




2023-10-12 16:50

扫码打开虎嗅APP


第69 届 IEEE 国际电子设备年会将于 12 月 9 日开幕,会议预告片显示,研究人员一直在扩展多项技术的路线图,特别是那些用于制造CPU和GPU 的技术。本文来自微信公众号:半导体行业观察 (ID:icbank),作者:编辑部,题图来自:unsplash
由于芯片公司无法通过在二维上缩小芯片功能来继续增加晶体管密度,因此他们通过将芯片堆叠在一起进入了三维。现在他们正致力于在这些芯片中构建晶体管。接下来,他们很可能会通过使用二硫化钼等2D 半导体设计 3D 电路,进一步进入三维领域。
所有这些技术都可能服务于机器学习,这是一种对处理能力日益增长的需求的应用程序。但 IEDM 上发表的其他研究表明,3D 硅和 2D半导体并不是唯一能让神经网络保持正常运转的东西。
3D芯片堆叠
通过堆叠芯片(在本例中称为小芯片Chiplet)来增加可以挤入给定区域的晶体管数量,这既是硅的现在,也是未来。一般来说,制造商正在努力增加芯片之间的垂直连接的密度。但也有一些并发症。
一是改变了芯片互连子集的布局。从 2024 年末开始,芯片制造商将开始在硅下方构建电力传输互连,而将数据互连留在上方。这种被称为“背面供电”的方案会带来芯片公司正在研究的各种后果。
看来英特尔将在本届的IEDM讨论背面电源对 3D 设备的影响。IMEC 将研究称为系统技术协同优化(STCO)的 3D 芯片设计理念的影响。(这个想法是,未来的处理器将被分解为基本功能,每个功能都将位于其自己的小芯片上,这些小芯片将采用适合该工作的完美技术制成,然后这些小芯片将被重新组装成一个系统使用 3D 堆叠和其他先进封装技术。)同时,台积电将解决 3D 芯片堆叠中长期存在的问题——如何从组合芯片中排出热量。
顾名思义,所谓3D芯片堆叠,是将一个完整的计算机芯片(例如 DRAM)放置在另一个芯片(CPU)之上。结果,电路板上原本相距几厘米的两个芯片现在相距不到一毫米。这降低了功耗(通过铜线传输数据是一件很麻烦的事情),并且还大大提高了带宽。
IEEE也表示,当前每一代处理器的性能都需要比上一代更好,从最基本的角度来说,这意味着将更多的逻辑集成到硅片上。但存在两个问题:一是我们缩小晶体管及其组成的逻辑和存储块的能力正在放缓。另一个是芯片已经达到了尺寸极限,因为光刻工具只能在约 850 平方毫米的区域上形成图案。
