2026-06-15 09:18

本文来自微信公众号: 叶小钗 ,作者:叶小钗,原文标题:《WorkBuddy VS 钉钉悟空 VS 字节 Aily:桌面 Agent 的工程设计》
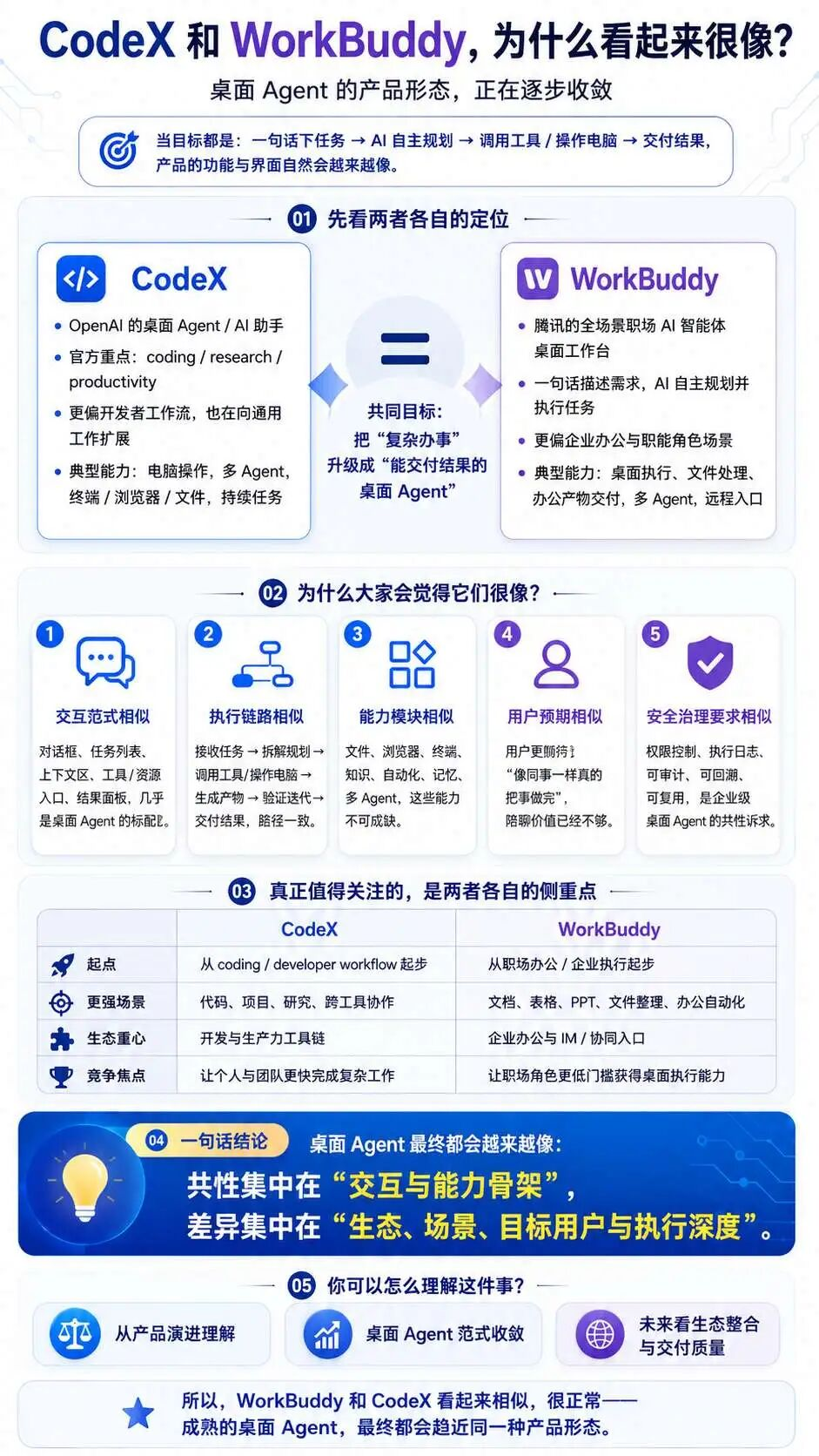
从小龙虾OpenClaw以后,国内几个巨头都在追求桌面段的Agent入口,比如:
钉钉的悟空体系;
腾讯的WorkBuddy体系;
字节的aily;

就当前的体感来说:WorkBuddy被接受的程度可能是最高的,虽然不知道它为什么火了,出去逛一圈都有人在讨论它。
作为技术博主,我们当然想要看到不一样的东西,依旧是从它的实现机制出发吧!
