




2023-07-27 16:57

扫码打开虎嗅APP


本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,原文标题:《“人造太阳”精准放电!DeepMind实现AI可控核聚变新突破》,题图来源:《终结者3》
AI可控核聚变,指日可待。
秘密研发3年,DeepMind去年宣称,首次成功用AI控制“托卡马克”内部等离子体。其重磅成果登上Nature。
时隔一年,谷歌AI团队在这一领域再次取得突破。
最新实验模拟中,将等离子体形状精度提高了65%。
DeepMind团队基于上次的研究,对智能体架构和训练过程提出了算法改进。
研究发现,等离子形状精度提高的同时,还降低了电流的稳态误差。
甚至,学习新任务所需的训练时间减少了3倍还要多。

论文地址:https://arxiv.org/pdf/2307.11546.pdf
从“星际争霸”AI碾压人类,到AlphaGo大战李世石、AI预测蛋白质折叠,DeepMind已经将人工智能算法深入到了足以改变世界的不同领域。
这次,DeepMind最细实验模拟结果,为RL实现精确放电指明了道路。
这一里程碑式的成果,标志着“人造太阳”可控放电离人类终极能源的未来又进了一步。
一旦人类掌握了可控核聚变能,将可拥有无穷不尽的清洁能源。

要知道,反馈控制对于“托卡马克装置”的运行至关重要。
而控制系统会主动管理磁线圈,以控制拉长离子体的不稳定性,防止破坏性的垂直事件发生。
此外,人类若能实现对等离子体电流、位置和形状的精确控制,还可以实现热排放,甚至对其能量的管理。
一直以来,科学家们致力于研究等离子体配置变化对这些相关量的影响。因此就需要能够用于新配置,以及围绕标称场景快速变化的系统。
传统上,等离子体的精确控制是通过等离子体电流、形状和位置的连续闭环来实现的。
在这种模式下,控制设计者预先计算出一组前馈线圈电流,然后为每个受控量建立反馈回路。等离子体形状和位置无法直接测量,必须通过磁场测量实时间接估算。
尤其是等离子体的形状,必须使用平衡重构代码进行实时估算。
虽然这类系统已成功稳定了大范围的放电,但其设计不仅具有挑战性,还耗时,特别是针对新型等离子体情况。
值得一提的是,强化学习(RL)已成为构建实时控制系统的另一种全新范式。
2022年,DeepMind团队登上Nature的一篇论文表明,RL设计的系统能够成功实现“托卡马克磁控制”的主要功能。

论文地址:https://www.nature.com/articles/s41586-021-04301-9
这项工作提出了一个系统,RL智能体通过与FGE 托卡马克模拟器交互,学习控制托卡马克配置变量(TCV)。
智能体学习的控制策略随后被集成到TCV控制系统中,通过观察TCV的磁场测量,并为所有19个磁控线圈输出控制指令。
尤其,研究人员展示了RL智能体控制各种情况的能力,包括高度拉长的等离子体、雪花。
