




2018-07-19 11:10

扫码打开虎嗅APP


虎嗅注:本文主要分为三个部分:1.音乐推荐系统的发展简史;2.三种主要的推荐模型的基本介绍;3.总结。Spotify现如今已经遍布多个国家,而使它一战成名的便是本文将要提到的推荐系统,这些推荐系统到底是如何运作的?是大数据、云计算,还是有着什么独特的操作呢?本文转自微信公众号BitTiger(ID:bit-tiger),原名为深度技术揭秘:Spotify的推荐系统怎么可以这么准!摘选自Medium分享文章,原作者为Sophia Ciocca,英文链接可在底部看到。
特别值得一提的是,本文写作于2017年10月,现在的Spotify已经拥有超过1.6亿用户,其中超过7500万为付费用户。无论是不是归功于这套推荐系统,Spotify的快速发展都让它成为了北美最受瞩目的音乐软件公司。
每周一,超过一亿Spotify用户都会收到一个名为“Discover Weekly”的全新歌单。歌单中包含了30首用户从未听过但很可能会喜欢的歌曲。
我是Spotify的忠实用户,尤其是Discover Weekly。为什么会这么喜欢这一功能?因为它真的很懂我,好像它对于我的音乐品位了如指掌。如果不是它每周向我推荐新歌,我可能永远找不到很多我喜欢的歌。

这个星期我的Discover Weekly歌单
事实证明,热爱Discover Weekly的并不只是我一个人,很多用户都特别喜欢这个功能,这也促使Spotify更加关注这一功能并试图在优化歌单生成算法投入更多精力。

自从2015年Discover Weekly功能推出以来,我一直在试图研究它背后的技术(我是Spotify的粉丝,所以我喜欢研究它的产品)。在疯狂地Google了三周后,我觉得我已经初步掌握Discover Weekly的原理了。
那么Spotify是如何每周为每个用户选择30首歌曲的?首先,让我们先来了解一下其他音乐服务是怎么处理音乐推荐的以及为什么Spotify比这些竞争对手们做得更好。

回到本世纪初,Songza开始了在线音乐管理场景,通过“人工管理”的方式为用户提供歌单。这意味着需要一个“音乐专家”团队或其他人类决策者挑选一些好听的歌曲,进而组成歌单,然后用户就能听到这些歌单(后来,Beats Music也采用了类似的策略)。人工管理的歌单本身没有问题,但它是基于特定管理人员的品味,很难符合每位用户的音乐品味。
和Songza一样,Pandora也是在线音乐管理的早期玩家之一,它使用了稍稍先进一些的方法——人工标记歌曲标签。通过让听完音乐的用户为每首歌选择一些描述性的词语(打标签),Pandora就可以简单地通过筛选标签的方式来制作歌单。
与此同时,来自MIT Media Lab的音乐智能机构Echo Nest诞生了,它推出了一套更为先进的个性化音乐推荐方案。Echo Nest使用算法分析音乐的音频和文本内容,从而进行音乐识别、个性化推荐、歌单创建和分析等功能。
最后,Last.fm又采用了另一种被称为“协同过滤”的方法来识别用户可能喜欢的音乐,这种方法一直沿用到了今天,稍后会详细介绍。
那么,如果上面提到的方法就是其他音乐管理服务进行音乐推荐的方式,那么Spotify的优异的推荐引擎是如何运行的呢?为什么它能做到比其他服务更加了解用户的品味?
实际上,Spotify并没有使用全新的推荐模型,而是将其他服务使用的最佳策略组合在一起,从而实现了自己独特且强大的Discover引擎。
为了创建Discover Weekly歌单,Spotify主要使用了三种推荐模型:
- 协同过滤模型(Collaborative Filtering model)与Last.fm起初使用的类似,分析你的行为和其他用户的行为。
- 自然语言处理(Natural Language Processing ,NLP)模型分析文本。
- 音频模型,分析原始音轨本身。
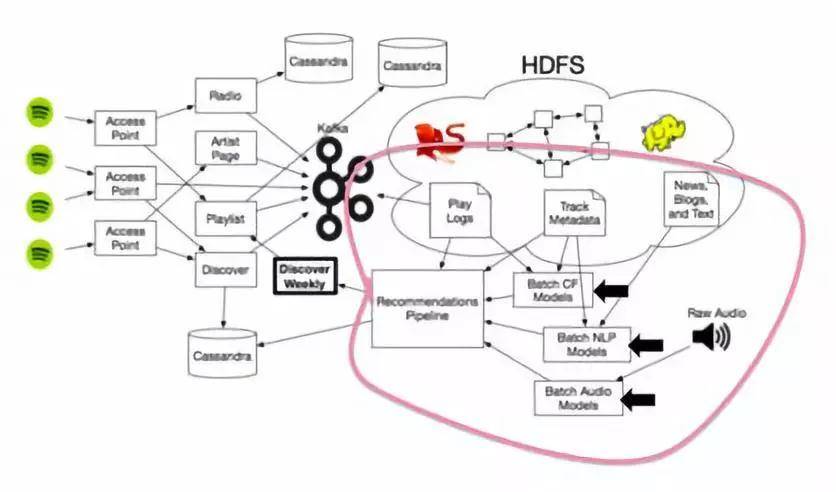
图片来源:http://blog.galvanize.com/spotify-discover-weekly-data-science/,作者Galvanize
让我们来深入了解一下这些推荐模型是如何工作的吧。

