




2023-09-05 18:21

扫码打开虎嗅APP


本文来自微信公众号:学术头条(ID:SciTouTiao),作者:闫一米,编辑:学术君,原文标题:《ChatGPT的这项核心技术要被替代了?谷歌提出基于AI反馈的强化学习》,题图来自:视觉中国(谷歌AI负责人Jeff Dean)
与基于人类反馈的强化学习(RLHF)相媲美的技术,出现了。
近日,Google Research 的研究人员提出了基于 AI 反馈的强化学习(RLAIF),该技术可以产生人类水平的性能,为解决基于人类反馈的强化学习(RLHF)的可扩展性限制提供了一种潜在的解决方案。
相关论文以“RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback”为题,已发表在预印本网站 arXiv 上。

RLHF:导致不准确或有害行为
RLHF 是一种利用人工指导来微调预先训练好的大型语言模型(LLMs)的方法。它由三个相互关联的过程组成:反馈收集、奖励建模和策略优化。
其中,反馈收集负责收集人类对 LLMs 输出的评价。然后利用这些反馈数据,通过监督学习训练奖励模型。奖励模型旨在模拟人类的偏好。随后,策略优化过程使用强化学习循环来优化 LLMs,从而产生获得奖励模型有利评价的输出。这些步骤可以迭代执行,也可以同时执行。
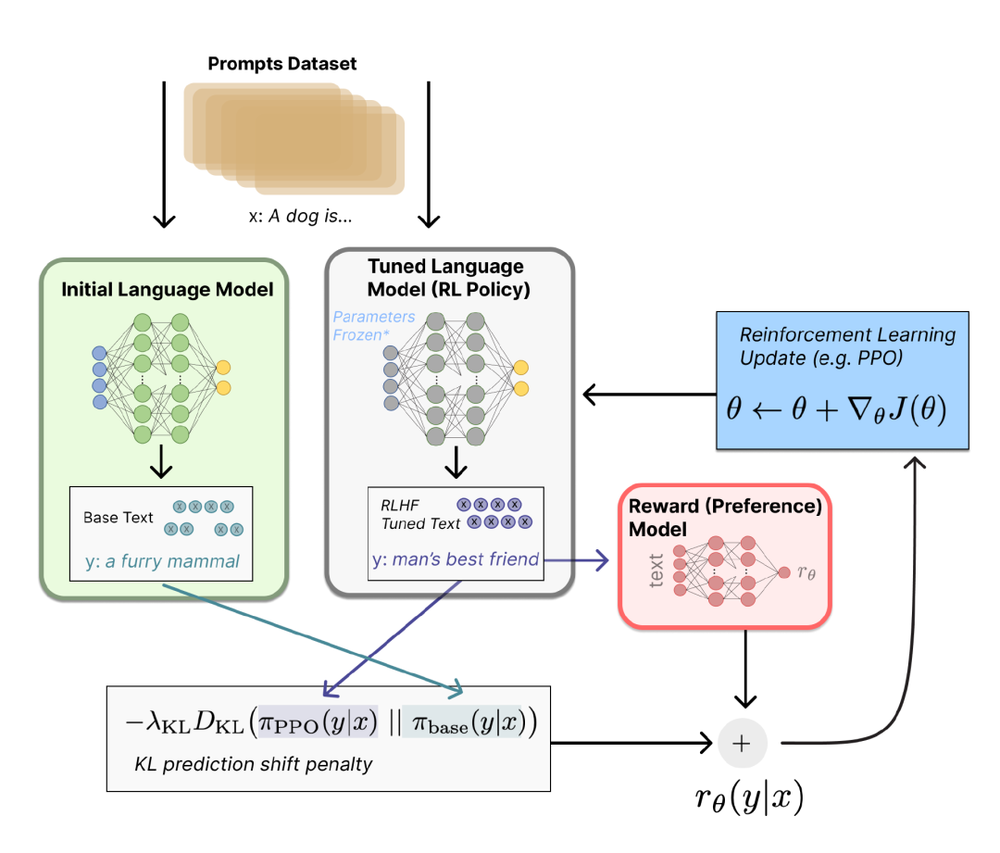
与传统的 RL 方法相比,RLHF 的关键优势在于能更好地与人类的意图保持一致,以及以未来的反馈为条件进行规划,从各种类型的反馈中进行流畅的学习,并根据需要对反馈进行整理,所有这些都是创建真正的智能代理所不可缺少的。
另外,RLHF 还允许机器通过抽象人类的价值来学习,而不是简单地模仿人类的行为,从而使代理具有更强的适应性,更强的可解释性,以及更可靠的决策。