甚至还展示了同时在真空室中,使用两个独立等离子体稳定“液滴 ”配置的新方法。
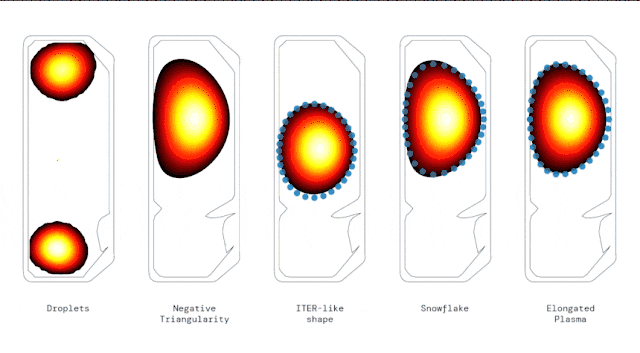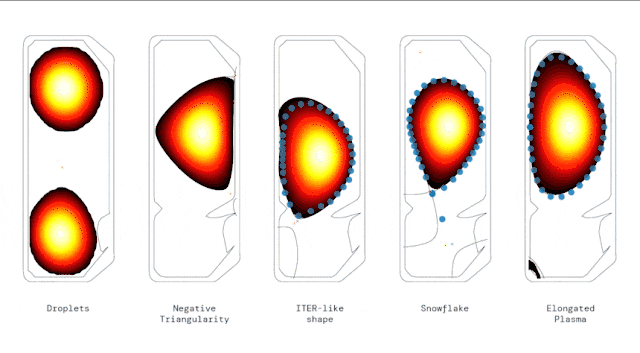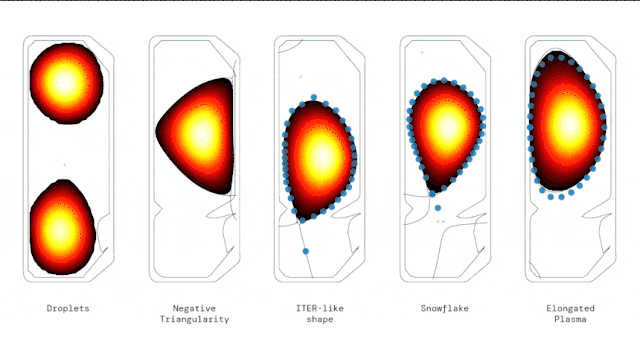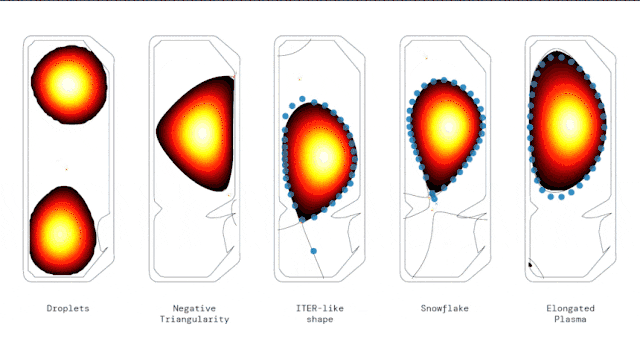
AI控制下生成的几种不同等离子几何形状
但是,RL方法有许多缺点,限制了其作为控制托卡马克等离子体的实用解决方案的应用。
最新研究中,DeepMind决定要解决三个挑战:
指定一个既可学习又能激发精确控制器性能的标量奖励函数
追踪误差的稳态误差
较长的训练时间
首先,团队提出了“奖励塑形”的方法,以提高控制精度。
然后,通过向智能体提供明确的错误信号,和集成错误信号来解决积分器反馈中的稳态误差问题。这缩小了经典控制器和强化学习控制器之间的精度差距。
最后,在片段分块和迁移学习中,解决了生成控制策略所需的训练时间问题。
研究人员针对复杂的放电情况采用了多重启动方法,使得训练时间大幅缩减。
此外,研究还表明,当相关新情景与之前的情景接近时,使用现有控制策略进行热启动训练,是一种非常有效的工具。
总之,这些技术大大缩短了训练时间,提高了精确度,从而使RL成为等离子体控制的常规可用技术取得了长足进步。
最新论文中,研究人员采用与Nature那篇论文相同的基本实验。
RL通过与模拟环境的交互,学习特定实验的控制策略,然后TCV上部署由此产生的放电策略。
具体来讲,使用自由边界模拟器FGE进行动态建模,并添加了额外随机性,以模拟传感器值和电源的噪声,并改变等离子体的参数。
传感器噪声适用于每个环境步骤,而等离子体参数变化(等离子体电阻率Rp、归一化等离子体压力βp、等离子体轴安全系数qA)则经过简化,因此其值在一个事件内是恒定的,但在两个事件之间随机取样。
然后,研究人员使用最大后验优化(MPO)算法来制定控制策略。
MPO依靠两个神经网络:一个是输出当前策略π的actor网络,另一个是近似该策略预期累积奖励的critic网络。
智能体与1000份FGE环境进行交互,收集看到的观察结果、采取的行动,以及获得的奖励。
每一步获得的奖励,都是根据等离子体状态与参考值中包含的目标值的接近程度来计算的,并辅以其他因素,如避免不良等离子体状态。
从最优控制范式到强化学习的直接转换是,为每个要最小化的误差项设置一个奖励分量,其中每个分量i都被映射为一个标量值xi。
然后将这些值合并为一个标量奖励值。
根据观察、行动和奖励的记录序列,智能体使用正则化损失函数上的梯度下降交替更新策略和critic网络。更新后的actor网络参数将用于未来与环境的交互。
对于等离子体放电,actor网络被限制在一个能以10kHz频率执行的小型架构中,但critic网络只在训练过程中使用,因此可以足够复杂地学习环境动态。
