2015-08-18 15:17

虎嗅注:当李开复还在谷歌的时候,他对搜索引擎的语音识别功能就非常着迷。几年过后,百度终于做了一个拿得出手的普通话语音识别模型,以及它背靠的深度学习系统Deep Speech。本文是SCALE记者对百度高级工程师Awni Hannun进行的专访,Hannun谈论了Deep Speech的特点、普通话语音识别的难点,以及对深度学习(Deep Learning)未来的展望。原文来自Medium,标题为《Baidu explains how it’s mastering Mandarin with deep learning》,由虎嗅编译。
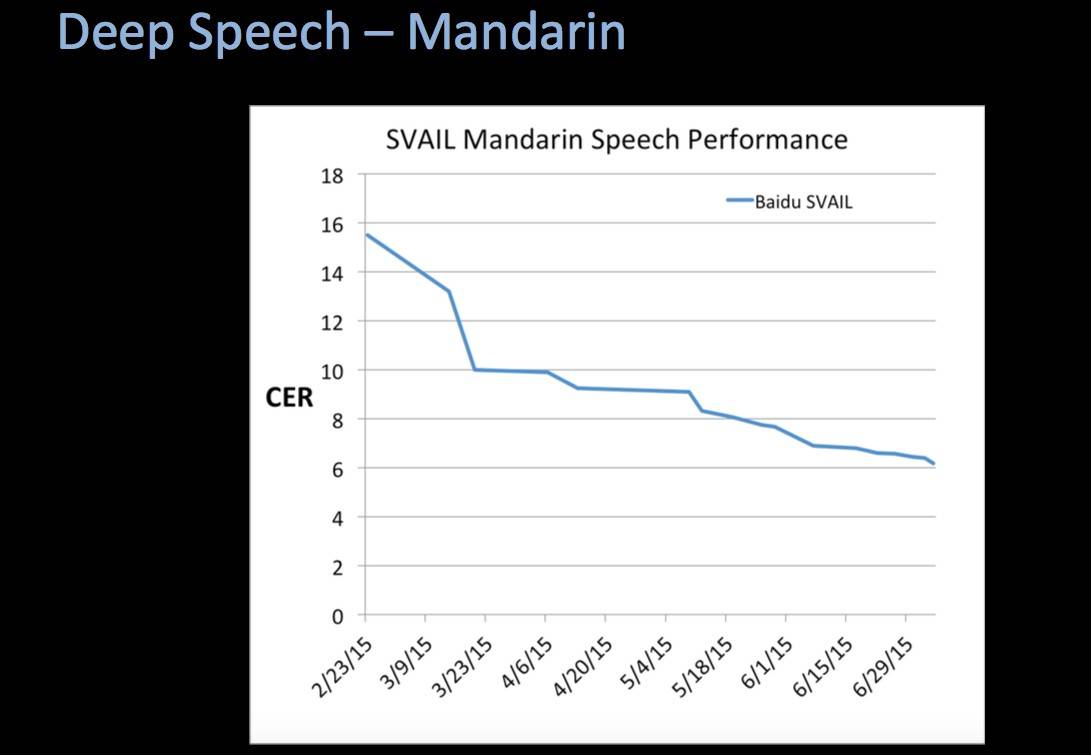
8月8日,国际神经网络协会(International Neural Network Society)在美国旧金山召开大数据会议。会上,百度的高级研究工程师Awni Hannun向大家展示了一个新的语音识别模型,由百度研发用以识别普通话语音检索。这个语音识别模型基于百度在2014年12月发布的深度学习系统Deep Speech,并在测试中达到94%的正确率。
在这个稍经编辑的采访中,Hannun将解释这个研究成果的重要性、为什么普通话是一种很难学习的语言,以及深度学习将对我们的未来产生怎样的影响。
关于Deep Speech
Q:Deep Speech在翻译普通话时的准确性如何?