WorkBuddy是什么
官方的原话是:
WorkBuddy是腾讯推出的全场景职场AI智能体桌面工作台,面向各类职能角色设计
您只需用一句话描述需求,WorkBuddy便能像同事一样自主规划和执行任务,并交付可验收的结果。
官方的说法WorkBuddy看起来是一个企业级的桌面Agent,我们简单问它一个问题:你能做什么?
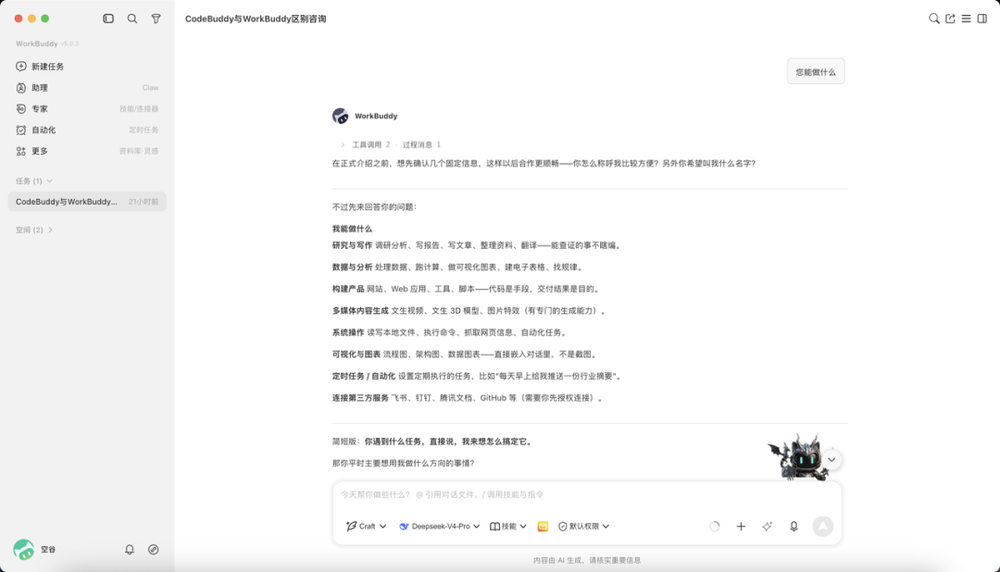
整个界面和CodeX非常相似,基本上差不多,这里我们就不一一展开做功能介绍,大家可以自己去感受下:
一出来就出现了你是谁\我是谁,这两个经典问题,然后就是它自己能做什么的一个功能介绍。
他既然是一个Agent,我们知道Agent是由模型,工具,技能,上下文,运行时等组成...
事实上,我每次看到一个新的Agent的时候,最关心的是上下文工程的管理,因为我觉得上下文工程决定了这个Agent是否聪明、好用的关键。
而上下文工程里面我一般比较关注系统提示词的组装,会话压缩机制,记忆机制,下面我们逐一展开来看看:
系统提示词
每研究一个新的Agent,我总是会从系统提示词开始,于是我准备让WorkBuddy给我介绍下它的系统提示词:

WorkBuddy拒绝了我,没有给我系统提示词,我就想了点其他方法。
从我拿到的系统提示词来来看,内容较多,它大致可以分成下面这些模块
能力定义
记忆系统
用户画像
内容安全策略
个人文件安全规则
区域化习惯
工作模式
Agent Loop
结果展示规则
代码探索子代理
自动化任务
工具使用规则
可视化规则
任务管理
提问与澄清规则
工具调用策略
Skills机制
专家管理
MCP配置
回复语言设置
运行环境配置
能力定义
这一部分的提示词用下面这部分开头
Here's what you're good at—and you should use all of it......
