2023-12-25 08:14


扫码打开虎嗅APP

本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:周健工,头图来自:视觉中国
苹果冷静地观察了生成式AI亢奋的一年,一直在为自己的生态基础添砖加瓦,还在一步一个脚印地迈向明年发布AiPhone。
十月份,苹果机器学习研究团队曾推出一个“雪貂“模型(Ferret),这个多模态大模型比GPT-4v对空间的理解更准确。最近这个模型开源了。简单地说,在一幅图中的任何地方,你指出任何一个物体,哪怕它再微小,“雪貂”都能解释清楚。
这种对空间的敏感,对于苹果即将发布的Vision Pro具有重要作用,它让自然/虚拟的视觉感知与语言大模型结合。这篇不张扬的论文作者全部是华人,最近越来越引起业内的重视,它在空间计算上达到了SOTA水平。
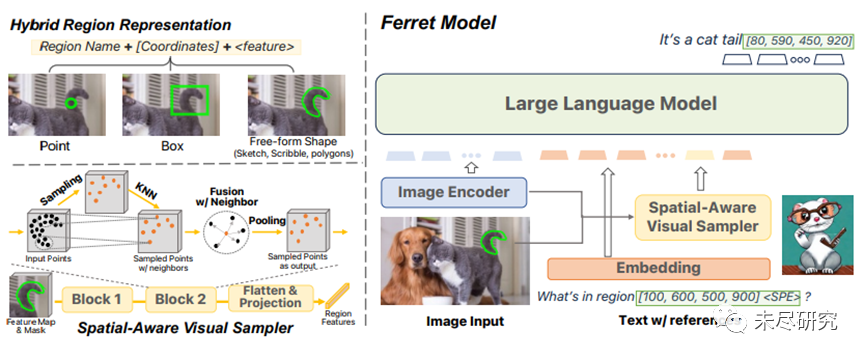
“雪貂”模型架构 (来源:FERRET: REFER AND GROUND ANYTHING ANYWHERE AT ANY GRANULARITY )
苹果最近推出了能在其M3芯片上训练部署大模型的开源框架MLX。这意味着Mac笔记本电脑的开发者,可以开发出大模型支持的应用。
苹果还推出了“闪电大模型” (LLM in a Flash),用闪存解决了手机上部署大模型内存(DRAM)不足的问题。
这是个人很喜欢的一篇论文。是的,偷偷干活的苹果,也开始默默地发论文了。
这篇论文谈的是一个小而关键的问题,如何在手机这样一个内存非常有限的空间里,部署一个大模型,而且推理的速度要快,还不费电池。
它的最大优点,不是就算法谈算法,而是从对硬件的深刻理解,结合算法提出了自己的方法。它的出发点完全是消费者思维,大模型在遥远的云端,大得吓人,贵得惊人,只有揣在用户的口袋里,才能让消费者对生成式AI产生感觉。
DRAM太小,放不下一个几十亿级的模型。尽管可以放到闪存里,但闪存的带宽不够。为了最小化从闪存到DRAM带宽的负载,苹果创新了两个技术,窗口化 (windowing)和行列捆绑 (row-column bundling)(详见论文)。
在OPT 6.7B和FALCON 7B两个模型上测试,结果相当“炸裂”,能够运行的模型尺寸达到可用DRAM能容纳的两倍,与CPU和GPU中的简单加载方法相比,推理速度分别提高了4~5倍和20~25倍。
对齐芯片、操作系统和系统设计,找到方法建立起一个推理成本模型,这事只有苹果做得出来。
最近一系列的几十亿参数级小模型表现当惊世界,如Mistral, Phi-2能挑战百亿参数级大模型;谷歌推出了18亿参数的Nano级Gemini模型,直接装到Pixel手机上。高通的骁龙芯片能跑得动百亿参数级的模型。三星可能将于2024年初推出生成式AI游戏功能的Galaxy S24手机。
还有上海交大团队推出的推理引擎PowerInfer,都为大模型在设备终端,尤其是手机和笔记本电脑的部署,扫清一个又一个障碍,也预示着2024年,消费类电子产品,将会迎来一波大模型加载的高潮。
这些“小”模型的推出,有一个共同的特征,就是采用了高质量的数据,“教科书级”的数据。无疑,主流新闻媒体的档案,所能提供的是好的语言训练材料。
苹果正在与美国各大媒体机构谈判,约以5000万美元的价格,获得这些媒体的档案语料库,用来训练自己的大模型,可能会用Siri的对话服务。
想想这些用来训练语料的品质吧,康迪纳斯特的Vogue、New Yorker、NBC News,以及IAC的People、The Daily Beast、Better Homes、 Gardens等。它包括大量的以时尚与生活方式为内容的精美文字和图片。也包括部分新闻文章、图片和视频。
但是其他的主流媒体对此没有表示出多少兴趣。以往纸媒与社交媒体的合作,并没有给他们带来多少利益。另外,媒体将其档案中的新闻交给苹果去训练大模型,在使用的过程中,可能产生的法律纠纷,也引起这些媒体的担忧。
苹果的做法,被认为更加地道。其他的AI公司或者科技巨头,是先用了人家的语料,被揪住了再去谈授权,已经引发了一些官司。
苹果出于对隐私的强调,它不愿意直接从网络上扒数据。苹果也不允许收集其客户的数据。
那么,2024年苹果会做什么?
大家首先想到的是,它会在明年推出生成式AI加持的语言助理Siri。它将是2024年秋季iPhone16和iOS18的最大亮点。有些果粉开玩笑说会推出SiriGPT。但这些都只是冰山一角。
巨头的做法,通常是寻找新的技术加强其固有的核心能力,在原有的产品上产生差异化。是从表面上看,吃老本的苹果,在生成式AI上行动迟缓,采取了保守的跟随战略?还是苹果能真正利用其在芯片、操作系统、大模型方面一体化整合的能力和产品设计能力,做出最好的AI产品体验?答案可能是后者。
苹果在过去的几年,已经收购了几十家AI初创企业,用于其产品、服务及生态中。只是这里面没有那些明星级的初创公司。
苹果只做不说,早有分析人士注意到,苹果在AI上的投资,一点都不比微软少:已经花了上百亿美元,建造生成式AI应用开发的基础设施。稍早人们传闻苹果在内部偷训自己的大模型Ajax,或者叫Apple GPT,据说当时能赶上GPT-3.5。
但最近苹果在机器学习方面一系列的研究成果表明,苹果在走自己的路。微软、谷歌、亚马逊、英伟达,以及OpenAI为代表的闭源大模型公司,围绕模型、云和算力去收割了第一茬。
而苹果看重的是其20亿设备及其用户所形成的巨大的生态。生成式AI所带来的iPhone的新的体验,以及用大模型去加持所有的应用,这些给苹果带来的消费市场机会,是其他巨头难以夺走的。苹果以隐私保护的名义,控制了第三方应用之间互相窜访,这也让苹果商店成为自己未来AI应用的金矿。
苹果动作慢了吗?生成式AI的幻觉问题,还有监管、隐私保护、版权纠纷等,这些问题都会令苹果想得更深一些,考虑得更周全一些。苹果有这样的底气,因为它在芯片、操作系统、应用、产品、制造等各个层面一体化的设计,最终所带来的产品体验创新性的深度,仍将可能是其竞争对手难以比拟的。
OpenAI引发的“iPhone时刻”,已经尖叫好几回了,但下一个苹果,还是苹果。
参考论文:
https://arxiv.org/pdf/2312.11514.pdf
https://arxiv.org/pdf/2310.07704.pdf
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:周健工

 05:28
05:28









 14:24
14:24
 13:37
13:37
 36:43
36:43
 14:05
14:05
 06:21
06:21
 05:44
05:44
 05:19
05:19
 11:57
11:57
 05:37
05:37



