2026-05-24 10:33

本文来自微信公众号: 叶小钗 ,作者:叶小钗
最近遭遇知识诅咒了,在做培训的时候会发现一个情况:我们以为的常识,在其他人看来是卡点,而因为这种卡点多了,整体学习效果就很差,而今天要聊的“常识性卡点是Function Calling”...
我第一次接触Function Calling,是一个天气查询Demo。用户问一句天气,模型返回一个get_weather,应用层查完天气,再把结果交给模型生成回答。
流程一跑通,很容易让人觉得,它就是一个函数调用,而且大模型终于可以接入业务系统了。
于是乎Function Calling很容易被讲成一句话:让模型调用函数。
但我们在做Agent系统的时候,才发现它是一点都不简单,查天气时,回答错了系统还能接受。换成订单、地址、退款、数据库写入,错一次就可能改到真实业务状态:
模型拿不到订单号怎么办?
超时后反复查同一笔订单怎么办?
高风险动作被误触发,又由谁拦下来?
所以我们自己在做实践的时候是把Function Calling看成一个入口。
它让模型用结构化方式表达调用意图,至于这个意图能不能执行、什么时候执行、失败以后怎么处理、风险动作要不要确认,那已经是Agent工具治理的问题。
于是,今天我们来系统性聊聊Function Calling:
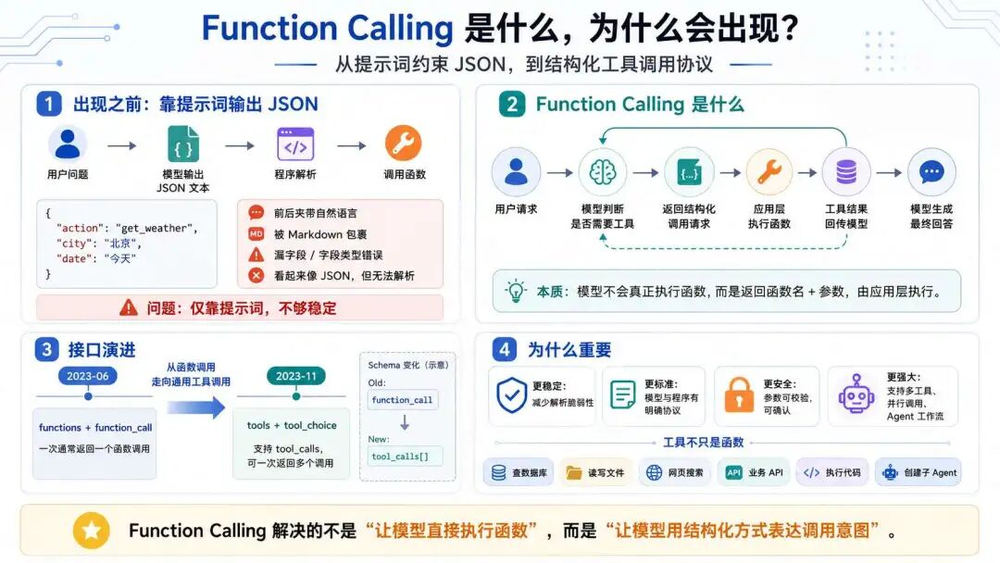
Function Calling是什么
在Function Calling出现之前,如果想让大模型触发外部函数,办法其实很直接:在提示词里约定输出JSON,外部程序再解析这段JSON,根据返回的函数名和参数调用真实函数。
我们可以在系统提示词中这样写道:

用户输入:
北京今天天气怎么样?
理想情况下模型会返回下面的JSON:
{
"action":"get_weather",
"city":"北京",
"date":"今天"
}
我们需要设计一个外部程序来解析这个JSON,提取函数名和参数,然后再去执行这个工具,调用天气API获取实时的天气数据。
这个流程其实没有啥问题,唯一的缺点就是模型输出不稳定。特别是早期模型推理能力还不够强的时候,它不会严格按照我们提示词中的JSON格式输出。
我们在测试的时候经常看到下面这种格式的内容输出:
在JSON前后夹带自然语言;
用Markdown代码块包裹结果;
漏字段;
写错字段类型;