为了解决这些问题,几年来,片上系统开发人员已经开始将其更大的设计分解为更小的小芯片,并将它们在同一封装内连接在一起,以有效增加硅面积等优势。在 CPU 中,这些链接大多是所谓的 2.5D,其中小芯片彼此相邻设置,并使用短而密集地互连进行连接。既然大多数主要制造商已经就 2.5D 小芯片到小芯片通信标准达成一致,这种类型的集成的势头可能只会增长。
但要像在同一芯片上一样传输真正大量的数据,需要更短、更密集的连接,而这只能通过将一个芯片堆叠在另一个芯片上来实现。面对面连接两个芯片意味着每平方毫米要建立数千个连接。这也催生了3D芯片堆叠。
Synopsys在一篇博客文章中指出,堆叠芯片之间的数据传输通过集成在底部芯片中的 TSV 进行。这些 TSV 是垂直运行的物理柱,由铜等导电材料制成。将堆叠芯片粘合到单个封装中而不是 PCB 上的多个封装中,可将 I/O 密度提高 100 倍。采用最新技术,每比特传输能量可降低至 30 倍。

至于背面供电,按照IEEE所说,向数十亿个晶体管提供电流正迅速成为高性能 SoC 设计的主要瓶颈之一。随着晶体管不断变得越来越小,为晶体管提供电流的互连线必须排列得更紧密、更精细,这会增加电阻并消耗功率。这种情况不能再继续下去:如果电子进出芯片上的设备的方式没有发生重大变化,我们将晶体管制造得再小也无济于事。
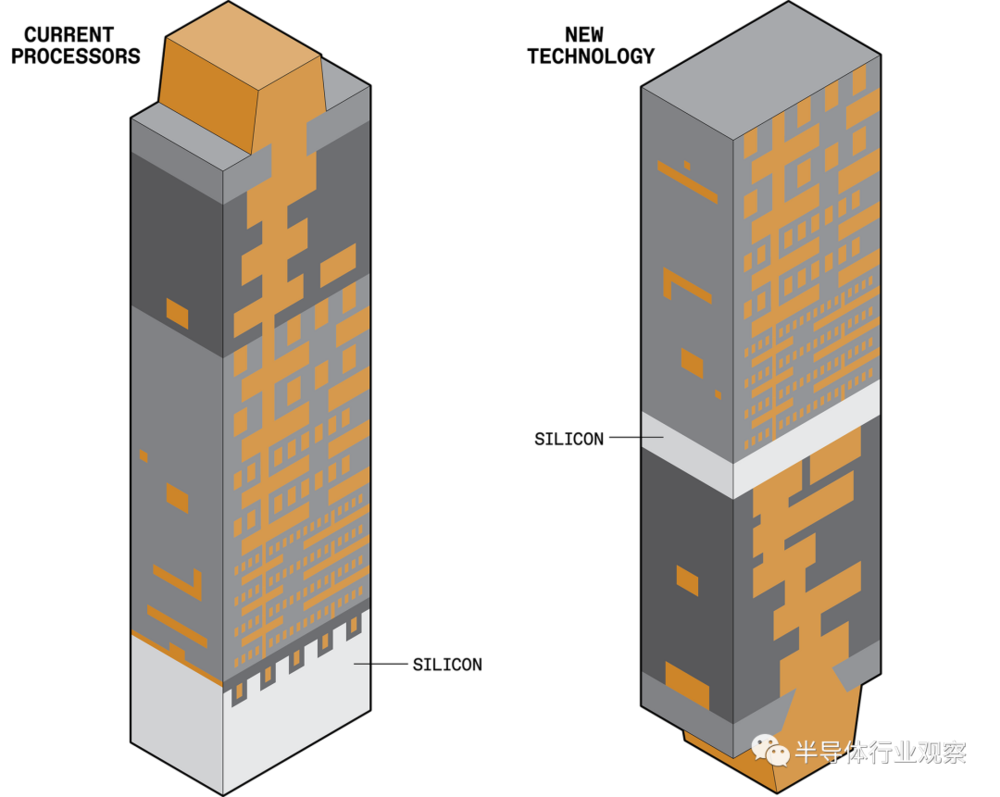
在当今的处理器中,信号和功率都从上方到达硅[浅灰色]。新技术将分离这些功能,从而节省电力并为信号路线腾出更多空间[右]。
幸运的是,我们有一个有前途的解决方案:我们可以使用长期以来被忽视的硅的一面。
为了从 SoC 获取电源和信号,我们通常将最上层金属(距离晶体管最远)连接到芯片封装中的焊球(也称为凸点)。因此,为了让电子到达任何晶体管以完成有用的工作,它们必须穿过 10 到 20 层越来越窄和曲折的金属,直到它们最终能够挤到最后一层局部导线。这种分配电力的方式从根本上来说是有损耗的。
于是,我们利用晶体管下方的“空”硅,这正是imec开创的一种称为“埋入式电源轨”或 BPR 的制造概念。该技术在晶体管下方而不是上方建立电源连接,目的是创建更粗、电阻更小的电源轨,并为晶体管层上方的信号承载互连释放空间。
CFET 和 3D 电路
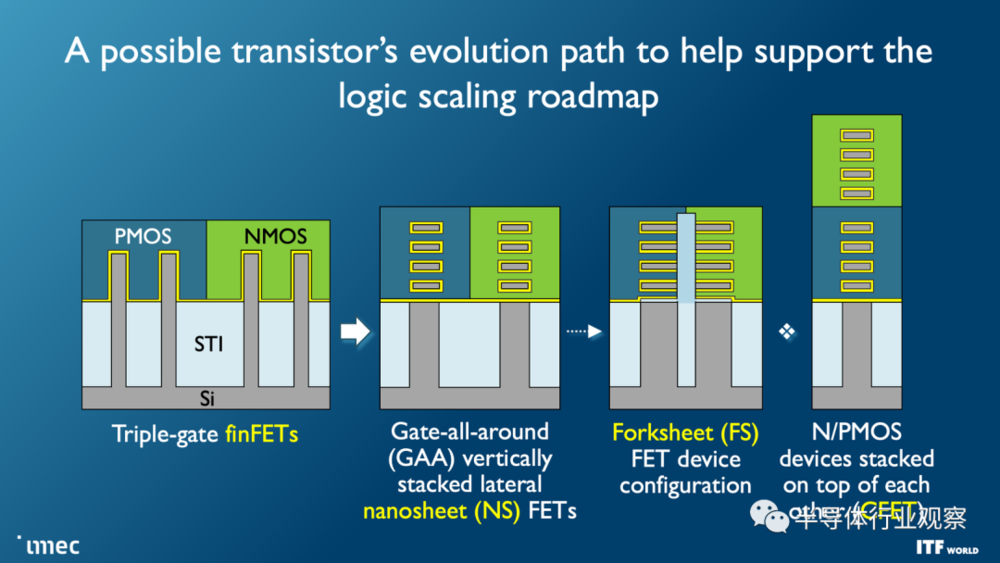
随着先进芯片的领先制造商转向某种形式的纳米片(或环栅)晶体管,对后续器件——单片互补场效应晶体管(CFET)的研究不断加强。
CFET 的想法是由 IMEC 研究机构在 2018 年提出,其中 n 型和 p 型晶体管垂直单片堆叠(参见 IMEC 提出的“ n-over-p”互补 FET 提案)。此后,大量研究论文充实了该提案,但这些论文来自 IMEC 和学术研究人员,而不是商业组织的研发团队。
CFET 的明显优势是两个晶体管占据 GAA、FinFET 或平面架构中一个晶体管的空间。但这也意味着可以更有效地设计 CMOS 逻辑电路。IMEC 此前曾指出,标准单元面积主要取决于对晶体管端子的访问,而 CFET 可以简化这一点。
在 IEDM 上,台积电将展示其在 CFET 方面的努力。他们声称良率有所提高(即 300 毫米硅晶圆上工作器件的比例),并且将组合器件缩小到比之前演示的更实用的尺寸。
在最新的论文中,台积电研究人员将推出了他们所谓的实用的单片 CFET 架构方法,用于逻辑技术扩展。它采用 48nm 栅极间距堆叠式 n-FET-on-p-FET 硅纳米片晶体管。这些表现出高通态电流/低亚阈值泄漏,从而产生令人印象深刻的开/关电流比(六个数量级)。他们还表现出相对较高的良率,FET 存活率 >90%。
尽管之前的工作表明功能性 CFET 器件可以在 300mm 晶圆上构建,但这些器件的栅极间距对于未来的扩展来说太大了。在这项工作中,通过垂直堆叠的 n/p 源极-漏极(SD)外延实现了更相关的 48nm 栅极间距,其中包括中间电介质隔离、垫片和 n/p SD 隔离。虽然仍必须集成其他基本功能才能释放 CFET 技术的潜力,但这项工作为实现这一目标铺平了道路。
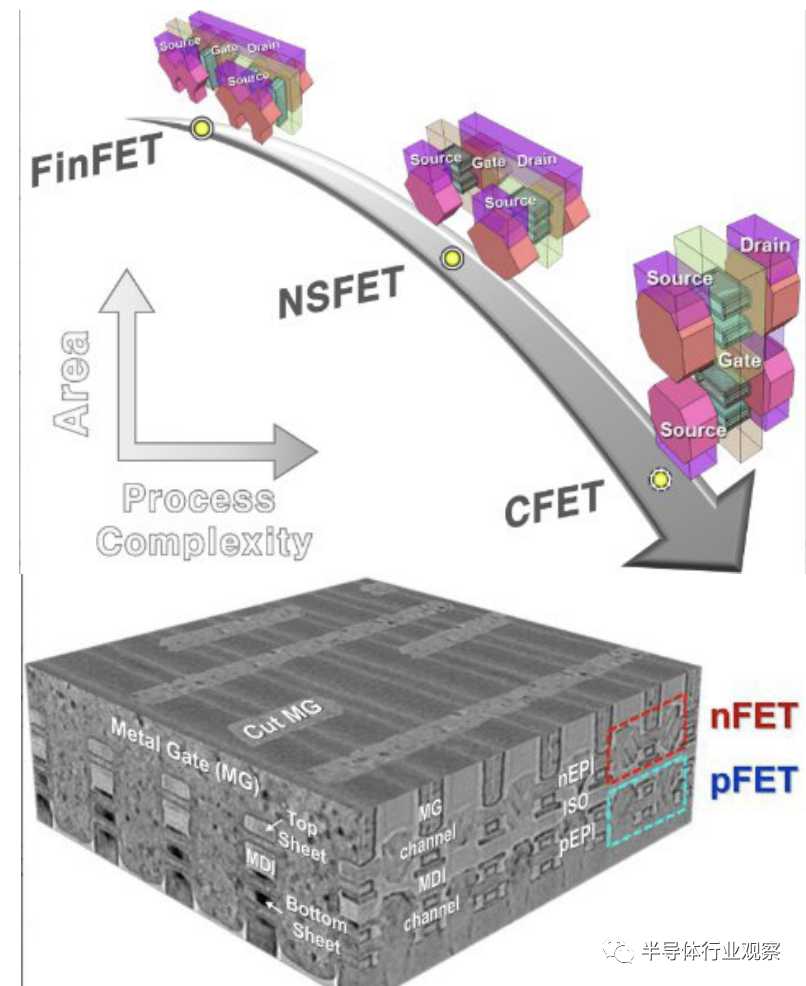
上图显示了器件架构从 FinFET 到纳米片 FET (NSFET) 再到 3D 堆叠式 CFET的演变,新颖的晶体管架构创新不断推动摩尔定律的延续;底部是单片 CFET 的内联横截面 TEM 演示,栅极间距为48nm,nFET 放置在 pFET 上方,两种类型的晶体管都被单一mental gate包围。
