2023-06-30 16:23


扫码打开虎嗅APP


本文来自微信公众号:海外独角兽(ID:unicornobserver),作者:程天一,原文标题:《拾象硅谷见闻系列:打破围绕开源LLM的6大迷思》,题图来自:视觉中国
最初吸引我对开源语言模型关注的是 Stanford Alpaca,它展示出了一个低成本微调过的指令遵循可以做到不错的问答对话效果,还有端侧运行、私有化部署以及降低调用成本等方面的潜力。在 3 月份 Alpaca 问世后的一个月里(也就是 LLaMA 泄露的一个多月后),这类模型又出来很多,围绕着它们的炒作达到顶峰,所有人期待的 LLM Stable Diffusion 时刻似乎就快要到了。
在团队出发前硅谷的前一天晚上,我在 YouTube 上刷到 OpenAI 元老 John Schulman 在伯克利有关 RLHF 和 Hallucination 的讲座,他一针见血地指出这类开源模型的做法只是“形似”,实际上降低了模型的 Truthfulness。之后的硅谷之旅我集齐了这个生态的不同视角,对开源社区的现状有了更加清醒的认知——尽管 Stability AI 也非常积极地入场了 LLM,但是这里的 Stable Diffusion 时刻可能仍未到来。
这里的卡点有很多:缺少明确的开源扛把子团队/公司、没有被普遍认可的标准化测试、开源团队都缺高质量数据、蒸馏 ChatGPT 进行指令微调的做法有许多局限、Query 和用户反馈数据飞轮难以转起来、多重的不可商用限制……
不过非常鼓舞人心的是开源社区也非常快地意识到了这些问题,Alpaca Farm 试图解决 RLHF 和标准化测试的问题,OpenLLaMA 和 RedPajama INCITE 等项目开始从预训练环节攻克可商用问题,微调的方向也更百花齐放。
不同的角色在此刻对于 LLM 开源社区的前景信心不一,本文试图从我的硅谷见闻出发,提供对 6 个常见迷思的一些思考,希望对整个社区也有所帮助和启发。我自己非常期待在接下来见到智能跟可商用问题都解决得不错的 Base Model、被普遍认可的开源模型标准化测试和更符合 LLM 时代的开源协议出现。
一、开源模型景观概览
本文的重点是对围绕着 LLM 开源模型的一系列迷思的重新思考,但是在开头先给没那么熟悉这个领域的读者一些大的图景。