首先介绍一些背景知识:当很多人都听到“协同过滤”这个词之后,通常会联想到Netflix,因为它是第一家使用协同过滤驱动推荐引擎的公司之一,利用用户对于电影的星级评分了解哪些电影可以向品味类似的用户进行推荐。
在Netflix取得成功之后,协同过滤迅速传播开来而且到现在已经成为所有推荐模型的基础。
但与Netflix不同,Spotify并没有用户星级评分系统。Spotify的数据来自于隐式反馈——具体来说就是流媒体服务会记录用户所听的歌曲,用户是否将歌曲保存在自己的歌单中以及是否在听完歌后访问了歌手的主页等等。
但什么是协同过滤?它是如何工作的?简而言之,就像下图所示的那样的:

图片来源:https://www.slideshare.net/erikbern/collaborative-filtering-at-spotify-16182818/10-Supervised_collaborative_filtering_is_pretty,作者:Erik Bernhardsson,Spotify前员工
这里面发生了什么?两个人都有一些自己喜欢的歌,左边那位喜欢P、Q、R和S,右边那位喜欢Q、R、S和T。
协同过滤获得以上数据得到下面的结论:
“嗯……看来你们都喜欢Q、R和S,所以你们很可能是相同品味的用户。所以你们应该喜欢听对方喜欢而自己没听过的那几首歌。”
所以推荐系统就会向右边的用户推荐歌曲P(P是右边用户没有表示喜欢的但是她的同类用户喜欢的歌曲),同样的道理,左边用户会被推荐歌曲T。很简单,是吧?
但Spotify是如何在实践中实现根据数百万用户的偏好来计算出这些用户各自的推荐曲目呢?答案是构造矩阵,通过Python库实现!

事实上,你看到的矩阵是很庞大的。每一行代表Spotify的1.4亿用户中的一个用户(如果你是Spotify的用户,你在里面就是矩阵的一行),每一列代表Spotify曲库中3000万歌里的一首。
然后,Python库运行这个长而复杂的矩阵分解公式:

一些复杂的数学计算
当这个计算完成后,我们会得到两种类型的向量,分别由X和Y来代表。X是用户向量,代表一个用户的歌曲偏好,Y是歌曲向量,代表一首歌的受欢迎程度。

用户/歌曲矩阵产生两种类型的向量:用户向量和歌曲向量。图片来源:https://www.slideshare.net/MrChrisJohnson/from-idea-to-execution-spotifys-discover-weekly/31-1_0_0_0_1,作者Chris Johnson,Spotify前员工。
现在我们拥有了1.4亿个用户向量和3000万歌曲向量了。它们本身只是一些数字,并没有什么意义,但它们可以用来进行很多比较。
为了找到哪些用户的音乐品味与我相近,协同过滤将我的向量与其他用户的向量进行比较,最终得出哪个用户是最匹配的。同样的事情也发生在歌曲向量上,你可以把一首歌曲的向量和其他所有歌曲的向量进行比较,然后找出哪些歌曲最相似。
协同过滤是一个不错的方法,不过Spotify借助另外一个引擎——NLP来实现更上一层楼的效果。
Spotify采用的第二种推荐模型是自然语言处理(NLP)模型。顾名思义,这种模型的数据源来自元数据、新闻、博客、评论和互联网的其他各种文本。

