2017-04-01 19:04


扫码打开虎嗅APP


今天愚人节,我却在写严肃的东西。
上周我在虎嗅撰文致意吴恩达先生的离职,文中有两处提到谷歌翻译和百度翻译的对比:一处是说百度领先谷歌一年上线基于NMT神经网络的翻译系统,一处是说百度翻译的功能体验不如谷歌方便。巧的是几天之后,3月29日,谷歌翻译APP就重返中国大陆,引起一片欢腾。
此次谷歌优化了中国大陆地区的用(bu)户(yong)体(fan)验(qiang),有网友一边感叹,一边顺带怀念了谷歌全家。在段子手国度,此事很快演变成狂欢。人们拿出各种网络用语虐各家翻译软件,对比结果。
有人说,与谷歌翻译比,中国的翻译软件都是垃圾。也有反怼谷歌的。连谷大白话老师也上阵笑侃,拿出“不明觉厉”、“活久见”、“朝阳群众”、“啪啪啪”调戏谷歌,结果显示搜狗翻译更走心:

图片来自谷大白话文章
我觉得,这种事,各方都能找出几个例子来证明对方不行自己行。玩玩可以,当真了就不严肃。而且如果一味强调本地段子翻译准,就好比问对方茴香豆的“茴”字有几种说法,没什么实际价值。下面从技术本质角度来谈一谈。
翻译有多重要
巴别塔的典故传了不知道多少遍,可见翻译应该是个普世的工作。相比段子,我更想把技术人的想法“翻译”出来,谈谈国内各翻译巨头到底在和谷歌比拼什么。
夸张点说,“翻译”是人类信息文明的一切。
翻译背后是语言,语言的本质是符号,翻译就是符号的“编码”和“解码”。从一种语言翻译到另一种语言,就是对一种编码进行解码,再重新编码为另一套体系。
人类文明萌芽于符号(语言),赫拉利老师在《人类简史》中就强调,我们的智人祖先正是因为有了完备的语言,才能组织起来,击败身体强壮的尼安德特人。
现代文明无不基于符号的流通、利用。法国哲学家、符号学家鲍德里亚善于“翻译”当代生活。比如《消费社会》一书就把消费行为当作一种语言行为——你消费任何商品都是在表达某种意思。以往经济学家强调商品的使用价值和交换价值,鲍德里亚看到的是:
商品的物质“使用价值”不再重要,符号价值才重要。商品就是一种语言符号,消费成了一种言说。爱漂亮衣服,爱打折标签,你是凡客。吃西少肉夹馍、骑摩拜单车,你是创业狗。
今天的人类生活更是进入了“过度”符号化的时代。信息技术的发展可以描述为数据符号“侵袭”自然生活。想想,“宅男”、“二次元”的另一面就是“真实”生活退后,人们都生活在经过互联网编码后的世界里。
在这种时代,依赖符号运作的机器反而如鱼得水。因为它们的一切运行以符号(代码、函数、数据、标签)为基础。追溯计算机的发明,无非是人类把自己的意图翻译成机器可以理解的语言,促成机器的行动。一切信息都是“语言”,一切语言传递都是编码——解码。所以,“翻译”成了人工智能的关键。
观察当下AI大企业,技术线路都有清晰的两块,一块是图像识别、语音识别方向,一块是自然语言处理方向。从阿里的小黄图牛皮藓鉴别、讯飞的语音识别,甚至到百度的无人车,更多利用前者。从百度的搜索、翻译、度秘到阿里的机器客服、搜狗的输入法,更多基于后者。
二者是并列的关系吗?新任百度AI技术平台体系(AIG)负责人王海峰说过一段话:
相对于看、听和行动的能力,语言是人类区别于其他生物最重要的特征之一。视觉、听觉和行为不仅是人特有的,动物也会有,甚至比人强,但是语言是人特有的。AlphaGo对于普通人来讲是非常震撼的一件事情,我们也认为它是一个挺大的成绩。但是我们也不能忽略,它的规则是明确的,空间是封闭的,为围棋训练出来的程序下象棋就不好用。基本来讲是一个可解的问题,但是语言的很多问题是更难解的。
几天前坊间有文章谈及百度结构大调整,用了“王海峰的崛起”这样的小标题。我以为除了人事戏码,更可以从自然语言处理技术的重要性来理解。
机器翻译的进化
翻译,是“自然语言处理”的最重要分支,也是比较难的一支。人工智能在早期就是符号智能,人把各种规则变成符号算式输入机器。
最早的机器翻译方法就是基于词和语法规则。注意,人类并不了解大脑是如何工作的,但是依然工作的很好。反过来,人类自己语言熟练,不代表人能理解自己语言神经是怎么运作的。这就导致依赖人工规则的翻译软件笑话百出。即便现在,谷歌、百度也无法避免下面这样的翻译错误:
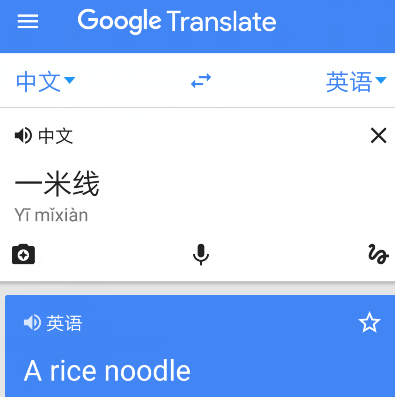
谷歌翻译

