2023-09-14 15:39


扫码打开虎嗅APP

本文来自微信公众号:硅星人Pro(ID:gh_c0bb185caa8d),作者:Nikki,编辑:VickyXiao,原文标题:《AI开卷视频:一句话一张图就能出大片,“人均诺兰”时代不远了》,头图来自:Runway
当我们还在讨论ChatGPT和AI绘画时,AIGC的圈子里又刷新了一些新玩法。
只见大叔打个响指,摇身一变成贵族,穿越到了17、18世界的欧洲宫廷。

随后,又一个响指,变成了“星球崛起”里的主角,在残垣断壁的战场上穿梭。

这还不算最神奇的,紧接着一个转场,打响指的人物从老爷子变成了健美女性。

这个爆款视频正是通过AI初创公司Runway制作而成的,他们的AI视频生成产品Gen-1和Gen-2已全面开放,任何人都可以注册一个账号免费尝试。目前网站上可试用功能比较多,其中应用最多的是:文字+图像生成视频(Text + Image to Video)、图像生成视频(Image to Video),升级版效果比之前更好。
于是很多网友探索出了用Midjourney生成图像,然后用Gen-2把图像转化为视频的玩法。

甚至在此基础上,还能融合连贯的剧情和统一的艺术风格,再对视频画面进行一定编辑,一个电影预告片就诞生了,让我们一起来看看用Gen-2整活,究竟可以出多少脑洞?这些视频创意又是如何生成的?又有哪些技术原理呢?
一、令人惊叹的《创世纪》电影预告片
由 Nicolas Neubert创作的《创世纪》电影预告片的视觉震撼力吸引了许多人,据了解,这是作者使用Midjourney和Runway制作出来的。再将其进行剪辑优化,最终成为一条专业的预告片。

很多人在推特上询问Neubert的制作步骤,他后续也在推文中详细介绍了灵感来源和创作过程。首先他是从配乐开始构思整个故事,然后在剪辑时将视觉效果与音乐节拍进行匹配。
对于具体的故事情节,他想一步步增强紧张感,所以分成了3个部分来完成:背景介绍、制作冲突、引入高潮。

第一步就是起草文案,将“Sharing everything, living with the consequences, and then calling humanity up for action”作为主题,通过这个主题来定后面的整体基调和声音,然后就可以围绕这些主题去生成场景,在阅读观看大量关于军事科技、战斗主题的科幻剪辑后,最后确认了故事线,为了使影片看起来更加有深度,他还添加了三个带有发光护身符孩子的镜头,提高故事深度。
第二步是用Midjourney生成一致的图像。为了最大限度地保持一致性,他拟了一个提示词模板,可以在预告片的每个镜头中重复使用。
“Cinematic Shot, Crystal Object in the middle of circular room, star wars warfare, earthy naturalism, teal and yellow, frostpunk, interior scenes, cinestill 50d --ar 21:9 —style raw”
“电影镜头,圆形房间中间的水晶物体,星球大战战争,朴实的自然主义,青色和黄色,霜朋克,室内场景,cinestill 50d --ar 21:9 —风格原始”

closeup shot of raising a blade, detailed face, star wars warfare, cinematic contour lighting, in the style of detailed crowd scenes, earthy naturalism, teal and yellow, frostpunk, interior scenes, cinestill 50d --ar 21:9 —style raw

Huge laser cannon beam, star wars warfare, cinematic contour lighting, in the style of detailed crowd scenes, earthy naturalism, teal and yellow, frostpunk, interior scenes, cinestill 50d --ar 21:9 —style raw

Humans attached to computer by wired, detailed face, star wars warfare, cinematic contour lighting, in the style of detailed crowd scenes, earthy naturalism, teal and yellow, frostpunk, interior scenes, cinestill 50d --ar 21:9 —style raw
使用“Strong Variations”功能也很有帮助。这使得创建多样化场景变得容易,同时还能保持前一个变体的色调。女战士的场景可以转变为普通市民、网络黑客或战斗场景,而无需生成新的提示。

第三步是用Runway生成动画。勾选“Upscaled”可以提升画质(这个选项需要付费使用),但可能面部处理得不好,所以他通常使用标准质量,基本都是用图像直接生成一个个视频镜头。
第四步是在CapCut(免费软件)上进行后期剪辑。他将生成的镜头卡着音乐节奏拖入时间轴,慢慢拼凑出完整的故事。同时还要对2-3个剪辑包进行颜色匹配,使得它们看起来更像一个电影场景。

最终,他花费了大约7个小时完成这部预告片,其中在Midjourney输入了316个提示词,放大了128个图像,在Runway生成了310个视频片段,预告片使用了44个片段,相当于每分钟的制作成本是125美元。
二、火爆外网的AI影片“芭本海默”
最近在外网有个词特别火:“芭本海默”(Barbenheimer),是由网友用AI生成的《芭比》和《奥本海默》拼接而成的电影预告片——《Barbenheimer》(芭本海默)在网络上广泛传播。

视频作者表示此预告片由Midjourney和Runway的Gen-2合成,配音也是由AI生成的玛格特·罗比和马特·达蒙的声音。更令人惊讶的是,整个制作过程他只花了4天!
万万没想到的是,这些超燃超真实的预告片画面竟然都是用AI生成的,这些预告片中的画面皆是由Midjourney生成,然后再通过Runway的Gen-2来实现让画面动起来的视觉效果。


而此次爆炸性效果让更多人尝试用Midjourney和Gen-2混搭,也二创出了超多优秀作品。由于Gen-2生成的视频时长比较短,甚至还有网友找到了Gen-2输出更长时间视频的方法,就是用Midjourney生成的图像作为初始图像,然后使用Gen-2输出的最后一帧作为下一张的图像提示。