输出看起来像JSON、实际上无法解析的内容。
这些问题都会让我们的程序解析报错,我们不得不写一些工具函数来清洗模型返回的JSON:去掉多余自然语言、删除Markdown代码块、修复格式错误、做字段类型转换,必要时还要兜底重试请求模型返回新的JSON。
所以单靠提示词让模型稳定输出可解析JSON结构并不可靠。
早期形态
2023年6月13日,OpenAI引入Function Calling能力,接口中主要使用两个参数:
functions:用于向模型描述可用函数。
function_call:用于控制模型是否调用函数,或者要求模型调用某个指定函数。
开发者可以通过JSON向模型描述函数名称、用途和参数结构。模型根据用户输入判断是否需要调用函数,并生成符合Schema的参数。
例如,一个天气查询函数可以这样描述:
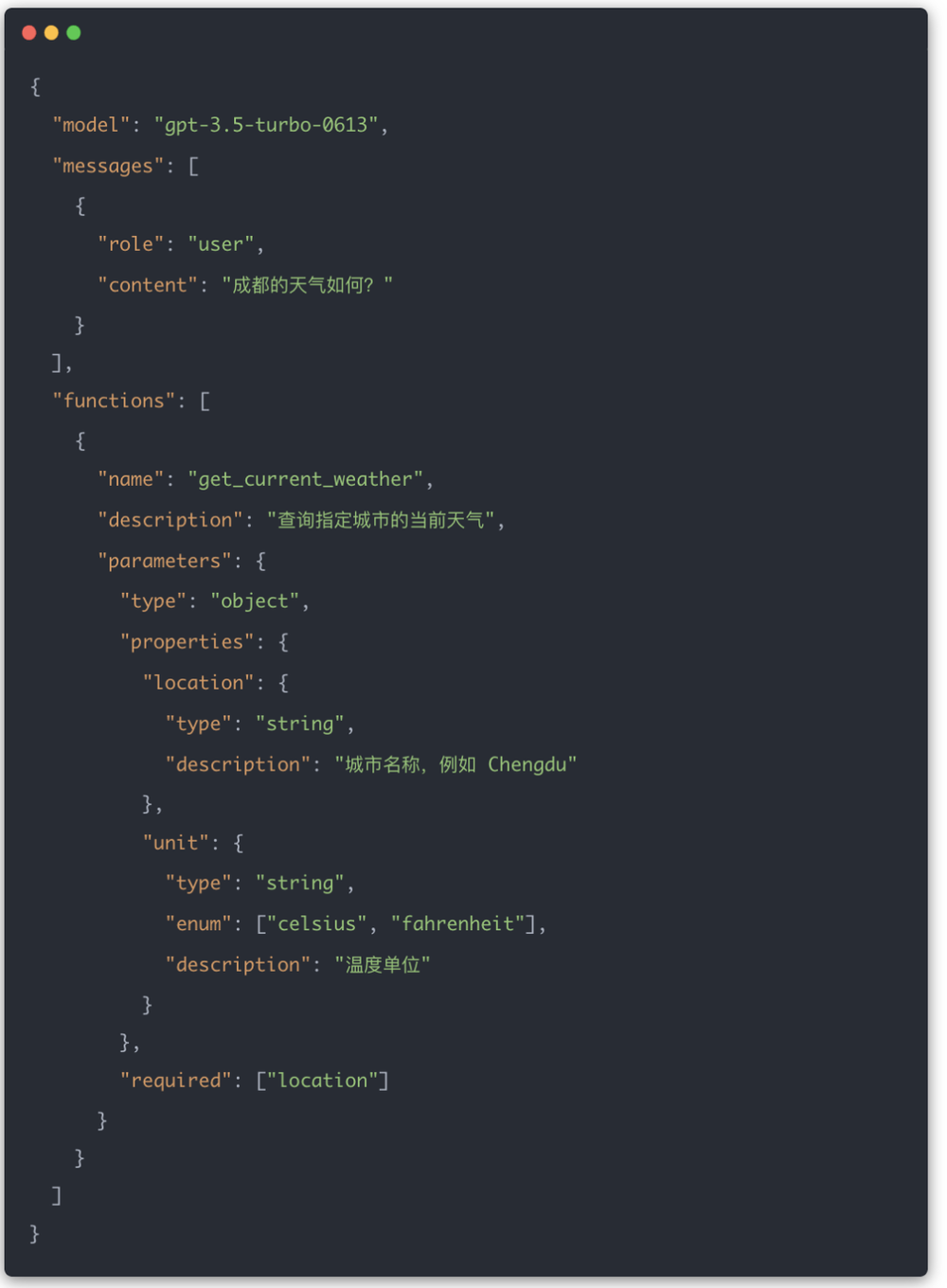
如果模型判断需要查询天气,它会返回一个函数调用请求:
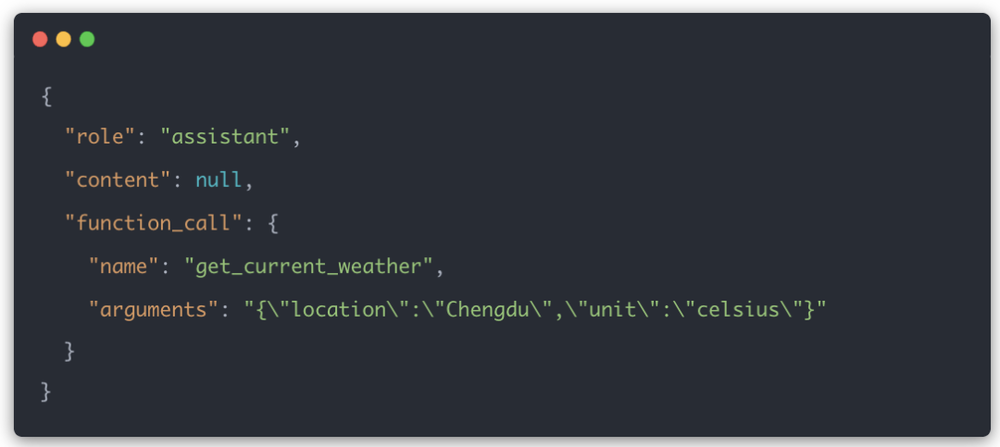
这里返回是模型训练的结果(去年下半年在工具识别这里比上半年强很多),但要注意这里返回的是JSON字符串,并没有去做调用;
调用API的是应用层(我们的业务后台),他拿到上面的完整工具JSON对象后,要先解析函数名和参数,再校验参数是否合法,然后再调用真实天气服务。
工具结果回来以后,还要把结果放回消息上下文,再次请求模型生成最终回答。也就是说,模型只是返回了一张结构化调用单,执行和兜底都在应用层。
工具调用体系
到2023年11月,OpenAI对FC做了进一步演进,这个阶段有两个明显变化:
模型可以在一轮回复中发起多个函数调用。
接口形式逐渐从functions和function_call演进为更通用的tools和tool_choice。
新的写法大致如下:
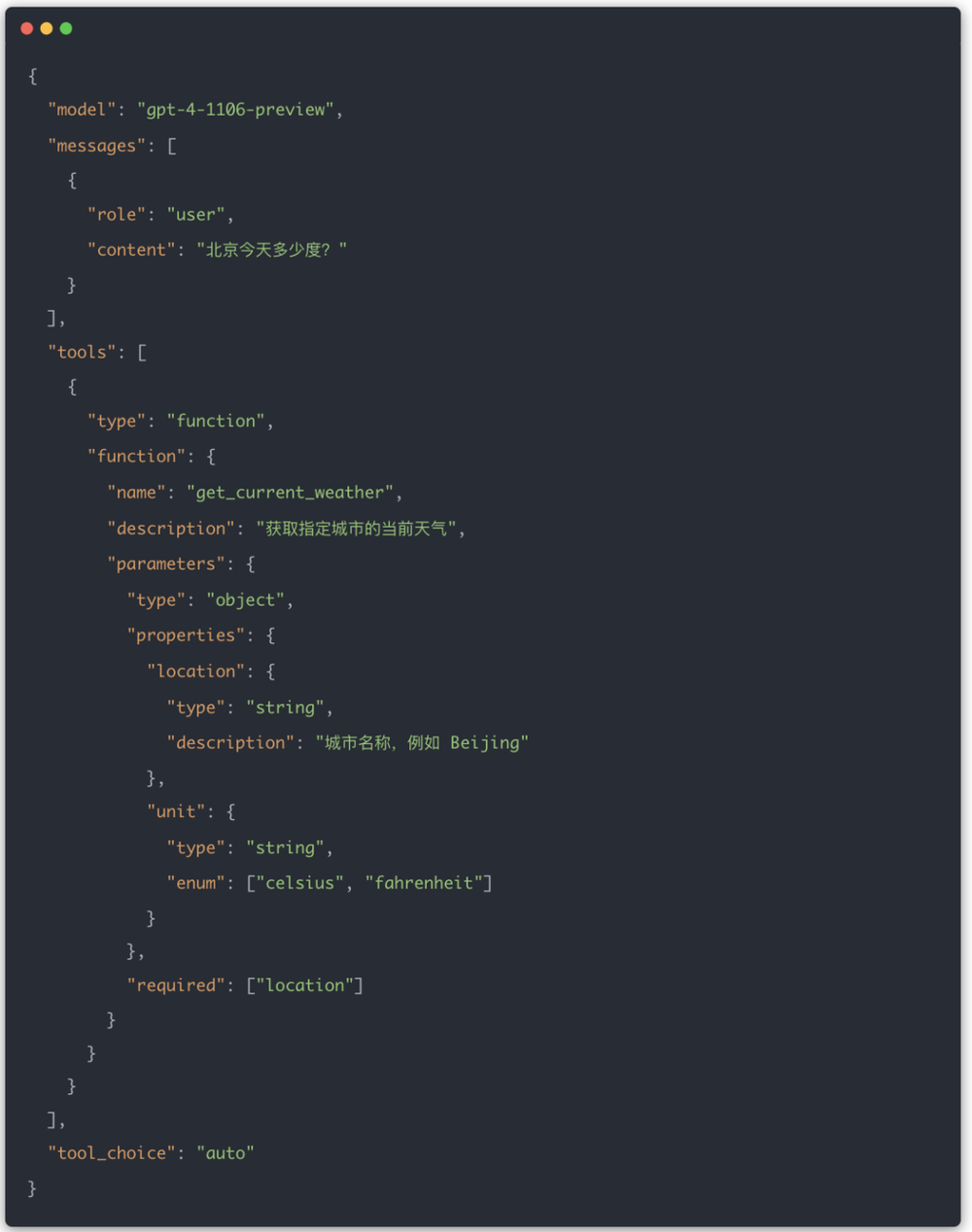
模型返回结构也发生了变化,早期返回的是单个function_call字段:
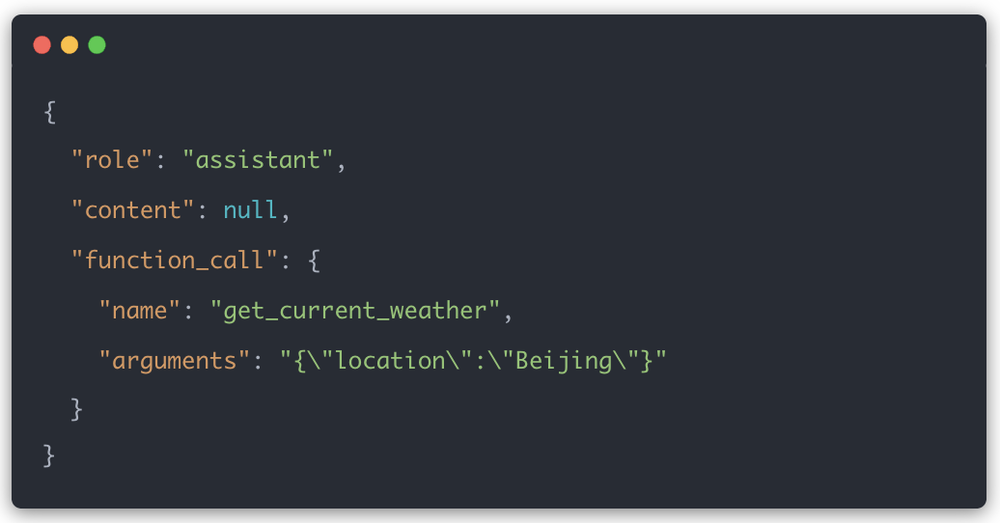
后来返回的是tool_calls数组:
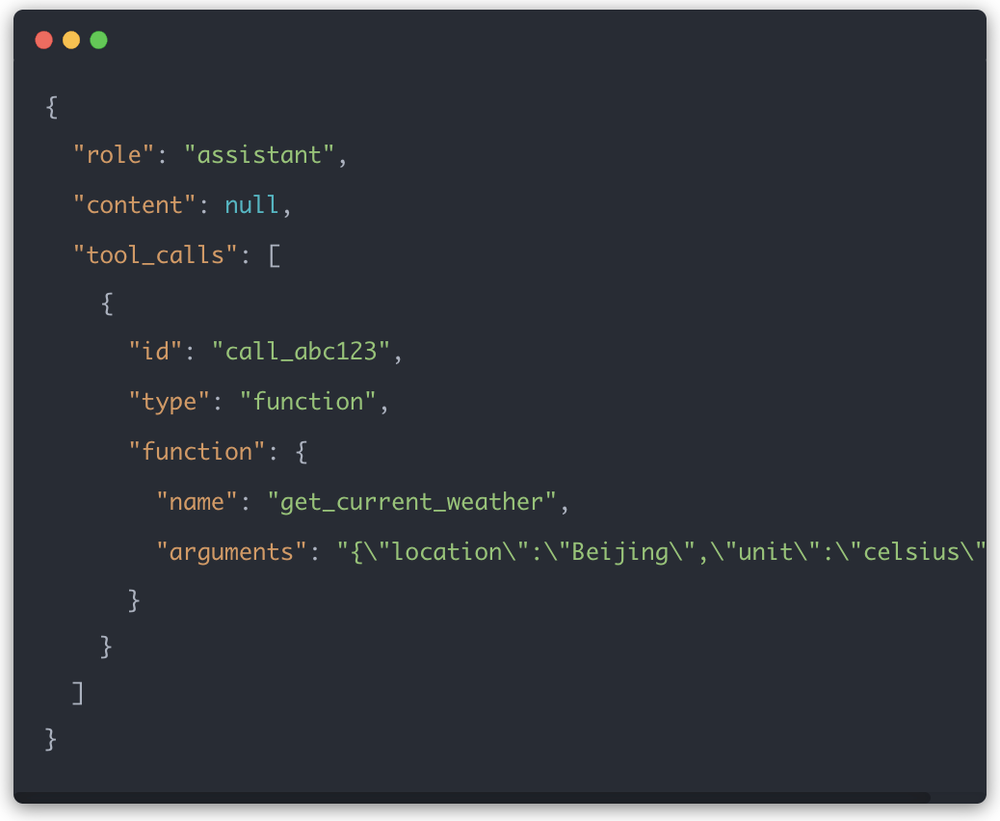
多个tool_calls的价值在于:一个订单问题可能同时要查订单、查物流,这些调用并行起来,延迟就不会被单方面拖住。
