




2017-09-29 10:34

扫码打开虎嗅APP


虎嗅注:本文转自“AI科技评论”(aitechtalk),内容为计算机视觉专家、斯坦福副教授李飞飞在IROS 2017上的专题报告,由三川负责编辑、整理。
朋友建议我,在机器人大会演讲至少要放一张机器人的图片。我挑了一张最喜欢的:

问题来了:为什么在这幅儿童画里,机器人是有眼睛的?
我认为这与进化演进有关。不管是智慧动物还是智能体,眼睛、视觉、视力都是最基本的东西(儿童在潜意识里也这么认为)。让我们回到 5.4 亿年前的寒武纪——在寒武纪生物大爆发之前,地球上的生物种类算不上多,全都生活在水里,被动获取食物。但在距今约 5.4 亿年的时候,非常奇怪的事情发生了(如下图):短短一千万年的时间内,各种各样的新物种纷纷涌现,这便是“寒武纪大爆发”。
这背后的原因是什么?
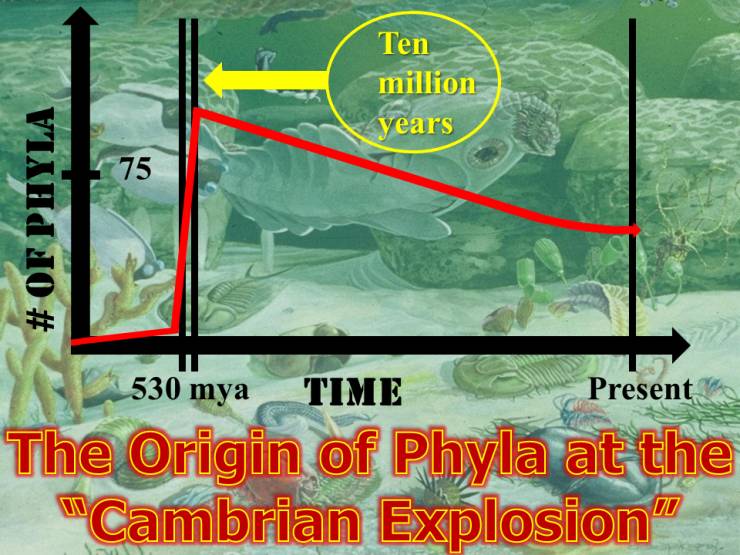
最近,一名澳大利亚学者提出了一套非常有影响力的理论,把“寒武纪大爆发”归功于——视觉。在寒武纪,最早的三叶虫进化出了一套非常原始的视力系统,就像最原始的德科相机,能捕捉到一丁点光。但这改变了一切:能“看”之后,动物开始主动捕食。
猎手和猎物之间从此开始了持续数亿年的“追踪—躲藏”游戏,行为越来越复杂。从这个节点往后,几乎地球上所有动物都进化出了某种形式上的视觉系统。5.4 亿年之后的今天,对于人类,眼睛已成为我们最重要的传感器,超过一半的大脑皮层都会参与视觉功能。
在地球生物向更高智慧水平进化的过程中,视觉真的是非常重要的推动力量。这套如此神奇的感知系统,便是我今天想要讲的主题。这也是我们对机器的追求——让机器拥有人类这样的视觉智能。
下面,我讲一个小故事,关于人类视觉系统令人惊叹之处。
在 1960 年代的好莱坞,诞生了一个非常有里程碑意义的历史电影《The Pawnbroker》(首部以幸存者角度表现二战中犹太人被大屠杀的美国电影) 。随着这部电影诞生了一种全新的为电影插入视频剪辑的技术,导演 Sidney Lumet 对此做了个很有意思的实验——插入的画面需要显示多久才能让观众捕捉到内容?