三、AI视频打破次元壁,让梗图动起来
之前也有一些工具能够给图像添加动效,但都只是让图像的某些部分动起来,例如让老照片说话,前段时间DragGan的技术再现,都是通过对图像的部分进行移动,而此次Runway可以做到让AI来根据图像内容想象动态场景,其创意脑洞可以说是无限的。
许多网友也进行了二次创作,把一些搞笑梗图融合起来,就是一部电影故事。例如这位网友用Midjourney和Gen-2生成了一个电影短片,让美国知名政治人物、企业家齐上阵,出演由恶魔伪装的人类。
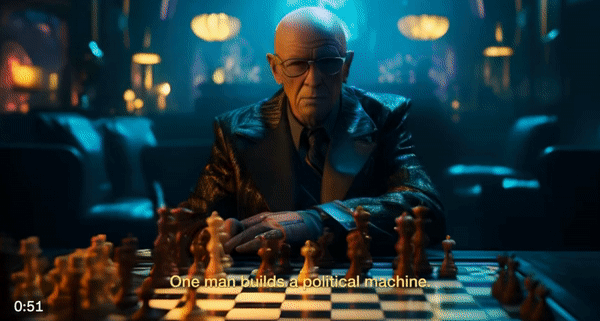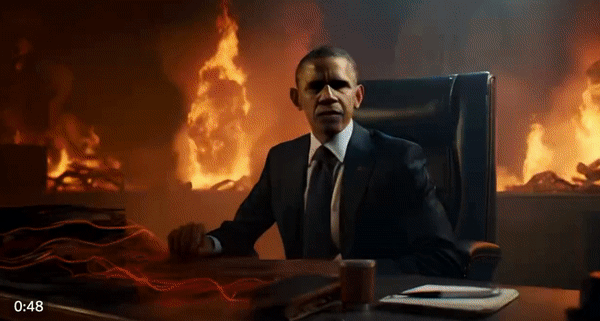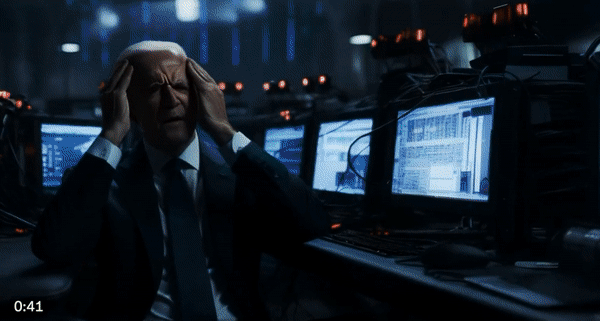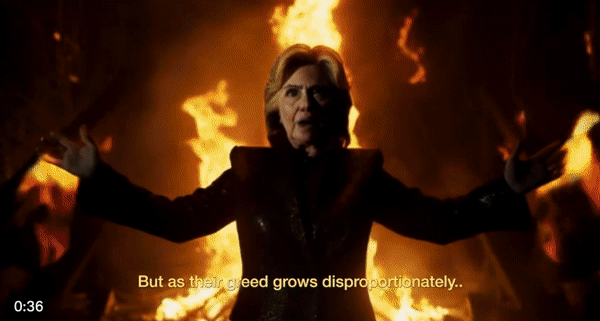
我们可以在片中看到许多熟悉的面孔:特朗普、拜登、希拉里、马斯克、扎克伯格……他们似乎在共同密谋着什么邪恶计划。
借助AI,人们可以发挥想象,创造出原本现实中不存在的人物动作和故事情节。除了电影和整活视频之外,还有人利用ChatGPT写脚本,Midjourney生成图像,Runway Gen-2生成视频,然后再通过剪辑组合,就是一个高质量的广告片。

四、视频生成技术发展的关键阶段
看到这里,你肯定要感叹AI视频的技术已经这么成熟了,甚至让好莱坞电影制作方都要开始担忧了。但其实目前Runway的视频生成还是不能一步到位,无法生成更长片段的视频,并且人物面部、动作变形问题等还是不太可控。如果真的要制作一个完整的电影或者广告片,你可能要花费更多的时间去不断尝试使用它。
视频生成的技术发展至今,其实大致可以分为图像拼接生成、GAN/VAE/Flow-based生成、自回归和扩散模型生成几个关键阶段。随着深度学习的发展,视频生成无论在画质、长度、连贯性等方面都有了很大提升。但由于视频数据的复杂性高,相较于语言生成和图像生成,视频生成技术当前仍处于探索期,各类算法和模型都存在一定的局限性。
Runway就是使用的主流模型Gen,Gen模型通过潜在扩散模型学习文本-图像特征,可以根据给定的文本提示或参考图像生成新的视频,或根据原始视频+驱动图像进行视频风格转换等多种任务。模型在视频渲染和风格转换方面具有较好的表现,生成的视频艺术性和图像结构保持能力较强,因此可以更好地适应模型定制要求,但Gen模型在生成结果的稳定性方面仍然存在局限,还需要技术去不断探索精进,按现如今AI技术的发展,相信这些局限性在不久的将来就能解决。
除了Runway,市面上还有一些支持文字生成视频、图片生成视频的工具,比如ZeroScope、PikaLab、Kaiber等,以目前AI视频的处理效果来看,是否能达到商业应用要求,还有待考究。
本文来自微信公众号:硅星人Pro(ID:gh_c0bb185caa8d),作者:Nikki,编辑:VickyXiao

 07:01
07:01









 34:59
34:59
 04:39
04:39
 03:40
03:40
 05:03
05:03
 08:42
08:42
 07:37
07:37
 08:28
08:28
 12:23
12:23
 32:10
32:10