字段也从function_call变成tool_calls,说明模型正在从单个函数调用走向通用工具调用体系。
到这一步,function更像tool,它可能是函数、文件、浏览器操作、代码执行器,甚至另一个Agent。
其他模型厂商的跟进
随着工具调用能力越来越重要,其他模型厂商也陆续支持了类似机制。例如,包括Claude、DeepSeek等。
不同模型厂商的字段名称、协议和返回结构都不太一样。但不管如何变化,开发者要处理的事情并没有改变
一个完整的调用流程如下:
先把工具定义清楚,
再交给模型判断是否需要调用,
由应用层执行对应工具,
把执行结果重新放回上下文,
最后让模型基于新信息继续推理,直到任务完成。
这个流程正是Agent工具调用的基础。
稳定格式
Function Calling最大的变化是:以前要靠提示词去约束输出JSON,现在接口直接返回定义好的字段。应用层不需要再费劲从自然语言里拆函数名和参数了,可以直接从接口返回的字段中获取函数名称和对应的参数。
不管是之前的JSON还是现在的Function Calling都是模型输出工具的方式,它并没有解决工具调用之后的一系列工程问题:
它选的工具是对的吗,参数是不是可信,执行失败以后怎么办
这些问题都还存在,工具执行不能稳定的执行。
我们可以从三个层面来理解Function Calling的稳定性
第一层是格式稳定。模型返回的是结构化字段,应用层可以拿到工具名、参数和调用ID,这个已经由模型厂商返回的Function Calling解决
第二层是语义稳定。模型要在一组工具里选对那个工具,参数也要来自用户输入、上下文或上游工具结果,不能靠猜。
第三层是执行稳定。工具真的跑起来以后,会遇到超时、权限、业务状态、高风险动作、循环调用这些问题。这些已经超出模型返回格式本身,必须交给运行时兜住。
Agent是如何使用工具的
如果把Function Calling放进Agent里看,它会变成一轮一轮推进的循环。这个循环通常叫Agent Loop。
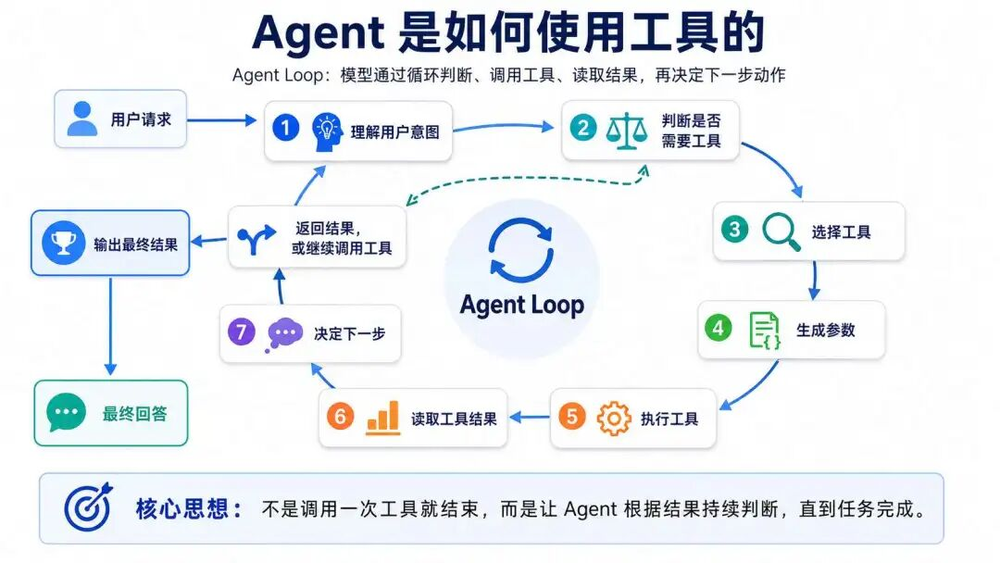
从上图可以看出,Agent Loop是一个由模型驱动的运行时循环:
应用层把用户消息、系统提示词、历史上下文和工具列表一起发给模型。
模型判断是否需要调用工具。
如果模型返回工具调用请求,应用层执行对应工具。
应用层把工具结果追加到消息上下文中。