百度翻译
后来出现了“统计机器翻译方法”(SMT),也就是通过对大量的平行语料进行统计分析,找出常见的词汇组合规则,尽量避免奇怪的短语组合。
SMT翻译短语效果好,但是翻译句子就一般,直到近几年基于神经网络的翻译模型( NMT)崛起。 与AlphaGo的神经网络原理类似,NMT模拟人脑神经的层级结构,具有多层芯片网络,从基础层开始,每一层都对从上一层接收来的信息进行抽象,自动识别出语言的规则、模式。人不了解那些规则也没关系,反正交给机器了,只要结果正确即可。这就是端到端的翻译。
但是无论SMT还是NMT,前提是数据量要大,否则这样的系统也是无用的。简单的说,规则都是用函数表示的。假定给你一个未知函数f(x),我告诉你当x=5,f(x)=250,你能推导出函数式f(x)到底是什么吗?显然不能,可是如果给你100个x的具体值,及其对应的f(x)的值,你就可以通过数学学科里的逼近计算或者拟合函数推导出一个近似的函数f(x)。如果让机器去做这个推导,那就叫做“机器学习”。吴恩达的著名项目机器识别猫,就是输入了数百万猫的照片(x),告诉机器输出结果是猫这个语词,机器自己找到了图像形状到猫之间的推导规则。
在翻译界的常识是:机器翻译是突然爆发的,原因在于互联网带来的大数据。前谷歌工程师吴军在《智能时代》里说过,2005年,谷歌翻译在美国翻译界大赛上异军突起,秒杀老牌翻译公司,靠的就是更多的数据。因为谷歌有互联网,有网上人类提供的海量翻译例句。
十年后机器翻译第二次爆发。百度和谷歌一前一后上线NMT神经网络翻译系统。相比SMT聚焦于局部信息(短语),NMT更擅长利用全局信息——在对整个句子的信息解码、编码后,才生成结果。所以无论是语音识别还是翻译,你会发现句子长一点,机器识别和翻译的效果就会更好一点。
比如,语序问题是“翻译”头疼的问题,中文会把所有的定语都放在中心词前面,英文则会倒装,以往机器常混淆这个顺序。 NMT通过基于深度学习的神经网络,向人类较好地学习到语序模式,长句翻译比以往流畅多了。
在谷歌和腾讯工作过的吴军,认为在搜索、翻译领域,排在前面的就是谷歌和百度,别人很难追上这俩。因为他俩都是搜索引擎起家,先发优势明显。谁积累的数据多、算法训练成熟,谁就会赢者通吃。搜狗搜索技术不弱,且有微信搜索的优势,但是搜索结果依然被人诟病,也是因为起步晚,吃了马太效应的亏。
为了优化对人类语言世界的理解,谷歌和百度都构建了庞大的知识图谱,知识点之间不断生成的关系非后来者能追。