他不断缩短画面播放的时间,从十几秒到几秒,最后到三分之一秒——他发现这是一个相当好的时长,足够观众看清楚并且充分理解画面。
心理学家和认识科学家们受此启发,开展了更进一步的实验:向参与者播放连续多帧画面,每帧的显示时间仅有 100 微秒。其中,仅有一幅画面里有一个人,要求参与者找出这个人。
而大家确实都能够找出来。这非常令人惊叹,只需 100 微秒,我们的视觉系统就能检测到从来没见过的人。
1996 年,神经心理学家 Simon J. Thorpe 在 《自然》发表了一项研究,通过脑电波观察人脑对复杂图像进行分类的速度。他发现,仅需 150 微秒,大脑就会发出一道区分信号,对画面中的物体是否为动物做出判断。
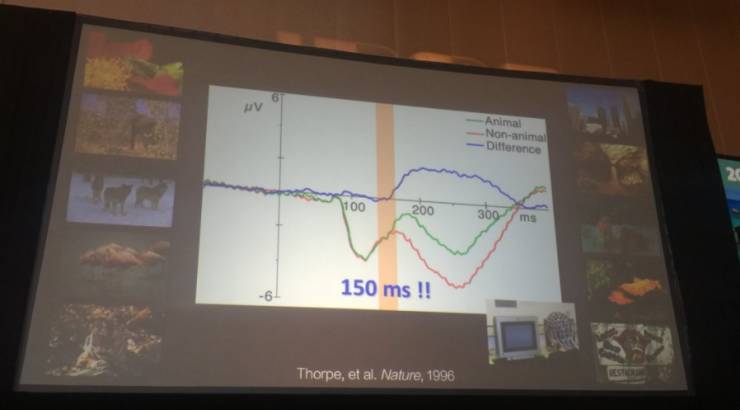
后来,哈佛人体视觉学者 Jeremy Wolfe 在论文中写道,虽然很难去衡量一个人究竟看到了什么、对某个画面达到了什么程度的理解,但直觉告诉我们,画面中的物体应当是我们观察的对象之一。
看起来很显而易见,但这提醒我们,对物体的识别是视觉最基础的部分之一,计算机视觉也在这个领域攻关了许多年。从 2010 到 2017,ImageNet 挑战赛的目标识别(object recognition)错误率一直在下降。到 2015 年,错误率已经达到甚至低于人类水平。

我不会说目标识别是个已经攻克的领域。许多关键问题尚待研究,其中不少和机器人息息相关。比如 3D 轮廓理解、目标局部理解,对材料、纹理的理解等等。这些方面的研究非常活跃,我也感觉到做这些比组织 ImageNet 分类任务挑战赛更有意思。
接下来,我想分享一些新的、探索性的工作,而不是列出识别对象清单(inventory list of objects)这样的基础研究。让我们回到 Jeremy Wolfe 的论文,他继续写道:“物体之间的关系,必须写进 gist。”
假设有两张图片:把一盒牛奶倒进玻璃杯;把一盒牛奶倒出来(倒在空中),旁边放着一只玻璃杯。两者不是一回事。两张图片中的物体都一样,但它们之间的关系不同。
仅凭图片的对象清单,无法完整传递其内容。下面是另一个例子:

两张照片都是人和羊驼,但是发生的事情完全不同。当然,过去在这方面也有不少研究,包括空间关系、行为关系、概率关系等等,就不一一阐述了。这些工作基本都在小型封闭环境中开发测试,探索的也不过十几、二十几种关系。而我们希望把视觉关系的研究推向更大的尺度。
我们的工作基于视觉表达和 leverage model 的结合,通过把图像空间的嵌入以及关于对象关系的自然语言描述以巧妙的方式结合起来,避免了在对象和对象之间的关系做乘法带来的计算负担。

上图展示的便是可视化结果的质量。给定该照片,我们的算法能找出空间关系、比较关系、不对称空间关系、动词关系、行为关系以及介词关系。
更有意思的是,我们的算法能实现 zero-shot (零样本学习)对象关系识别。举个例子,用一张某人坐在椅子上、消防栓在旁边的图片训练算法。然后再拿出另一张图片,一个人坐在消防栓上。虽然算法没见过这张图片,但能够表达出这是“一个人坐在消防栓上”。

类似的,算法能识别出“一匹马戴着帽子”,虽然训练集里只有“人骑马”以及“人戴着帽子”的图片。当然,这个算法还很不完美。例如当两个类似的对象(如两个人)部分重叠在一起,算法就容易判断失误。如下图,算法错误得认为是左边的人在扔飞碟:

这是一个计算机视觉下面飞速发展的领域。在我们团队的 ECCV 2016 论文之后,今年有一大堆相关论文发表了出来,一些甚至已经接近了我们的模型效果。我非常欣喜能看到该领域繁荣起来。