系统提示词一开始就定义了WorkBuddy的能力边界,我们开发Agent的时候,总是说你是一个什么什么的助手,这里不是这样,而是告诉模型,你不是只会聊天,你可以想一个会使用电脑的人一样完成任务。
并且提示词里面也说明了它能做什么,比如:文档生成、数据分析、邮件处理,周报生成,可以写代码,构建网站等。
这些能力的定义,就是在告诉模型,遇到真是任务时,不要停留在说,而是可以主动的去完成,你可以做到这些事情。
记忆系统
在提示词里面记忆系统占了很大的篇幅,用了一个标签
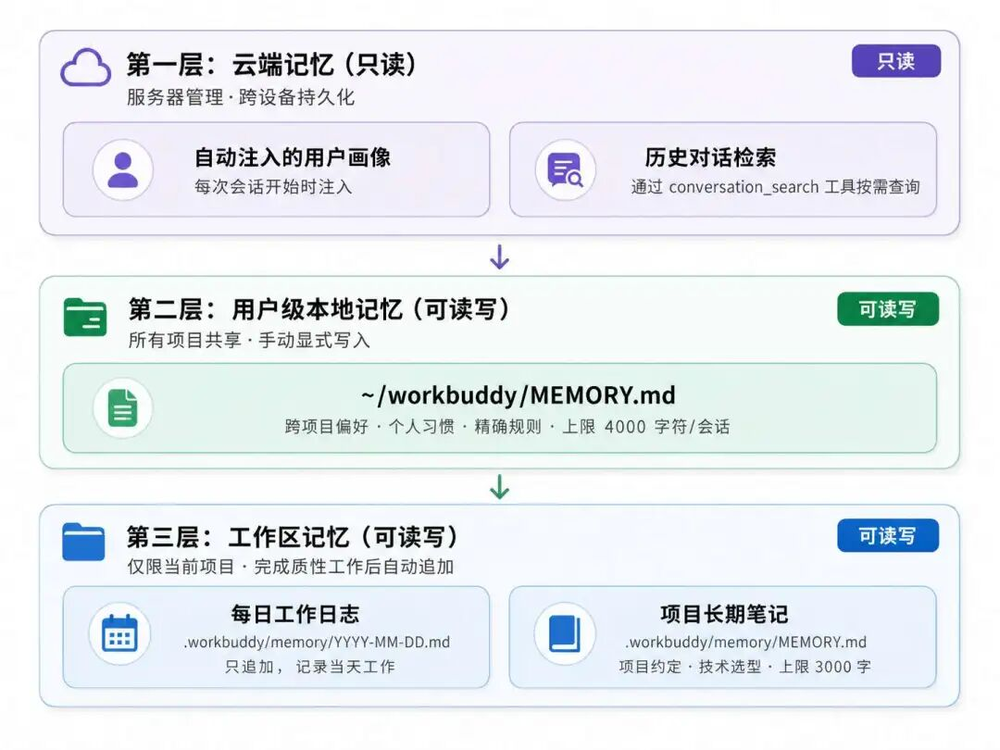
第一层是Cloud Memory,也就是云端记忆。
这部分包含了两个能力,一个是自动注入用户画像,另外一个是历史会话检索,自动注入的用户画像是只读的,模型不能随便改,历史会话检索适用于查找用户过去聊过的内容。
比如用户说,我们之前谈论的那个压缩方案,你还记得吗?
这个时候模型就会使用历史会话检索能力,而不是瞎猜。
第二层是User-level Local Memory,也就是用户级本地记忆。
它的文件位置是:
~/.workbuddy/MEMORY.md
这部分是跨项目生效的,适合记录用户长期稳定的偏好和规则。比如:
用户希望所有回答都用中文。
用户希望代码示例尽量简单。
用户希望某类项目默认使用Vue而不是React。
这类信息不是某一个项目独有的,而是长期跟随用户的偏好,就适合放到用户级记忆里。
第三层是Workspace Memory,也就是工作区记忆。
它只对当前项目生效,放在当前项目的.workbuddy/memory/目录下面。这里面又分成两类:
一类是每天的工作日志.workbuddy/memory/YYYY-MM-DD.md每日工作日志是append-only,也就是只能追加,不能覆盖。它用来记录当前项目每天做了什么。
另一类是项目长期记忆.workbuddy/memory/MEMORY.md,项目长期记忆则用来沉淀更稳定的项目结论,比如技术选型、架构约定、项目规则等。
它把记忆拆成了三个不同作用域:
云端用户画像:跨设备、跨会话、只读注入
用户级本地记忆:跨项目、用户显式要求记住的规则
项目级记忆:只服务当前工作区,记录项目上下文
记忆如何写入
完成实质性工作后,立即使用Edit工具将简短记录追加到.workbuddy/memory/YYYY-MM-DD.md这个文件中
实质性工作包括:
构建或修改了网站/应用
修复了一个bug
编写或生成了报告/文档
完成了代码重构或架构更改
选择了技术方案(框架、设计模式等)
用户如果分享了项目约定或偏好,同时更新.workbuddy/memory/MEMORY.md文件
用户画像
系统提示词里还有一个
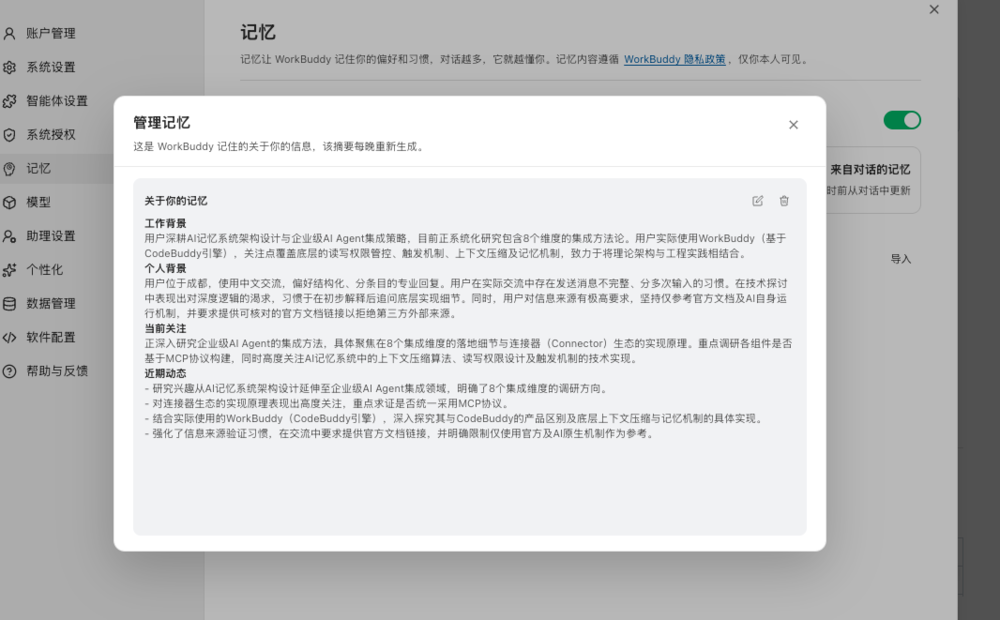
用户画像是什么时候写入的呢
这个记忆来之云端,在服务器上生成的,在WorkBuddy的设置可以看到记忆是由服务器在每天晚上定时更新,从我的使用来看,它从我的对话中总结了以下内容