下面这张图出自 Translink 投资人 Kevin Mu,他从技术复杂度、货币化潜力和瓶颈的存在三方面论证了 LLM 的市场可能由 OpenAI 闭源玩家占据主导。但是就像图中的问号所代表的,目前还胜负未分,离市场份额的终局还比较远。
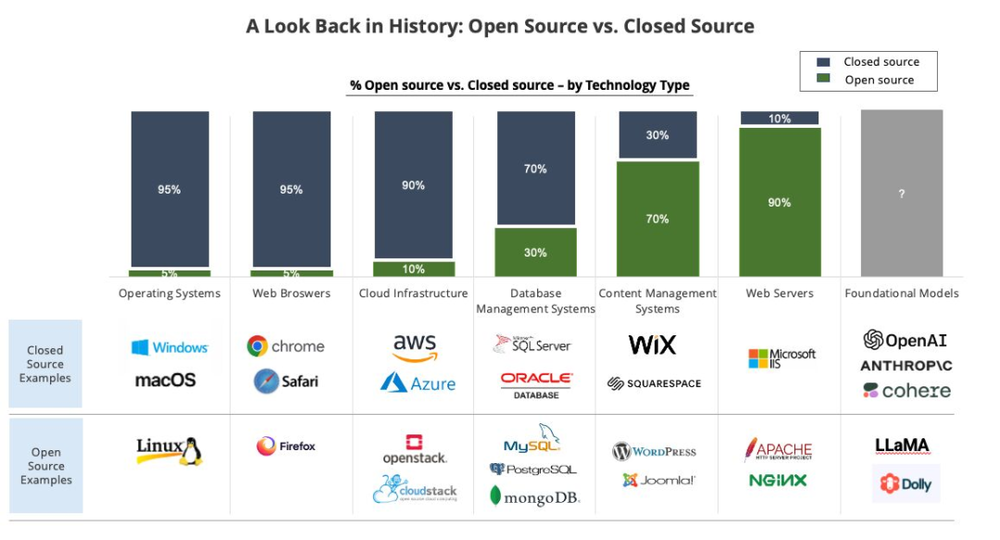
历史上的闭源 vs 开源格局,Source: Kevin Mu 的 Linkedin 动态
抛开投资人 top-down 的终局思维,从 bottom-up 的视角审视现在的 LLM 开源社区,在 LLaMA 出现后,模型相关的项目其实在过去两个季度发展得相当如火如荼:
按照 Decibel.vc 的 GenOS Index 对 GitHub 中星数前 30 的项目统计,40% 的项目都是围绕开源模型的;
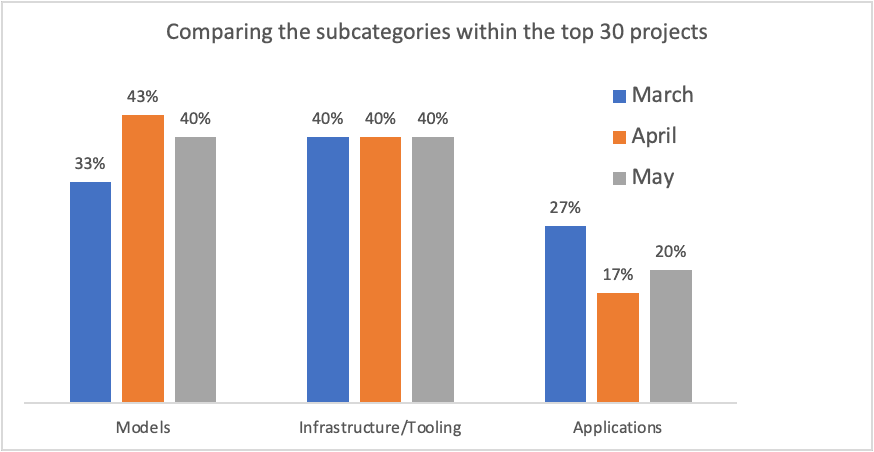
Source: Decibel GenOS Index 五月版
而 GitHub 中星数前 10 名的 LLM 开源项目中,和开源模型相关有第二名的 GPT-4All、服务 serving 环节的 llama.cpp 以及引爆了指令遵循微调的 Stanford Alpaca。
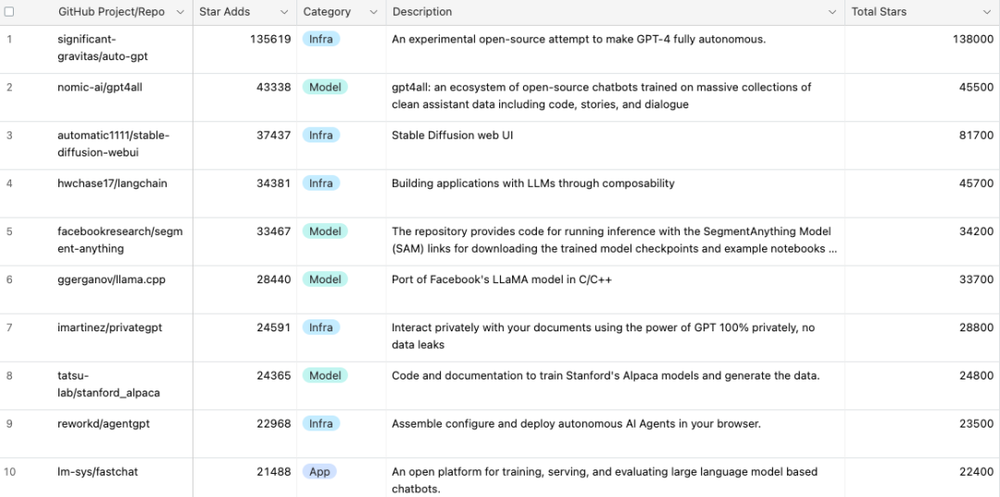
聚焦到具体项目上,在 Base Model 和经过微调的模型两个层次上都有爆款模型接连出现,近期的代表分别是 Falcon 40B 和 WizardLM 13B。
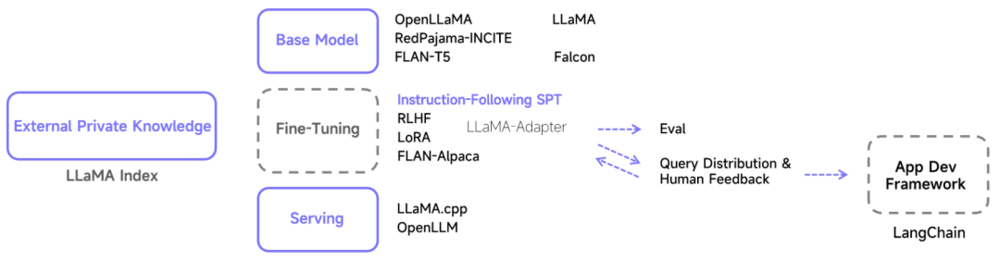
下图列举了理解这个生态的一种简单框架和一些常见的名字,感兴趣的读者当然也可以按照训练方法的不同、原始 Token 或微调指令数据集的不同以及其他标准来进行其他细分的分类。
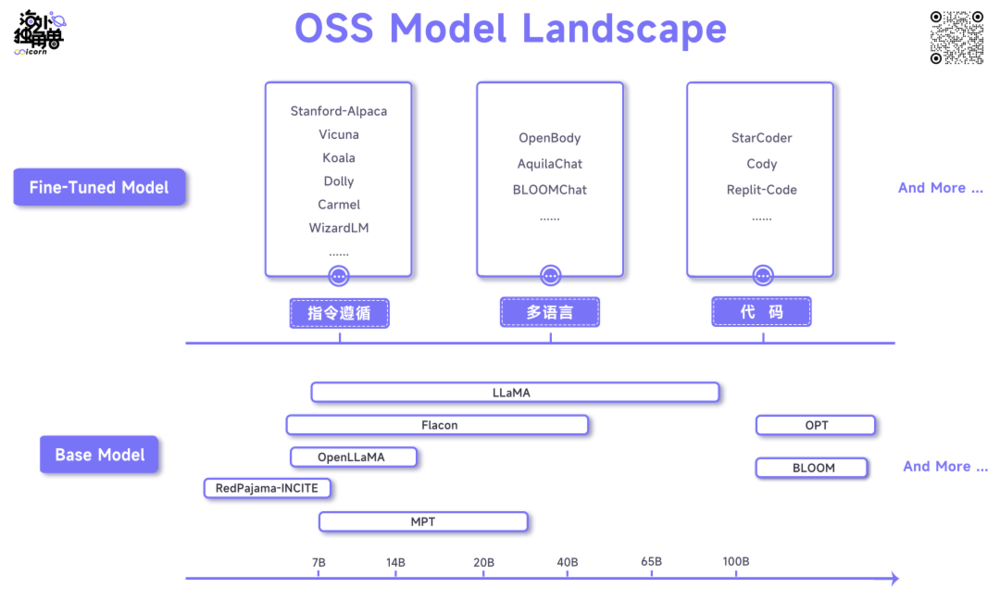
有了这些大背景,我们可以深入到在硅谷之行我对开源 LLM 模型一些重要问题的思考转变。
二、打破六大迷思
迷思1: “We Have No Moat, And Neither Does OpenAI”
“We Have No Moat, And Neither Does OpenAI”是 5 月上旬从 Google 内部泄露的一篇文档,总结了开源模型在 LLaMA 泄露的 2~3 个月里取得的进展,并以此认为模型的训练没有壁垒,并号召内部拥抱开源、LoRA 微调以及小参数量的模型。这并不代表 Google 的官方观点,只是内部一名资深软件工程师的呼吁。由于它发布于我们硅谷之行的途中,我因此有机会了解各种人对它的看法,并发现那些没有紧跟开源模型最新进展的人更倾向于使用这篇文章论证开源模型的巨大前景。
