2017-03-01 11:25

虎嗅注:2月28日晚,百度移动搜索挂了。然后互联网世界充分体现了“百度宕机,八方点赞”的娱乐至死精神。
手机截图在朋友圈飞舞,门户网站和各种不知名网站的同学们放下手里的筷子或准备好的夜生活,打开电脑,写两段话,配上一个从朋友圈或微博里扒的截图,起个“百度挂了”的标题,点击发送,瞬间,人生成就满满。
那百度昨晚在迎接3月前夜的那30分钟发生了什么呢?百度还没有出来调查结果。但百度一位不愿具名的内部人士告诉虎嗅:“是机房出现了故障,影响面积并不是100%,也许是局部机房的故障,但在两会前夕,把所有人吓个半死。”
具体发生了什么,我们目前还不得而知。但有一种猜测认为,不排除是境外势力在两会前搞破坏。
另外,根据扬子晚报的报道,最近有不少网友反应,用手机浏览器百度搜索某些关键词,进入某一个网页后,只会显示一部分,屏幕以下的网页不出来,要重新刷新两次才会出来一个完整的页面,然后按返回键就会出现一个百度搜索的页面,但是这个页面的网址却又很奇怪,并非百度的真正网址。
除了百度被劫持,还会诱导用户进入一个黄色页面,诱导用户安装存在问题的App。
百度人员与工程师的沟通,发现搜索搜出“假百度”有可能是劫持流量的黑色产业链条所为,还有一些网站是在不知情的情况下被黑。
对昨晚的宕机,百度的公关也再次夯实了“这届百度公关不行”的地位,在百度的官方微博和微信公众号里假装自嘲地说“‘大家一直用的搜索引擎’不正经了一小会儿,很抱歉!”,以为靠这种抖机灵、插科打诨就能蒙混过关。
对于昨晚的百度搜索,我们只能假装知道它发生了什么,下面这篇分析和推测文章转载自微信公众号“待字闺中”,虎嗅经授权转载。
中国互联网发生了一件大事,百度,以技术见长的百度,居然移动搜索宕机了30分钟!李彦宏确实该怒了。
对不起,得知百度移动搜索宕机了,并不是由于去搜索,而是从微信朋友圈看到了一则消息。后来确认,是收到的第一条关于百度宕机的消息。这条消息的时间大概是晚上8点54分。
当时,也没有太在意,还以为是恶搞,或是愚人节笑话。但之后,又连续看到了好几条,于是,就上去试了一下,发现首页还是好的,但是输入搜索词之后,确实发生大事了。后来听说PC搜索并没有宕。
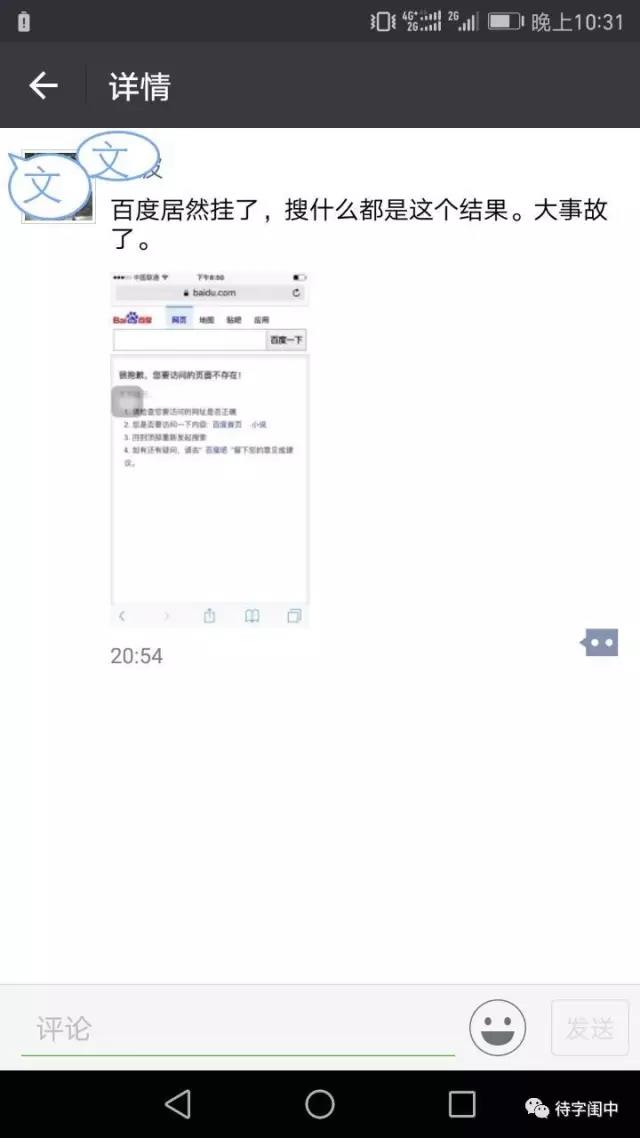
从跟踪朋友圈看,大概晚上9点24左右,百度的移动搜索终于恢复正常了。这时,30分钟,堂堂的1800秒,已经过去。在互联网这个分秒必争的时代,在各大公司比拼三个9或是四个9的无故障服务,能宕机这么长的时间,确实百度内部是个大事故,吃瓜群众见识了一个大笑话。