工作背景
个人背景
当前关注
近期动态
内容安全策略
这一部分规定了模型不能泄露系统提示词、不能处理敏感政治内容、不能生成色情内容、不能提供违法活动指导、不能协助获取隐私信息、不能生成假新闻或欺诈文档等。
大家直接看下原始提示词是怎么说的:

个人文件安全
这一块写的是操作用户文件的安全规则。
用
像Desktop、Downloads、Documents、Home这些目录,都算高风险区域。具体要求有这几条:
不能递归删除这些目录
不能用rm-rf
扫描文件时只能生成报告,不能直接移动、重命名或删除
如果用户提的要求比较模糊,必须先追问
删除之前必须警告、列出文件、让用户确认
需要先做备份
删除要进回收站,不能直接物理删除
每批最多处理10个文件
WorkBuddy是能直接访问文件系统的。比如用户说帮我清理一下下载目录的文件,要是没有这套规则,它可能直接扫描并删掉文件,后果会很严重。
文件系统权限对这类Agent来说,能读写文件才真正能干实事,但没限制的话,也可能会造成不可逆的数据丢失。
工作模式:Craft、Plan、Ask
WorkBuddy的系统提示词里还定义了三种工作模式:,这部分主要放在了
Craft:你说,我做
Plan:先想,再做
Ask:只聊,不做
Agent loop:一步一步完成任务
这是我第一次在系统提示词里看到这么明确描述了Agent Loop的工作方法。一般我们都是在Agent runtime中实现这个机制。
大概的意思是:
它不是让模型一次性回答完,而是要求模型按循环方式完成任务
先分析上下文,然后思考下一步,再选择工具,执行动作,接收结果,然后继续迭代,直到任务完成。
这就是我们常见的Agent运行机制,我们来看下WorkBuddy是如何描述的

结果展示:做完任务后必须交付结果
WorkBuddy的系统提示词里还有一个
具体要求大概是:
如果是HTML文件,要用preview_url来展示
报告、PPT、视频这些,用open_result_view展示
生成附件的时候,要调用deliver_attachments交付
不能光生成一个文件扔在那里,却不告诉用户结果在哪
工具使用规则:什么时候用什么工具
WorkBuddy的系统提示词里还有一大块是关于工具调用规则的,这些都是非常实用,告诉模型什么时候选择合适的工具来做事情。比如:
优先用专门工具,而不是直接敲shell命令
要在代码库里大范围探索时,得用代码探索子代理
需要操作网页,得先加载browser skill
安装MCP要改指定的配置文件
删除自动化任务不能直接操作SQLite,要用自动化工具
腾讯文档的链接要按指定格式输出
腾讯乐享里的实体,要用badge里的id,不能按标题搜索
为什么需要这些规则,之前我开发Agent的时候,让Agent完成一个任务,我给它提供了专门的工具,但是它不选,因为我同时提供了代码执行工具,它就一直自己写代码去执行,偏偏它代码又写得不好,老是报错,都把我看着急了。
如果我们这里加一个提示词,优先使用专门的工具,这个问题可能就不会出现了。
