户问:
这几份资料里,对AI知识库未来发展最重要的判断是什么?
这个问题其实包含多个子任务:
找出每份资料里的核心判断
比较不同资料之间的共同点
识别冲突观点
提炼长期趋势
给出综合结论
所以系统需要先生成一个query plan:
用户问题:
这几份资料里,对AI知识库未来发展最重要的判断是什么?
Query Plan:
1.找出资料中关于AI知识库未来趋势的内容
2.找出资料中对RAG局限的判断
3.找出关于知识结构化、Wiki化、知识图谱的内容
4.找出NotebookLM与传统知识库的差异
5.找出数字分身/同事.skill相关技术路径
然后系统再做多路召回:
每个子问题
↓
向量检索
↓
关键词检索
↓
元数据过滤
↓
候选内容合并
↓
去重
再进入排序:
候选证据
↓
相关性评分
↓
可信度评分
↓
引用质量评分
↓
覆盖度判断
↓
最终排序
这里影响Ranking的条件可就多了,除了相关性以外还有:
是否来自可信source
是否覆盖多个source
是否有足够上下文
是否和问题意图匹配
是否与其他证据重复
是否包含明确结论
是否适合作为引用
这一连串工程动作下来,大家就会认为NoteBookLM回答得很靠谱了,只不过还是那个逻辑,在整个文档理解那块其实就决定了这里能回答得怎么样,前置数据处理才是上限。
六、Context Engineering
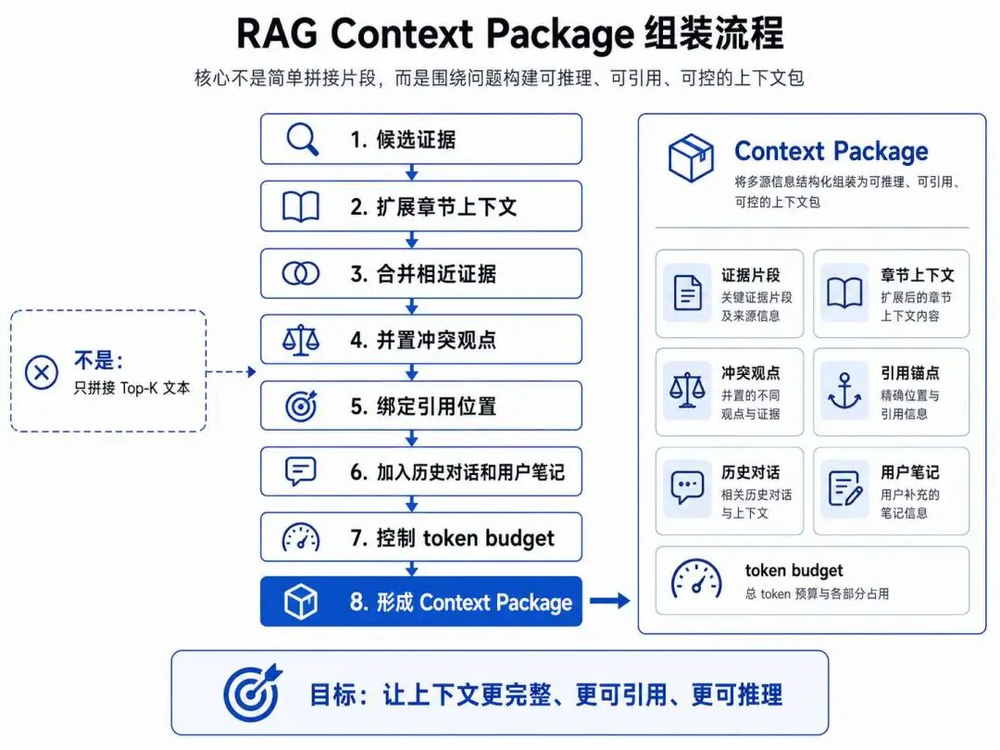
NotebookLM这种系统,在这里会进入Context Engineering:它要把候选证据组织成一个模型真正能用的上下文包。
这个Context Package可能包含:
用户问题
问题意图
候选证据
证据所属source
章节上下文
前后文扩展
多份资料摘要
历史对话
用户笔记
引用映射
回答约束
资料不足时的处理规则
有些同学可能就会说了,现在模型不都号称百万Token了吗,管他这么多干嘛,直接全塞进去不行?
