2016-12-07 10:14

我为如此深奥的主题而感到歉意,但观看它们真的很有趣。本位来自:大数据文摘,选文 | 吴佳乐 翻译|黄念 校对|冯琛 姚佳灵,作者 |Mike Bostock 素材来源 | bost.ocks.org

独立心灵的力量被高估了……真正的力量源自于外部能提高认知能力的帮助。
——唐纳德
本文重点研究算法。然而,这里讨论的技术适用于更广泛的问题空间:数学公式、动态系统、过程等。基本上,任何需要理解代码的地方。
那么,为什么要可视化算法呢?甚至为什么要去可视化呢?这篇文章将告诉你,如何利用视觉去思考。
算法是可视化中一种迷人的用例。要将一种算法可视化,我们不只是将数据拟合到图表中,况且也没有主要的数据集。相反的是有描述行为的逻辑规则。这可能是算法可视化如此不寻常的原因,因为设计师可以尝试这种新奇的形式来更好地沟通。这就是来研究它们的充分的理由。
但是,算法也提醒人们——可视化不仅仅只是一种在数据中寻找模式的工具。可视化利用人类的视觉系统,以增加人类的智慧。这样,我们就可以用它来更好地了解这些重要的抽象过程以及其他事情。
采样
在解释第一个算法之前,我首先需要解释它要解决的问题。

梵高的《星夜》
光(电磁辐射),从这个屏幕上发出的光,穿过空气,由你的晶状体聚焦,并投射到视网膜上,这是一个连续的信号。要被感知,我们必须通过测量其在空间中的不同点的强度和频率分布把光信号降低到离散脉冲。
这种还原过程被称为采样,它对视觉至关重要。你可以把它理解为——一个画家应用不同的颜色,采用离散的笔触形成图像(特别是点画或点彩派)。采样其实是计算机图形学的核心关注点,例如,为了通过光线追踪来栅格化3D场景,我们必须确定在何处拍摄光线。甚至调整图像大小也需要采样。
采样会因为各种因素的矛盾性而变得困难。一方面要保证采样点要均匀分布,不要有间隙,另一方面要避免重复采样或有规律地采样(否则会产生混叠)。这就是为什么你不应该在照相时穿细条纹衬衫:条纹与相机传感器中的像素网格产生共振,从而造成莫尔条纹(Moiré patterns)。

图片来源:retinalmicroscopy.com
这是一张人类视网膜周边的显微照片。较大的锥形细胞检测颜色,而较小的杆细胞改善低光视觉。
人类的视网膜有一个出色的解决方案,在其感光细胞的位置取样。细胞密集和均匀地覆盖着视网膜(除了视神经上方的盲点),然而细胞的相对位置是不规则的。这被称为泊松盘分布,因为它保持了细胞之间的最小距离,避免遮挡而浪费光感受器。
但是构造一个泊松盘分布是困难的,因此有一个简单的叫做 Mitchel的近似算法,它是最佳候选算法。