再次请求模型。
模型继续判断是否需要下一次工具调用。
直到模型不再返回工具调用请求,循环结束。
一般聊天机器人主要生成文本,Agent需要在生成文本和调用工具之间来回切换。
真实调用过程
如果只看天气查询,Function Calling会被理解成一次工具调用:用户问天气如何,模型就返回get_weather这个工具调用,应用层执行工具,把结果交回给模型。
线上业务可不是这么简单的一次工具调用
例如:
帮我把这个订单的收货地址改成新地址。
Agent收到用户的请求后,并不会马上调用一个修改地址的工具。
它要先确认用户说的是哪一个订单,在历史会话里面去找订单信息,还要根据订单信息判断目前还能不能修改地址,当前用户有没有权限去修改订单的地址。
如果不能修改地址,系统还要把业务状态返回给模型,让模型解释为什么不能修改,好让用户明白这个事情为什么不能做。
一个看起来很普通的用户请求,再进入Agent系统以后,背后都是一条真实的运行时链路。
传统业务系统里,流程都是写死的。查订单,检查订单状态,修改地址。每一步什么时候执行,开发者已经提前写好了。
Agent不一样。它没有一条完全固定的执行路径。每一步调用哪个工具,都是模型根据当前上下文临时判断出来的。
这种方式比较灵活,由模型自己决策业务流程怎么走,选择哪些工具来执行,这就会带来一些不可控的风险:
模型选错工具
模型生成的参数不合法
工具执行失败
工具结果太长,超出上下文
模型一直调用工具,不停止
高风险工具被误用
......
我们可以把这些问题都归纳为四种运行时治理能力:
工具入口治理,
工具执行治理;
上下文与收敛治理;
安全与授权治理。
Agent能不能稳定运行,很大程度上取决于运行时有没有把这几个治理功能做好。
Agent工具治理
工具治理的核心就是保证工具执行的稳定性。
工具入口治理
入口治理就是工具在执行之前,由运行时系统主动做检查。
主要看这2个问题:模型是否选对工具,返回的参数是否正确。
我们可以在工具调用之前,尽量把这些问题解决,下面这几个方法可以试一试

工具定义要清晰
工具定义不要有歧义,在写工具说明的时候,可以根据下面几个说明来写:
这个工具做什么;
什么时候应该用;
什么时候不要用;
参数从哪里来,不能怎么填。
下面这个定义就过于模糊:
{
"name":"query",
"description":"查询信息"
}
这个写法人看了都摇头,模型就更加看不懂了!