与此同时,英特尔研究人员将详细介绍由单个 CFET 构建的inverter circuit 。这种电路的尺寸可能只有普通 CMOS 电路的一半。英特尔还将解释一种新方案,用于生产 NMOS 和 PMOS 部分具有不同数量纳米片的 CFET。
英特尔表示,该器件由 3p-FET 纳米带顶部的 3 个 n-FET 纳米带组成,它们之间的垂直间距为 30 纳米。他们使用该器件以 60nm 栅极间距构建全功能inverters(test circuits),这在业界尚属首次。该器件还采用垂直堆叠双 S/D 外延技术;连接 n 和 p 晶体管的双金属功函数栅极叠层;以及与背面供电和直接背面器件接触的集成。
研究人员还将描述纳米带“depopulation”过程,用于需要数量不等的 n-MOS/p-MOS 器件。这项工作有助于加深对逻辑和 SRAM 应用扩展 CFET 潜力的理解,并了解关键的工艺推动因素。
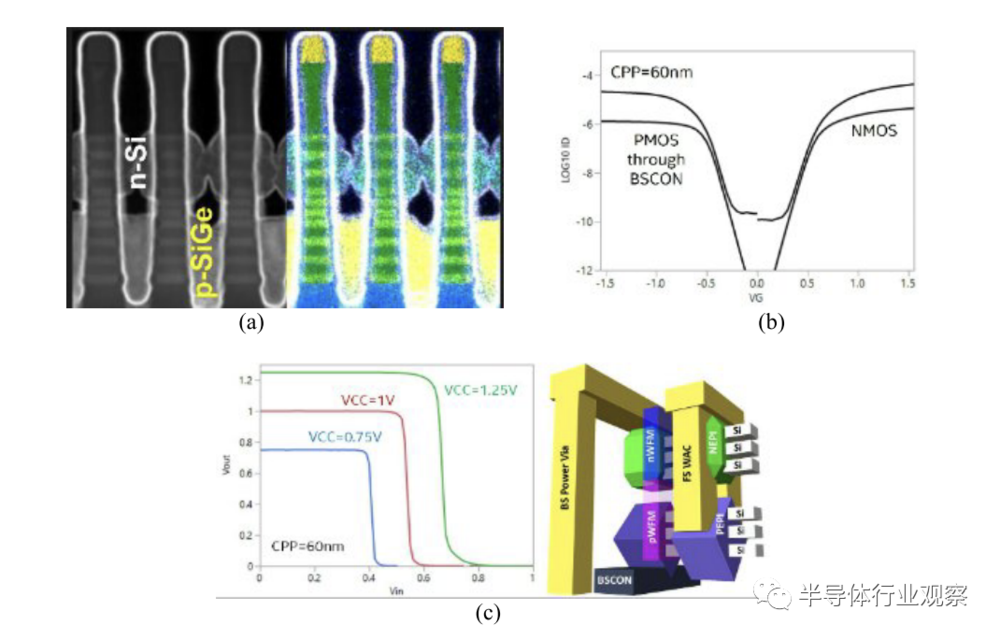
如上图所示,图(a) 是 CPP=60nm 垂直堆叠双源极-漏极 (SD:source-drain) 外延后 CFET 器件的 TEM 显微照片;图(b) 是在 CPP=60nm 下相同扩散的 CFET 器件在 VDS=0.05V 和 0.65V 时的 ID-VG 曲线。底部 p-MOS 通过背面器件触点 (BSCON:backside device contacts) 进行测量,而顶部 n-MOS 通过浅正面触点和背面电源通孔进行测量。对于 n-MOS 和 p-MOS,器件的亚阈值摆幅 (SS) 分别为 63mV/dec 和 66mV/dec,DIBL 分别为 57mV/V 和 38mV/V;图(c) 是逆变器电压传输曲线,它验证了所有突出显示的组件都在同一扩散上一起工作,从而实现了平衡良好的inverters。
2D晶体管
缩小纳米片晶体管(以及 CFET)的尺寸将意味着晶体管核心的硅带(ribbons of silicon)变得越来越薄。最终,将没有足够的硅原子来完成这项工作。因此,研究人员正在转向二维半导体材料,即使是一层只有一个原子厚的材料。
二维半导体属于一类称为过渡金属二硫属化物的材料。其中,研究最好的是二硫化钼。理论上,电子应该比MoS2更快地穿过二硫化钨(另一种二维材料)。
同时,二维半导体可以取代硅的想法面临着三个问题。一是生产(或转移)无缺陷的二维半导体层非常困难。第二个问题是晶体管触点和二维半导体之间的电阻太高。最后,对于 CMOS,您需要一种能够同样良好地传导空穴和电子的半导体,但似乎没有一种二维半导体能够同时传导空穴和电子。
据IEEE的报道,二维半导体面临的最大障碍是与它们进行低电阻连接。该问题被称为“Fermi-level pinning”,它的意思是金属触点和半导体的电子能量之间的不匹配会对电流产生高阻势垒(high-resistance barrier)。
在之前的研究中,金一直是与 MoS2 形成晶体管的首选接触材料。但沉积金和其他高熔点金属会损坏二硫化钼,使势垒(barrier)问题变得更糟。
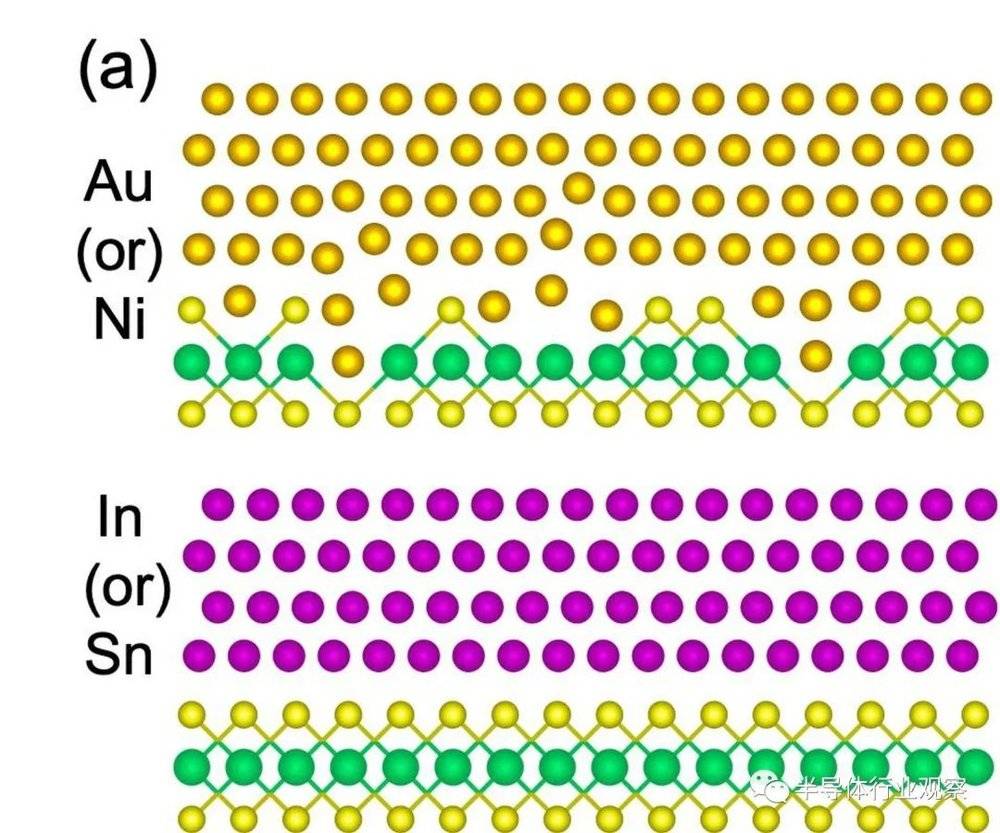
早在2021年的IEDM,台积电的研究人员就针对制造 2D 晶体管最棘手的障碍之一提出了单独的解决方案:半导体接触处的电阻尖峰金属触点(sharp spikes of resistance at the places where the semiconductor meets metal contacts)。而“锑”就是他们的答案。
按照台积电企业研究部低维研究经理 Han Wang 介绍,具体做法通过使用半金属作为接触材料来减少半导体和接触之间的能垒(energy barrier)。半金属(例如锑)的行为就像处于金属和半导体之间的边界并且具有零带隙。由此产生的肖特基势垒非常低,是的台积电器件的电阻都很低。
台积电此前曾与另一种半金属铋进行过合作。但其熔点太低。王表示,锑具有更好的热稳定性,这意味着它将与现有芯片制造工艺更兼容,从而生产出更耐用的设备,并为芯片制造工艺的后期提供更大的灵活性。
在本届的IEDM 上,台积电提出的研究以一种或另一种形式解决了所有这三个问题。
台积电将展示将一根二维半导体带堆叠在另一根带上的研究,以创建相当于支持二维的纳米片晶体管。研究人员表示,该设备的性能在 2D 研究中是前所未有的,而取得这一成果的关键在于采用了新的环绕式触点形状,从而降低了电阻。

上图是堆叠 1L-MoS2 的 (a) 亮场 TEM 图像和 (b) 暗场 TEM 图像
台积电表示,目前,纳米片缩放是通过减薄硅通道来实现的,但我们仍在努力寻找使用超薄过渡金属二硫属化物(TMD)作为沟道材料的实用方法。(MoS2 等 TMD 被称为单层或 2D 材料,因为它们只有原子层厚度。)
台积电领导的团队将讨论两个堆叠 NMOS 纳米片的前所未有的性能,其中拥有MoS2 栅极长度的 NMOS 器件表现出正阈值电压(VTH~1.0V);高导通电流;低接触电阻。
这些结果的关键是新型 C 形环绕接触,提供更大的接触面积和栅极堆叠优化。这些器件表现出可接受的机械稳定性,但研究人员表示,需要进行更多研究来减少 MoS2 沟道中缺陷的产生。
台积电还将在本届IEDM上带来首个真正的 2D CMOS 演示。
据介绍,其每个极性的 FET 器件(n-FET 和 p-FET)必须提供匹配的性能,以便 CMOS 逻辑器件正常工作。但是,虽然 MoS2 是一种适合 n 型器件的 TMD 材料,但它不适用于 p 型器件,而 TMD 材料 WSe2 更适合 p 型器件。
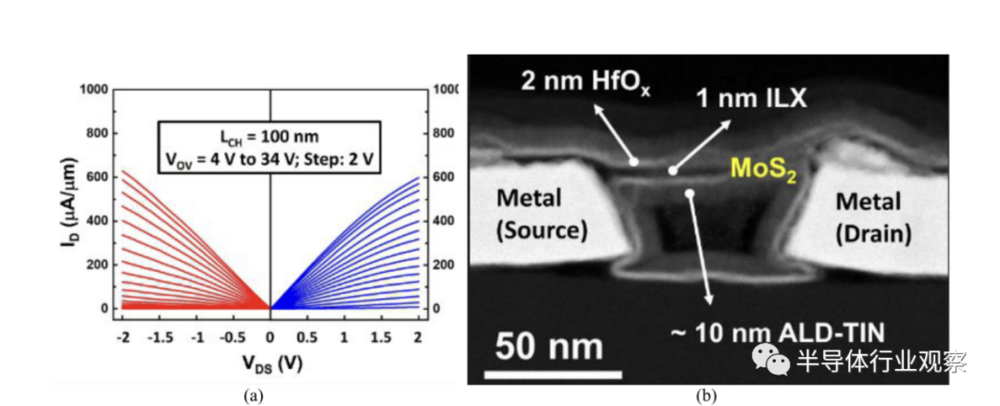
图(a) 显示了所制造的 n/p FET 的良好匹配的输出特性。图(b) 是具有共形栅极堆叠的悬浮 MoS2 纳米片结构的横截面 TEM,该结构包含 10nm TiN、2nm HfOx 和 1 nm ILX(界面电介质)。
此外,这两种极薄的材料都必须足够坚固,能够承受典型的制造工艺。TSMC 领导的团队将在业界率先描述分别使用这两种 TMD 沟道材料制造的匹配良好的 n MOS 晶体管和 p MOS 晶体管。他们通过在蓝宝石上单独生长这些高尺寸(~50nm 沟道长度)和高电流密度材料,然后将它们逐个芯片转移到 300mm 硅晶圆上进行集成,展示了这些材料的鲁棒性。
在此转移过程之后,器件的性能几乎没有改变,n-FET 和 p-FET (VDS = 1V) 在相同的栅极驱动下具有高输出电流 (~410 µA/µm)。此外,p-FET 迁移率达到了历史最高水平(~30 cm² /V∙s)。
另辟蹊径的解决方案
