




2016-03-31 12:03

扫码打开虎嗅APP


本文分三段刊载于作者微信公众号“字典序列”及头条号“词典序列”。
Target很早就开始通过线下超市的结算系统,记录会员的消费情况,比如你在某一天走进一家Target,买了一听可乐,当你扫码结账的时候,这些消费数据都会被记录进你的会员数据库中。从中,Target可以挖掘出一些营销机会。
于是2003年的时候就出了这么一件事。一天,有一个中年男子走进明尼苏达州的一家Target超市,要求见店长。在店长的办公室里,这个男人拿出一叠优惠券,告诉店长,这些都是Target通过电子邮件发给他上高中的女儿的。这些优惠券几乎全部是关于婴儿用品的:婴儿床、婴儿玩具、婴儿服装、护理用品等。在这位男子看来,Target给一位高中生投递这样的促销信息,是极不尊重的。
店长也不得不同意他的看法,于是他请这位男子先回家,并承诺会给他一个答复。在做了几天的调查之后,他确信是Target的电子营销部门犯下了错误,并打电话给这位男子向他道歉。

他没想到的是,这位男子却先向他道歉了,他说回到家后他向家人了解了情况,才知道自己的女儿确实已经怀孕了,预产期就在3个月以后。
为什么一家超市能比这个少女的父亲更早知道她已经怀孕了呢?
答案就在Target的数据库里。根据数据挖掘的结果,Target发现,女性经常在预产期前3-5月的时间点开始,消费这四种商品:无味的润肤露和肥皂、大包装的棉球、包括钙镁锌在内的孕妇营养品。所以,如果系统发现某位女性消费者开始在Target购买这几件特定的商品,就会向她发送关于婴儿用品的促销信息。

尽管让这位女性的父亲产生了些许不快,但是毫无疑问,这样精准的信息推荐,对于当事人本人是非常有用的。如果某个家庭将在3个月内迎来一位新的成员,而家中没有任何她可能用到的东西,你无疑会感到焦虑和无助。这时,一封恰到好处的邮件,能给你带来很大的帮助。
不幸的是,大多数超市并没有那么发达的数据库和数据挖掘技术,因此,多年以来我们所熟悉的超市宣传物料看上去是这个样子的:

收到这样一份把上百条促销信息塞在一张纸上的宣传品,你的第一反应是什么?我的第一反应是扔掉。你几乎可以肯定其中有一两件商品是你需要的,但是你不知道它们在哪里。在这样一份琳琅满目的单页里找出这些有用的信息,然后省上个五毛一块钱,绝对是一件得不偿失的事。
难道超市的营销团队不知道这样的信息对消费者来说没有用吗?他们当然知道。但是,如果想要实现Target那样高精准度的信息推荐方式,至少要解决两个技术问题:
能够知道每个受众所需要信息是什么;
能够为每个受众定制他所需要的信息。
然而在一个没有消费者全量数据的商业机构里,第一点是无解的。在传统企业里,人们也会做消费者调查,但全都是小样本量的抽样调查。以超市这个行业为例,访问员可能会随机地在超市附近寻找消费者,对他们进行不具名的问卷调查,然后得到一些类似这样的结论:
50%的人每周到访超市一次;
35%的人每次到访超市的消费额度在100元以内;
80%的人会购买快速消费品;
0.5%的消费者是孕妇。
根据这样的信息,经营者能够对“该对消费者说什么”这件事有一个简单的判断(例如,宣传单上应该有80%的篇幅是关于快速消费品的),但是想要做到精准的信息推荐和信息生产,是绝无可能的。我们知道200个人里有一个是孕妇,但是不知道她是谁,这样的信息又有什么用呢?难道随机地在200份宣传单中夹上一份关于婴儿用品的宣传品吗?