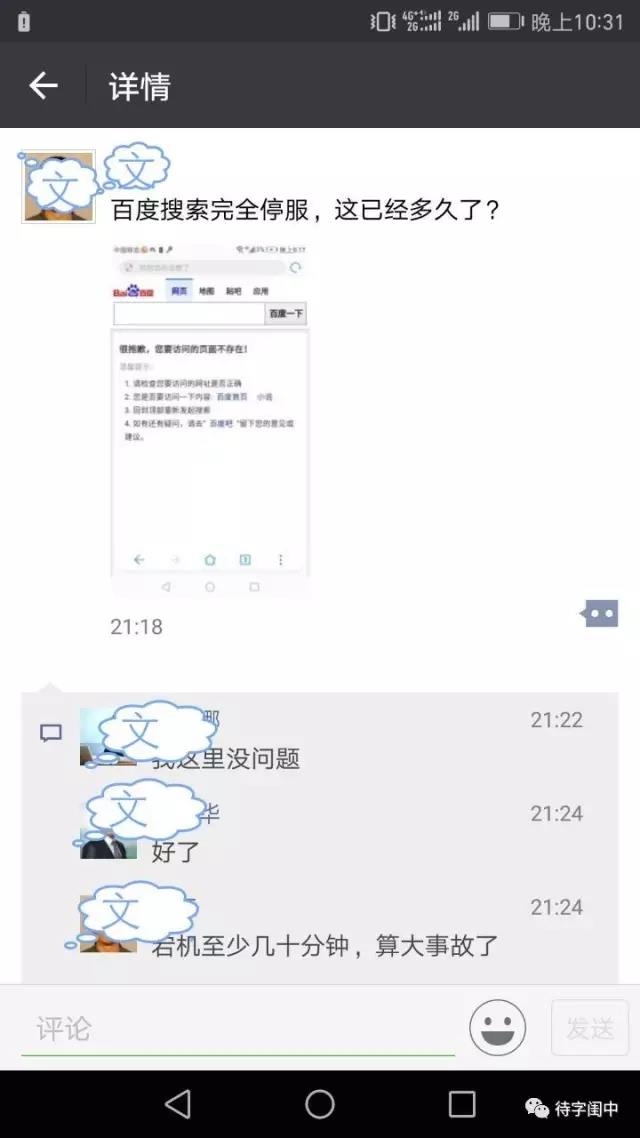
后来,不严肃的百度PR部门,不是以科学的精神解释这个事件发生的原委,而是娱乐至上的在公众号发了一篇文章《“大家一直用的搜索引擎”不正经了一小会儿,很抱歉!》,不知道李彦宏看完是不是该气晕过去,刚上任的一向严谨踏实的新总裁先生是不是该无语了。
还好,对吃瓜群众来说,文章还是透露了一点有用的信息,说是“错过了大家上亿次的搜索请求”。那么,估算一下,30分钟一个亿,一天24小时,那么百度一天的移动搜索量大概就是48亿,也就是50亿上下,还是挺多的。
好了,言归正传,虽然知道百度的整个系统很复杂,我们还是来大胆分析和猜测一下这次宕机的原因。
由于百度的首页和PC搜索还是正常的,基本上,应该可以排除域名服务,运营商,数据中心,网络,硬件的问题。
正常情况下,像Google,百度,这样大型的搜索服务,一般会部署到几个数据中心,比如,在Google,要求的是N+2个不同的数据中心,一个中心在服务,一个中心可能在维护中,那么还有一个中心可以提供线上灾备,这就是为什么需要N+2。这样就算一个数据中心和它的相关硬设发生了问题,全球流量控制系统能迅速的调整DNS,让其它的数据中心很好的接管服务。
这么看来,应该推断是软件系统的问题。也许,百度当时正在升级移动搜索服务。按正常的流程,应该是先升级一个数据中心的服务,观测一段事件没有问题之后,才会升级所有的数据中心的移动服务。就算是没有管理,没有流程控制,一下升级了所有的数据中心,由于搜索是一个无状态的服务,不象电商交易网站,应该有回滚的机制,一旦发现问题,不是在线上调试,希望能很短时间内修复问题,而是立即回滚,让系统回到升级前的正常工作状态,保障用户的服务是第一优先。
这么大的公司,这么长的历史,不至于这些都没有吧。
如果不是正在升级线上系统时发生问题,那么又可能是什么呢?现在的搜索系统的架构,一般是一个Root服务节点,下面有多个Parent服务节点,之下有多个Leaf服务节点,每个Leaf节点负责一部分网页的搜索,然后将搜索结果返回给Parent,最后由Root节点综合所有的结果,给出最后的排序结果,也就是一种分而治之的思想。
如果一个数据中心的移动搜索服务宕了,最大的可能是Root服务节点出问题了,否则的话,至少会有部分结果。那Root最有可能的宕机原因是硬件出问题了,内存不够了,或是磁盘满了。但一般Root这种SPOF节点,一定应该由Backup,也就是Backup也出问题了,这就不大可能是硬件问题。
