




2023-05-16 14:59

扫码打开虎嗅APP


本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas、好困,原文标题:《重磅内幕:OpenAI即将开源新模型!开源社区的繁荣,全靠大厂“施舍”?》,题图来自:视觉中国
就在刚刚,根据The Information的最新爆料,OpenAI即将发布一款全新的开源大语言模型。
虽然目前还不清楚,OpenAI是不是打算利用即将开源的模型,来抢占Vicuna或其他开源模型的市场份额。但几乎可以肯定的是,新模型的能力大概率无法与GPT-4甚至GPT-3.5相竞争。
毕竟,270亿美元的估值也决定了,OpenAI最先进的模型将会被用于商业目的,尽管前两个版本的GPT都是开源的。
对此,OpenAI的发言人没有回应置评请求。

羊驼家族开源大爆发
十天前,谷歌的一份内部文件泄漏。在这篇名为《我们没有护城河,OpenAI也没有》的文章里,作者沉痛控诉了开源对于谷歌和OpenAI的沉重打击。
的确,在这次军备竞赛中,谷歌和OpenAI似乎都不是赢家,因为开源社区正在吃掉属于它们的“利益”。
ChatGPT一出,引爆了全球的LLM革命。然而,OpenAI不Open,很多公司和开发者只能看着干着急。
此时,Meta站出来发布了LLaMA,为全世界开发者谋了一把福利。
本来呢,Meta承诺的是LLaMA会对非商用的研究用例开源,可是谁能想到,仅在发布一周后,LLaMA的权重忽然在4chan上泄漏了,瞬间就引发了数千次下载。
这场“史诗级泄漏”,直接让开源LLM领域变了天。短短几周内,各种ChatGPT平替就以迅雷不及掩耳之势呈爆炸式增长。
Alpaca、Vicuna、Koala、ChatLLaMA 、FreedomGPT、ColossalChat……简直堪称是“羊驼家族”大爆炸。
其实,早在羊驼之前,开源模型就曾破灭过OpenAI的野心。
当时,刚刚发布的Dall-E 2凭借着惊艳的文生图效果,在网上引起了不小的轰动。
然而,当OpenAI还在试图兜售API时,一款开源替代突然横空出世——Stable Diffusion。
随着Stable Diffusion的迅速崛起,Dall-E 2也很快就被开发者们抛在了脑后。
开源大模型,要颠覆硅谷大厂?
UC Berkeley的计算机教授Ion Stoica正是使用Meta的研究开发Vicuna的学者之一。
为了提高Vicuna的能力,Stoica和同事们正在努力增加模型中的计算数量,这将有助于处理涉及推理的任务,比如写代码。
开发Vicuna的是一个伯克利的团队,每年的预算为数百万美元,其中大约50万美元来自包括微软、谷歌和亚马逊在内的上市公司。
UC Berkeley的计算机教授Ion Stoica表示,现在的免费AI模型,在性能上已经“相当接近”谷歌和OpenAI的专有模型了,毫无疑问,大多数开发者最终都会选择免费模型。
一方面,开源模型可以让开发者使用自己的数据来解决特定的问题。
另一方面,像Vicuna这种模型的训练成本甚至可以低至几百美元,而且还不用向大厂支付昂贵的使用费。
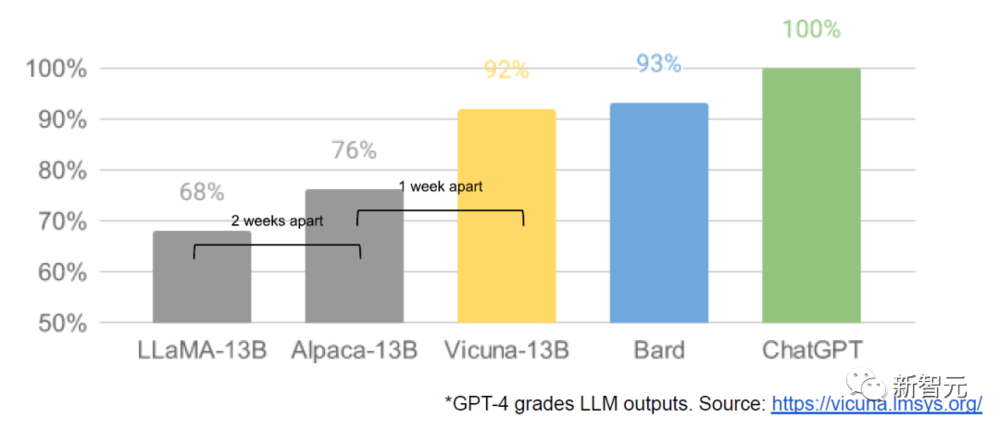
如果Stoica的看法正确,开源AI必将颠覆谷歌、OpenAI、微软等出售专有模型使用权的大厂的商业计划。
Vicuna的质量和开源AI的寒武纪大爆发,让谷歌工程师Luke Sernau警告同事,谷歌在努力追赶OpenAI时,太过关注专有软件了。
如果免费、高质量的平替没有使用限制,谁会去付费使用带有条条框框的谷歌产品呢?开源AI的发展正在超越我们,谷歌应该在开源社区中建立自己的领导地位,并放弃对我们模型的部分控制。
这份备忘录迅速在整个行业内引起了共鸣——即使Sernau或许高估了开源AI的能力,低估了它们的成本和风险,但大多数从业者都同意,Meta非常有可能从中获益。
比如,Meta在内部会使用AI模型进行内容推荐和广告定位,当开发者改进Meta的模型时,Meta就可以把这些改进纳入自己内部的AI。
Meta CEO小扎对此筹谋已久。
4月,在他与分析师的一次电话会议中,他曾这样谈到公司的策略——
如果行业能够在我们使用的基础工具上达成标准化,那么我们就能从其他人的改进中受益,这样会更好。
谷歌倒是没有完全采用专有的方式来处理AI软件。
早在2020年,谷歌就发布了一个开源语言模型T5,让开发者可以构建能执行翻译和摘要任务的软件。随后,谷歌又发布了一个更先进的Flan-T5。
但是,根据Stoica和其他从业者的说法,Meta发布的软件能够在谷歌模型的基础上做出显著改进,这让开发者选择Meta模型的可能性大大增加了。
不过,Stoica表示,谷歌在开源软件方面仍有两个优势。
1. 如果谷歌利用其不向外部开放的用户数据,模型在某些专业领域(如内容推荐)的表现可能会更好。
不过,谷歌发言人表示,公司并没有在现有用户数据上训练其基础模型。
2. 搜索公司在管理大规模计算机基础设施方面的专长,意味着它能够以更低的成本来运行模型,包括为云客户提供服务。
与此同时,OpenAI在收集数百万人与ChatGPT互动方式的数据上,已经抢得了先机,这会更有助于OpenAI改进AI软件,更不用提它和微软的合作协议。
开源的繁荣,是大厂的“施舍”?
不过,这种建立在开源基础上的繁荣,是不稳定的。
目前大多数的开源,仍然依赖于资金雄厚的大公司发布的巨型模型。如果OpenAI和Meta决定关闭业务,繁荣的开源社区,可能就会变得萧条。