因此,对于超市来说,最为经济的信息传播模式就是:把消费者“最有可能”感兴趣的信息堆在一起,一股脑地塞给用户,然后让用户自己完成信息的过滤和筛选,选择性地接受其中与自己需求匹配的信息。
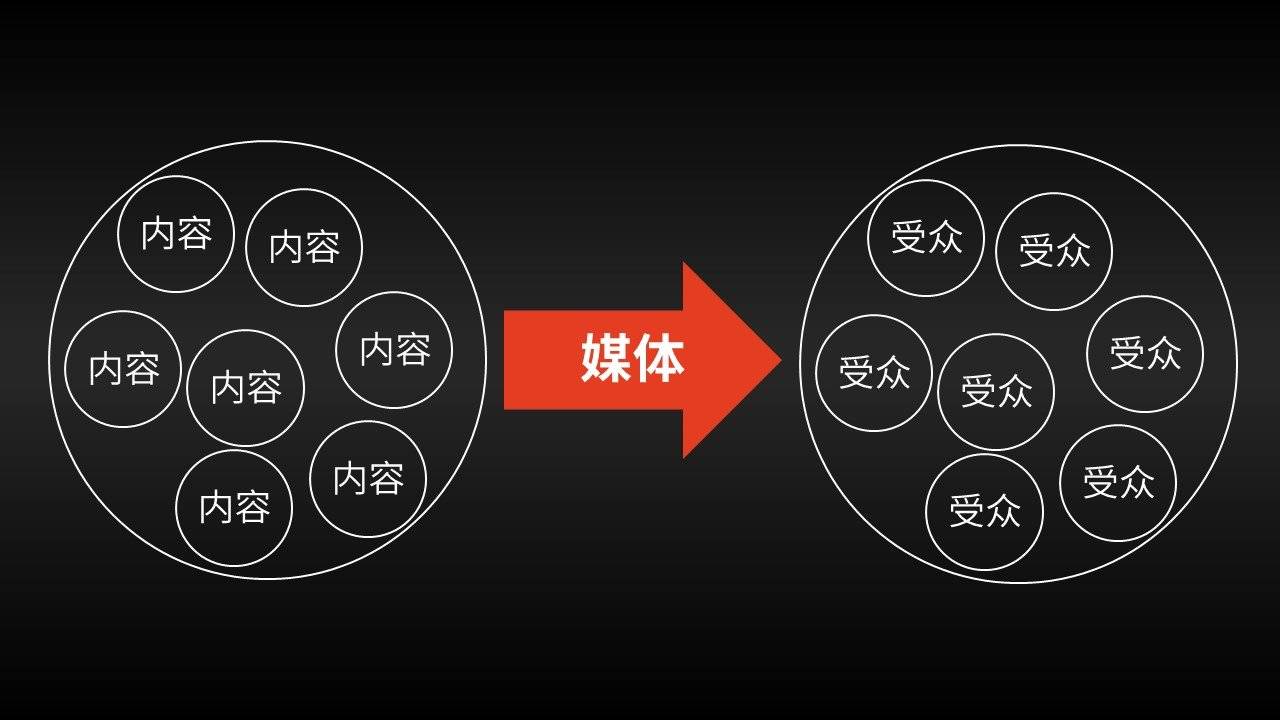
而这种传播模式,其实也是过去数百年间媒体行业的主流模式。
这是前几天某都市报的两个版面:

其实,这就是超市宣传单的一种翻版:把受众最有可能感兴趣的信息打包放在一起批发给用户,让用户自己完成信息的筛选和匹配工作。
我在一家知名平面媒体工作过。时不时地,我们也会尝试对媒体提供的信息与用户的需求之间做重新的适配工作,这个工作在媒体一般被称为“改版”。我们会通过以下方法获取“改版”所需要的信息:
读者抽查;
对过往媒体内容的读者的历史反馈;
同行评价;
资深编辑记者的品味、经验。
“改版”主要会包括以下一些改变:
读者最有可能感兴趣的内容,给予靠前的版面顺序和更大的版面规格;
读者有较小可能感兴趣的内容,给予靠后的版面顺序和比较小的版面规格;
有极少部分读者会感兴趣的内容,可能会从版面上放弃。
不过,无论如何改造,一切还是以“打包”的方式进行的。因为媒体行业面临的问题和超市行业并无本质不同:我们无法精准而完整地知道每个用户想要什么。
当然,在传统媒体时代,我们还面对着另一个问题:信息生产的成本问题。即使我们能够知道每个用户的需求,要在物理世界中为他们定制信息(印刷)以及分发信息(线下发行),会产生任何一个媒体机构都无力承担的巨大的成本。
不过,这一点在互联网兴起之后很快便不是一个问题。互联网让信息的发布和留存成为了一件极低成本的事情。但是,在很长时间内,前一个问题仍然没有好的解决方案。所以,我们在很长时间里,看到的网络媒体是这样的:
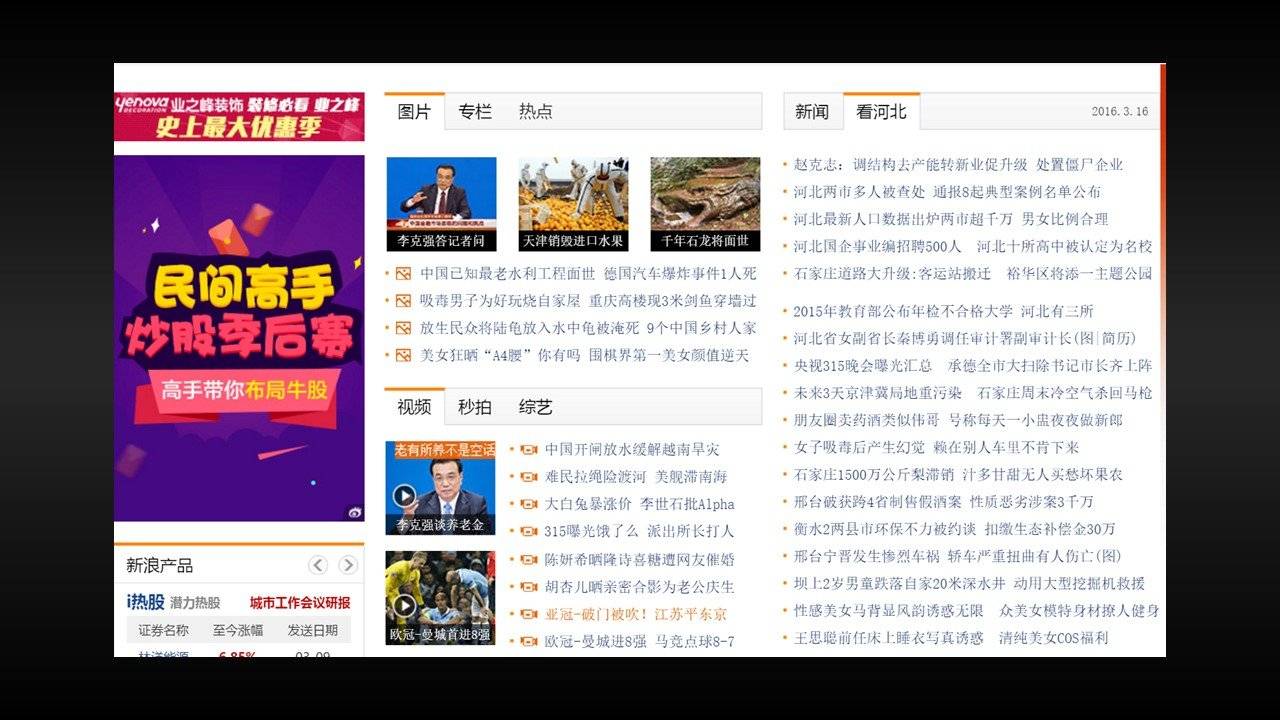
以“门户”模式为代表的媒体形态,存放和发布信息已经几乎不再受到物理成本的约束。因此,一个显著的改变就是,媒体所容纳的信息越来越多。上面这个截图里出现的信息,可能已经达到以前一份报纸的信息容量的上限。而这仅仅是一个网站的局部。
选择变多了,筛选成本也更高了,根本上说,这种模式和传统媒体并没有什么区别。所以,在媒体网络化的早期,人们经常谈论的一个担忧就是:“信息爆炸”。
再回顾一下传统媒体时代(包括门户网站等早期网络媒体形态),信息的分发模式:
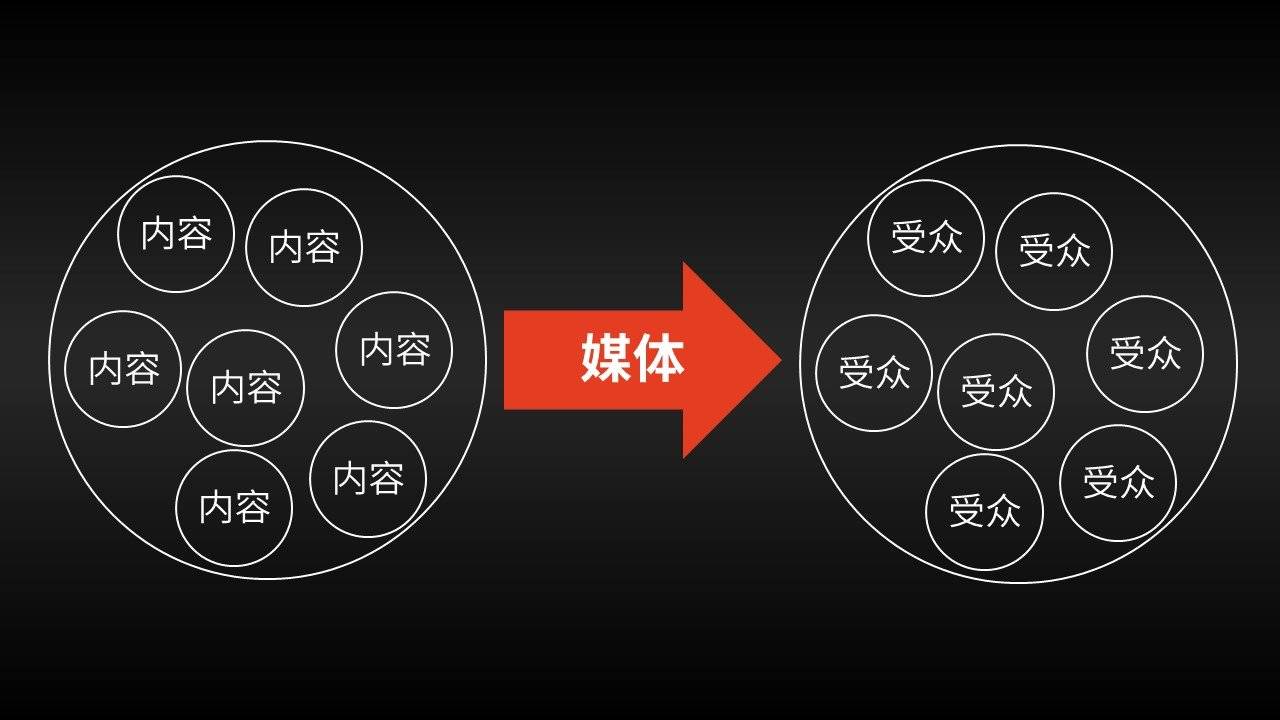
为什么无论是网站,还是报纸,都会用和超市推销商品一样的方式向受众贩卖信息呢?因为他们思考的方式和超市并无不同。
不是因为他们不愿意,而是因为他们做不到。
如果今天晚上你想在家里招待客人,需要购买一瓶葡萄酒,你会选择去以下哪个商店采购?
A:精品便利店,有3种进口自波尔多的红酒,以及2种进口自澳大利亚的新世界红酒;
B:大型进口酒类超市,有300多种来自世界多个不同产区、品种各异的红酒,其中也包括上面说到的5种酒。
如果不考虑地理位置、采购预算等具体因素,你会选择去哪里,可能完全决定于你是什么样的人。如果你是一个对葡萄酒一无所知或者刚刚入门的消费者,你会选择A;如果你是一个专业的品酒者,你很可能会选择B。
就最终的消费选择而言,一个人不可能从A商店里挑出比B商店更适合自己的酒。但是为什么大多数人都会倾向于A呢?因为筛选信息是有成本的。品酒专家会选择B商店,不仅是因为他们对酒的品质更加挑剔,也是因为他们能迅速地筛选信息,做出最优的消费决策。