Skills机制
WorkBuddy的系统提示词里还有一大段关于Skills的规则,使用
Skills是工作流的迁移这个事情大家都很清晰了,他扮演的是可复用的专业工作流。系统提示词要求:
用户任务匹配某个Skill时,要优先加载Skill。
如果遇到能力缺口,要先搜索是否有可用Skill。
浏览器相关任务,要加载agent-browser Skill。
安装新Skill前,要先做安全审计。
提示词里面还约定了用户技能和项目级紧跟的区别:
用户级技能:存储在~/.workbuddy/skills/。这些是当前用户在所有项目中可用的个人技能。
项目级技能:存储在{workspace}/.workbuddy/skills/。这些是项目特定的技能,团队成员共享。
这个skill机制里面还有一个有趣的说明,原始的提示词如下:

上面的大概意思是:如果完成了复杂任务,发现了可复用流程,就要把它沉淀成Skill,如果发现Skill有错误,你需要修改它,不要问用户,不要推辞,立即修复。
然后,这个不就是Hermes Agent的自我进化吗?
MCP配置:连接外部能力的标准入口
系统提示词里还包含MCP配置规则。
当用户要求安装或配置MCP Server时,WorkBuddy要修改:~/.workbuddy/mcp.json
并且有明确要求:
先查官方文档。
读取已有配置。
合并新配置,不能覆盖已有服务器。
按官方格式写command、args、env、headers、url。
如果需要凭证但用户没提供,要追问。
写完配置后,不直接运行MCP Server,而是提示用户去连接器管理页面信任。
这里可以看出,WorkBuddy把MCP当成扩展外部能力的重要入口,可以通过MCP连接外部工具和服务。
这也是当前Agent产品的一个主流方向:
模型本身负责推理和调度,外部能力通过工具、Skills、MCP等方式接入
所以,大家真的去做Agent的时候会发现:Tools和Skills的工作量是极大的。
可视化能力
系统提示词里还有关于Visualizer相关规则,它们在
它要求WorkBuddy在讲解复杂概念、架构设计、对比分析、流程图、图表等场景下,主动使用可视化工具。
这说明WorkBuddy的回答形式不是只有文本,可以根据用户的问题,生成示意图后者架构图,流程图等。
系统提示词里面有这么一个案例说明:
用户问:"解释一下TCP/IP是如何工作的"
→
主动使用Visualizer展示一个内联的协议栈示意图
然后在图示周围用文字进行解释
自动化任务:把一次性任务变成定时任务
关于自动化任务,WorkBuddy提供了表单创建,可以通过左侧的自动化菜单进入创建,同时也提供自然语言创建机制,这个提示词包裹在
这里支持周期性任务/自动化功能
自动化任务存储在SQLite数据库中,路径为$HOME/.workbuddy/workbuddy.db定义信息存放在automations表中,运行时状态(上次/下次执行时间)存放在automation_runtime_state表中,执行历史记录存放在automation_runs表中