NLP是让计算机理解人类语言含义的技术,它本身是一个广阔的领域,在业界通常通过情绪分析API(sentiment analysis API)来实现。
NLP背后的机制原理超出了本文的讨论范围,但这是发生在一个非常高级别的事情:Spotify会不停地爬取网页、博客和其他书面文本,然后分析对于特定的歌手和歌曲的评价——用到了哪些形容词和特定的语言?在讨论某些歌手和歌曲的时候,哪些其他歌手和歌曲也会同时被讨论?
虽然我不能确切知道Spotify是如何选择并处理这些抓取的数据,但我可以根据Echo Nest过去处理这些数据的方法给出一些自己的见解。他们会把这些Spotify搜集到的数据放入所谓的“文化向量(cultural vector)”或“顶级描述词(top term)”了。每个歌手和每首歌曲都有数千个顶级描述词。每个词都有相应的权重,权重与描述词的重要性相关(大概是人们用这个词描述当前歌手或者音乐的概率)。

Echo Nest使用过的“文化向量”或“顶级叙述词”。图片来源:https://notes.variogr.am/2012/12/11/how-music-recommendation-works-and-doesnt-work/,作者Brian Whitman,Echo Nest联合创始人
然后,就像在协作过滤中一样,NLP模型使用这些描述词和权重来生成歌曲的矢量表示,用矢量来确定两段音乐是否相似程度。