王海峰演讲中展示的,关于章子怡,机器自动产生的人物关系知识图谱。图片来自微信公号“AI科技评论”文章
段子手的调侃也抓住了一些本质——由于长期被排除在中国市场之外,谷歌缺少中文数据。去年谷歌的“你画我猜”游戏风靡一时,我看那其实就是一种数据采集和训练办法。玩家的每一次绘画和判定都是在教育谷歌的图像识别系统更精准。谷歌善于用喜闻乐见方式,既做到PR也做到技术提升。
谷歌翻译进入大陆,以后用的人越多,它的段子也可能翻译越准。所以比段子没什么好得意的。人类之间存在文化壁垒,但是对于没文化的机器,一切壁垒都会击穿,或者说一切文化他都能学会,从推特上的种族歧视言论到中国的神段子。真正要比拼的只有技术深度和产品体验的积累。
仅从技术角度来讲,我说一切都是翻译。语音识别也是一种翻译(从声音信号翻译到文字符号,或者从一种发音翻译到另一种发音)。机器人的文艺世界也离不开翻译。英特尔、百度等公司都推出过机器写诗游戏,经常真假难辨。

左边为百度写诗机器人的作品,右边为宋代诗人葛绍体所作
听王海峰介绍过机器写诗的原理。出乎很多人的意料,这个写诗系统正是用翻译模型来做的。在系统看来,当已经有了第一句诗,那么写作第二句诗的过程就是一个翻译过程——根据第一句寻找合适的对应语句:
首先根据用户 Query(诗歌题目)对要生成诗歌的内容进行规划,预测得到每一句诗的子主题,每一个子主题用一个单词来表示。这个过程和人类创作诗歌比较相似,诗人在创作之前往往会列出提纲,规划出每一句诗要描写的核心内容,然后再进行每句诗的创作。主题规划模型在生成每一句诗的时候,同时把上文生成的诗句和主题词一起输入来生成下一句诗。在这里,主题词的引入可以让生成的诗句不偏离主题,从而使整首诗都做到主题明确,逻辑顺畅。
基于主题规划的诗歌生成框架(写诗 2.0 版本)如图所示:
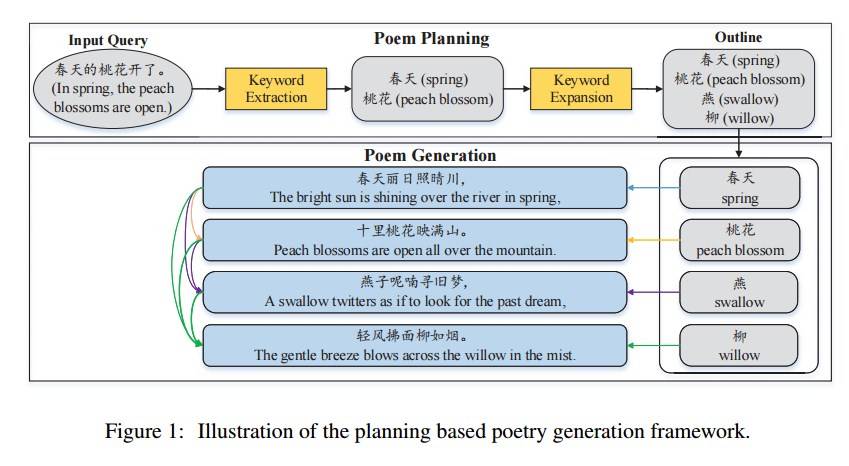
写诗 2.0 框架(来源于论文 Wang et al. 2016),有兴趣读者可以参考“机器之心”上这篇有趣文章 ,另外我不同意诗人写诗是先给每一句诗列提纲的。
翻译技术无处不在,这样我们才能从技术角度理解为什么亚马逊、谷歌、百度都无比重视智慧音箱产品,那就是一个人机对话系统,在人与机器世界之间充当翻译官角色。
还有“实物翻译”和“拍照翻译”功能,目前谷歌和百度在做。实物翻译主要是图像识别技术,拍照识别物体是什么并提供相关资料。拍照翻译,谷歌的产品体验做的好,拍照时候翻译结果直接融入实物,有种虚拟现实的效果。据传,百度翻译原本也打算这样做,但最终选择了更复杂的交互方式——需要用户用手指涂抹照片相应部位才会出现翻译效果。我觉得,除了要反思技术宅对手指的过分重视,产品体验也是一个需要悟性的领域。

