2017-05-23 15:53

虎嗅注:就在刚刚,柯洁以四分之一子惜败给了AlphaGo,虎嗅也在现场围观了比赛过程,现场的同事用“惜败”来形容,认为双方势均力敌,“在最后的统计结果上,AlphaGo 以四分之一子获胜,而这其中三又四分之一子是因为柯洁执黑子贴的。”结果已经不重要,相信会有不同的解读声音出来。以上作为一个信息铺垫,下面看这篇角度特别的文章,转载自微信公众号“待字闺中”,虎嗅获授权转载。
记得小时候,城里来了个机器人展,于是买了门票,兴致勃勃的去看,有踢球的,有打球的,有玩游戏的,有讲故事的,有谈情说爱的,等等。我最感兴趣的是一个能和我对话的机器人,她会问我问题,也会回答我的问题,好神奇呀。天真无暇的我,玩的很开心,心中有了追求科学的梦想。但是,后来有人告诉我,其实当时每个机器人里面都是藏着一个真人,于是心中咯噔一下,有些沮丧,幼小的心灵就这么受伤了。

现在,人工智能取得了飞速发展和进步,儿时的记忆的场景已经完全反转了。看看 AlphaGo 和李世石的围棋比赛,其中最大的看点和吐槽应该是图片中的石头人黄博士,这时,机器人走到了后台,充当了智能的核心,而人,也就是黄博士,只是起到了人机交互的媒介。

看来,这次和柯洁的比赛,依然没有改变这种现状,因为现状太难改变了。还是黄博士,而不是黄博士化身的机器人,我是多么期待真正的机器和人下围棋。

这么来说,有些异样,为什么这么聪明的 AlphaGo,不真正做成一个机器人,能看棋盘,能下棋子,能思考,还能说笑,会不会更好玩。其实,有时看起来简单的事情,让机器来做不一定简单,这是后话,不啰嗦了。
好了,段子讲完了,该言归正传了。免得被唾沫淹死,首先申明一下,AlphaGo 确实很厉害的,也不简单。但是,为什么又说,AlphaGo 挺“笨”的呢?
我们知道,围棋的搜索空间很大,有3的19x19次方个状态,要在这么大的空间去找最优算法,一个一个看是不可能的,所以被认为人类智能的一个高点,解决时需要优化搜索。人是根据一些输入空间和参数较少的模式识别来记忆和搜索,而机器采用的却是大数据,大记忆和大计算来实现的。说到 AlphaGo 后面的智能和算法,就不能不说深度学习(DL),强化学习(RL),和蒙特卡洛树搜索(MCTS)。
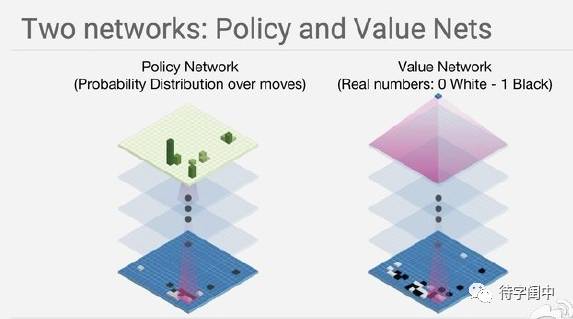
深度学习,主要用来学习和建立两个模型网络。一个是评测现在的棋盘状态如何,也就是说给当前的棋盘状态打个分,评估一下赢的期望值,它就是价值网络(Value Network)。输入是棋盘19x19每个点的状态,有子或无子,输出是赢的期望值。按理说,如果要是有一个聪明的数学家或是机器足够聪明,说不准他马上就能在黑板上写一个高级的数学公式。很遗憾,现在还没有,所以,只能用多层的神经元网络来近似表示这个高级的函数。这么来说,是不是有点“笨”。
二是根据现在的棋盘状态,决定下一个棋子该如何走才能有最大的赢的概率,它就是 AlphaGo 的策略网络(Policy Network)。也就是说,给一个19x19的棋盘状态,在所有空的地方,哪个是最佳的选择,会有最大的赢率。同样,也可以用一个函数来描述,输入是当前棋盘状态,输出是每个空处和它期望的赢的期望值,但这个函数还没有一个高级的数学公式,所以,最后也求助于多层神经网络。
但是,这两个深度学习网络模型,怎么训练出来的呢?这时,不得不说随机梯度下降(SGD),这个“笨”办法。
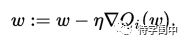

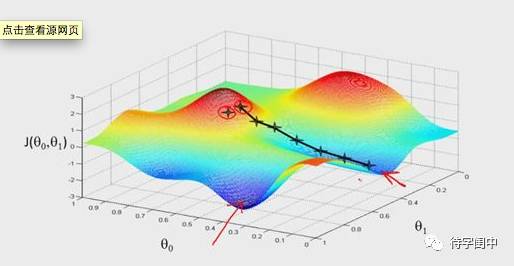
为了求一个目标函数的最优值,复杂一点的,不能像解一个二次方程一样,用一个简单的公式就能得到方程的解。