目前,RLHF 已经在商业、教育、医疗和娱乐等领域得到了广泛的应用,包括 OpenAI 的 ChatGPT、DeepMind 的 Sparrow 和 Anthropic 的 Claude 等。
然而,基于 RLHF 的 AI 模型有可能做出不准确或有害的行为。而且,收集人类偏好数据作为反馈的成本很高,人类标注者之间的分歧会给训练数据带来差异,在基本事实模糊的情况下会造成混乱(如道德困境)。另外,人类在 RLHF 中的反馈往往被限制在提供有限信息的偏好排序的形式中,从而限制了适用性。
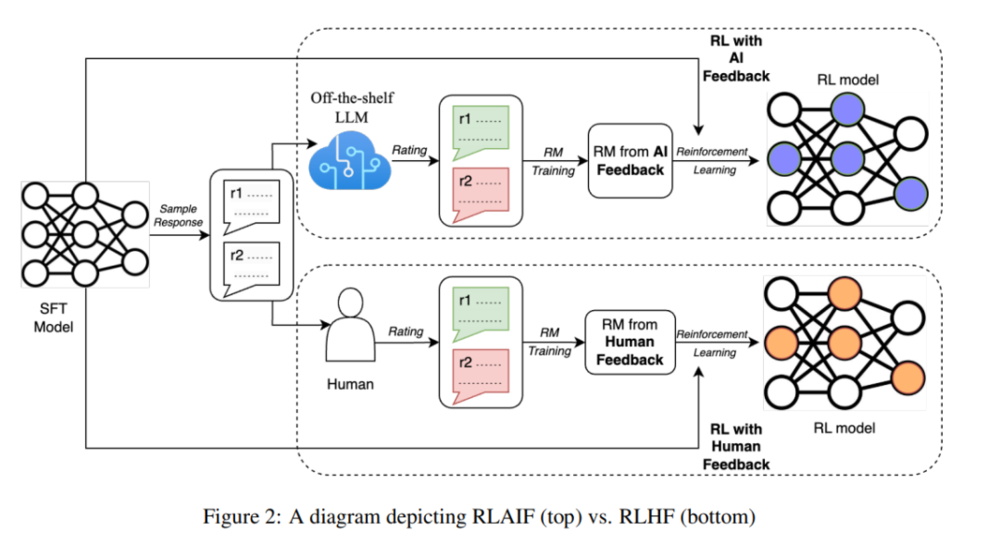
RLAIF vs. RLHF
在这项工作中,RLAIF 展现出了解决 RLHF 难题的潜力。
研究人员使用了一个通用的 LLMs 模型来对候选项对之间的偏好进行标注,该模型预先经过训练或根据通用用途进行过微调,但并没有为特定的下游任务进行微调。
给定一段文本和两个候选摘要,LLMs 被要求评价哪个摘要更好。其输入结构如下:
1. 前言——介绍和描述当前任务的指示;
2. 少量样例——一个文本示例,一对摘要,思维链(CoT)的逻辑依据,以及一个偏好判断;
3. 待标注样本——一个文本和一对待标注的摘要;
4. 结尾——用于提示 LLMs 的结束字符串。
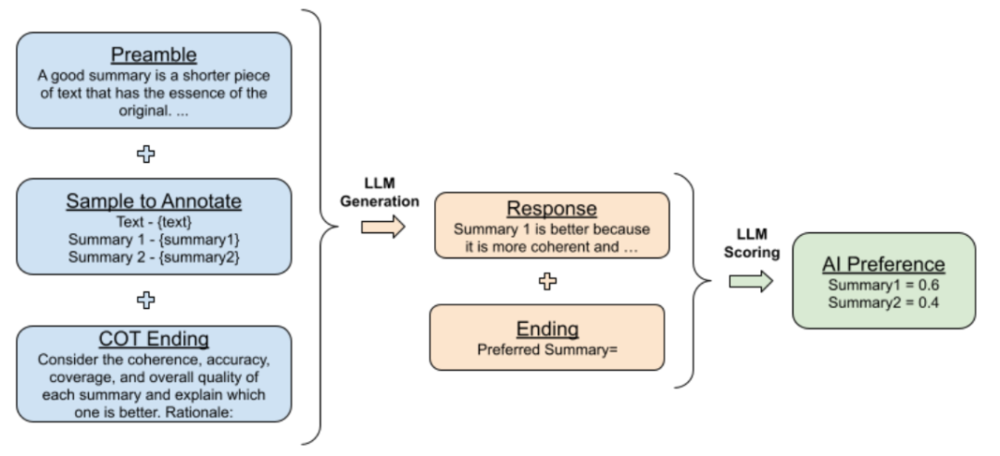
在 LLMs 接收到输入后,研究人员获得生成 token“1” 和“2”的对数概率,然后计算 softmax 以得出偏好分布。
他们进行了两种类型的前言实验。在“Base”实验中,简要地询问了“哪个摘要更好?”,而在“OpenAI”实验中,他们模仿了 OpenAI TLDR 项目中由人类偏好标注者生成的评分指示,这些 token 包含了关于构建强大摘要所需的详细信息。
此外,他们还进行了上下文学习实验,通过添加一些手动选择的示例来提供更多上下文,这些示例覆盖了不同的主题。
在 LLMs 标记偏好之后,研究人员训练一个奖励模型(RM)来预测偏好。随后,又使用了三个指标来评估 AI 标签对齐度、两两准确率和胜率。
实验结果表明,在无需依赖人工标注者的情况下,RLAIF 可作为 RLHF 的一个可行替代选择。在人类评估中,RLAIF 在基线监督微调策略之上的受欢迎程度达到了 71%,而与之相比,RLHF 在基线监督微调模型策略之上的受欢迎程度为 73%。
此外,研究还直接比较了 RLAIF 和 RLHF 在人类偏好方面的胜率,结果显示它们在人类评估下具有相同的受欢迎程度。研究还比较了 RLAIF 和 RLHF 的摘要与人工编写的参考摘要。在 79% 的情况下,RLAIF 摘要优于参考摘要,而 RLHF 在 80% 的情况下优于参考摘要。
然而,尽管这项工作凸显了 RLAIF 的潜力,但也存在一些限制。
首先,该研究仅关注了摘要任务,其在其他任务上的泛化性能尚不明确;其次,与人工标注相比,研究未充分评估 LLMs 推理的成本效益;此外,也存在许多未解决的有趣问题,例如将 RLHF 与 RLAIF 相结合能否超越单一方法,直接利用 LLMs 分配奖励的效果如何,提高 AI 标签对齐性是否能够转化为改进的最终策略,以及使用与策略模型相同大小的 LLMs 标注者能否进一步改进策略。
不可否认的是,本次研究为 RLAIF 领域的深入研究奠定了坚实的基础,期待未来该领域能够取得更出色的成果。
参考链接
https://arxiv.org/abs/2309.00267
https://bdtechtalks.com/2023/09/04/rlhf-limitations/
本文来自微信公众号:学术头条(ID:SciTouTiao),作者:闫一米,编辑:学术君