在具体任务实操中,研究人员演示了智能体具体训练过程。
首先讨论了通过奖励塑形来提高控制精度。然后介绍了通过积分观测来减少稳态误差的工作,讨论了使用“episode chunking”来改善现实的训练时间。最后探讨了迁移学习作为提高训练效率的手段。
传统控制算法用各种办法来最小化主动测量(或估计)的数量误差,而强化学习(RL)算法则旨在最大化一个通用定义的奖励信号。
在训练过程中,这种奖励最大化目标能推动智能体行为的演化,但是在部署时不会计算奖励值。
在经典控制算法中,控制器的性能可以通过显式调整控制增益(例如,修改响应性或干扰抑制)和调整多项输入多项输出(MIMO)系统的权衡权重来进行调整。
相比之下,在强化学习中,奖励函数对于被学习的控制器行为至关重要。
因此,需要仔细设计奖励函数来调整控制器行为。
在本节中,研究人员探讨了如何修改奖励的设计,以引发最终训练得到的智能体去进行我们所期望的行为。
研究人员发现,通过调整奖励函数的设计,他们可以快速适应智能体的行为,并权衡目标的不同方面。
此外,研究人员证明了塑形奖励函数对于创建准确的强化学习控制策略是必不可少的。
而且他们进一步展示了通过使用更新后的奖励函数继续训练,可以将智能体应用到新的目标上。
研究人员在先前研究的基础上修改了为磁控而设计的奖励函数。
研究人员使用加权的SmoothMax函数来组合奖励组件的值。
在某些情况下,一个单独的奖励组件由多个相关的误差量构成,比如在多个控制点处的形状误差。
研究人员还利用SmoothMax函数将这些误差组合成一个单一的标量奖励组件。
SmoothMax函数的定义如下所示:
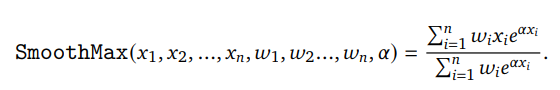
许多喂给SmoothMax函数的单独组件的构建方式与经典控制器类似(例如,将等离子体电流保持接近期望值)。
然而,奖励组件并不受限于从传感器测量中获得,这在构建中就能提供了额外的灵活性。
奖励组件还可以是多模态的,例如鼓励智能体远离状态空间中不理想或模拟器建模较差的区域。
研究人员使用SoftPlus转换来获得标量奖励组件:
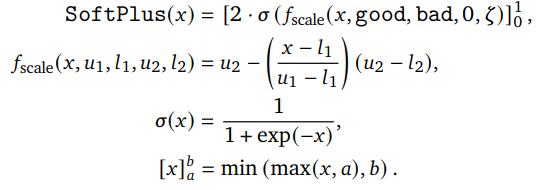
理论上,许多参数的选择应该是近似等效的,因为它们是奖励的单调调整,不应该对最优策略产生很大影响。
然而,在实践中,研究者依赖于梯度下降(gradient descent),并没有一个完美的全局优化器(global optimizer)。
研究人员需要在面对随机回报的情况下探索全局空间。
很好和很差的紧密值使得很难找到任何可观的奖励区域(或者在如何改进方面有明显的梯度)。
另一方面,较宽松的很差值使得更容易找到奖励信号,但更难以发现精确的控制,因为改进时奖励变化较小。
直观上,因此,“紧密”奖励参数可能更适用于初始条件接近目标状态的情况,因此奖励不需要塑造目标发现,而应更注重精确性。