在来看下面这个例子,是不是就清晰很多。
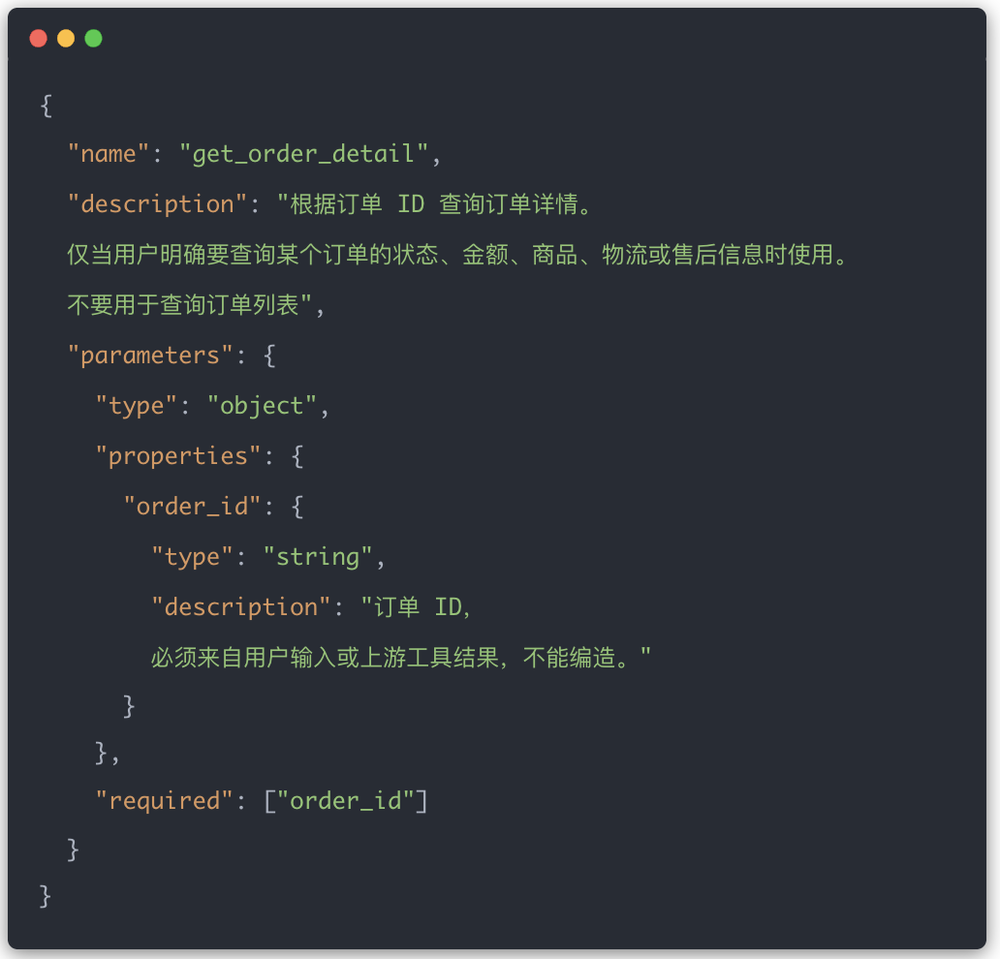
工具定义越清楚,模型越不需要猜。
单次暴露给模型的工具不要太多
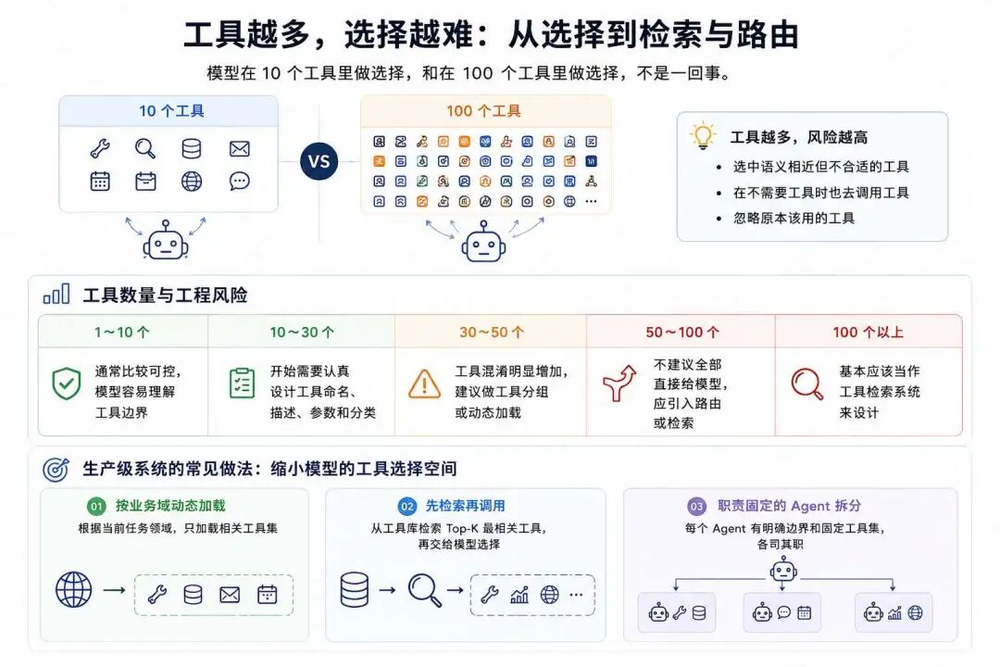
模型在10个工具里做选择,和在100个工具里做选择,难度不在一个级别上。OpenAI官方文档里面也明确说明最多可访问128个工具。
从工程实践看,工具多了之后,选择本身就会慢慢变成检索和路由问题。
实际在做Agent系统时,我平时一般大致按下面这个数量评估风险:
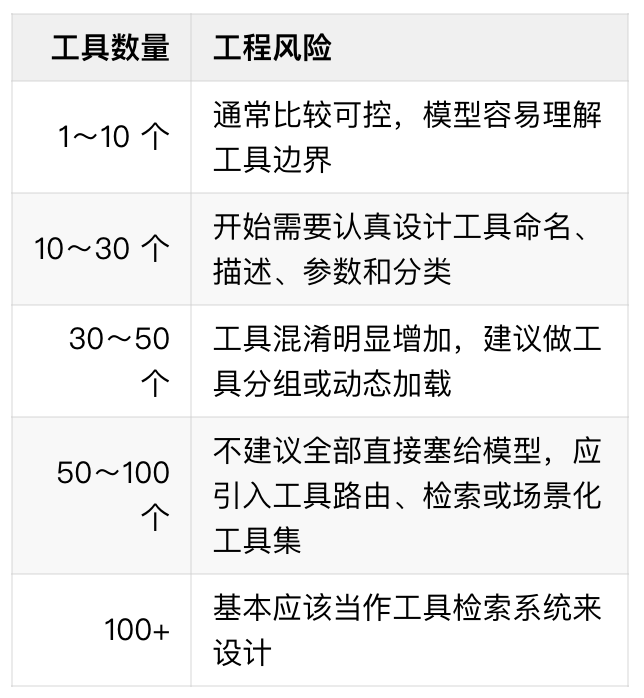
工具越多,模型越容易犯一些低级错误:挑一个语义相近但其实不对的工具、不该调工具的时候也去调、或者把本来最合适的那个给忽略了。
生产环境里没人会一次性把所有工具都丢给模型,通常都会先做裁剪。我见过这几种做法比较实用:
按业务域动态加载:根据当前任务所需领域,只加载相关工具集;
先检索再调用:从工具库中检索Top‑K个最相关工具,再交给模型选择;
职责固定的Agent拆分:为每个Agent分配明确边界和固定工具集,各司其职。
给模型明确的工具选择规则
除了工具定义本身,还可以在系统提示词里加入工具选择规则,例如:

参数必须做运行时校验
模型给出的参数不一定总是合法的,执行前应用层必须做参数校验。可以通过工具定义的参数信息,检查必填字段、字段类型、枚举值、业务约束等相关信息是否符合字段的定义约束。
如果参数检查不通过,系统不能只返回一个笼统的失败信息。我们需要返回结构化错误,并说明原因,让模型判断下一步要怎么做,是修正参数,还是向用户追问缺失的信息。
例如:
{
"success":false,
"error_type":"invalid_arguments",
"message":"order_id is required",
"retryable":false,
"suggested_action":"ask_user_for_order_id"
}
工具执行治理
我们在工具调用前,已经做了必要的检查,但是工具执行失败仍然会发生,外部系统出错超时,权限不足,业务状态不对等
传统软件里失败后常见做法是重试,但Agent的工具执行不能这么简单地一刀切,需要根据不同错误类型选择不同策略。
我们梳理了常见的错误类型:
invalid_arguments:参数错误;
timeout:超时或临时不可用;
permission_denied:权限不足;
business_rule_violation:业务规则不允许;
unknown_error:未知异常。
不同类型的错误,处理策略完全不同。
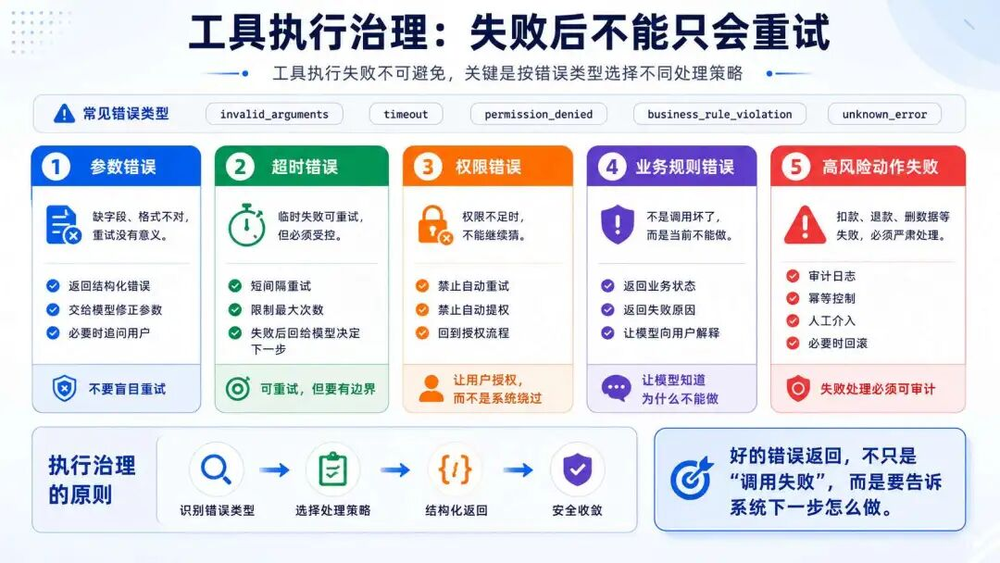
参数错误
工具如果缺少必填字段,字段类型不对这类错误继续重试一点用都没有。我们应该把错误结构化返回给模型,让模型知道那个参数有问题,具体错误是什么,引导模型重新生成参数。
超时错误
调用工具出现网络超时、第三方服务临时不可用的时候,一般我们可以设置自动重试,需要有一定的规则限制,不能无限重试消耗资源:
短间隔重试;
限制最大次数;