Awni Hannun:有6%的错误率,也就是说在100个字中会有6个错字。如果放到语境中,我认为这是辨识普通话语音检索的工具中最好的一个系统(我们的研究数据也这样显示)。
事实上,我们做过一个实验。在我们的实验室里有几个会讲中文的人,他们将我们用以测试系统的语音进行人工识别和转录。结果显示,如果我们不让被试者使用网络或其他一些工具,系统的转录效果要比人工的好。
“我们提供足够多的数据,在尽可能少的人为干预下,让系统得以辨别与输入相关的信息,并正确输出转录结果。”
Q:为什么普通话的语音识别相比其他语言要难得多?
Awni Hannun:普通话和其他语言有几个区别,以至于我们的英语语音系统难以适用于这种语言。首先,这是一种有音调的语言。如果你用不同的音调说一个词,它的意思可能完全不一样了,这和英语完全不一样。在传统的语音识别中,音调的不变性很重要,也就是说系统在转录语音的时候,会忽略音调。所以,为了进行普通话(或其他中文语言)语音识别,你必须更改很多系统设置。
 Awni Hannun
Awni Hannun
但是,对我们来说,我们也不需要改变那么多的东西,因为我们的传输路径比传统语音的传输路径要简单的多。我们不需要在音频上做那么多的预处理,来减少音频的语调变化。我们只需要让系统从相关数据中学习音调,从而能够准确转录出语音信息。这种方法在普通话这种语言上很有效,并不需要改变输入。
中文(普通话)另一个不同之处在于它的汉字系统。英语只有26个字母,而在中文中差不多有八万个汉字。我们的系统在语音转换的同时直接输出汉字,所以我们认为和26个字母相比,每次在八万个汉字中工作的难度非常大。我们用以克服这个挑战的方法就是只使用汉字的一小部分,也就是人们的常用字。
Q:目前,百度已经开始在处理大量的语音检索了。Deep Speech系统相比以前的普通话语音识别系统,好在哪里?
Awni Hannun:百度的普通话语音检索很活跃,而且效果不错。我认为就所有的检索活动而言,语音检索仍旧只占据很小一部分。我们希望让这个比例变大一些,或者至少通过让语音识别系统更准确,使人们更多地使用这个功能。

Q:你能描述一下像Deep Speech这种基于搜索引擎的语音识别系统,和例如微软的Skype语音实时翻译系统(也是基于深度学习)的区别吗?
Awni Hannun:通常,语音识别有三种模式。第一种是语音-转录模式;第二种是机器-翻译模式;第三种是语音-合成模式。我们在谈的,其实都是第一种语音-转录模式,我相信Skype翻译的其中一部分是这种模式。
我们的系统和微软那个系统不一样的地方在于,我们的系统更多的是“端对端”。以前研发的语音检索都有很多人为干预:他们会看着系统,然后说哪些哪些特点很重要,或者系统应该要能够预测某种音素。我们不一样,我们只需要输入数据,也就是一段音频。对于一段WAV文件,我们几乎不用进行预处理。然后我们有一个巨大的深度神经网络可以直接转录输出文字。我们输入了足够多的数据,所以在尽可能少的人为干预下,系统得以辨别与输入相关的信息,并正确输出转录结果。
最令我们惊喜的是我们并不需要过多地对其进行修改,除了给它设定范围以及提供正确的数据。这个我们在去年12月展示的系统,在英语识别中做得非常好,中文识别也相当不错。
Q:通常对于这种系统,从研发到生产需要多长时间?
Awni Hannun:这并不是一个简单的过程,但我想不会比提高模型准确性更难——这更像是一个工程问题而不是研究问题。我们正在这方面积极努力,我们的研究系统很有希望在不远的将来投入生产。
Q:百度在其他领域有一些计划和产品,包括可穿戴设备,以及语音识别系统的其他嵌入形式。那么你在做的工作和其他一些项目有关系吗?