在研究人员的初始实验中,考虑了三种训练方法,重点是通过修改“shape_70166”任务中形状误差的奖励组件的超参数来最小化形状误差。
1. 基准线:采用之前研究的默认奖励参数 - good = 0.005,bad = 0.05。
参考值产生了一个较为宽松的奖励函数,该设置使奖励信号集中在较高的误差值,对于较小的误差值也提供了引导信号,激励增加形状控制的准确性。
2. 窄化奖励:将参数更新为good = 0和bad = 0.025。
这些参考值产生了一个更为严格的奖励函数。该设置将奖励信号集中在较低的误差值,甚至对于小的误差值也提供了引导信号,鼓励在控制形状时提高准确性。
3. 奖励调度(reward schedule):将good和bad的值在训练过程中逐渐调整为更加尖峰(more Peaked),good = 0,bad从0.1逐渐减少到0.025,共进行600万次策略更新步骤。
该调度在训练开始时提供了一个较宽的奖励区域来帮助探索,随着训练的进行逐渐收紧奖励函数,以鼓励准确性。
历史数据在奖励函数演变过程中不会重新被标记,但过时的数据最终会从学习智能体的回放缓冲区中消失。
这一系列的实验结果如下图所示。该研究证明了用于训练的奖励选择对最终训练的智能体的性能有着显著影响。
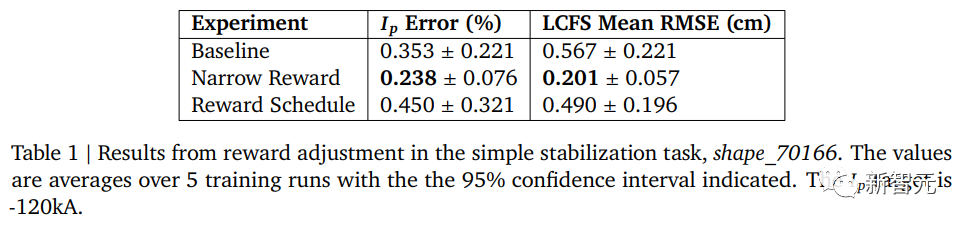
通过对形状误差的关注,研究人员注意到对最终智能体性能影响最大的是采用了高度严格的静态奖励函数的“窄化奖励”。
在这个简单的任务中,更精确的奖励函数为控制器提供了强烈的准确性激励。
尽管如上所述,这样尖锐的奖励信号可能会对策略发现造成影响,但该任务的目标是保持交接位置,因此在这个任务中探索并不是一个主要的挑战。
由于几乎不需要探索来找到高度奖励的状态,智能体可以专注于满足严格的奖励信号。
此外,任务的简单性意味着在奖励组件之间准确控制很少或几乎不需要权衡取舍(trade off)。
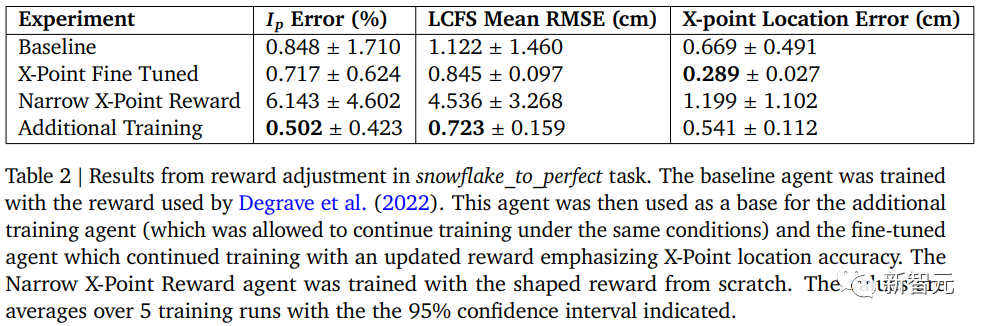
研究人员转向“snowflake_to_perfect”任务,这个任务训练成本更高,奖励调整更为复杂,因为涉及到时变目标和更多的关注指标。
而且他们试图通过奖励塑形来提高X点位置的准确性。
以下是针对X点位置准确性的奖励塑形方法:
1. 基准线:使用从Degrave等人先前采取的默认参数进行训练 good = 0.005,bad = 0.05。
2. X点微调(X-Point Fine Tuned):首先使用默认参数进行训练,然后进行第二阶段的训练,使用更为严格的奖励,强调X点位置的准确性 — good = 0,bad = 0.025。
3. 窄化X点奖励(Narrow X-Point Reward):从训练开始就使用更为严格的奖励函数 — good = 0,bad = 0.025。
4. 额外训练:在不更新奖励函数的情况下进行额外的训练。这样使得研究人员能区分更多训练和改变奖励函数所带来的影响。
研究人员比较了上述四种不同的训练配置的性能,结果总结在下表中。
积分误差的近似可以通过递归神经网络来计算,然而,它们更容易过度拟合仿真动态。
在这项工作中,研究人员采用了一种更简单的解决方案:没有让策略(policy)学习积分误差,而是手动计算它,并将其附加到前馈策略所观察到的观测集中。
他们特别关注了减少等离子体电流(Ip)的稳态误差,之前研究的训练策略表现出明显的偏差,并且该误差可以很容易地计算。
与传统方法稍有不同,研究人员向网络提供了时间的平均等离子体电流误差定义如下:
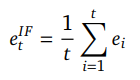
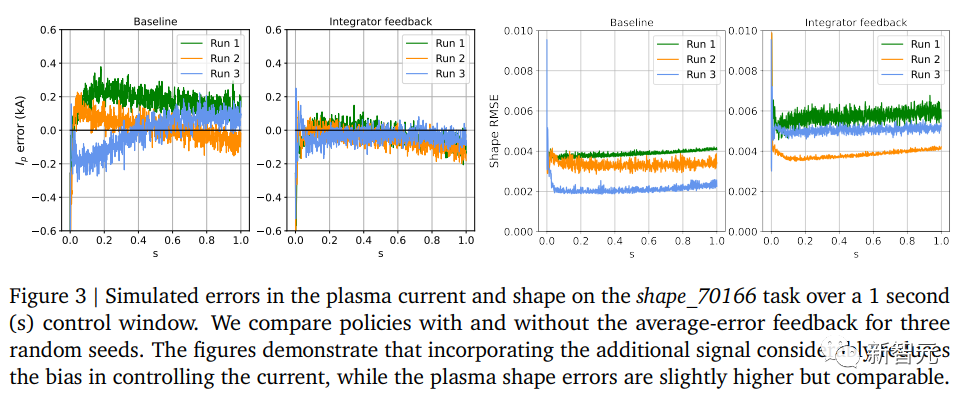
研究人员在“shape_70166”任务中评估了将平均误差信号纳入考虑的好处。
在该任务中,等离子体电流和形状的参考值是恒定的,环境初始化后实际值接近参考值。
因此,智能体的主要目标是控制稳态误差(steady-state)。
下图显示了使用积分器反馈训练和未使用积分器反馈训练的策略的模拟等离子体电流误差轨迹,每种情况下进行了三次随机运行。
研究人员发现,积分器反馈显著降低了等离子体电流偏差,正如预期的那样。
在TCV上的实验持续1~2秒,相当于以10kHz的控制频率进行10000~20000个时间步。
FGE模拟器(如上所述用于训练智能体)在训练过程中使用一颗AMD EPYC 7B12 CPU核心,每个典型的模拟步骤大约需要2秒钟,使用随机动作。
因此,FGE生成包含10,000个步骤的一次完整episode大约需要5小时的时间。
这意味着在最理想的情况下,即智能体在第一次尝试之前已经知道最佳策略,训练时间仍然会约为5小时(以观察高质量的结果)。
实际上,强化学习智能体需要探索动作空间以找到最佳策略。因此,根据任务复杂性,训练时间可能从几天到几周不等。
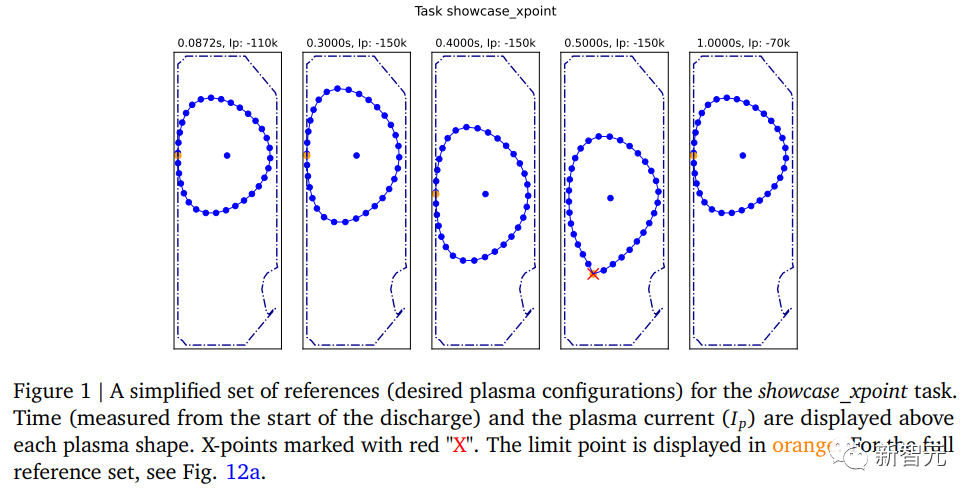
此外,研究人员的任务结构使得智能体需要按顺序学习相对独立的“技能”。例如,在“showcase_xpoint”任务中,智能体必须先使等离子体变形,然后移动其垂直位置,然后改变其流向,最后恢复原始形状(参见下图1)。研究人员观察到该任务的学习过程发生在两个明显的阶段(见下图2a)。
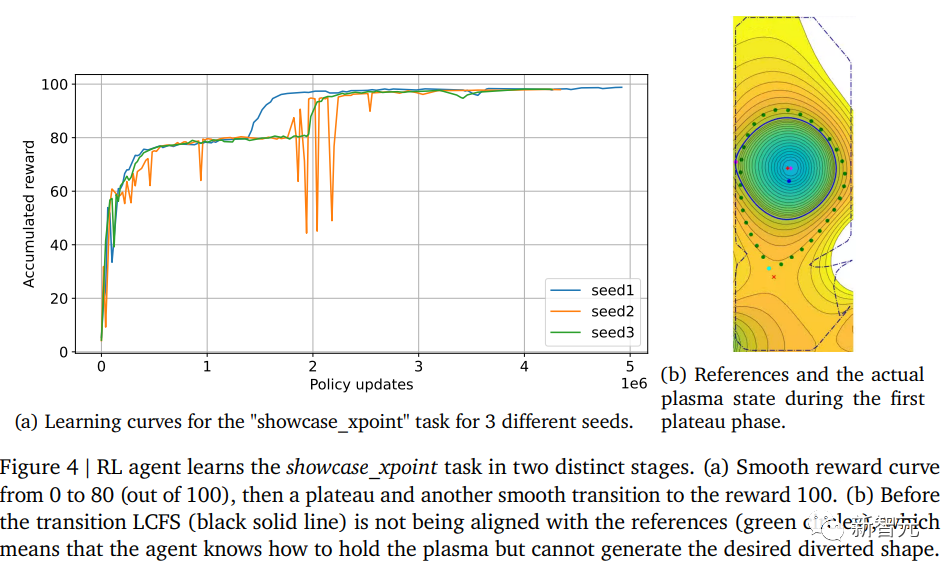
首先,智能体学会操作有限的等离子体,理解如何延展、移动和保持等离子体,这对应于奖励曲线,就是从0平滑上升至约80。
在此阶段,智能体尝试(但失败了)生成一个转向形状,取而代之的是获得具有非活动X点的圆形LCFS,如上图b所示。
奖励在此水平上保持稳定,直到最后,智能体发现如何成功地将等离子体转向,这时奖励值从80突变至接近1。
将分块(chunking)技术应用于展示_x点(showcase_xpoint)任务,并分别使用两个/三个块(如下图一所示),可以显著缩短训练时间,如下图2所示。