重试仍失败后,把结果回给模型;
由模型决定是否向用户解释、是否改走其他路径。
权限错误
如果遇到权限错误,就不能让模型自己发挥了,需要有一套机制来处理权限问题,例如:
禁止自动重试;
禁止自动提权;
明确告诉模型当前没有权限;
必要时要求用户授权或切换账号。
业务规则错误
如果用户要求取消订单,但是业务系统显示订单已经发货。取消订单这个操作就执行失败了,系统需要将失败原因详细返回给模型,让模型能向用户解释原因。
高风险动作失败
我们线上有个原则:扣款、退款、删数据、改权限、发通知这类动作,如果调用失败,重试是最危险的。必须同时做审计日志、幂等控制(防止重复执行)、自动失败后转人工处理,并且要把最终状态推给用户。
如果工具返回错误只是一句调用失败,模型就会懵掉,它就不知道下一步要怎么办了,就会自己胡乱的重试。我们需要把错误类型、失败原因、能不能重试、是否需要用户介入这些信息通过结构化的方式返回给模型,模型才能判断下一步要怎么做。
上下文与收敛治理
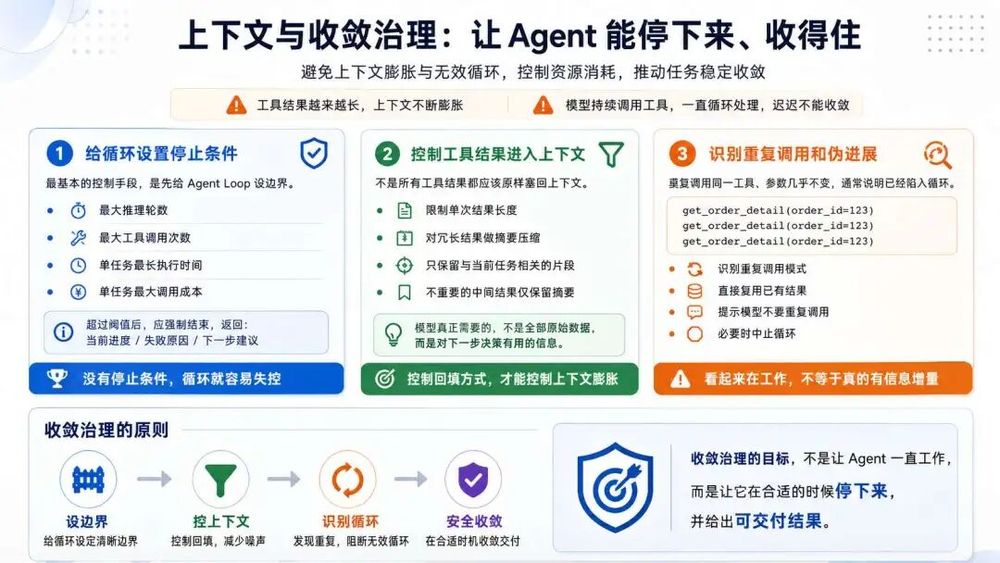
前面我们讨论了工具执行前和执行中的治理逻辑,Agent在运行的时候还有2个显著的问题:
工具返回的数据,不断累加,模型上下文不断增多
模型反复调用工具,一直无法收敛
循环停止条件
当模型无法收敛、出现无限循环执行时,可以采用以下几种最基本的控制策略
最大推理轮数
最大工具调用次数
单任务最长执行时间
单任务最大调用成本
在设计Agent系统时,需要在程序中显式实现上述规则。一旦Agent的执行达到任一规则设定的阈值,系统应主动终止循环,并向用户返回终止执行的详细说明。
控制工具结果进入上下文
工具结果应避免原样添加回上下文。特别是搜索、数据库查询、文件读取、网页抓取等工具,返回内容往往过长,容易导致上下文溢出或干扰模型推理。
更稳一点,可以这样处理:
限制单次工具结果长度
对冗长结果做摘要压缩
只把与当前任务相关的片段放回上下文
对不重要的中间结果仅保留摘要
核心原则是:让模型在做下一步决策时,拥有足够且有用的信息进行推理。
工具结果结构化
我们在设计工具的时候,对工具的返回信息,不能简单的就返回一句话,而是要为Agent的工具进行统一的结构化设计,所有工具都返回同样的格式比如下面这种,工具执行失败时返回错误类型,错误信息,是否重试,下一步建议等。
{
"success":false,
"error_type":"order_not_found",
"message":"未找到该订单",
"retryable":false,
"suggested_action":"ask_user_to_check_order_id"
}
工具执行成功时也一样,把模型下一步会用到的信息整理出来。比如订单状态、是否允许退款、是否允许改地址等。
{
"success":true,
"order_id":"123",
"status":"shipped",
"can_change_address":false,
"can_refund":true,
"next_actions":["explain_address_change_unavailable","offer_refund_help"]
}
这样做的好处是,模型不需要从一段业务文本里重新推断状态。工具结果越结构化,Agent Loop下一步越容易稳定。
识别重复调用
如果模型连续多次调用同一个工具,并且参数都是一样的,正常情况一般都是陷入了死循环。
例如:
get_order_detail(order_id=123)
get_order_detail(order_id=123)
get_order_detail(order_id=123)
这类调用看起来还在工作,但是对模型完成任务已经没有一点帮助。在设计Agent系统时,可以考虑增加以下规则:
识别重复调用模式;
直接复用已有结果;
提示模型不要重复调用;
必要时中止循环。
安全与授权治理
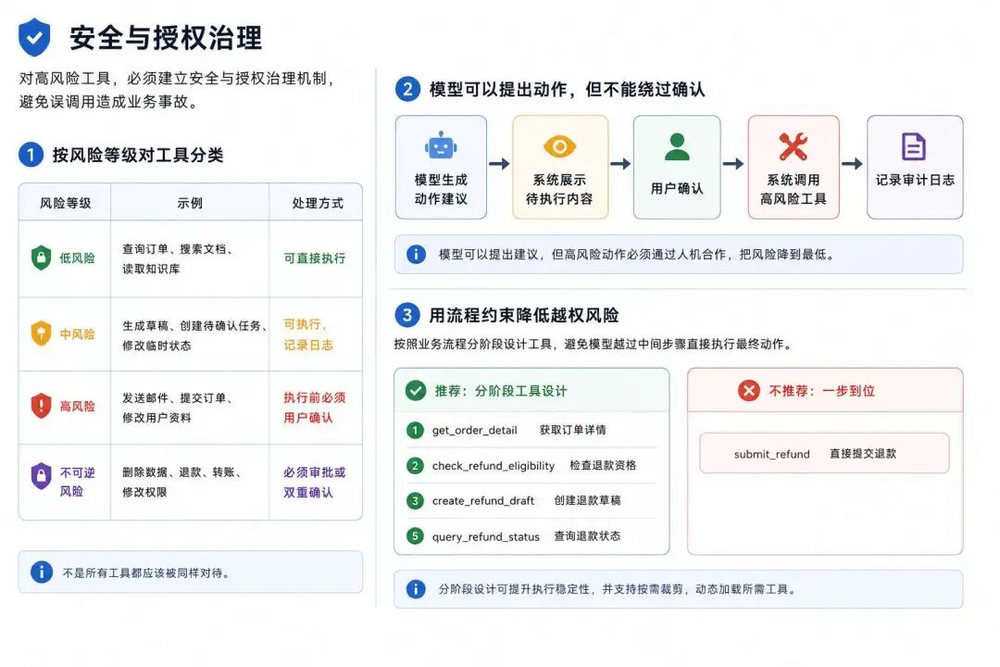
对于高风险工具的调用,我们必须设计一套安全授权机制,不能让模型随意调用。保证业务数据安全,避免线上业务事故
工具安全分类
我们常用的方法时对工具进行分类,把不同的工具设置分组到不同的风险等级中
| 风险等级 | 示例 | 处理方式 |
|---|---|---|
| 低风险 | 查询订单、搜索文档、读取知识库 | 可直接执行 |
| 中风险 | 生成草稿、创建待确认任务、修改临时状态 | 可执行,但要记录日志 |
| 高风险 | 发送邮件、提交订单、修改用户资料 | 执行前必须用户确认 |
| 不可逆风险 | 删除数据、退款、转账、修改权限 | 必须审批或双重确认 |
这个分好了之后,系统在执行工具的时候,就可以根据工具的安全分类,采取不同的执行策越。
高风险工具手动确认
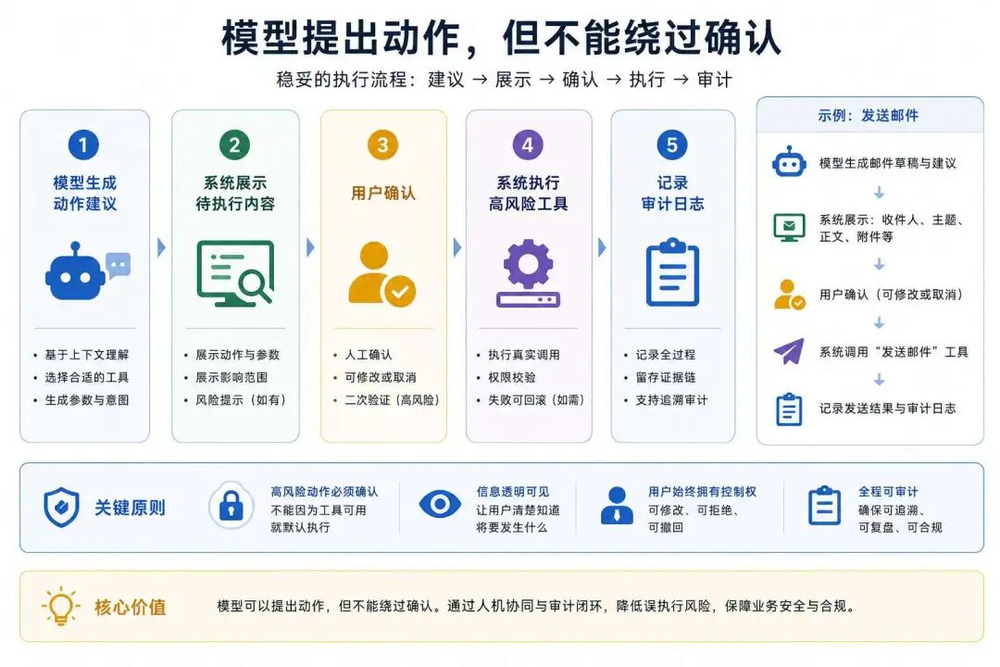
当模型返回一个高风险工具的调用时,必须要通过用户手动授权才能去执行工具,这个需要在系统中设计一个高风险工具执行的流程。
一般我们会讲工具执行的信息发给用户确认,用户确认后才能执行,如果用户拒绝执行,需要把拒绝的行为明确告诉模型。
用流程约束降低越权风险
我们在设计工具的时候,可以根据业务流程来细分工具。
例如退款流程,我们可以给一个submit_refund这种直接退款的工具,但是这样就有一些问题,这个单子能不能退款,退款金额是多少,大模型就不知道了,用户确认的时候,也不能给出足够的信息,让用户判断是否能够执行退款操作。
我们不如将流程拆分为多个细粒度的工具:
get_order_detail–获取订单详情
check_refund_eligibility–检查退款资格
create_refund_draft–创建退款草稿
submit_refund_after_confirmation–确认后提交退款
query_refund_status–查询退款状态
模型必须依次调用这些工具,模型可以获取更多的信息来推理和显示,同时也无法一步就直接退款。这就从流程上约束了越权风险。
此外,还可以按当前流程阶段动态加载相关工具:比如在确认资格阶段只暴露前两个工具,完成后再加载后续工具。这样既避免了把所有工具一次性交给模型,也让业务执行更加可控、稳健。
这里关于工具整理的话题就差不多了,我们再额外思考一个问题:为什么业务工具不能直接使用后端API?