你可能会问这个问题:我们已经从前两个模型中获得了如此多的数据,为什么我们还需要分析音频本身?
首先,加入这个模型可以进一步提升推荐服务的准确性。不过事实上,引入这第三种模型还有一个目的:与前两种模型不同,原始音频模型主要用于处理新歌。
比方说,一个你的创作型歌手朋友在Spotify上发布了一首新歌,但他/她可能只有50个听众,这意味着几乎不会有人会对新歌进行协同过滤,网络上也没有很多人讨论它,所以NLP模型也不会抓取到信息。幸运的是,原始音频模型不会关注新歌是流行的还是小众的,有了它的帮助,你朋友的新歌就会和流行歌曲一样出现在不少人的Discover Weekly上了!
那么我们如何通过音频来分析音乐的风格?现在听起来还有点抽象。
答案是使用卷积神经网络(convolutional neural networks,CNNs)。
卷积神经网络是人脸识别软件经常会用到的技术。在Spotify中,它被用于处理音频而不是像素。下图是一个神经网络架构的示例:
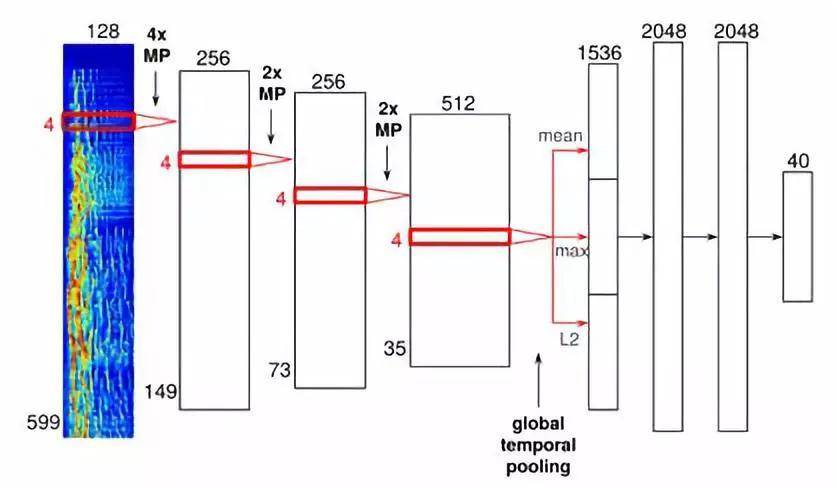
图片来源:http://benanne.github.io/2014/08/05/spotify-cnns.html,作者Sander Dieleman
这个特殊的神经网络由四层卷积层,左边是厚一些的矩形,三个是致密层,右边是较窄的矩形。输入是时频信号表示的音频帧,然后级联成频谱图。
音频帧通过这些卷积层,随后在最后一个卷积层会遇到“全局时域池化(global temporal pooling)”层,它会对整个时间轴进行池化,可以有效地计算整首歌的特征并进行统计。
经过处理后,神经网络对这首歌有了充分了解,包括估计的拍号(time signature)、调(key)、调式(mode)、速度(tempo)和响度(loudness)等特征。下面是Daft Punk“环游世界(Around the World)”30秒片段的数据图。
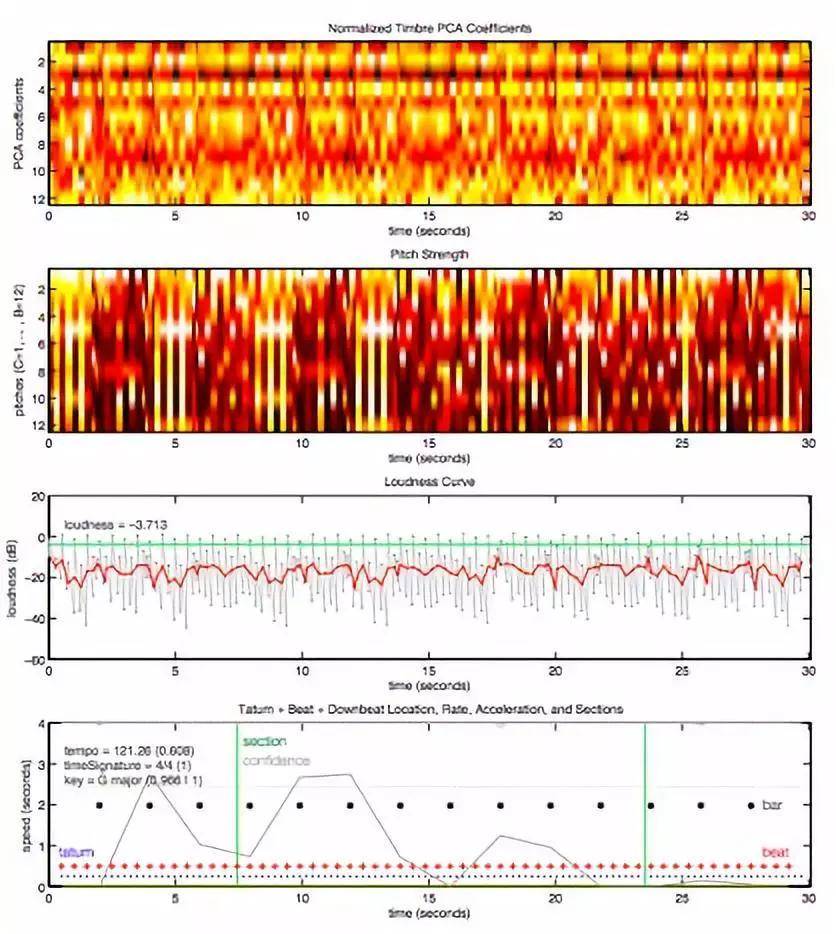
最终,通过对歌曲关键特征的解读,Spotify能够了解歌曲之间的基本相似之处,再根据用户自己的播放历史,了解哪些用户可能喜欢它们。
本文涵盖了三种主要的推荐模型的基本介绍,他们为Spotify的高准确性推荐系统提供了保障,最后Discover Weekly歌单“一战成名”!

当然,这些推荐模型都与Spotify的强大的生态系统有关,后者包括大量的数据存储和使用大量Hadoop集群来扩展推荐系统,进而使这些引擎在大数据组成的矩阵、在线音乐评论和音频文件中发挥作用。
本文转自微信公众号BitTiger(ID:bit-tiger),摘选自Medium分享文章,原作者为Sophia Ciocca。
英文原文链接:https://medium.com/s/story/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe