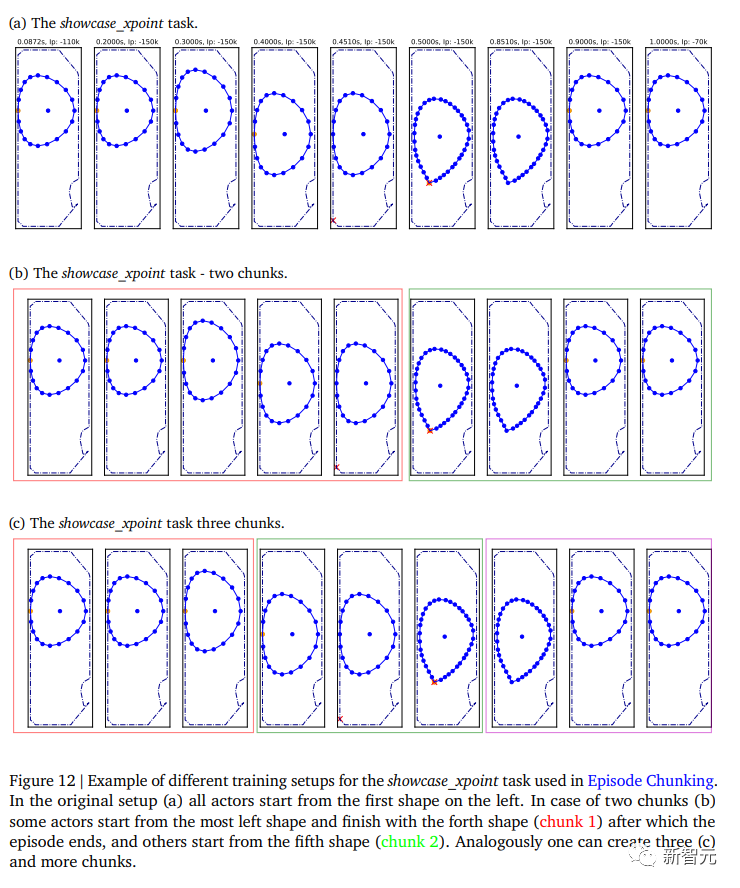
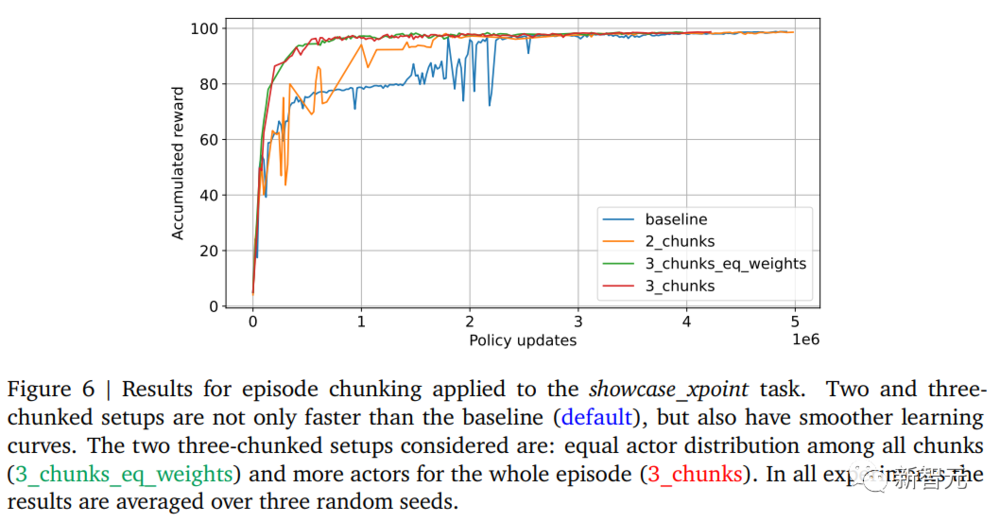
两个块的设置(橙色曲线)已经比基准线(蓝色曲线)更快。三个块的设置(3_chunks和3_chunks_eq_weights)不仅提供进一步的训练加速,而且学习曲线更加平滑。
智能体在约10小时内就能达到96(满分100)的奖励,而基准线需要40小时。
在这里,研究人员尝试了两种不同的三块设置:所有参与者(actor)被平均分为相同大小的组(3_chunks_eq_weights);与每个其他块相比,整个episode使用三倍更多的参与者。这两种设置给出了类似的结果。
在试图减少训练时间时,一个自然的问题是问是否可以重用之前放电时训练的模型,也就是说,智能体在解决一个初始任务时积累的知识在多大程度上可以转移到一个相关的目标任务上。
研究人员以两种形式考察迁移学习的性能:
1.零样本(Zero-shot):研究人员在目标任务上运行在初始任务上学习的策略,而无需进行任何额外的数据收集或策略参数更新。
2.微调(Fine tuning):研究人员使用在初始任务上学习的模型的权重来初始化策略和值函数,然后使用这些权重在新的目标任务上通过与环境交互进行训练,其中目标任务作为奖励。需要注意的是,这要求在两个任务中使用相同的架构(actor和critic网络)。
在两种情况下,研究人员使用在showcase_xpoint任务上训练的智能体参数作为迁移的初始参数。
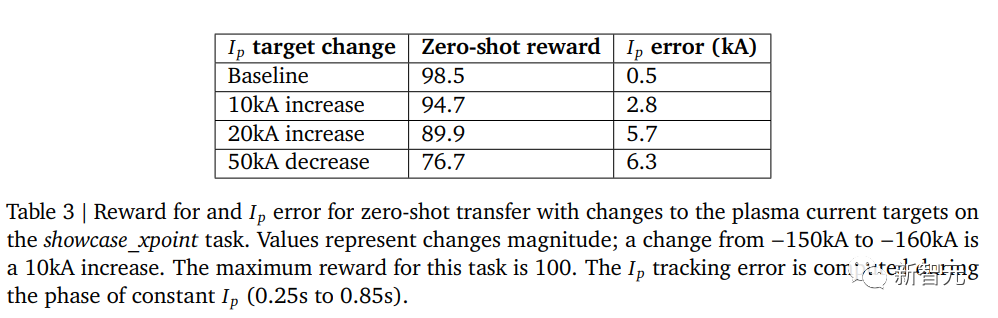
在第一个实验中,研究人员考察当参考等离子体电流调整到新的参考水平时的迁移学习。
具体而言,研究人员选择了三种变化,其中目标从基准线-150kA调整到-160kA,然后-170kA,最后-100kA(具体而言,在图1中除了初始交接水平和最终降温水平外的所有时间片中调整参考电流)。
研究人员测试了在showcase_xpoint上训练的策略,首先在目标任务上没有任何额外训练,然后允许在目标任务上进行新的训练。
零样本结果的奖励和误差如下表所示,在小的Ip变化情况下,智能体表现良好,但在较大的变化情况下,尤其是对于较大的Ip变化,智能体表现较差。
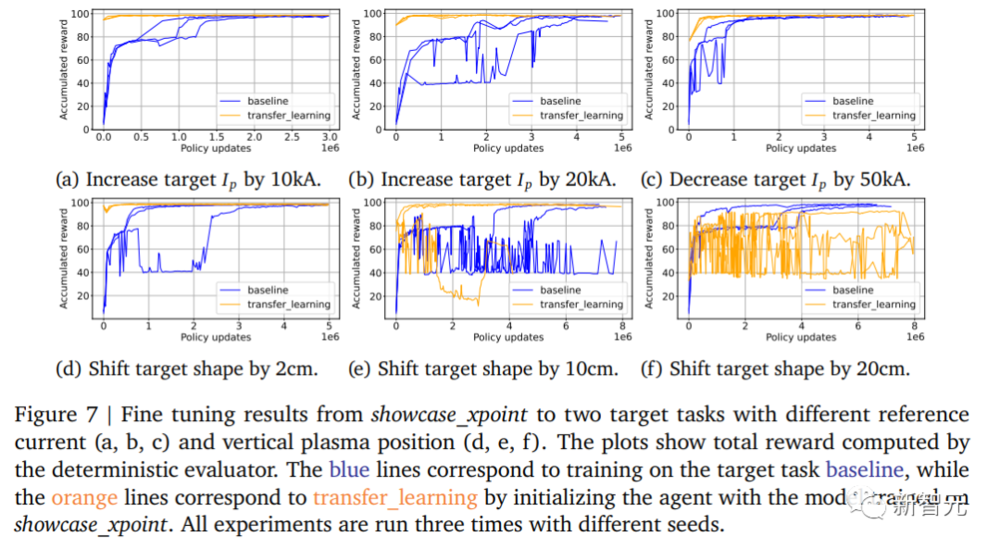
微调的结果如下图a、b、c所示,微调智能体在所有情况下比从头开始训练的智能体更快地收敛到近乎最优的策略,尽管在最大的50kA变化情况下差异较小。
第二个实验考察了等离子体目标位置的变化。
具体而言,研究人员沿着z轴向下调整目标形状,分别平移2厘米、10厘米和20厘米。对于这个实验,研究人员观察到以下结果:
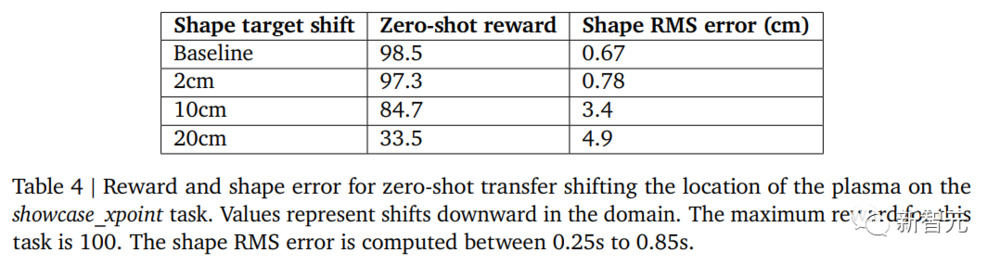