人们常常说自己面临着“选择困难症”,他们真正的意思是:选择的代价太高了。著名的科技作者Clay Shirky(《众包时代》、《未来是湿的》、《认知盈余》等书作者)曾针对“信息爆炸”这一现象做出一个极有洞察力的论断:“这不是信息过载,而是过滤失败。”
进入到互联网时代以后,发布和存放信息的物理成本持续降低,刺激着信息生产的不断增长。于是降低信息的“筛选成本”就成了媒体行业的重要命题。
现在再来设想一下,如果你只有B商店一个选项,而你非得从中挑出一件符合你需求的酒,你该怎么办?如果是我,我会叫上一位懂酒的朋友和我一起挑选。这就是通过“社交关系”向用户推荐信息的模式:“社交媒体”的基本模式。
Twitter大概算是最早的一个成熟的社交平台产品,随后兴起的facebook、Instagram、微博、微信朋友圈等等,已经彻底改变了人类获取信息的方法和习惯。
社交媒体分发信息的模式有两个最核心的优势:
每个用户都参与信息的分发,如果你有1亿个用户,你就有1亿个编辑去分析、筛选和分发信息;
用户分发的信息总是先达到和自己有直接社交关系的其他用户,“关注”关系的双方要么是物理世界中的朋友、同事,要么是在网络世界中的兴趣相投者。因此,一方对信息的筛选,有很大的可能符合另一方对信息的需求。
总而言之,社交媒体不仅显著扩大了人类处理信息的劳动力总量,而且提升了单个信息节点接受信息时的匹配质量。对于“过滤失败”这一挑战来说,可谓是一个属于人类的里程碑式的胜利。
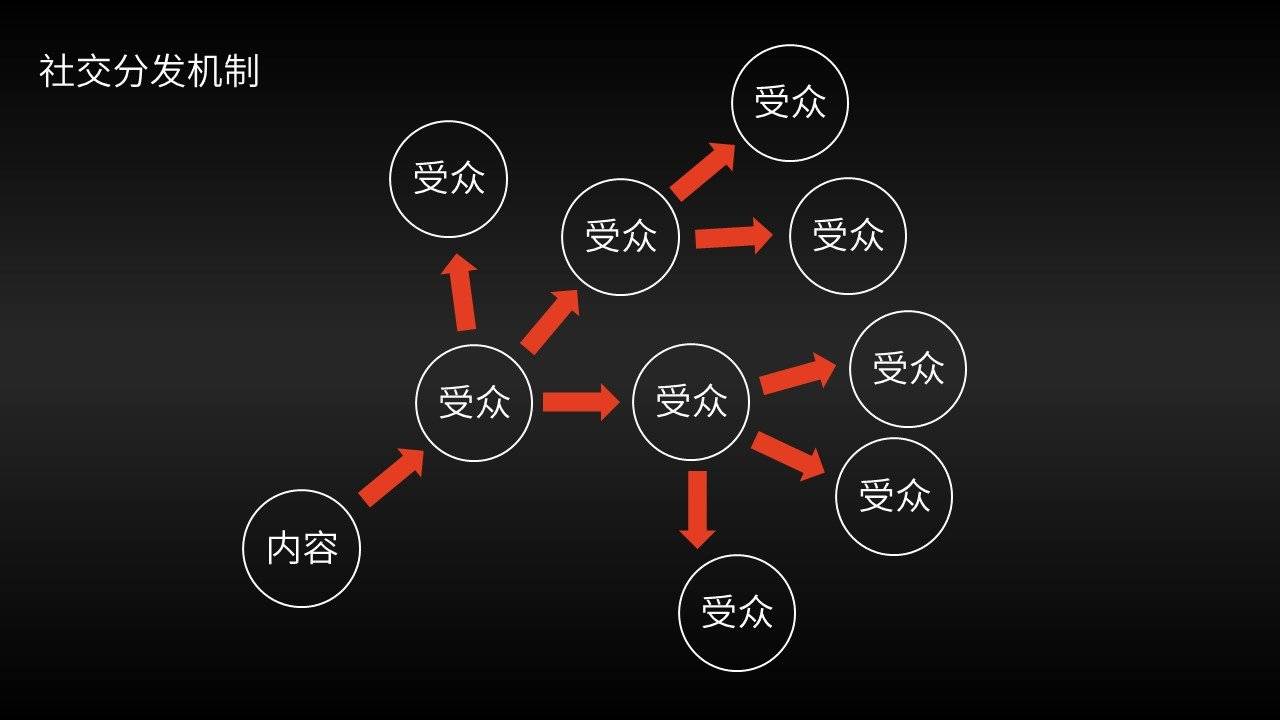
那么,参与社交媒体的用户们得到了什么呢?
通过关注另一位用户,你得到了更多的符合自己需求的信息(各取所需);
通过转发和分享,你可以施展自己的所长,并维系自己的社交关系(各尽所能)。
各取所需、各尽所能,一个看上去很完美的解决方案,但它真的完美吗?很遗憾,就像人类历史上其他一些试图根本性解决人类问题的社会化实验一样,这个“完美”的信息分发模式也存在着缺陷。

在传统媒体,某个版面编辑经常对接的内容生产者(记者、撰稿人等)一般在25-50个之间。然而,如今如果统计某个人在各种社交平台上的社交关系,那么有极大的可能性,你会得到一个远远超过30的数字。
直观地说,就是每个人的“微博”和“朋友圈”都“看不过来”了,而这种“看不过来”又会直接影响我们向其他人分发信息的质量和精确性,形成了恶性循环。
如果你同时找30个葡萄酒专家给你意见,而他们每个人又要同时给30个客户提供意见的话,那么信息过滤又会重新成为一个问题。

Clay Shirky另一个非常著名的论断是他谈论“众包”时提出的:“互联网是爱的大本营。”可惜的是,互联网同时也是“自利”的大本营。
社交分发模式允许人们以“众包”的方式筛选和分发信息,但是这并不等于每一个社交节点的分发权力是平等的。如果一个人(KOL、网红、公共知识分子……)掌握了比其他人更大的信息流量分配权,那么他就会受到激励去生产或者发布那些对“他自己”而非“他的关注者”有价值的信息,例如广告、软文、片面的观点等等能让发布者本人从中获利的信息。
想像一下,当你走进葡萄酒商店的时候,一位受聘于厂家或者商家的“品酒专家”向你推荐了几款葡萄酒——这些酒更可能是符合你的需求,还是符合厂家、商家的利益?
以上两个缺陷,会导致“社交分发”这个貌似完美的社会实验发生“退化”:越来越多的人越来越不负责任地生产、过滤和分发信息,从而人为地、重新制造了“过滤失败”。这种“退化”最典型的例子就是“微博”:“大V”们轻轻点击转发按钮就可以赚取巨大利益,而绝大多数用户只能被迫接受他们分发的低质信息。
那么微信呢?尽管抱怨“朋友圈”水化、“公众号”看不过来的声音已经不少见,但目前看来,它的“退化”并不像微博那么迅速和彻底。因为微信一直在通过各种手段抑制这种“退化”:
个人用户的关注列表被限制在5000个以内;
没有节点数量限制的“订阅号”,被折叠进“订阅号”抽屉中,并且每天只能推送1次信息;
没有节点数量限制也没有被折叠的“服务号”,被限制为每月只能发送4次信息。
然而,这不是“解决方案”,而是“权宜之计”。它以牺牲信息总数量和丰富性为代价,缓解了“过滤失败”现象的出现速度和严重程度。
有没有一种更加完美的解决方案呢?有没有一家应有尽有的葡萄酒商店,不会被品酒专家和混在其中的酒托们挤得水泄不通,而又能让任何一个想要买酒的人高效精准地找到适合自己需要的那瓶酒呢?
如何在不询问本人(以及她的家人、朋友)的前提下,知道一位女子已经怀孕了?Target超市通过消费者数据库解答了这个问题。
根据消费者在超市的购物时记录下的数据,他们发现:如果一个消费者在某个时间点转变了消费习惯,开始购买:无味润肤露、无味肥皂、大包装的棉球、包括钙镁锌等微量元素的保健品。
那么,她有极大的可能在3-5个月后,开始持续采购婴儿用品——换句话说,她是个孕妇。当Target在消费者数据库中发现一位符合这些“特征”的用户时,他们就会向她发送一封包含婴儿用品促销信息的邮件,实现一次信息与受众的精准匹配。
要实现这样一次信息的匹配,你需要:
包含商品“特征”的数据库;
包含消费者身份(姓名、性别、电子邮箱……)“特征”的数据库;
包含消费者购物记录“特征”的数据库。
除此之外,你还得有一套方法,能从种种数据“特征”中推测出一位消费者可能的需求——这就是“算法”。
实际上,算法很早便被应用于“信息过滤”的领域。例如,人类已经非常习惯用Google这样的“搜索引擎”从网络上过滤出符合自己需求的信息:输入关键词、点击“搜索”按钮、计算机自动把搜索结果罗列出来。而在这个“自动”的过程中,就包含了大量的数据和运算过程。
首先,Google的爬虫程序要按照一种“遍历算法”把互联网上每一个网页到下载到Google的服务器中。
然后,机器会统计网页上出现关键词的频率,为每个相关网页计算出它与搜索关键词的相关度。
再然后,仅仅知道网页与关键词的相关度还不够,人们还希望得到在相关网页中最有价值的那些。简单来说,Google用一种叫做“Page Rank”的算法解决了这个问题。
最后,Google会剔除掉无关的网页,根据相关度和“Pgae Rank”为搜索排序,提供给搜索者。这种过滤和获取信息的模式,可以说是一种“智能媒体”的早期形式。
但是,搜索引擎还是一种“半自动”的信息分发机制,人需要归纳、整理自己对信息的需求,将其提炼为机器能够识别的“关键词”,并对机器发出指令,机器根据人的指令完成剩下的工作。这个过程,是人和机器配合完成的。
有没有可能把人的那部分工作也交给机器完成呢?现在也许还言之过早,但是已经出现了很多成功的实验,如“今日头条”提出的“推荐引擎”。要完成一次信息与用户需求的匹配,“智能媒体”在对信息进行过滤之前,首先要推测出人类可能的信息需求。对于这个问题,今日头条的解决方案是:让用户对自己收到的信息进行持续的“投票”。这些投票的方式可能是:点击/不点击、阅读时间、终止阅读、顶/踩、分享、搜索、屏蔽、投诉……
这些用户使用过程中留下的大量的数据“痕迹”,就成为了“推荐引擎”推算用户需求的依据。而这个原理,和Target通过用户消费行为推测其潜在需求的方法非常相似。
从“搜索引擎”到“推荐引擎”,意味着计算机在信息过滤和匹配方面的作用更加主动,在一定的范围内,人类可以“坐享其成”了。
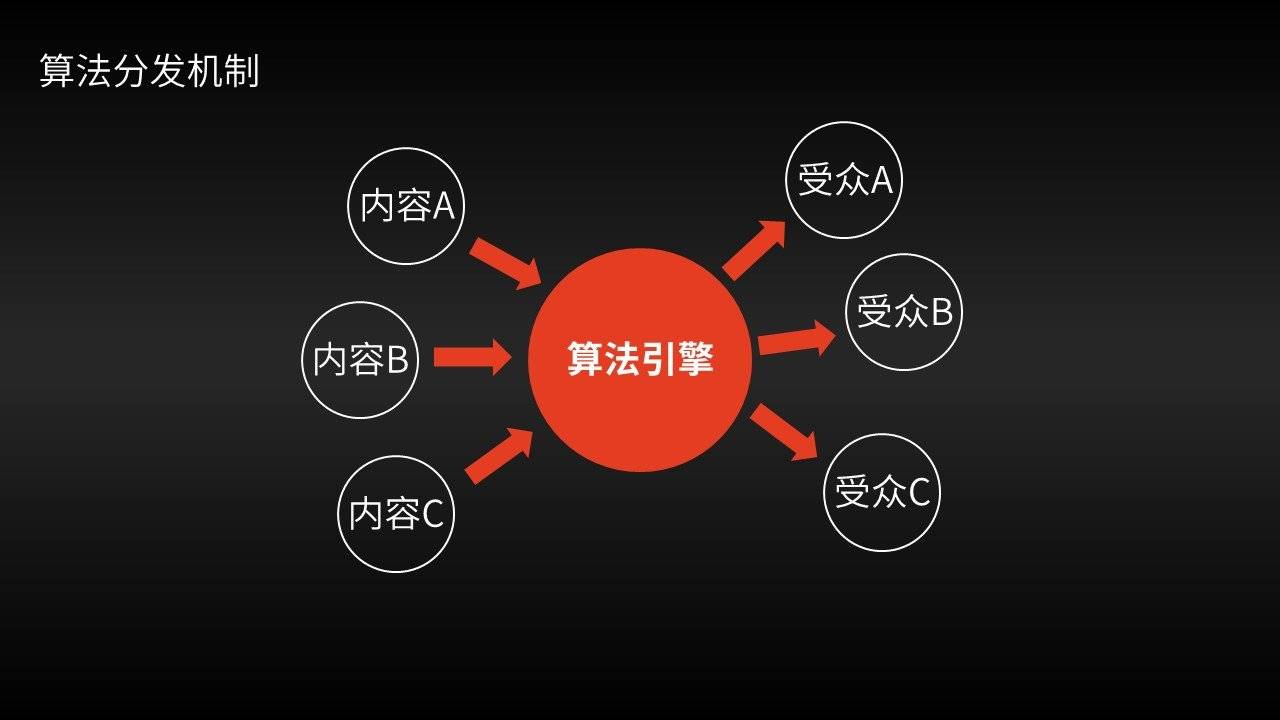
“智能媒体”模式的优势在于,允许用户与符合其需求的信息实现直接匹配,而不需要通过;
媒体精英的过滤和推荐(传统媒体);
社交关系的过滤和推荐(社交媒体)。
社交媒体的出现,优化了“信息过滤”的两个问题:
通过“众包”,显著扩大了社会处理信息过滤的劳动力总量;
基于线下关系或者相似需求的“关注”关系,使分发方提供的信息,更有可能符合接收方的需求。
然而——在理论上说——智能媒体可以在这两件事上都做得比社交媒体更好。
首先,人类处理和过滤信息的效率是有上限的,而至少目前看来,人类对计算机处理效率的开发还远远没有接近上限。
第二,社交关系两端的信息匹配是一种模糊、间接、多对多的匹配,而基于用户数据的匹配则是一种直接、精准、一对一的匹配。
除此之外,智能媒体还有一项明显的优势,那就是,计算机没有自利动机,不会滥用分发信息的权力。但是,“智能媒体”是否完美无缺呢?至少现在看来还很难这么说。
尽管智能媒体的兴起已经引起了全球范围内的关注和模仿,但是目前,计算机还很难洞察人类信息和信息需求的深度和复杂度。曾经有某个头条号发布了一篇关于“毛鸡蛋”的文章,其实并不是在谈论这种食物本身,而是表达一种带有猎奇心态的青年亚文化。对于一个知道“毛鸡蛋”是什么的中国人来说,这一点并不难理解。但是计算机却把这篇文章分类为“美食”——如果你告诉计算机,一篇写满了某种食物的文章其实和“食物”本身并没有多少关系,至少在当下,她是很难理解的。
所以,在今天我们所处的阶段,出现了一种相对保守但更接近人类习惯的媒体形态:“社交媒体”和“智能媒体”的交叉形态。“微博”在2014年底开始实施的“信息流优化计划”,就是一种用“智能媒体”技术对“社交媒体”进行改造的实验。
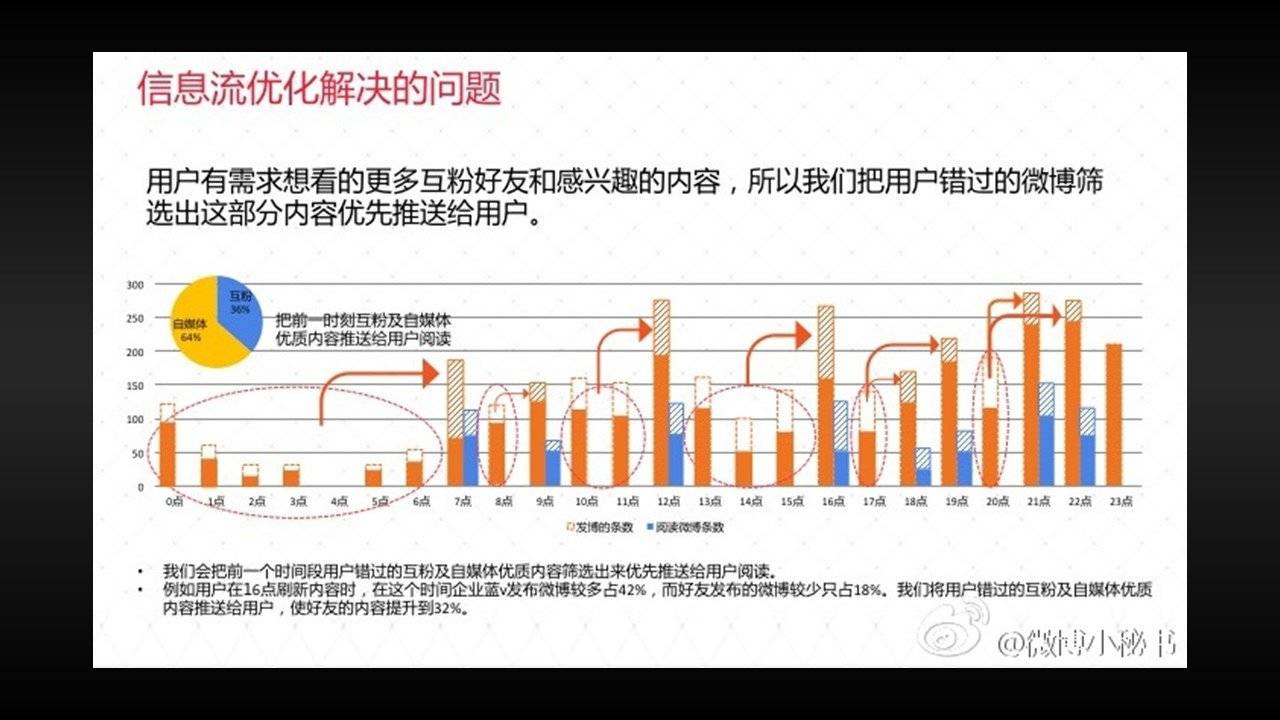
通过这种改造,微博把用户信息流的排序从最原始的“时间排序”变成了“智能排序”,把用户更有可能需求的信息提前、插入;而把“大V”们出于自利动机分发的无效信息从用户的时间线上后置甚至移除。
这种改造在最初——就像大多数人类的新发明一样——遭到了用户的普遍抵触。但是从微博收集的实际数据来看,这却是一次成功的改造:实施1年以后,微博的人均阅读量上涨了30%,转发、点赞等互动行为增加了52%,信息流中的营销信息则减少了62%。
在目前这个历史阶段,把“社交媒体”中人类的优势与“智能媒体”的效率与公平性结合起来,也许提供了一种更平滑的过渡方式。

那么,在未来呢?AlphaGo对李世石的胜利已经证明,在逻辑思考的效率上计算机已经更胜一筹。但是在感情、趣味、创造力等等更加复杂的方面,计算机也能代替人吗?
其实这种可能性是很大的。计算机也许永远不可能知道“爱情”是什么样一种感觉,但是,如果它注意到一个人开始增加在服装、发型上面的花费,开始频繁增加和某位异性/同性的在线社交,她的心跳血压开始经常出现某种异动,她开始不断推迟回到家里的时间……“智能媒体”大概就能在周五下班前,在某间氛围浪漫的餐厅里,为她提前订好两个人的座位。
“智能”也许永远不能像真正的人类那样思考,但是如果有足够多的数据、足够快的运算力、足够优秀的算法,“智能”的确能够思考。
就像艾伦·图灵所说的:“如果人们能够接受思考方式的彼此不同,为什么不能接受机器的思考方式和我们不同?”

