2023-09-19 20:29


扫码打开虎嗅APP


本文来自微信公众号:GenAI新世界(ID:gh_e06235300f0d),作者:薛良Neil,题图来自:《她》
从理论到实践,大语言模型LLM完全体的形态是什么样子的?
很多人会说是基于对自然语言的深刻理解,但这一点目前OpenAI的GPT系列已经做得很好。也有人在讨论AI Agent在实践上的可能性,但目前这种讨论也没有脱离对自然语言的处理范畴。
生成式AI实际上包括了两个方面,大语言模型是其中之一,它着重理解人类的语言,而更广泛的所谓AIGC应用,实际上指的是以扩散模型为代表的跨模态转换能力,也就是所谓的文生图、文生视频等等。
那么把这二者结合起来呢?在许多人眼中,这实际上就是下一代GPT,或者说GPT完全体的样子。最近出现在预印网站arxiv上的一篇来自新加坡国立大学计算机学院的论文引起了人们的注意,因为这篇论文设计的NExT-GPT模型试图进行全面的模态转换。

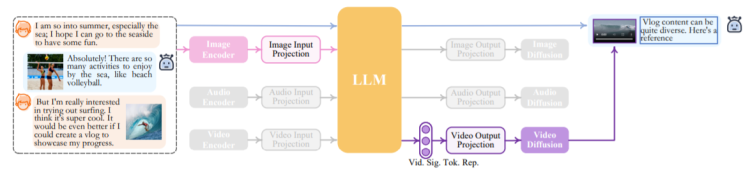
从上图中我们可以看到,NExT-GPT模型的输入和输出端都能生成包括文字、图片、音频和视频在内的多种模态形式。其中输出端除了文字以外均使用了对应不同模态的扩散模型。输入和输出之间的介质转换依靠大模型进行。
NExT-GPT模型的样式,实际上不仅符合目前人们试图把生成式AI的两股力量:大语言模型和扩散模型结合起来的趋势,甚至某种程度上说也符合人的直觉——人类大脑正是依靠对多种模态的自由转换和交互理解来认识这个世界的。
特别值得指出的是,所谓多模态转换与大语言模型能力的结合,并不是简单地用prompt方式在彼此之间“搭桥”,而是真正把多模态数据(向量)同语言数据结合起来,这个过程被真正拉通后,等于大模型可以不仅学习从而理解人的语言,还能把这种能力扩大到更多模态去,这种结合一旦成功,将会带来AI能力质的飞跃。
NExT-GPT结构一览:两个突破点
据说Google 和OpenAI的GPT5都在进行类似的研究。在这之前,让我们首先来看看NExT-GPT模型是怎么做到的吧。
总的来说,NExT-GPT模型是把大模型与多模态适配器以及扩散模型解码器连接了起来,仅仅在投影层进行了1%的参数调整。论文的创新之处在于创建了一个名为MosIT的模态切换调整指令,以及一个专门针对跨模态转换的数据集。
具体来说,NExT-GPT由三层组成,第一层是各种成熟编码器对各种模态输入进行编码,然后通过投影层映射到大语言模型可以理解的形式。第二层这是一个开源的大语言模型,用来进行推理。值得一提的是,大语言模型不仅会生成文本,还会生成一个独特的标记,用来指令解码层输出具体什么模态的内容。第三层则是将这些指令信号经过投影,对应不同的编码器生成对应的内容。
为了降低成本,NExT-GPT利用了现成的编码器和解码器,为了最大限度减轻不同模态内容转换时出现的“噪声”,NExT-GPT利用了ImageBind,它是一个跨模态的统一编码器,这样NExT-GPT不需要管理诸多异构的模态编码器,而是可以统一将不同模态投影到大语言模型中去。
至于输出阶段,NExT-GPT广泛使用了各种成熟的模型,包括用于图像生成的 stable diffusion,视频生成的Zeroscope,以及音频合成的AudioLDM。下图是论文中一个推理过程的一环,可以看到文本模式和信号标记决定了模态被如何识别、触发以及生成,灰色的部分是没有被触发的模态选项。
这其中涉及到了一个不同模态之间语义理解的问题,因此对齐是必不可少的。不过由于结构上比较清晰,实际上NExT-GPT的对齐是很好操作的。作者设计了一个三层的耦合结构,编码端以大模型为中心对齐,解码端则与指令对齐。这种对齐放弃让扩散模型与大语言模型之间执行完整规模的对齐过程,而是仅使用文本条件编码器,在最小化了大模型模式信号标记与扩散模型文本之间的距离后,对齐仅仅基于纯粹的文本进行,因此这种对齐的量级很轻,只有大概1%的参数需要调整。
考虑到需要让NExT-GPT具备准确地跨模态生成和推理的能力,论文还引入了MosIT,也就是Modality-switching Instruction Tuning模式切换指令微调,它的训练基于5000个高质量样本组成的数据集。
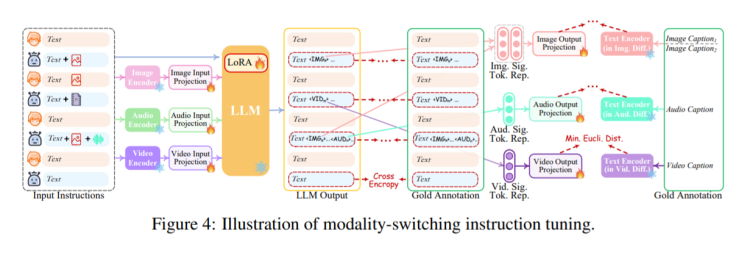
具体的训练过程有些复杂,就不展开细说了,总的来说MosIT可以重构输入和输出的文本内容,让NExT-GPT能够很好理解文本、图像、视频和音频的各种模式组合中的复杂指令,这就十分接近人类理解和推理的模式。
完全体要来了吗?
目前NExT-GPT还具有许多的弱点,作者在论文中也提到了不少,比如非常容易想到的,四种模态对于真正的多模态完全体大模型来说种类还是有点太少,训练MosIT的数据集的数量同样有限。
另外,作者还正努力试图通过不同尺寸的大语言模型来让NExT-GPT适应更多场景。
相比尺寸来说,另一个棘手的问题更为现实——尽管NExT-GPT展现出一种关于多模态能力的强大前景,但其实以扩散模型为代表的AIGC能力目前所能达到的水平依然有限,这影响了整个NExT-GPT的性能。
总的来说,多模态AI有着非常诱人的前景,因为它和应用场景以及用户的需求结合得更紧密,在大模型赛道目前热度略有下降的情况下,多模态AI给人以巨大的想象空间。NExT-GPT作为一个端到端的多模态大模型,实际上已经具备了多模态AI的雏形,论文中关于参数调优对齐以及使用MosIT进行模型推理能力强化的思路让人印象深刻,因此我们甚至可以说,迈向完全体AI的道路,此刻已经有人迈出了第一步。
本文来自微信公众号:GenAI新世界(ID:gh_e06235300f0d),作者:薛良Neil