百度工程师话不多,但是翻译的界面有点话多,谷歌界面则极简
善解人意,是翻译要求的品质,也是用户体验要求的品质。国内的技术型科技企业似乎都有产品体验弱的问题。比如讯飞的语音输入技术很强,但是输入法产品设计上就弱了点,全键盘首屏有些常用标点没有,也没有百度输入法和搜狗输入法那样方便调出的多重记录剪贴板。

讯飞手机输入法截图
我给双方都提过产品建议,谁会更快修改呢?
谷歌翻译APP重返大陆,想必会给国内企业带来冲击,对于改善用户体验是大好事。有竞争才有进步。
技术论剑
产品体验容易学,技术积累更是苦功夫。我相信技术人自己是绝不会只为段子翻译传神而沾沾自喜的。在自然语言处理方面,各家巨头都在比拼。
谷歌自不用说,2016年,谷歌人在《Nature》、《PNAS》、《JAMA》三大顶级科学期刊惊人地发表了218篇论文,绝大多数都关于人工智能领域。
去年微软亚洲研究院的秦涛和他的团队,在机器翻译领域提出“对偶学习法”,听起来很有创意。目的是:利用没有标注的数据。要知道,一般机器学习需要人类标注过的数据。比如一张猫的图片需要人工打上“cat”文字标签,然后拿去训练机器。但是人工标注成本高,探求如何让机器自主学习就成了未来发展方向。
秦涛团队认为:很多人工智能的应用涉及两个互为对偶的任务,例如从中文到英文翻译和从英文到中文的翻译互为对偶、语音识别和语音合成互为对偶、基于图像生成文本和基于文本生成图像互为对偶、搜索引擎中给检索词查找相关的网页和给网页生成关键词互为对偶等等。这些互为对偶的任务可以形成一个闭环,使从没有标注的数据中进行学习成为可能。通过设定一个精巧的原始任务模型,对偶任务可以自反馈自学习。(有兴趣读者可以参考微软亚洲研究院主页上的这篇文章 )
在自然语言的自主学习领域,最近百度也搞了个大新闻。余昊男、张海超、徐伟发表了一篇论文,提出了一个新的框架,把视觉识别和自然语言处理技术结合起来,让AI机器人在没有先验知识的情况下,自己学会理解人的命令并在迷宫中导航并定位物体。

他们把初始机器人称做婴儿智能体,用无数回合来迭代训练。在每个回合,只给出极少的像素和语言指令,通过梯度下降,端到端地从零开始训练,让AI在实验中自主学习环境的视觉表示,语言的句法和语义,以及如何在环境中给自己导航。比如要求智能体能够推广解释从未见过的命令和词汇。
我认为这是一项了不起的探索。为什么?前面我说人类进入了过度符号化世界,其实略有遗憾。过度符号化意味着脱离现实和实践。而这篇论文A Deep Compositional Framework for Human-like Language Acquisition in Virtual Environment旨在把AI从符号世界放入物理世界,认为只有物理世界的反馈才能让AI真正智能。研究团队认为:
复杂语言系统的发展是实现人类水平的机器智能的关键。语言的语义来源于感知经验,可以编码有关感知世界的知识。这种知识能够从一个任务迁移到另一个任务,赋予机器泛化的能力(generalization ability)。有研究认为,机器必须经历物理的体验,才能学习人类水平的语义[Kiela et al., 2016],即,必须经历类似人类的语言习得过程。然而,目前的机器学习技术还没有能以高效率实现这一点的方法。因此,我们选择在虚拟环境中对这个问题进行建模,作为训练物理智能机器的第一步。(译文来自“新智元”)。
有必要重温吴恩达的话:人工智能领域,很多创新都是中国人做出来的。
那么中国企业还缺什么?古人曰,做人要“世事洞明,人情练达”,改一下就可以送给中国AI企业:“技术洞明,产品练达”。技术好,还要转化为产品的体贴和话语的高度。当然,中国人总是与最好的比,要求很高,动力很足。
我听到百度基层的工程师朋友夸谷歌翻译好,我觉得,这是正确的态度。“翻译”乃国之重器,文明重器。想想严复当年对进化论的曲解翻译是如何影响中国救亡运动的?技术人或许也需要这样的高度。