只不过,百万上下文不是让你无脑塞全文,而是让你在证据之外,还能放入更多结构化辅助信息。比如:
证据前后文
章节摘要
source摘要
历史对话
用户笔记
冲突观点
引用映射
模型底层也是具有注意力机制的,千万不要把模型当垃圾场。
七、答案生成
最后就是生成了,这类AI知识库产品,一般要遵守几个规则:
只基于资料回答
资料不足时保守回答
回答中的关键结论要能绑定证据
不同source有冲突时要指出冲突
不要把推断说成事实
所以生成链路大概是:
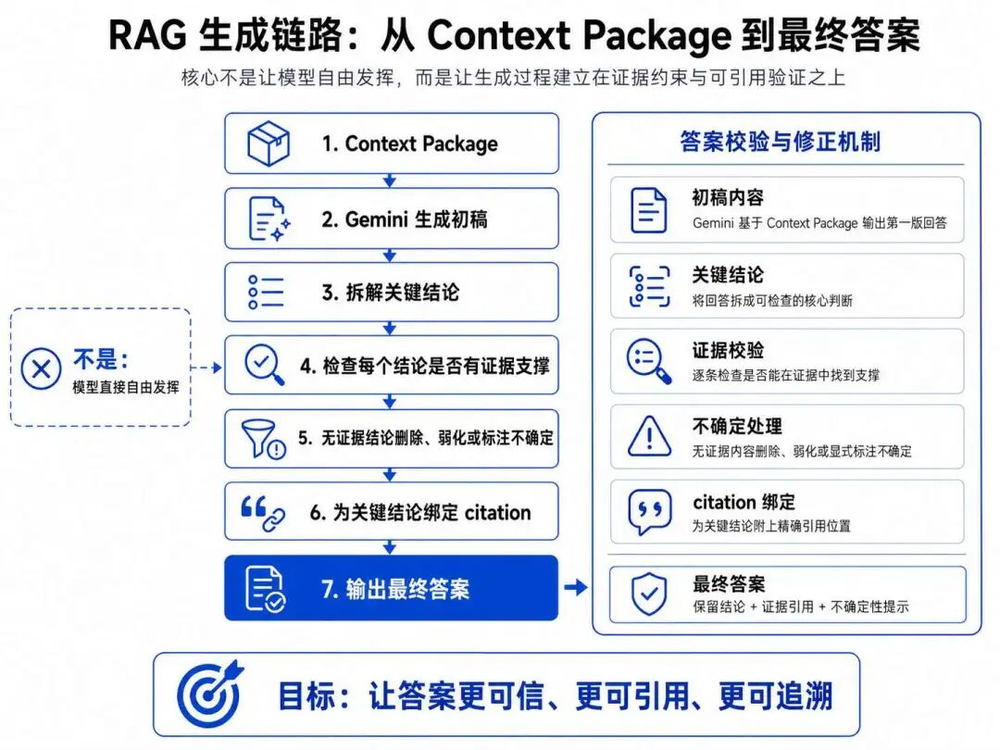
其实核心就是可溯源,也就是:
这句话来自哪个source?
依据是哪几个evidence block?
能不能回到原文?
如果没有依据,要不要删掉或弱化?
技术路径的最终演进
把上面全部串起来,一个NotebookLM类系统的完整回答流程大概是:
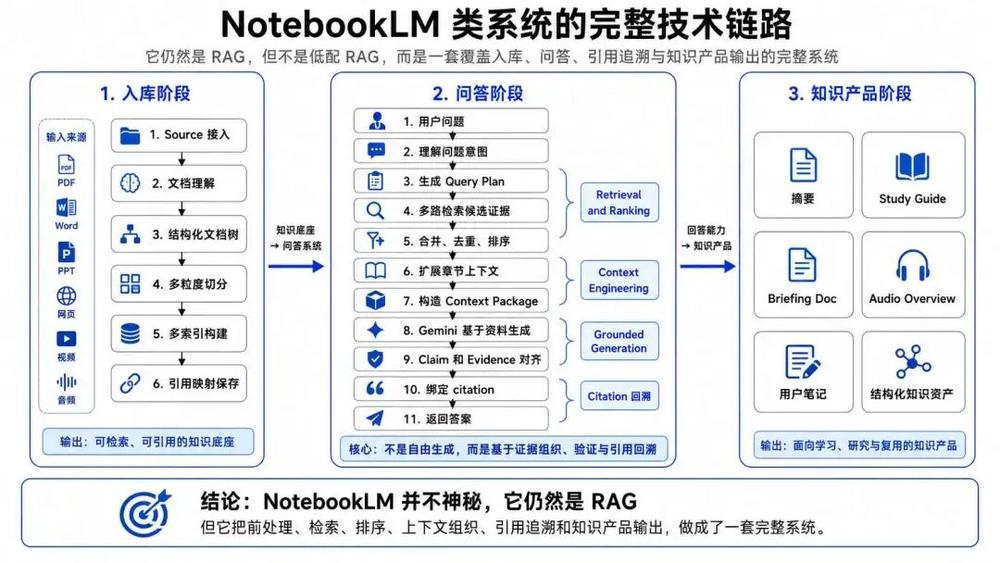
所以,如果我们把NotebookLM拆开,它并不神秘,它仍然是RAG。
但它不是低配RAG,而是把RAG的前处理、检索、排序、上下文组织、引用追溯和知识产品输出做成了一套完整系统,说实话一般公司应该做不了这东西,挺复杂的...