Awni Hannun:我们想要构建一个可以在智能设备中充当界面的语音系统,而不仅仅是语音检索。语音检索在百度的整个生态中非常重要,所以这正是我们可以有重大影响的领域。
 Baidu Eye:可穿戴电脑
Baidu Eye:可穿戴电脑
让深度学习模型无所不在
Q:目前深度学习的发展速度和重要成就,在你看来够快吗?
Awni Hannun:我认为现在深度学习的发展速度在加快,因为人们认识到当你输入一些内容,并期待从电脑中获得一些输出的时候,你正在使用深度学习。如果是一些老的机器学习任务,例如机器翻译或语音识别,这些是被人为重度干预的。但是如果你尝试用深度学习和数据来简化整个路径,就会得到显著的成效。我们正处在这个的顶峰。
特别的,我们刚刚找出怎样用深度学习处理接续的数据。我们做出了一个适配的模型,然后我们将开始简化这个模型。当我们处理接续数据的时候,基线已经确定了。
超出这个范围,我就不知道了。有可能我们会到达一个平稳期,也有可能我们会开始创造出一些新的东西来应对新的任务。我想这个故事的中心思想在于:“有大量数据的地方,以及可以使用深度学习模型的地方,成功极有可能发生。这就是为什么人们感到深度学习发展速度之快的原因了。”
深度学习真的变成“我们怎样获取正确的数据”这个问题了。这才是真正的大挑战。
Q:从结构上来说,深度学习在一个强大的以GPU为基础的系统上运行。有没有可能将深度学习算法移植到一个更小的系统,来减少百度服务器的运转负荷呢?
Awni Hannun:这正是我在思考的问题。事实上,我觉得在这方面未来是光明的。确实,深度学习模型正在变得越来越大,但是模型的大小以及表达性在训练过程中比在测试过程中更重要。
有很多事例可以证明以下这点:如果一个在32比特环境下训练的模型,放到8比特的环境进行测试,运行效果一样好(或者说差不多一样好)。也就是说,大小可以缩小四倍,但运行起来同样好。
同样,我们在压缩已有的模型方面也做出了很多努力。例如我们如何用一个已经吸收大量数据的巨型模型来训练一个稍小一些的模型?而那个小模型可以嵌入到其他设备中。
通常,困难的部分在于训练系统。在这些例子中,系统确实需要很大,而且服务器要稳固。但是我认为,现在有很多努力都可以将模型变得更小,而且未来有可能将其嵌入其他设备。
Q:搜索引擎必须背靠云服务,除非你可以把整个网络装载手机上,对吗?
Awni Hannun:当然。这极具挑战。
另外……
如果想要知道Deep Speech有多强大,以及百度为什么这么强调深度学习带来的系统架构,你可以看看百度的系统研发科学家Bryan Catanzaro的解释:
“正如其他深度神经网络系统,我们的系统在接受越来越大的数据库训练后,变得越来越准确。中文拥有太多方言和地方口音,所以(百度)的研究员努力寻找大的数据库,让系统可以从中学习所有关于中文口语的细微差异。当我们集结所有这些数据库之后,这种不断扩展的训练带来了新的系统问题。
“为了给系统提供一些语境,我们完整的数据库给Deep Speech进行一次训练需要千亿亿次运算。每当评估一个新的网络或新的数据会否改善Deep Speech,我们需要等待这个训练过程的完成,这要好长一段时间。而相应的,我们越快训练Deep Speech,我们就能评估得越多,整个系统也就进步得越快。
“这就是我们为什么要特别关注训练时发现的系统问题。当我们改善训练系统的效率时,准确性的提高非常明显。我们将系统训练平行分置与多个GPU上,用来减少训练的时间。在8个GPU上训练一个模型时,我们的系统可以包含25兆运算,因此训练Deep Speech的时间可以缩减到几天。我们正在继续突破系统扩展性的边界,因为数据库越拓展,准确率也就会不断提高。”
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。