对于,围棋这种深度学习要求的目标函数,没有一个简单的求解公式,那怎么办?只能求助于迭代,随机梯度下降迭代(SGD),就像爬山,每往上走一步,都是接近山顶一点点,或者叫摸着石头过河。毕竟机器的计算能力强,这种数值计算,是它的强项,就让它拼命的算,直到算到一个还算满意的结果。这回知道了吧,为什么 GPU 这种东西来做这种重复简单的计算。这么说来,是不是有点“笨”。就像我们一个公式不会解时,就从1开始带入计算,看看是不是满足条件。或是,做选择题有四个选项,每个选项代入公式算一下。
这些玩意儿,都是线下用大量数据,做大量的辛苦计算得到的,赚的是不是辛苦钱呀。那么,在真正下棋的时候,用它们就能减少或是已经预算了很大的搜索空间,不好的状态,不好的棋子,就不用花时间去看了。在平时不比赛的时候,机器也不会闲着,毕竟还有很多状态没有尝试过,毕竟那些暂时认为不好的棋子不一定最后不好,那怎么办?

AlphaGo 有自己的想法,它求助于强化学习,也就是self-play,或是左右手互搏,来提前尝试更多的搜索空间,减少未知空间,同时通过深度学习的网络模型记录下来,提高前面两个模型网络的效果,那么真正下棋的时候就能用上。这就是平时多努力,老大不白头。这种劳模的精神,在现实生活中,有时会不会被认为时有点“笨”,只会死干。
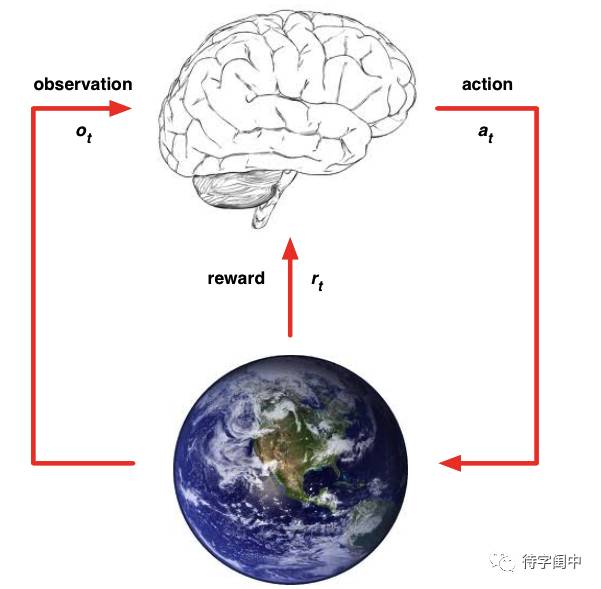
在强化学习的算法中,也需要大量的迭代计算,以求得到最优的期望值,也就是达到收敛。这种“笨”办法,效果还不错。
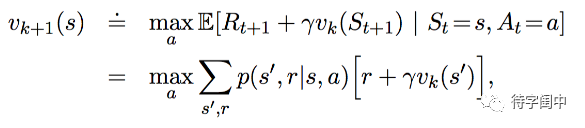
有了这些,机器就能玩的可以了,但是,毕竟还有很多的空间没有尝试过,也不能保证当前的模型预测的每一步都是最优,因而,AlphaGo 心里不是特别有底气。那怎么办?这时,机器需要求助于蒙特卡洛了,就是在下棋的过程中,以当前的状态为起点,在有限的时间内,尽量多的再探索一些搜索空间。这个探索的办法,就是暴力采样,一个一个的试,这么看来,是不是有点“笨”。
具体来说,“蒙特卡洛树搜索”是一种启发式的搜索策略,能够基于对搜索空间的随机抽样来扩大搜索树,从而分析围棋这类游戏中每一步棋应该怎么走才能够创造最好机会。来个通俗的解释,假如筐里有100个苹果,让你每次闭眼拿1个,挑出最大的。
于是你随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……你每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但你除非拿100次,否则无法肯定挑出了最大的。
这个挑苹果的算法,就属于蒙特卡罗算法,尽量找好的,但不保证是最好的。想像这个拿苹果的场景,是不是就感觉累,而且有点“笨”,然而,对于机器来说,它可是要做巨多的这种尝试。确实是劳模。
好了,好了,AlphaGo 如果你不“笨”,能和人类一样,触类旁通就牛逼,能不能玩一些人类很容易适应的新玩法,还是围棋,比如,将棋盘改成一个比19大的,或是改变下棋时的一个小小规则,这样,也许能更好得证明不“笨”。这个场景,涉及到另外的一个机器学习领域,就是迁移学习。人类,好像特别擅长。
这么看来,你是不是也感觉 AlphaGo 其实挺“笨”的,这个“笨”,其实是人类把自己能解决此类问题,用的最聪明的“笨”办法教给机器了。至少到现在为止,AlphaGo,在还没有像爱因斯坦的E=MC2的美妙数学公式发明前,也是最聪明的了。

期待不久的将来,AlphaGo 能“抛弃”人类教他的“笨”办法,和爱因斯坦一比高下。那时,让人类真正体验到你的自有的智慧和聪明。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。