2017-03-15 18:18


扫码打开虎嗅APP

百度用人工智能技术做了新产品。
百度硅谷实验室(SVAIL)周一上线了网页应用 SwiftScribe,基本的功能是把音频资料转录成文字。在一篇博客文章中,项目主管 Tian Wu 说他们解决了一个重要的“痛点”:消耗大量时间的逐字听写转录。
SwiftScribe 目前还处在内测阶段,并未开放,不过你可以通过一个演示示例了解它是怎么工作的。SwiftScribe 支持上传时长 1 个小时以内的 wav 或 mp3 文件,目前只接受英文。接下来它需要花点时间生成文字,官方说法是,1 分钟的录音需要不到 30 秒、1 小时的录音需要 20 分钟左右。
接下来你会在网页上看到转录好的文字,但这并不意味着转录结束。文本不会区分大小写、没有标点符号,更没有分段,你需要在文本框中手动编辑,然后再做导出。这个过程也会被百度记录,就像所有的人工智能学习过程一样,它用来帮助算法纠正错误,提高准确率。
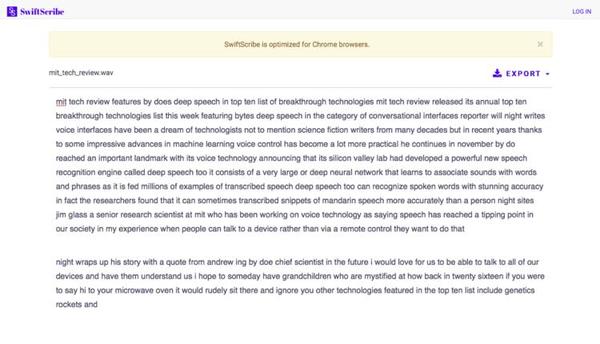
文本框底部有一排工具栏,播放按钮开启,一个高亮的标识会跟随语音标出阅读的进度,方便你停下来查看这个单词对应的语音。这个工具栏还有变速、标记的功能。
这个过程就相当于用机器算法取代了速记员、听写员的工作。“SwiftScribe 会在广泛的领域内带来积极影响,提高生产力,包括医疗机构、法律、商业和媒体。”Tian Wu 在博客中说,专业领域的人工听写效率低,1 小时的录音往往需要花费 4-6 个小时,每分钟语音的成本在 1 美元,SwiftScribe 能把完成工作的时间平均缩短 40%。
Tian Wu 在接受采访时表示,他们以后还会增加对视频文件的语音识别支持,也会添加自动插入标点符号等功能。
语音识别并不是什么新鲜事物,你手机里的各种语音助理比如 Siri、Cortana 都基于此,用户关心的唯一问题可能是到底识别的准确性有多高。
按照 Tian Wu 的介绍,SwiftScribe 基于他们的最新研究成果 Deep Speech 2。2014 年百度的首席科学家吴恩达刚刚入职百度不久,就带着一个 10 人的团队开发 Deep Speech,一套语音识别系统。
当时的研究重点在怎么提高嘈杂环境下的英语语音识别准确率。百度收集了 9600 个人 7000 小时的语音样本,添加了 15 种噪声,把样本扩充到 10 万小时。吴恩达说这套系统的错误率比同期的微软 Bing Speech、Google Speech API 等竞争对手低 10%。
2015 年,硅谷人工智能实验室又发表论文公布了 Deep Speech 2 ,这个系统开始学习汉语,也提高了对不同英语口音识别的能力。
到 2016 年,百度利用 Deep Speech 技术推出基于 Android 的语音输入应用 TalkType,强调输入法对“语音优先”。同一年,Deep Speech 2 还入选了《MIT 评论》评出的“ 2016 年十大突破技术”,入选的理由是“语音识别技术让智能手机变得更易操作”。
可以确定的是,百度之后还会花费更多的精力、更多的钱来支持人工智能的研究,这是李彦宏反复提及的最新故事。
上个月的财报电话会议上,李彦宏说会压缩百度糯米和百度外卖的补贴和营销费用、公司的未来在人工智能领域:“人工智能是改变互联网和传统工业的一个巨大机会。”
与之对应的是,百度 2016 年的营收涨了 6.3%、净利润少了三分之二。这是百度自成立以来,年度净利润首次下跌。而百度总收入中,依然有九成以上来自广告业务。
查看原文
 03:11
03:11








 05:44
05:44
 15:28
15:28
 08:04
08:04
 07:12
07:12
 09:02
09:02
 12:46
12:46
 13:10
13:10
 05:53
05:53
 06:37
06:37