IEEE表示,机器学习中最大的问题之一是数据的移动。涉及的关键数据是所谓的权重和激活,它们定义一层中人工神经元之间的连接强度以及这些神经元将传递到下一层的信息。顶级 GPU 和其他人工智能加速器通过使数据尽可能靠近处理元素来优先解决此问题。研究人员一直在研究多种方法来做到这一点,例如将一些计算转移到内存本身以及将内存元素堆叠在计算逻辑之上。
IEDM 议程中的两个前沿示例引起了我的注意。第一个是将模拟 AI用于基于 Transformer 的语言模型(ChatGPT等)。在该方案中,权重被编码为电阻存储元件(RRAM)中的电导值。RRAM 是执行关键机器学习计算、乘法和累加的模拟电路的组成部分。该计算以模拟方式完成,作为电流的简单求和,可能节省大量电力。
IBM 的 Geoff Burr 在IEEE Spectrum 2021 年 12 月号上深入解释了模拟 AI 。在 IEDM,他将提供一种模拟 AI 处理Transformer 模型的设计。
IEDM 上出现的另一个有趣的人工智能方案源自清华大学和北京大学的研究人员。它基于三层系统,包括硅 CMOS 逻辑层、碳纳米管晶体管和 RRAM 层,以及另一层由不同材料制成的 RRAM。他们表示,这种组合解决了许多方案中的数据传输瓶颈,这些方案试图通过在内存中构建计算来降低人工智能的功耗和延迟。在测试中,它执行了标准图像识别任务,其精度与 GPU 相似,但速度快了近 50 倍,能耗仅为 GPU 的 1/40。
特别不寻常的是碳纳米管晶体管与 RRAM 的 3D 堆叠。美国国防高级研究计划局花费数百万美元将这项技术在 SkyWater Technology Foundry 开发成商业流程。Max Shulaker 和他的同事在IEEE Spectrum 2016 年 7 月号上解释了该技术的计划。他的团队于 2019 年利用该技术构建了第一个 16 位可编程纳米管处理器。
参考文献
https://spectrum.ieee.org/iedm
https://spectrum.ieee.org/2d-semiconductors-and-moores-law
https://www.ieee-iedm.org/press-kit
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:编辑部