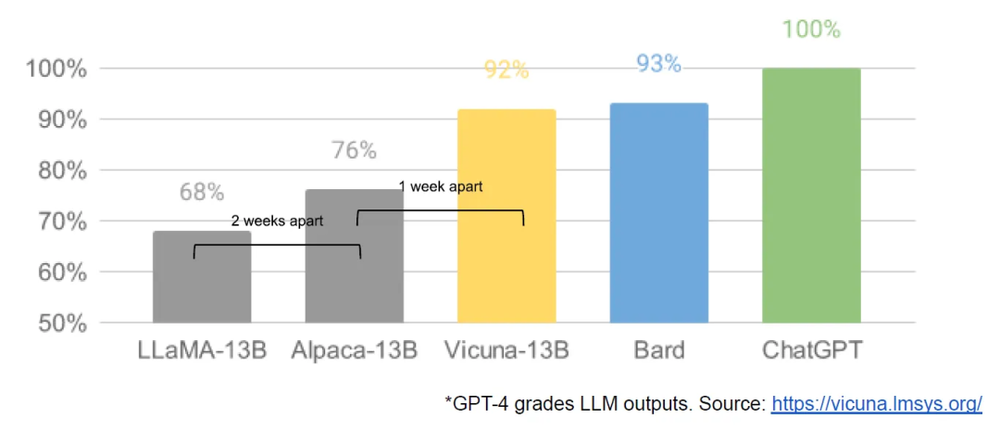
这份文档最大问题在于它被并不标准化和全面的评估给欺骗了,错误地相信“开源模型和 ChatGPT 的差距已经是 92% 和 100% 的关系”以及“LoRA 微调过的模型和 ChatGPT 基本上没有区别”,而忽略了这些对比都建立在“在某些任务上”的前提下。我们将在迷思 2 中对这一点进行更多的评论。
Source: We Have No Moat, And Neither Does OpenAI 配图
在倾听开源模型的训练者的声音以及思考这份文档的标题一个多月后,我反而认为 Google 有护城河,OpenAI 也有它自己的。比“护城河”更严谨的说法是“竞争优势”——在商业层面,Google 拥有其搜索引擎和 G Suite 背后强大的分发渠道,OpenAI 拥有王牌产品 ChatGPT 的用户心智;在技术层面,开源社区在预训练环节和高质量反馈数据的获取以及处理上跟 OpenAI 还有相当大的差距。
赞同这份文档的另一种观点是“搜索引擎将不复存在,因此 Google 的现有分发优势也不构成护城河”。搜索引擎被摧毁的进程目前看仍然会比较漫长。同时,在硅谷之行中,我可以明显感受到经历过了移动互联网和云之后,现有的公司非常 FOMO,而且不会觉得 LLM 和 Generative AI 的机会小,都会很明确地大力投入,大厂和创业公司的竞争不再是菜鸡互啄时代。
迷思2:达到“90% of ChatGPT”或“GPT-3.5 Level”水平
在我们前往硅谷前,3~4 月是开源社区最高歌猛进的一段时间,不断有以新的动物命名的模型出来,不过大体上都是“LLaMA + 指令遵循微调 + GPT 3.5/GPT 4 自动化评估”的范式。其中的指令遵循数据往往也来自 ChatGPT 或 GPT-4 生成。而且这些模型团队自行进行的评估结果都捷报频频,比如 Vicuna“使用 GPT-4 作为裁判的初步评估显示,Vicuna-13B 的质量达到 OpenAI ChatGPT 和 Google Bard 的 90% 以上”,成本则仅仅有几百刀。