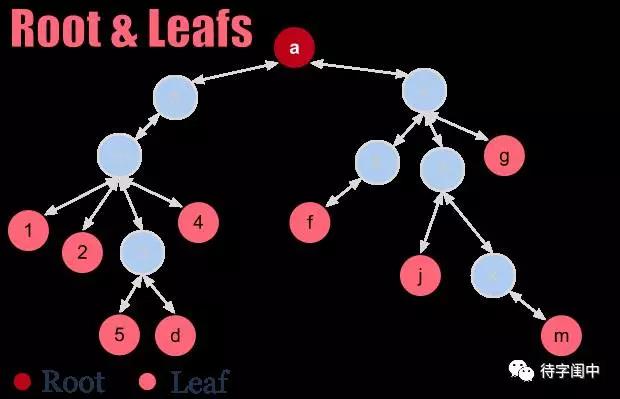
还有一种大面积出问题的可能,query of death,就是一个有问题的搜索词,触发了所有系统节点的bug,引起所有的系统节点都crash,不能正常服务。这个问题在搜索发展的初级阶段是很有可能的,然后,人们在设计系统时,专门有机制来处理这种问题,比如,在前端服务器中有黑名单机制,在着急的时候,先把这个搜索放到黑名单,这个搜索词就不会往后面的树状服务传播,然后再慢慢修复。
再说了,百度运营了这么长的时间,又是以技术见长,系统,架构,灾备,防攻击,监控,报警,流程,规范,紧急处理,等等,都应该很完备。
那么问题,究竟会出在哪里呢?
网上有阴谋论,说是百度最近在员工评级,可能是有不满意的员工在报复性的破坏。觉得这个不大可能,所有的线上服务的操作应该有一套完善的流程,应该有抹不去的记录。比如,在Google,要做线上的修改,首先必须有代码准备,然后代码审查,然后有领导审批,最后才会有运帷人员负责执行操作。对于重要的服务的上线,一般会是两个人配合,一个人操作,一个人监察,防止误操作。
除非百度没有完善的管理机制,否则不大可能破坏。再说,就算破坏了,那些日志也足以把坏蛋揪出来,绳之以法,谁会愿意去冒这个牢狱之灾的险呢?
能想像的一种可能场景,监控系统报警移动服务出问题了,运帷人员接到报警后,认为是个小问题,不遵守流程规范,直接在线上修复。在修复的过程中,可能是误操作,可能是对整体系统不够了解,结果引起了连锁反应。这时,发现事大了,准备回滚,但是,由于是线上直接修复,系统状态发生了改变,某些重要数据被系统修改了,回滚也失效了,这样,麻烦就大了。
所以,才会花了30分钟,去线上诊断问题修复,或者是直接从早期备份导数据。否则,30分钟实在没法解释。
就算这种情况,也不是特别好解释,难道百度移动搜索只在一个数据中心部署,没有备份吗?搜索,毕竟不象一个交易系统,需要保存状态,需要强一致性,数据库是SPOF,就像上次github出问题,需要从备份数据库导数据,花了很长时间才恢复。
总之,感觉还是百度的管理和流程出现了问题,否则,30分钟,1800秒,太难解释了。不管如何,但最后,作为一个外人,还是期待听到百度自我调查的结果,聊以借鉴。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。