从这些点可以看出,最佳候选采样产生了让人愉快的随机分布。这不是没有缺陷:在一些地区有太多的样本(过采样),而在其他地区是不够的(欠采样)。但它相当好,同样重要的是容易实施。
以下是它的工作原理:
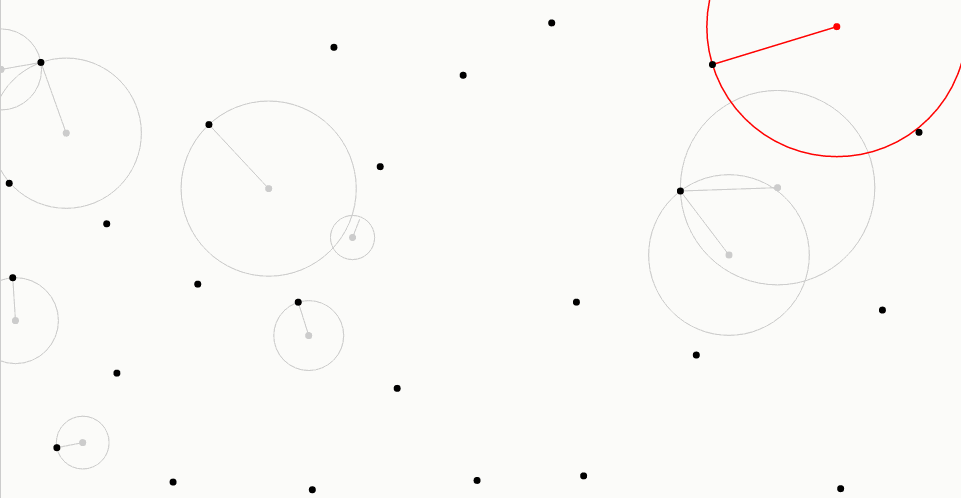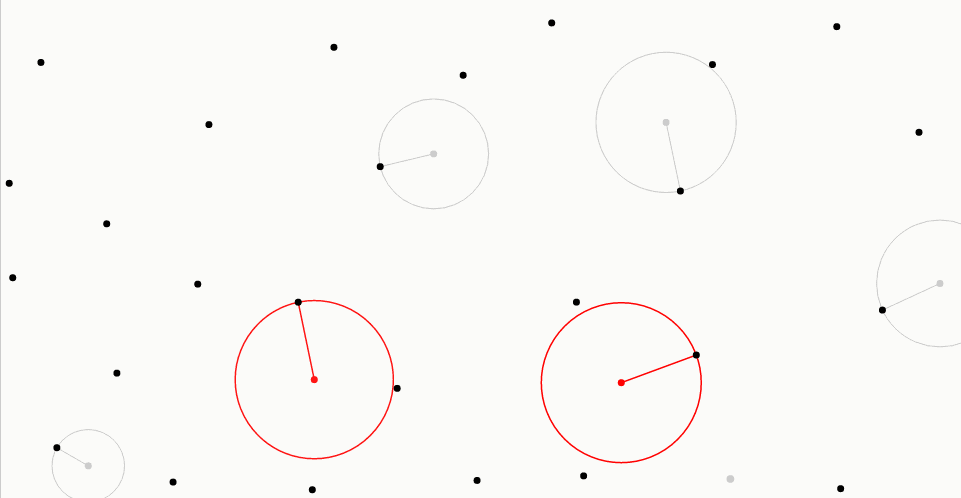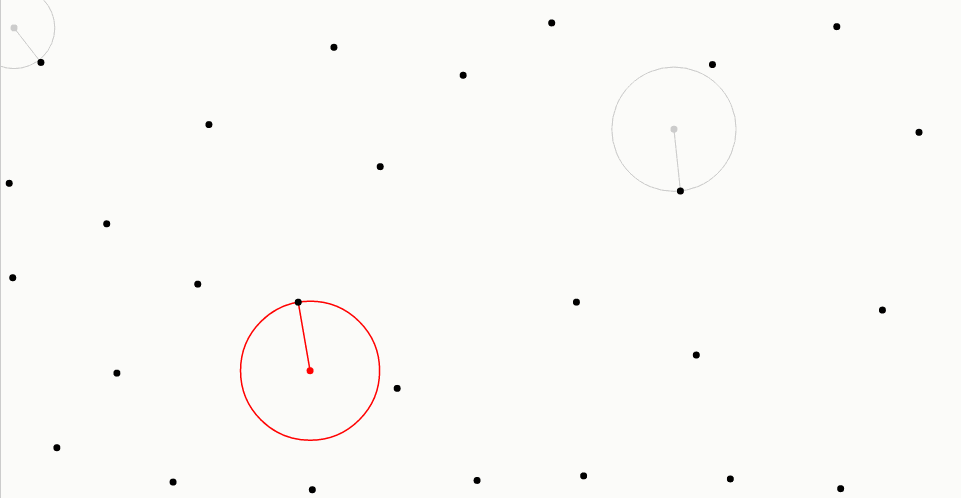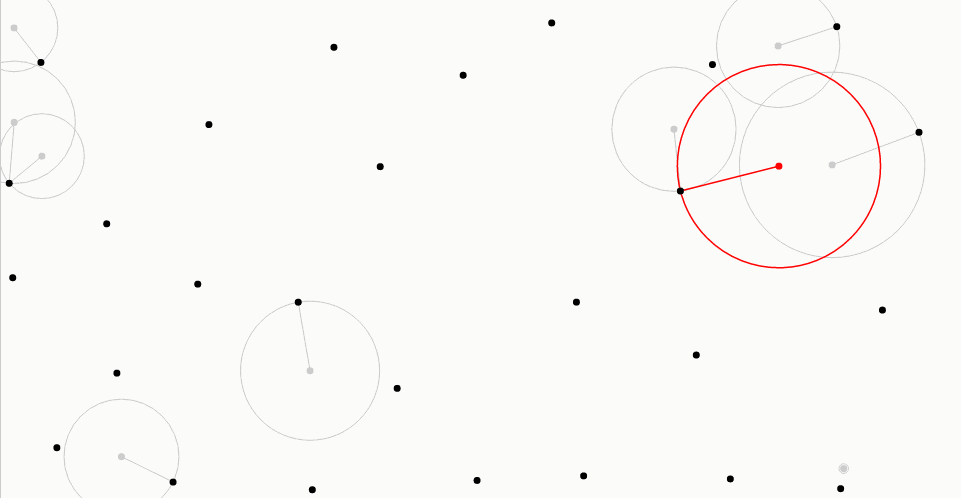
对于每个新样本,最佳候选算法生成固定数量的候选采样点,用灰色表示(在这里,这个数为10)。从采样区域均匀地选择每个候选采样点。
最佳候选者,以红色显示,是离所有先前样本(以黑色显示)最远的一个。从每个候选采样点到最接近的样本的距离由相关联的线和圆圈表示:注意在灰色或红色圆圈内部没有其他样本。在创建所有候选采样点并测量距离之后,最佳候选采样点成为新样本,并且丢弃剩余候选采样点。
▼代码如下所示:
function sample() {
varbestCandidate, bestDistance = 0;
for(var i = 0; i < numCandidates; ++i) {
var c = [Math.random() * width, Math.random() * height],
d = distance(findClosest(samples, c), c);
if (d > bestDistance) {
bestDistance = d;
bestCandidate = c;
}
}
return bestCandidate;
}
正如我解释了上面的算法,我会让代码独立出来(另外,这篇文章的目的是让你通过可视化学习代码)。但我会明确一些细节:
其中numCandidates表示一次生成的候选采样点个数。这个参数让你以质量换取速度。numCandidates越小,算法运行速度越快。相反,numCandidates越大,算法运行速度越慢,但是采样质量越高。
▼distance函数是简单几何:
function distance(a, b) {
vardx = a[0] - b[0],
dy = a[1] - b[1];
return Math.sqrt(dx * dx + dy * dy);
}
如果你想的话,在这里可以忽略开平方(sqrt),因为它是一个单调函数,并且,它不改变最佳候选采样点的结果。
findClosest函数返回距离当前候选采样点最近的采样点。我们可以使用暴力搜索来实现,即对每一个现有的采样点进行迭代。或者,可以让搜索加速,如利用四叉树搜索算法。暴力搜索实现简单,但非常慢(时间复杂度太高)。而加速方式要快得多,但需要做更多的工作来实现。
谈到权衡——在决定是否使用一个算法,我们不是凭空评估它,而是将其与其他方法进行比较。作为一个实际问题,权衡实施的复杂性:需要多久来实现、维护难度,对于衡量它的性能和质量是十分有用的。
▼最简单的替代方法是均匀随机采样:
function sample() {
return [random() * width, random() * height];
}
它看起来是这样的:

统一随机是相当糟糕的。存在严重的欠采样和过采样:许多样本点拥挤在一起,甚至重叠,导致大的空区域(当每次采样的候选采样点的数量被设置为1时,均匀随机采样也代表最佳候选算法的质量的下限)。
除了通过采样点的分布规律来鉴别采样质量,我们还可以尝试通过根据最接近的样本的颜色对图像着色来在不同的采样策略下模拟视觉。这实际上是采样点的Voronoi图,其中每个单元由相关样品着色。
通过6667个均匀随机采样后的《星夜》看起来是怎样的?

这种方法的弊端也很明显。采样点分布不均导致每个单位在尺寸大小上变化很大,和预期的不均匀采样点分布一样。细节丢失严重是因为密集采样点(小单元)没有充分利用起来。同时,稀疏采样点(大单元)通过夸大稀有色彩(例如左下角的粉红色)引入了噪音。
现在来看看最佳候选采样:

好多了!虽然仍然随机放置,但单元的大小更一致。尽管样品的数量(6667)保持不变,但由于它们均匀分布,保留了更多的细节和引入了更少的噪声。如果你眯着眼睛,几乎可以弄清楚原来的笔触。
我们可以使用Voronoi图来更直观地研究样本分布,通过根据其面积给每个单元上色。较暗的单元较大,表示稀疏采样; 较浅的单元较小,表明密集采样。最佳图案具有几乎均匀的颜色,同时保持不规则的采样位置(显示单元面积分布的直方图也是很好的,但是Voronoi具有同时显示采样位置的优点)。
这是同样的6667个采样点的不均匀随机采样:

黑点是采样点之间的大空隙,可能是由于欠采样导致的视觉局部缺陷。相同数量的最佳候选样品在单元面积中表现出小得多的变化,并且因此着色更一致:

我们能做得比最佳候选算法更好吗?是的! 我们不仅可以用不同的算法产生更好的样本分布,而且这种算法更快(线性时间)。它至少像最佳候选算法一样容易实现。这种算法甚至可以扩展到任意维度。
这个奇迹叫做Bridson的泊松盘采样算法,它看起来像这样:

该算法的功能明显不同于其他两个——它充分利用现有采样点逐步生成新的采样点,而不是在整个采样区域随机生成新的采样点。这使其进展具有准生物学外观,如在培养皿中分裂的细胞。注意,也没有采样点彼此太接近;这是定义由算法实施的泊松盘分布的最小距离约束。
这就是它的工作原理:

红点表示“活跃”采样点。在每次迭代中,从所有活跃采样点的集合中随机选择一个。然后,在围绕所选采样点的环内随机生成一些数量的候选采样点(用空心黑点表示)。环从半径r延伸到2r,其中r是样本之间的最小允许距离。
来自现有采样点的距离r内的候选采样点被拒绝;这个“禁止区”以灰色显示,用黑线连接将被拒绝的候选采样点和附近的现有采样点。网格加速每个候选采样点的距离检查。网格尺寸r /√2确保每个单元可以包含至多一个采样点,并且仅需要检查固定数量的相邻单元。
如果候选采样点是可以接受的,它被添加作为一个新的采样点,然后随机选择一个新的活跃采样点。如果没有一个候选采样点是可以接受的,所选择的活跃采样点被标记为无效(颜色从红色变为黑色)。当没有采样点保持活跃时,该算法终止。
面积用着色表示的Voronoi图显示了泊松盘采样算法相对于最佳候选算法的改进,没有深蓝色或浅黄色细胞:

泊松盘采样下的《星夜》最大地保留了细节和引入了最少的噪音。它让人想起美丽的罗马马赛克:

现在,你已经看到了一些例子,让我们简要地思考一下为什么要把算法可视化。
娱乐
我发现可视化的算法有无穷的魅力,甚至令人着迷。特别是在涉及随机性时。虽然这看似是一个牵强的理由,但不要低估了快乐的价值!此外,尽管这些可视化甚至在不理解基础算法的情况下也可以参与,但是掌握算法的重要性可以给出更深的理解。
教学
你发现代码或动画更有帮助吗?伪代码( 不能编译的代码的委婉语)怎么样? 虽然形式描述在明确的文档中有它的位置,可视化可以使直观的理解更容易。
调试
你有没有实现基于形式描述的算法? 可能很难! 能够看到你的代码在做什么可以提高生产力。 可视化不能取代测试需求,但测试主要用于检测故障而不是解释它。即使输出看起来正确,可视化还可以在实现过程中发现意外的表现(参看Bret Victor的《可学习的编程》和为了优秀的相关工作的《发明原理》)。
学习
即使你只是想为自己学习,可视化会是一个很好的方式来得到深刻的理解。教学是最有效的学习方法之一,实现可视化就像教自己。我发现看到它,而不是熟记小而容易忘记细节的代码,更容易直观地记住一个算法。
洗牌
洗牌是随机重新排列一组元素的过程。例如,你可以在打牌之前洗牌。一个好的洗牌算法是无偏的,其中每个排序都有相同的可能性。
Fisher-Yates shuffle是一个最佳的洗牌算法。 它不仅是无偏的,而且在线性时间内运行,使用恒定的空间,并且易于实现。
▼代码如下:
function shuffle(array) {
varn = array.length, t, i;
while (n) {
i= Math.random() * n-- | 0; // 0 ≤ i < n
t= array[n];
array[n] = array[i];
array[i] = t;
}
return array;
}
以上是代码,下面是一个可视化的解释:

每一条线代表一个数字,数字小向左倾斜,数字大就向右倾斜。
请注意,你可以对一组任何东西进行洗牌,不只是数字,但这种可视化编码对于显示元素的顺序很管用。它的灵感来自于Robert Sedgwick的《用C语言实现的算法》中的排序可视化。
该算法把数组划分为两个部分,右半边是已洗牌区域(用黑色表示),左半边是待洗牌区域(用灰色表示)。每一步从左边的待洗牌区域随机选择一个元素并将其移动到右侧,已洗牌区域元素数量扩大了1个。左半边的初始顺序不必保留,这样给已洗牌区域的新元素提供了空间,该算法可以简单地讲元素交换到位。最终所有的元素都被洗牌,算法终止。
如果Fisher–Yates是一个很好的算法,那么一个不好的算法是什么样的?
▼这是一个:
//不要这么做!
function shuffle(array) {
return array.sort(function(a, b) {
return Math.random() - .5; // ಠ_ಠ
});
}
这种方法利用排序通过指定随机比较器函数来洗牌。比较器定义元素的顺序。它使用参数a和b (要比较的数组中的两个元素),如果a小于b,则返回小于零的值,如果a大于b,则返回大于零的值,如果a和b相等,则返回0。比较器在排序期间重复调用。
如果不给array.sort指定一个比较器,元素按照字典序列排序。
在这里,比较器返回一个在-0.5和+0.5之间的随机数。假设这定义了一个随机顺序,那么排序会随机地混杂元素并实施好的洗牌。
不幸的是,这个假设是有缺陷的。随机成对顺序(对于任何两个元素)不会为一组元素建立随机顺序。比较器必须遵守传递性:如果a> b和b> c,则a> c。但随机比较器返回一个随机值,违反了传递性,并导致array.sort的行为是未定义的!可能你会有运气,也可能没有。
它怎么不好呢?我们可以通过可视化输出来试着回答这个问题:
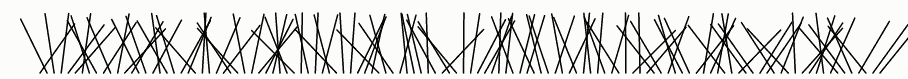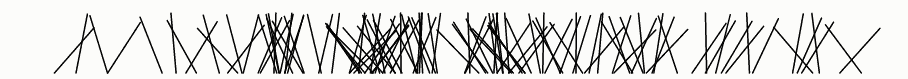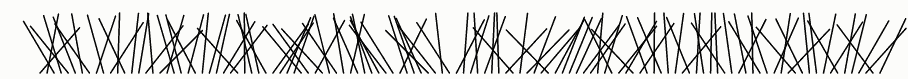
该算法不好的另一个原因是排序需要O(n lg n)时间,使得它显著地慢于只需要O(n)时间的Fisher-Yates算法。但是速度缺陷比偏差缺陷小。
这可能看起来是随机的,因此你可能会得出结论,随机比较器洗牌足够好了,并不再关注偏差,看作是迂腐的。但看起来可能会误导!有许多对人眼来说看起来是随机的,但实际上是非随机的。
这种欺骗表明可视化不是一个魔术棒。算法的单次运行显示不能有效地评估其随机性的质量。我们必须仔细设计一个可视化来解决手头的具体问题:算法的偏差是什么?
为了显示偏差,我们必须首先定义它。一个定义是基于在洗牌之后索引i处的数组元素将在洗牌之后处于索引j的概率。如果算法是无偏的,则每个元素在洗牌结束后出现在每个索引处的概率相等,因此所有i和j的概率相同:1 / n,其中n是元素的数量。
分析计算这些概率是困难的,因为它取决于知道使用的确切排序算法。但是根据经验计算是很容易的:我们简单地洗牌数千次,并计数索引j处元素i的出现次数。该概率矩阵的有效显示是矩阵图:
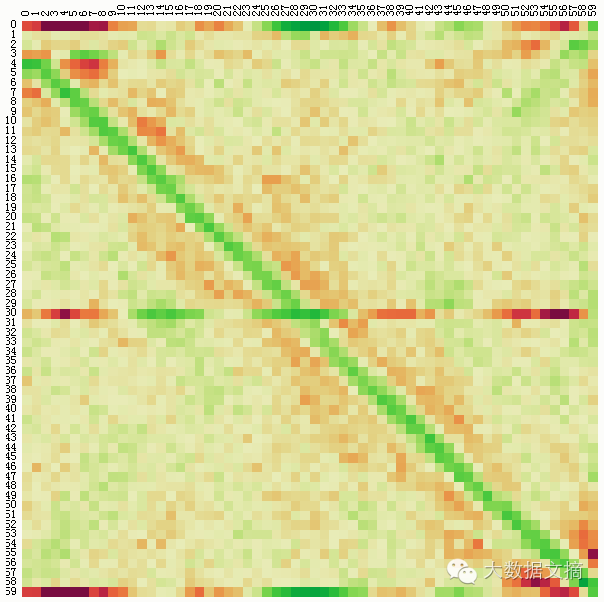
矩阵的列(水平位置)表示在洗牌之前的元素的索引,而行(垂直位置)表示洗牌之后的元素的索引。概率用颜色编码:绿色单元表示正偏差,其中元素出现地比我们对无偏差算法的预期更频繁;同样红色单元表示负偏差,其发生频率低于预期。
如上所示,Chrome中的随机比较器洗牌结果是令人惊讶的是平庸。部分阵列仅弱偏置。然而,它在对角线下方表现出强的正偏置,这表示将元素从索引i推到i + 1或i + 2的趋势。第一行、中间行和最后一行也有奇怪的行为,这可能是Chrome使用“三中值”的快速排序的结果。
无偏的Fisher–Yates算法看上去是这样的:

除了由于经验测量的少量噪声之外,在该矩阵中没有可见的规律。(如果需要,可以通过进行额外的测量来降低噪声。)
随机比较器洗牌的行为在很大程度上取决于浏览器。不同的浏览器使用不同的排序算法,并且不同的排序算法与(破坏了的)随机比较器表现非常不同。这里是随机比较器在Firefox上洗牌的结果:
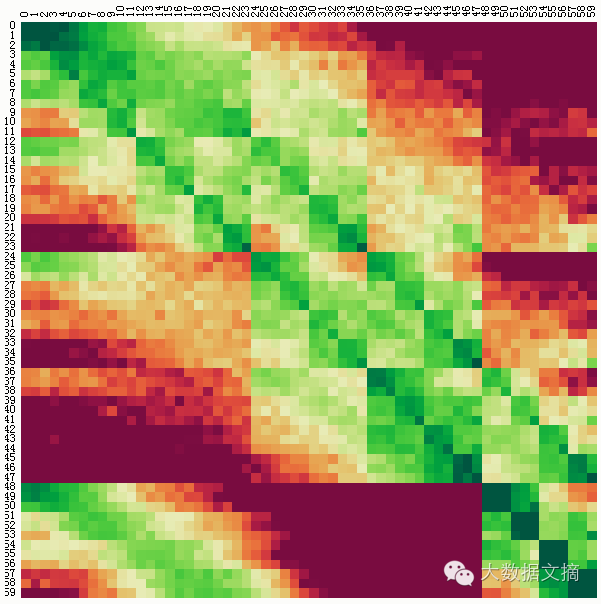
这是非常失偏的!所得到的数组通常几乎没有洗过牌,如该矩阵中的强绿色对角线所示。这并不意味着Chrome的排序是比Firefox的“更好”,它只是意味着不应该使用随机比较器洗牌。随机比较器从根本上被破坏了。
排序
排序是洗牌的逆过程——它从无序创建顺序,反之亦然。这使得排序成为更困难的问题,要为不同的权衡和约束设计各种解决方案。
最知名的排序算法之一是快速排序。

Quicksort首先通过选择一个基准将数组分成两个部分。 左半部包含所有小于基准的元素,而右半部包含大于基准的所有元素。在数组分区后,快速排序在左右两部分内递归。当每个部分只包含一个元素时,递归停止。
分区操作使得只在数组的活动部分上进行单一操作。类似于Fisher-Yates通过交换元素递增地建立洗牌区,分区操作递增地构建子阵列的较小(左)和较大(右)部分。当每个元素被访问时,如果它小于基准,它被交换到较小部分; 如果它大于基准,则分区操作移动到下一个元素。
▼代码如下所示:
function quicksort(array, left, right) {
if(left < right - 1) {
var pivot = left + right >> 1;
pivot = partition(array, left, right, pivot);
quicksort(array, left, pivot);
quicksort(array, pivot + 1, right);
}
}
function partition(array, left, right,pivot) {
varpivotValue = array[pivot];
swap(array, pivot, --right);
for(var i = left; i < right; ++i) {
if (array[i] < pivotValue) {
swap(array, i, left++);
}
}
swap(array, left, right);
return left;
}
快速排序有很多版本。上面显示的是最简单也是速度最慢的一个。这种变化对于教学是有用的,但是在实践中,为了得到更好的性能应用了更复杂的实现方法。
常见的改进是“三中值”枢轴选择,其中第一,中间和最后元素的中值被用作基准。这倾向于选择更接近真实中值的基准,导致类似大小的左半部分和右半部分以及递归层数更少。另一个优化是对于数组的小部分来说,从快速排序切换到插入排序,由于函数调用的开销问题这可以更快。
一个特别聪明的变化是Yaroslavskiy的双基准快速排序,它将数组分为三个部分,而不是两个。这是Java和Dart中的默认排序算法。
上面的排序和洗牌动画有不错的属性,那就是时间映射到时间:我们可以简单地观察算法如何进行。但是虽然直观,动画也可以让人在看的时候感到沮丧,特别是如果我们想关注偶然的、奇怪的算法的行为。动画也严重依赖我们的记忆来观察行为模式。虽然通过控制以暂停和擦洗时间来改进动画,但是同时展示一切的静态显示甚至可以更有效。眼睛扫描比手动要快。
将动画转换为静态显示的一种简单方法是从动画中选择关键帧,并按顺序显示,如同漫画一样。如果我们在关键帧之间删除冗余信息,我们会更有效地使用空间。更密集的显示可能需要更多的研究来理解,但是可以更快地扫描,因为眼睛移动较少。
下面,每一行显示递归之前的数组的状态。第一行是数组的初始状态,第二行是第一次分区操作之后的数组,第三行是第一个分区的左右部分再次被分区之后的数组等等。实际上,这是广度优先快速排序,其中左右两侧的分区操作并行进行。

与之前一样,每个分区操作的基准以红色突出显示。请注意,在下一级递归处,基准将变为灰色:分区操作完成后,关联的基准处于其最终的排序位置。显示的总深度是递归的最大深度,给出了快速排序执行如何有效的感觉。它在很大程度上取决于输入和基准选择。
快速排序的另一个静态显示,密度较小但可能更容易读,将每个元素表示为彩色线,并显示每个顺序交换。(这种形式是受到Aldo Cortesi的排序可视化的启发。)更小的值颜色更轻,更大的值颜色更深。

现在已经看到了同一算法的三种不同的视觉展示:动画、稠密静态展示和稀疏静态展示。每种形式都有各自的优缺点。动画看起来有趣,但静态的可视化允许仔细检查,而不用着急。稀疏展示可能更容易理解,但密集展示除了显示细节之外,还显示算法行为的“宏观”视图。
在我们继续下去之前,让我们将快速排序与另一个众所周知的排序算法——归并排序进行对比。
▼下列为归并排序的代码:
function mergesort(array) {
varn = array.length, a0 = array, a1 = new Array(n);
for(var m = 1; m < n; m <<= 1) {
for (var i = 0; i < n; i += m << 1) {
var left = i,
right = Math.min(i + m, n),
end = Math.min(i + (m << 1), n);
merge(a0, a1, left, right, end);
}
i= a0, a0 = a1, a1 = i;
}
if(array === a1) {
for (var i = 0; i < n; ++i) {
array[i] = a0[i];
}
}
}
function merge(a0, a1, left, right, end) {
for(var i0 = left, i1 = right; left < end; ++left) {
if (i0 < right && (i1 >= end || a0[i0] <= a0[i1])) {
a1[left] = a0[i0++];
}else {
a1[left] = a0[i1++];
}
}
}
下面是相关的动画展示:

正如你可能从代码或动画中推测的,归并排序采用了一种与快速排序非常不同的排序方法。快速排序通过执行交换就地运行,与快速排序不同,归并排序需要额外的数组副本。这个额外的空间用于归并排序的子数组,把来自子数组的每对元素组合在一起,同时保持顺序。由于归并排序运行副本而不是交换,因此我们必须相应地修改动画(或有误导读者的风险)。
归并排序自下而上进行。最初,它合并大小为1的子数组,因为它们经过了排序。每个相邻的子数组:首先,只是一对元素,使用额外的数组合并为大小为2的排序子数组。然后,将大小为2的每个相邻排序子数组合并成大小为4的排序子数组。每次遍历整个数组后,归并排序将排序子数组的大小加倍:8,16,等等。最终,这个加倍合并了整个数组,算法终止。
因为归并排序在数组上执行重复遍历而不是像快速排序那样递归,并且因为每次遍历使排序的子数组的大小加倍,而不考虑输入,所以更容易设计成静态展示。我们只需在每次合并后显示数组的状态。

让我们再花一点时间来想想我们所看到的。这里的目标是研究算法的行为而不是特定的数据集。但仍然有数据,这是必然的,因为数据是从算法的执行而导出的。这意味着我们可以使用派生数据的类型来将算法可视化分类。
▼第0级/黑盒
最简单的类,只显示输出。不解释算法的操作,但它仍然可以验证正确性。通过将算法视为黑盒,可以更容易地比较不同算法的输出。黑盒可视化还可以与更深入的输出分析结合,例如上面显示的随机偏移矩阵图。
▼第1级/灰盒
许多算法(虽然不是全部)增量地构建输出。随着它的进程,通过可视化过程中间的输出,开始看到算法是如何工作的。这解释了更多而不必引入新的抽象概念,因为过程中间和最终输出共享相同的结构。然而,这种类型的可视化会产生比它可以回答的更多的问题,因为它没有解释为什么算法做它要做的事。
▼第2级/白盒
为了回答“为什么”这个问题,白盒可视化暴露算法的内部状态以及其中间过程输出。这种类型有最大的潜力来解释,但也对读者是最大的负担,因为内部状态的意义和目的必须清楚地描述。这里有一个风险,额外的复杂性会压垮读者;分层信息可以使图形更容易获得。最后,由于内部状态高度依赖于特定算法,这种类型的可视化通常不适合于比较算法。
还有实现算法可视化的实际问题。通常不能只是运行代码;必须有办法捕获它以便可视化(查看本文的源代码示例)。甚至可能需要与可视化交叉执行,这对于捕获递归算法的堆栈状态尤其具有挑战性。语言解析器如Esprima可以通过代码检测方便地实现算法可视化,将执行代码与可视化代码完全分离。
迷宫的生成
最后一个问题,我们会看下的是迷宫生成。本节中的所有算法生成二维矩形网格的生成树。这意味着没有循环,并且存在从左下角的根到迷宫中的每个其他单元的唯一路径。
我为如此深奥的主题而感到歉意。我不知道为什么这些算法是有用的,除了简单的游戏,可能是关于电气网络。但即使如此,它们从可视化视角看也很迷人,因为它们以非常不同的方式解决了同样的有高度约束的问题。
观看它们真有趣。

随机遍历算法初始化左下角的迷宫的第一个单元。该算法然后跟踪迷宫可以扩展的所有可能的方式(以红色标示)。在每个步骤,随机挑选这些可能的扩展中的一个,只要这不重新连接它与另一个部分的迷宫,该迷宫就会延伸扩展。
像Bridon的泊松盘采样算法一样,随机遍历保持前沿,并从边界中随机选择进行扩展。因此,两种算法似乎都像真菌一样有机地生长。
随机深度优先遍历遵循一个非常不同的模式:

不是每次都选择一个新的随机通道,该算法总是在随机方向上延伸最深的通道,一个最长的回到根的通道。因此,随机深度优先遍历分支,仅当当前路径是个死结时,进入迷宫的较早时的分支。要继续,它会回溯,直到它可以开始一个新的分支。这种蛇状的探索导致迷宫带有明显更少的分支和更长的蜿蜒通道。
Prim的算法构造最小生成树,具有加权边缘的图的生成树具有最低的总权重。 该算法可以用于通过随机初始化边缘权重来构建随机生成树:

在每个步骤中,Prim的算法使用连接到现有迷宫的最低加权边缘(潜在方向)扩展迷宫。如果该边缘将形成环路,则其被丢弃,然后考虑次最低加权边缘。
Prim的算法通常使用堆来实现,这是用于对元素进行优先级排序的有效数据结构。 当一个新的单元格加入迷宫时,连接的边缘(以红色标示)被添加到堆。尽管边以任意顺序添加,堆允许快速除去最低加权边。
最后,这是一个最不寻常的例子:

Wilson的算法使用循环擦除随机游走来生成统一的生成树,是所有可能的生成树的无偏差样本。我们看到的其他迷宫生成算法缺乏这个美丽的数学属性。
该算法用任意起始单元初始化迷宫。然后,新的单元格被加入迷宫,启动随机游走(用红色标示)。继续随机游走,直到它重新连接到现有的迷宫(用白色标示)。然而,如果随机游走本身相交,则在随机游走继续之前擦除所得到的循环。
最初,算法看着可能令人沮丧地慢,因为早期随机游走不可能与小的现有迷宫重新连接。随着迷宫增长,随机游走变得更可能与迷宫碰撞,并且算法加速显著。
这四种迷宫生成算法的工作方式截然不同。然而,当动画结束时,所得到的迷宫彼此件难以区分。动画可用于显示算法如何工作,但无法显示生成的树结构。
一种显示结构,而不是过程的方法是用颜色填充迷宫:

颜色编码树深度——回到在左下角的根的路径的长度。随着越深入树,颜色标度循环;当一个深路径循环回邻近一个浅路径时,这偶尔会误导,但更高的对比度允许更好的局部结构的分化。(这不是一个传统的彩虹色标,名义上被认为有害,但立方体的彩虹具有改善的感知性能的能力。)
我们可以通过减去墙,进一步强调迷宫的结构,减少视觉噪声。下面的图中,每个像素表示通过迷宫的路径。如上所述,路径通过深度着色,随着时间的推移,颜色像潮水一样更深入迷宫。

颜色的同心圆,像领带染色衬衫,揭示随机遍历产生许多分支路径。然而,每条路径的形状不是特别有趣,因为它往往以直线回到根。因为随机遍历通过从边界随机采集来扩展迷宫,路径从来没有被给予很多蜿蜒的自由 - 它们最终与增长的边界碰撞并且由于对循环的限制而终止。
另一方面,随机深度优先遍历都是关于蜿蜒的:

这个动画以之前那个50倍的速度进行。这种加速是必要的,因为由于分支有限,随机深度优先遍历迷宫比随机遍历迷宫深得多。可以看到,在任何特定深度的活动分支通常只有一个,很少有多个。
下面,用随机图演示Prim的算法:

这更有趣!同时扩展的小花的颜色显示基本的分支,并且有比随机遍历更复杂的全局结构。
Wilson的算法尽管操作很不同,却似乎产生了非常相似的结果:

只是因为它们看起来相同并不意味着它们相同。尽管外观上一样,Prim的算法在随机加权图不生成统一的生成树(据我所知,证明这是我的专业领域之外)。可视化有时会由于人为错误而会误导。早期版本的Prim的颜色洪水有一个错误,颜色标度旋转的速度是预期的两倍;这表明Prim和Wilson的算法产生了非常不同的树,而事实上它们看起来相似多于差异。
由于这些迷宫是生成树,也可以使用专门的树来可视化地显示结构。为了说明迷宫和树之间的对偶性,这里由Wilson的算法生成的迷宫的通道(以白色标示)逐渐变换成整洁的树布局。与其他动画一样,它从深度开始,从根开始进一步扩展到叶子:

为了进行比较,我们再来看看随机深度优先遍历产生的拥有长通道和小分枝的树。

两棵树具有相同数量的节点(3239)并且被缩放以适合相同区域(960×500个像素)。这隐藏了一个重要的区别:在这个尺寸上,随机深度优先遍历通常产生比Wilson的算法深两到五倍的树。上面的树的深度分别为315和1338。在用于颜色洪水的更大的480000节点的迷宫中,随机深度优先遍历产生的树深10到20倍!
利用视觉来思考
本文重点研究算法。然而,这里讨论的技术适用于更广泛的问题空间:数学公式、动态系统、过程等。基本上,任何需要理解代码的地方。
那么:
——为什么要可视化算法呢?为什么要可视化一些东西?
——利用人的视觉系统,可以提高理解。或者更简单地说,利用视觉去思考。
来源:https://bost.ocks.org/mike/algorithms/
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。