大多数媒体在报道时都会自动忽略 Vicuna 团队对这一指标的声明是“GPT-4 做出的有趣且非科学的评估”。从更严谨的视角,这些模型提供了和 ChatGPT 几乎一样的聊天机器人,但是在许多维度上仍然和 ChatGPT 以及 GPT 3.5 有很大差距。这些团队自己也比较清醒,但是架不住媒体的炒作。
John Schulman 4 月下旬在伯克利的 RLHF 讲座上点明了这一类模型的事实性上的缺陷:
(关于 Hallucination 问题的出现)如果你使用同样的监督学习数据,然后训练另一个模型,那么同样的 Hallucination 问题会出现。现在有很多人使用 ChatGPT 的输出来微调其他模型,比如微调市面上的开源 Base Model,然后发现效果不错。但是如果你真的认真观察它们的事实准确度,你会发现它们编造的比例比原始模型更高。
Source: John Schulman - Reinforcement Learning from Human Feedback: Progress and Challenges
到了 5 月,伯克利的论文 The False Promise of Imitating Proprietary LLMs 指出这种方式微调出来的指令遵循模型存在的一系列问题:
在缺少大量模仿 ChatGPT 数据支持的任务上,这类模型无法改善 Base Model 到 ChatGPT 的差距;
这类模型只是擅长模仿 ChatGPT 的风格,而不是事实性,导致实际的性能差异会骗过人类评估者;
当前开源模型最大的限制仍然是 Base Model 层面跟 GPT 系列的差距,在微调而不是预训练环境进行优化可能是不正确的方向;
为了广泛地匹配 ChatGPT 支持的任务,需要更广泛和大量的模仿数据集,还需要新的工作;
……
而 6 月份 Allen Institute for AI 和华盛顿大学的 How Far Can Camels GO?工作再次通过实验表明不同的指令微调数据集可以释放或者增强特定的能力,但并没有一个数据集或者组合可以在所有的评估中提供最佳性能,并且这一点在人类或模型担任评估者时也很容易无法被揭示。
对于指令遵循微调背后的团队来说,他们也意识到自己的模型由于 Base Model(LLaMA)的限制,在复杂推理和代码任务上很弱,并且难以进入正向数据飞轮——模型能力越弱的领域越难得到更多的 query,也就难以筛选出高质量 query,想自己再标注提升模型能力就很困难。
至此,开源社区已经充分意识到原来这套微调 LLaMA 的框架的局限性,越来越多的团队开始探索预训练环节和更接近真实的人类反馈数据。我们也比较期待这两个方向上的进展,在迷思 4 中也会分享更多围绕这部分的观察。
迷思3:定义更“好”的模型和更“高质量”的数据
在迷思 2 中频繁出现的一个问题是“评估”。在传统的 ML 实践中,Benchmark 是衡量表现和将模型推向生产的重要基础设施。我们发布的《C-Eval:构造中文大模型的知识评估基准》也强调了 Benchmark 对于当前 LLM 发展的重要意义。
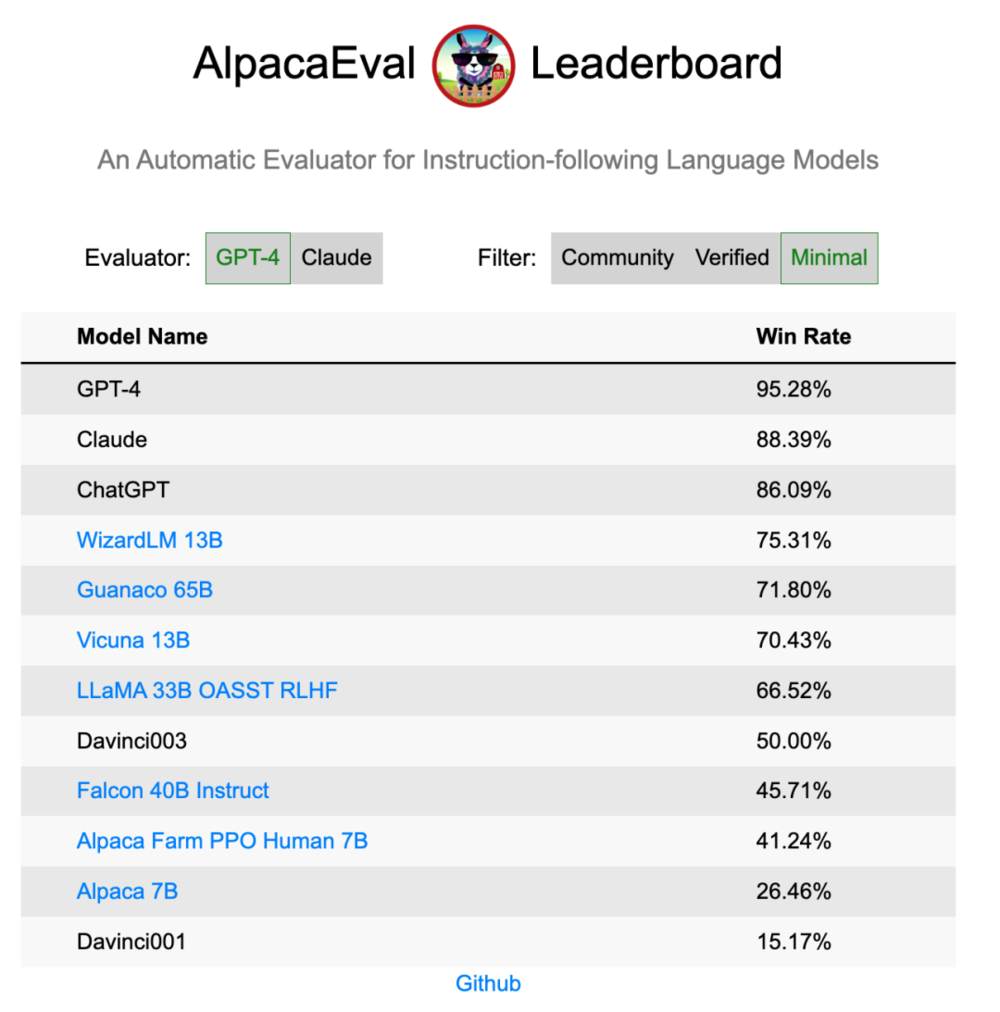
在各个动物混战的第一季度,每个新的指令微调模型出现都会宣称自己是“更好”的模型,但是就像我们在上文指出的,人类或模型担任评估者会让评估非常不全面,所以模型进步的方向也可能跑偏。这个问题目前被解决的还可以,Vicuna 和 Alpaca 都推出了自己的 LeadBoard,有助于各种指令遵循模型进行更自动化和标准化的评估。
除了“更好的模型”在相当长一段时间内缺少明确基准外,“更高质量的数据”一直还是个非常模糊的概念,很难精准地定义。从实操经验的角度,ShareGPT 和其他蒸馏 ChatGPT 输出的方式得到的数据往往是更好的指令遵循微调数据。此外,目前似乎只有一些模糊的方向可以用来指引开源社区寻找“更高质量的数据”,比如更中立和更具 Elavorative 特点的数据从经验上看效果更好。
跟“更高质量的数据”情况类似以及相辅相成的是对模型回答的评估——什么是好的回答?目前的开源模型团队仍然依赖许多主观判断,用户侧的反馈很难找到好的交互,点赞点踩数据基本上充斥着无效噪音,如果这方面有突破可能会让模型们朝迷思 2 结尾的“更接近真实的人类反馈数据”迈进一大步。
迷思4:LLM开源社区并不团结
第一季度时,指令遵循的微调模型格局似乎互相不是很团结,比如 Vicuna 和 Koala 几乎是一样的工作,但是两支伯克利 CS 的团队在分散做。
随着迷思 2 中的问题被意识到,开源社区内大量的注意力开始转移到预训练环节,过去一个季度陆续出来了 Redpajama、OpenLLaMA、Falcon、MPT 等新的模型。预训练对数据集准备、算力等资源的要求更高,也更需要社区协作,OpenLLaMA 最近取得的成果是开源社区团结力量的很好展现:

OpenLLaMA 的预训练数据集来自 Redpajama,按照配方还原了 LLaMA 的 1.2 万亿 token,Apache 2.0 协议可商用,是 Together、斯坦福 CRFM、ETH DS3Lab、Hazy 等合力完成;
OpenLLaMA 的实现由伯克利 BAIR 的两个 PhD 主力完成;
背后算力由 GCP 和 Stability AI 共同提供,模型的训练由 Stability AI 在 TPU 上进行,input 来自于 OpenLM,20B 模型有 78-B 的 token,后续可以由 Carper AI Lab 提供 SFT/RLHF。
除了在模型环节上的开源社区合力,现在到后续的环节目前也都有公认好用的开源项目冒头,链路很通畅。
迷思5:开源社区的目标是超越OpenAI等闭源玩家
开源模型在能力上落后于 OpenAI 和 Anthropic 等玩家是好事还是坏事?对这个问题非常线性的思考是:落后就是坏事,开源社区应该致力于做出来超越 OpenAI 的模型。但是在 LessWrong 这样更关注 AI 安全的社区和 Connor Leahy 这些开源社区的 KOL 那里有非常不一样的声音:
OpenAI 等闭源公司实际上采取了很好的叙事来解释自己的策略,即将最先进模型开源只会带来被威胁,没有一个开源社区可以完全豁免相关责任;
像 EleutherAI 这种组织的立场实际上是完全选择不致力于发布能够推动智能前沿进展的模型和功能,而只在特定情况下发布合适大小和智能能力的 LLM;
蒸馏 ChatGPT 的做法其实抽象来看并不错,即领先的模型推动 AGI 发展的同时帮助优化一些落后的、不会带来智能威胁的模型达到实用的程度,这样闭源和开源社区的发展是可以高度联动的。
迷思6:智能能力是下游客户选择模型的最重要标准
未来能否使用开源模型而不是 OpenAI API 是个回答非常两极分化的问题。真正在做这些开源模型的人会觉得比较无力,主要有几方面原因:
缺算力;
追上 OpenAI 最新模型的智能永远有个时间差;
OpenAI、Anthropic、Google 等公司已经迈向了“全栈产品”,可以把训练数据和用户体验联动来做。
但与此同时,我们在硅谷见到的 Hugging Face、Sambanova 以及 DeepSense 等提供模型实践和部署咨询服务的公司就整体乐观很多。一些解决方案工程师已经有一套完整的清单帮助客户想清楚是否要用 OpenAI API。
很多客户往往一开始想用 OpenAI,但是后面逐渐因为成本、数据安全、用户授权麻烦等问题转而使用开源模型,使用开源的客户大约占 2/3。同时因为 LLaMA 系模型在可商用方面有很多限制,FLAN-T5 是实际部署很多但是在社交媒体缺乏相应讨论度的模型。
从创业公司的角度来看,我们见到的比较优秀的应用,虽然目前还接的是 OpenAI API,但是内部很早就注重平台建设,可以无缝切换各种模型,认为可商用模型出来就会尽快切过去构建自己在模型层的竞争力,复制 Midjourney 的战略。Cresta 最近发布的 Ocean-1 就是个很好的范例,用 GPT-4、Claude 加上开源的 Falcon-40B。所以这个阶段“可商用”可能是比“更智能”更重要的突破方向。
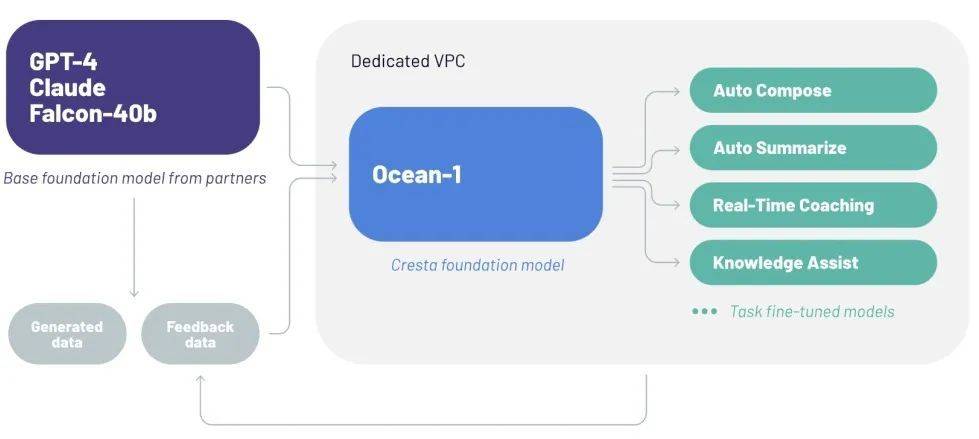
除此之外,本地化部署和确保隐私与数据安全是使用开源模型的重大驱动力,OpenAI 的 Foundry 应该带来很大的冲击,但是由于内部项目优先级的问题,OpenAI 没有真正大举进入这个领域,也让开源社区在近期能维持住来自客户方面的需求动力。
三、展望未来
目前来看阻碍开源模型更大范围爆发的最大的卡点仍然是 LLaMA 的可商用问题,OpenLLaMA、Falcon 等模型复制一个同等繁荣的生态还需要时间。除了在技术角度思考,从法律和政策制定也有很多突破的空间,比如 LLaMA 不可商用的决策出发点是法务,比如那些可以商用的模型使用的是 Apache 2.0 协议,许多社区成员认为用于软件的协议实际上并不适用于模型,呼吁新的开源协议出现。
在接下来 12 个月,我最期望看到的是 3 件事:
更好的 Base Model 出现,可能是 LLaMA 2.0;
更规模化生产和判断接近真实人类反馈数据的框架出现,可能是进化版的 Alpaca Farm;
更适合 LLM 的开源协议出现。
这 12 个月可能会比过去的 6 个月更精彩,鉴于我们看到的一系列既有成果以及 Meta 开源下一代模型的决心——根据 The Information 的两周前的报道,Meta 正在研究如何开源其下一代 LLM 并且可供用于商业用途。
原文后附录有“以 Stanford Alpaca 为例详解指令微调”,因其技术性较强此处省去,若需可查阅原文。
本文来自微信公众号:海外独角兽(ID:unicornobserver),作者:程天一