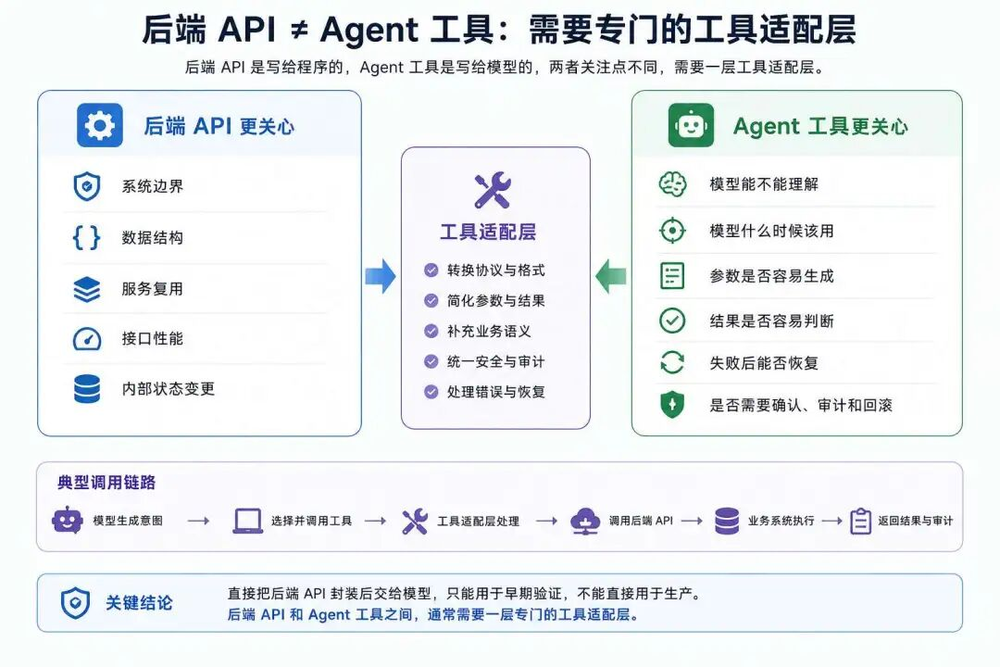
业务工具问题?
当我们需要把我们的业务改造成Agent系统时,多数人的第一反应都是:直接把后端已有API封装成工具,交给模型使用。方便,快捷,也不用二次开发。
这种只能作为早期Demo,通常不能直接用在生产环境上。
后端API面向程序,接口语义宽一点也没关系,人能看懂就行,工具面向模型,它要帮助模型在上下文里判断该不该用、参数能不能补齐、失败后怎么解释等。
所以,后端API和Agent工具之间,通常需要一层专门的工具适配层,我们需要重新设计一套业务工具提供给大模型,具体完成业务的还是后端的API。
比如后端有一个订单更新的接口:
POST/api/order/update
它可以接收很多参数,修改订单状态,修改订单金额,还可以修改订单的商品信息,物流信息等。
如果直接把它暴露成一个update_order工具,模型很容易犯糊涂,这个工具语义太宽、参数太复杂、风险边界也不清楚。
我们面向模型设计工具时,需要按照业务动作来设计工具:
update_order_address
cancel_order
add_order_remark
confirm_order_refund
工具要简单、职责单一,模型就很容易做出判断和选择。
工具参数也不能直接复用接口字段,需要先分清楚哪些信息该可以让模型来生成,再按照执行动作所需把必要的字段暴露出来。
按照来源,工具参数可以分成三类:
用户明确提供的信息:如订单ID、退款原因
模型能从上下文可靠提取的:如当前选中的商品
只能由系统自动补齐的信息:如产品标识、trace_id
前两类可以出现在工具参数里,第三类运行时自动补齐。
工具调用稳定性
工具调用的稳定性一直以来都是Agent的热门难点,所以怎么判断FC是否稳定呢?

这里就不能只看Demo了,因为Demo通常路径很短,工具也少,用户问题也比较标准,但生产环境里的问题更乱,用户的表达更是千奇百怪,这里复杂性就变高了。
我会看这几个指标。
工具选择稳定性。
同一个用户意图,模型能不能稳定选到正确工具。
如果用户问订单物流状况,正常应该调用物流查询工具。如果它有时查询订单详情、有时又去查知识库,出现模型不知道改选谁的情况,可能就是这两个工具相似性太高了。
参数生成稳定性。
模型输出调用工具的参数是否正常,比如必填字段有没有缺,具体数据提取的怎么样。
失败恢复能力。
工具调用失败这个很正常,我们必须要考虑工具执行失败返回的信息,是不是对模型下一步推理有用,让模型能够继续执行完成用户的任务。我们需要把工具失败的信息进行分类和结构化的数组,让模型明白失败的原因是什么。
循环收敛能力。
Agent Loop是否会重复调用同一个工具,是否会在没有新信息时继续消耗资源,是否能在达到阈值后给用户一个清楚的状态说明。一个Agent看起来很努力地调用工具,不代表它真的在推进任务。
高风险动作拦截能力。
涉及退款、删除、付款、权限修改、发送通知这些高风险工具调用时,系统是否稳定触发确认、审批这一类动作。这里不能依赖模型自觉,必须由运行时来兜底。
结语
篇幅差不多了,收下尾。
如果只看接口定义,Function Calling一点都不复杂,开发者把工具定义描述给模型,模型返回工具名和参数,应用层执行工具,再把结果返回给上下文,一个调用流程就走完了。
这里看着简单,Demo牛逼,结果上线就完蛋的Agent项目还挺多的。
这也是Agent开发真正的难点了:如何构造一个Agent能够稳定的工程环境?
当然,这个话题,我们下次再继续!
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。