讲到这里,再回头看Karpathy的LLM Wiki,整个链路就会更加完整了:
NotebookLM主要解决的是:资料如何被可信地问答和研究?
LLM Wiki进一步解决的是:资料如何被持续沉淀成结构化知识?
所以系统自动清洗、切块、索引、检索这件事,不能直接叫Wiki化,它应该叫:
RAG工程自动化
而Wiki化是下一层:
知识结构沉淀
可以看到,NotebookLM已经有一些Wiki化倾向,比如摘要、Study Guide、Briefing Doc、用户笔记、引用回溯。
这里可能也回答了后续RAG类AI知识库项目的技术路径会如何演进:
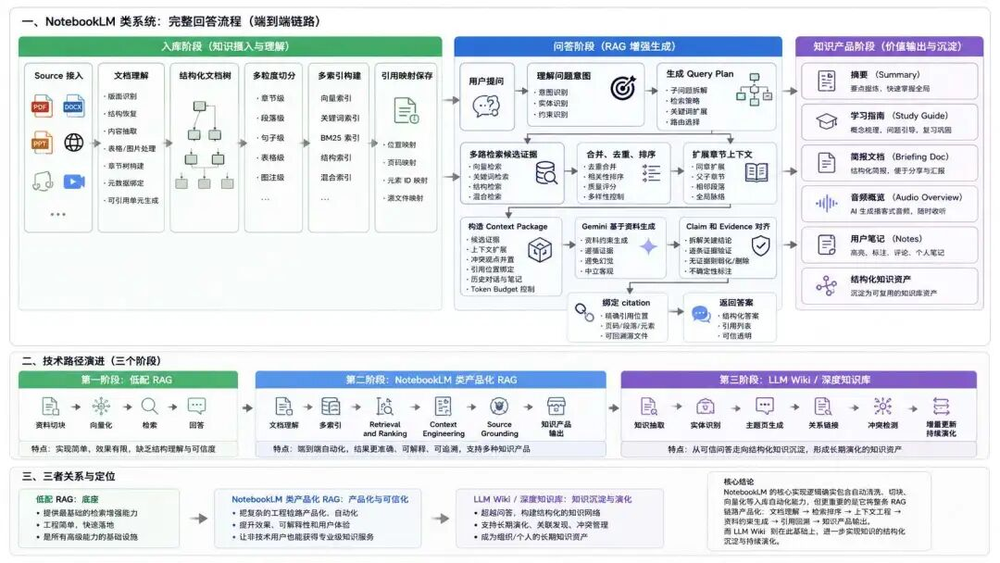
AI知识库的技术路径大概会经历三个阶段:
第一阶段:低配RAG
资料切块→向量化→检索→回答
第二阶段:NotebookLM类产品化RAG
文档理解→多索引→Retrieval and Ranking→Context Engineering→Source Grounding→知识产品输出
第三阶段:LLM Wiki/深度知识库
知识抽取→实体识别→主题页生成→关系链接→冲突检测→增量更新→持续演化
这三个阶段是一个逐层叠加的过程:
低配RAG是底座。
NotebookLM把这个底座产品化、自动化、可信化。
LLM Wiki再进一步,把知识结构沉淀为长期资产。
所以回到最开始的问题:NotebookLM的核心实现逻辑,是不是就是系统帮我们做掉了清洗、切块、向量化?
答案可能是,但各位依旧逃离不了RAG...
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。