1. 零样本(Zero-shot):结果如下表所示。研究人员发现对于最小的平移(2厘米),零样本迁移效果非常好,任务的表现达到了最佳可实现性能的97%以上(满分100分),形状误差也很小。
对于较大的10厘米平移,表现较为一般,只获得了85的奖励,并且形状位置误差更大。对于最大的20厘米平移,表现较差,只获得了35的奖励,由于未能成功转向等离子体。
2. 微调(Fine tuning):微调的结果如上图d、e、f所示,表明对于2厘米的平移,迁移学习效果显著,对于10厘米平移,三个不同的种子中有两个种子的效果有效。而对于较大的20厘米平移,迁移学习似乎对性能产生了不利影响。
总体而言,结果表明迁移学习在当前形式下是有用的,但也有一定的局限性。
正如预期的那样,目标任务与初始任务之间的差距越大,迁移学习的性能就会降低,尤其是在零样本学习的情况下。
然而,值得注意的是,在运行硬件实验之前,通过模拟进行零样本评估的成本相对较低(以CPU小时为单位)。
研究人员还发现,某些类型的任务变化比其他任务更容易进行迁移学习,在他们的实验中,相对较大的等离子体电流变化似乎更适合于迁移学习,而不是大的位置变化,这在考虑到任务的相对复杂性时是可以理解的。
需要进一步研究来了解哪些任务适合于迁移学习,并如何扩展有效迁移的范围,包括零样本和微调学习。
之前的部分仅关注使用FGE模拟器进行仿真、训练和评估控制策略。
考虑到托卡马克建模(Tokamak modeling)的复杂性和挑战性,重要的是不能盲目地认为仿真中的性能改进与实际放电中的性能改进完全相同。
虽然更好的仿真结果可能对实际托卡马克的改进结果是必要的,但往往是不够的。
如果没有额外明确的工作来减小仿真与实际之间的差距,模型不匹配误差可能会变成一个很主要的问题。
对于使用强化学习获得的策略,已知会过度拟合到不完美的模拟器,这种情况尤为明显。
因此,研究人员在TCV托卡马克上对一些上述的仿真改进进行了测试。
通过这种方式,研究人员可以评估当前工作的优势和局限性,并为下一步的改进提供方向。
研究人员检查了奖励塑形在两种不同配置和目标上所带来的精度改进:减少形状稳定任务中的LCFS误差和提高“snowflake_to_perfect”任务配置中的X点精度。
研究人员将模拟结果与TCV上的实验结果以及来自Degrave等人(2022)的可比实验进行了比较。与先前的研究一样,研究人员通过将演员网络(由JAX图定义)创建为共享库对象来部署控制策略,其中命令的动作是输出高斯分布的均值。
研究人员首先测试了一个控制策略,该策略通过在奖励塑形部分中讨论的奖励塑形方法来减少shape_70166稳定任务中的LCFS误差。
对于这个稳定任务,研究人员使用了TCV的标准击穿过程和初始等离子体控制器。在0.45秒时,控制权移交给学习的控制策略,然后它试图在1秒的持续时间内维持固定的等离子体电流和形状。
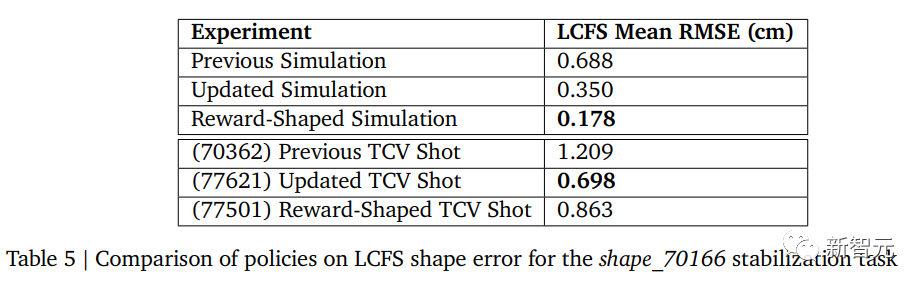