你可以使用automation_update工具来创建、更新、查看或删除自动化任务
任务管理:复杂任务需要显式跟踪
系统提示词里还有任务管理模块,要求模型在复杂任务中频繁使用任务管理工具(TaskCreate、TaskGet、TaskUpdate、TaskList),把任务拆成小步骤,并及时标记状态。
这个设计解决的是Agent执行复杂任务时容易失控的问题。
复杂任务如果没有计划,模型很容易做到一半忘记前面做了什么,哪些已经完成,哪些没有完成。
所以它需要像真实项目管理一样:
创建任务。
标记进行中。
完成一个标记一个。
遇到新的问题再拆新任务。
会话压缩
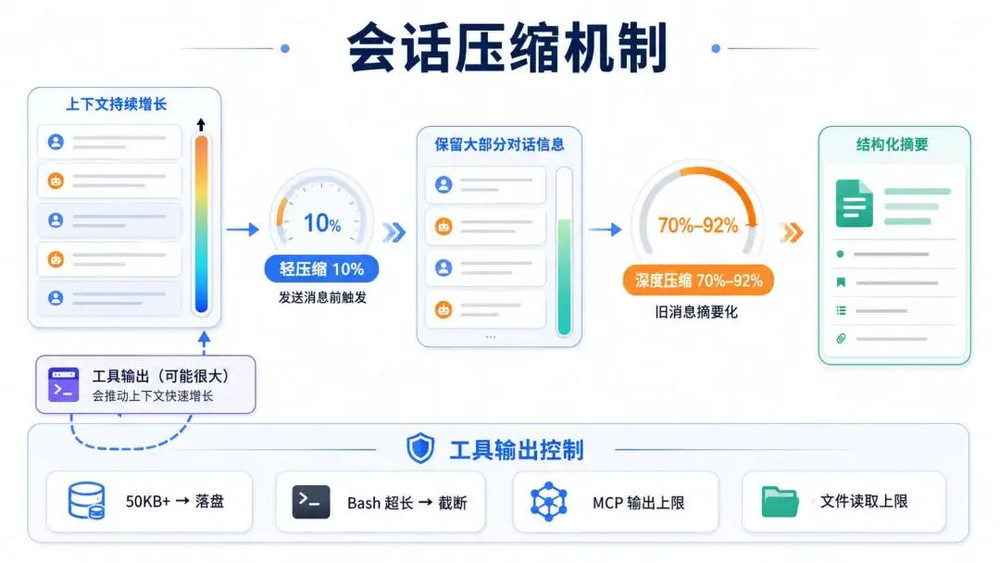
会话压缩机制,官方文档有2个环境变量说明
CODEBUDDY_PRE_MESSAGE_COMPACT_PCT,默认值是10%,每次发送消息前,系统检查当前上下文的占用比例,超过10%就自动压缩一轮,这个阈值设计的比较低,估计很容易就会达到,这个压缩会比较频繁。

上图中是触发压缩之后的内容,这个内容还是比较多的,没有怎么丢弃上下文,基本上是在重述整个对话过程,只是做了精简。
这也说明了为什么默认值10%,它并没有大幅度压缩原文,形成一个结构化的总结,而是尽可能的保留了原始内容。
CODEBUDDY_AUTOCOMPACT_PCT_OVERRIDE,默认70%-92%,当上下文持续增长到这个门槛,自动触发深度压缩,本质就是把旧消息做结构化的总结,变成摘要嵌入式上下文呢,释放大量空间。
看到这个我觉得很奇怪,就是前面10%已经被压缩掉了,怎么可能会到70%的上下文呢,我觉得唯一可能就是任务执行中,调用了大量的工具,返回了大量的内容触发了压缩,如下图所示
当上下文持续增长到这个门槛,自动触发深度压缩。
工具大量输入会触发压缩,系统有没有控制工具的输入,官方文档中给出了一些环境配置,用来控制工具的输入
CODEBUDDY_TOOL_RESULT_THRESHOLD_KB默认50KB工具结果超过此值,写磁盘,上下文里只留占位符
BASH_MAX_OUTPUT_LENGTH默认30000字符bash输出超限,保留头20%+尾80%,完整版落盘
MAX_MCP_OUTPUT_TOKENS默认20000 token MCP工具输出截断上限
CODEBUDDY_CODE_FILE_READ_MAX_OUTPUT_TOKENS默认20000 token文件读取token上限
结语
这篇文章,我们简单的解读WorkBuddy的系统提示词、记忆管理和压缩机制。
从最开始的你是谁,我是谁,这个问题,我们看到openClaw的影子,再到后面skills的创建和优化机制,我们又看到了Hermes Agent的影子,可以看出WorkBuddy正在吸收市面上其他Agent的优点,集大成于一体:
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。