比如,现在许多开源平替是基于Meta的LLaMA构建的。
而其他模型使用的是名为Pile的大型公共数据集,由开源非营利组织EleutherAI整理。
EleutherAI之所以存在,是因为OpenAI的开放性意味着一群开发者能够逆向了解GPT-3是如何制作的,然后在空闲时间里创建自己的模型。
但一切都可能改变。
OpenAI已经不再Open,Meta也在考虑限制开源,防止初创公司利用开源代码做坏事。
Meta AI的执行董事Joelle Pineau表示,现在向外部人员开放代码是正确的,但他并不确定,在未来五年内Meta还会采用相同的策略。
如果这种Close的趋势继续下去,那么不仅开源社区会被抛弃,下一代的AI突破也会重新回到那些最大、最不差钱的AI实验室手中。
显然,AI大模型的制造和使用方式的未来,正处于一个十字路口。
如果OpenAI曾经吝啬,就不会有如今的开源盛况
其他人也在权衡,这种开源的自由竞争带来的回报更大,还是风险更大。
就在Meta AI发布LLaMA的同时,Hugging Face推出了一个门禁机制,下载平台上的模型之前,用户必须申请访问并获得批准,这是为了限制那些没有合法理由的人。
“我并不是一个开源的布道者”,Hugging Face的首席伦理科学家Margaret Mitchell说。“我能看到不开源的意义。”
大模型广泛使用的一个弊端,就是可能造成AI色情产品的泛滥。
Mitchell曾在谷歌工作,并创立了AI道德团队,她对于模型被滥用的风险十分了解。因此,她赞成Meta AI以有控制的方式发布模型。
同时,OpenAI也在关闭水龙头。GPT-4发布时,并没有公布架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等细节,理由是“鉴于像GPT-4这样的大规模模型的竞争格局和安全影响”。
这种限制反应了OpenAI心态上的变化。联合创始人兼首席科学家Ilya Sutskever表示,OpenAI过去的开放性是一个错误。
OpenAI的政策研究员Sandhini Agarwal说:“以前,如果某样东西是开源的,也许一小群修理工会关心。但现在,整个环境已经改变。开源真的可以加速发展,导致竞争。”
时间倒回三年前,如果OpenAI在公布GPT-3的细节时,就秉持着同样的原则,那就不会有EleutherAI的出现,也就不会有蓬勃的开源创新。
今天,EleutherAI在开源生态系统中发挥着举足轻重的作用。Pile被用来训练多个开源项目,包括Stability AI的StableLM。
但随着GPT-4、5、6被锁死,开源社区可能会再次被落在几家大公司后面。
他们会困在上一代模型中,如果想取得进步,只能闭门造车。
参考资料
https://www.technologyreview.com/2023/05/12/1072950/open-source-ai-google-openai-eleuther-meta/
https://www.theinformation.com/articles/open-source-ai-is-gaining-on-google-and-chatgpt
本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas、好困