放电后,研究人员使用LIUQE代码计算重构的平衡态。在1秒的放电过程中的每个0.1毫秒时间片内,研究人员计算等离子体形状的误差。研究人员比较了三个实验的精度,分别从模拟放电和TCV放电中测量形状误差:
(a) 一种在本研究之前已经存在的基线RL控制器(“Previous”), (b) 一种使用本研究中更新的训练基础设施的更新的基线代理(“Updated”), (c) 一种使用奖励塑形训练的代理,就像在奖励塑形部分描述的Fixed Reward一样。
这些运行的结果在下表中。
接下来,研究人员将比较奖励塑形对更复杂的“snowflake”配置的影响,如下图所示。
该策略的训练奖励被塑形以增加X点控制的准确性。
与稳定实验中一样,等离子体是通过标准的TCV程序创建和初始控制的,在0.45秒时将控制权移交给强化学习控制器。
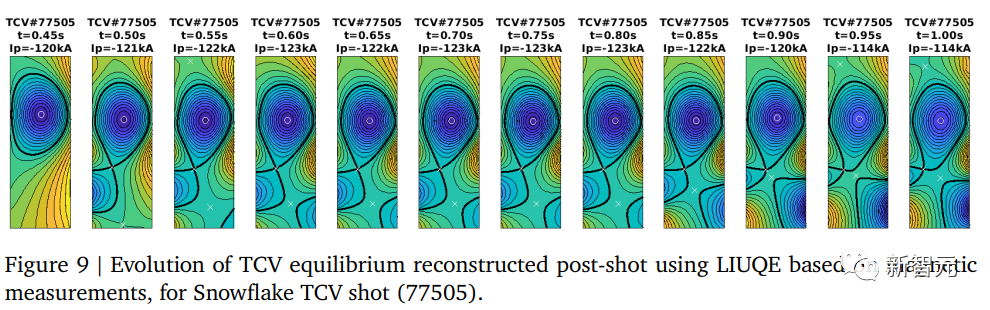
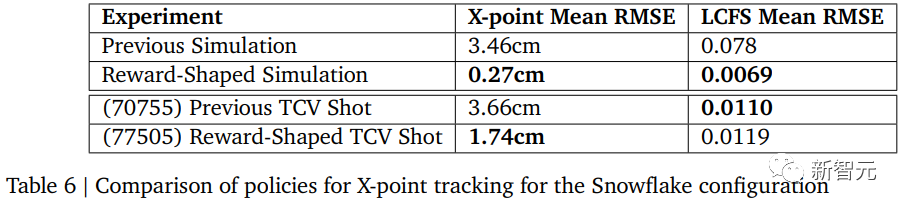
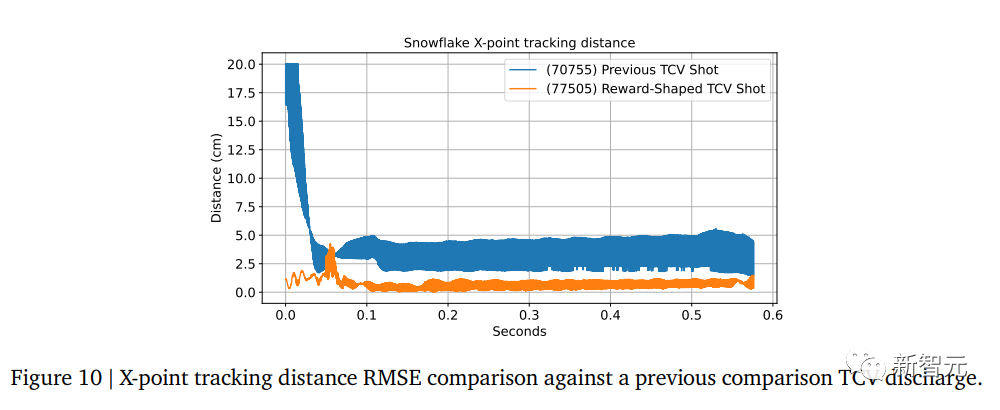
在这个实验中,RL训练的策略成功地建立了一个两个X点距离为34厘米的“snowflake”。
然后,该策略成功将两个X点带到了目标距离6.7厘米的位置,接近建立一个所谓的“完美snowflake”。
然而,在1.0278秒(即交接后的0.5778秒),等离子体因垂直不稳定性而发生破裂。
经检查,发现控制器在保持一致形状方面存在困难,其中垂直振荡增加,活动的X点在两个X点之间切换,导致失控。
下表显示了在等离子体成功控制期间对X点追踪的准确性。
最后,研究人员验证了使用“Episode Chunking”来减少训练时间,特别是验证在TCV放电中是否出现可能的“不连续性”。
研究人员进行了一个在showcase配置下使用3个块进行训练的实验。这个实验的重建平衡态的时间轨迹可以在下图中看到。
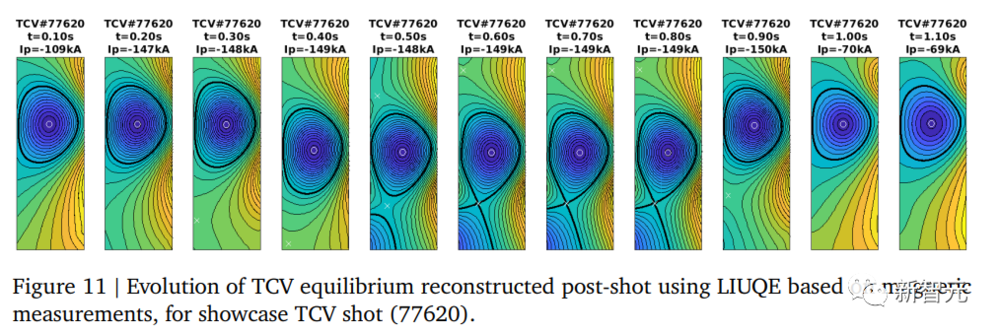
研究人员发现实验按预期进行,没有因为“episode chunking”而产生明显的伪影。
这证明了这种训练加速方法没有损失质量。
20世纪50年代起,众多科学家们致力于探索、攻克可控核聚变这一难题。
DeepMind最新研究,用强化学习算法大幅提升了等离子体的精度,极大缩短了学习新任务的训练时间。
这为可控核聚变在未来实现“精准放电”,能量管理铺平了道路。
在为人类获取海量清洁能源,以改变未来的能源路线图上,DeepMind再次点亮了一盏明灯。
参考资料:
https://arxiv.org/abs/2307.11546
https://twitter.com/GoogleDeepMind/status/1684217852289601541
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元

