2024-02-20 14:50


扫码打开虎嗅APP

本文来自微信公众号:量子位(ID:QbitAI),作者:白交、克雷西,原文标题:《大模型最快推理芯片一夜易主:每秒500tokens干翻GPU!谷歌TPU人马打造,喊话奥特曼:你们也太慢了》,题图来自:视觉中国
太快了太快了。
一夜间,大模型生成已经没什么延迟了……生成速度已经接近每秒500 tokens。
还有更直观的列表对比,速度最高能比以往这些云平台厂商快个18倍吧。
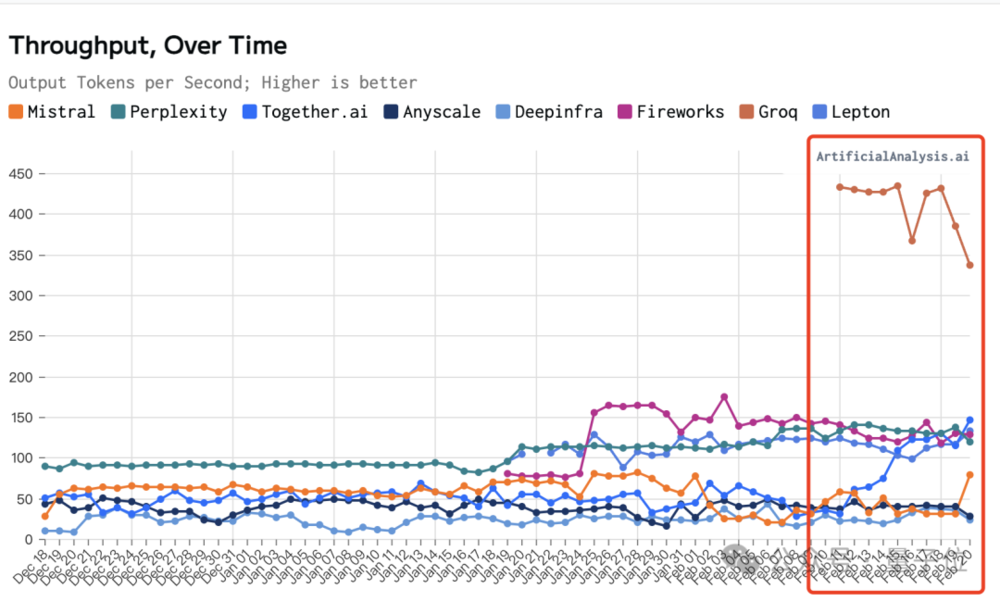
(这里面还有个熟悉的身影:Lepton)
网友表示:这速度简直就是飞机vs走路。

值得一提的是,这并非哪家大公司的进展。
初创公司Groq,谷歌TPU团队原班人马,基于自研芯片推出推理加速方案(注意,这不是马斯克的Grok)。
据他们介绍,其推理速度相较于英伟达GPU提高了10倍,成本却降低到十分之一。
换言之,任何一个大模型都可以部署实现。
目前已经能支持Mixtral 8x7B SMoE、Llama 2的7B和70B这三种模型,并且可直接体验Demo。
他们还在官网上喊话奥特曼:
你们推出的东西太慢了……

每秒接近500 tokens
既然如此,那就来体验一下这个号称“史上最快推理”的Groq。
先声明:不比较生成质量。就像它自己说的那样,内容概不负责。

目前,演示界面上有两种模型可以选择。
就选择Mixtral 8x7B-32k和GPT-4同擂台对比一下。
提示词:你是一个小学生,还没完成寒假作业。请根据《星际穿越》写一篇500字的读后感。
结果啪的一下,只需1.76秒就生成了一长串读后感,速度在每秒478Tokens。
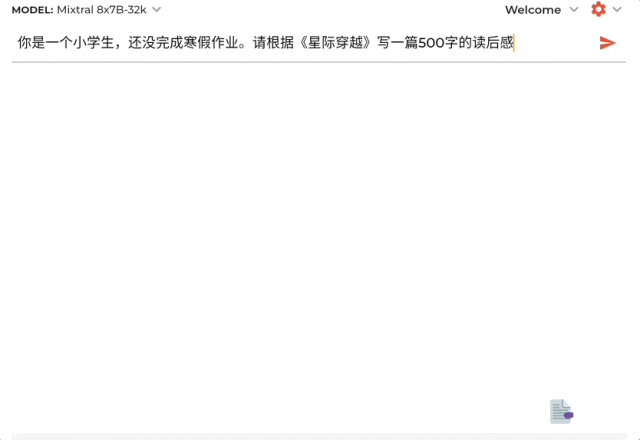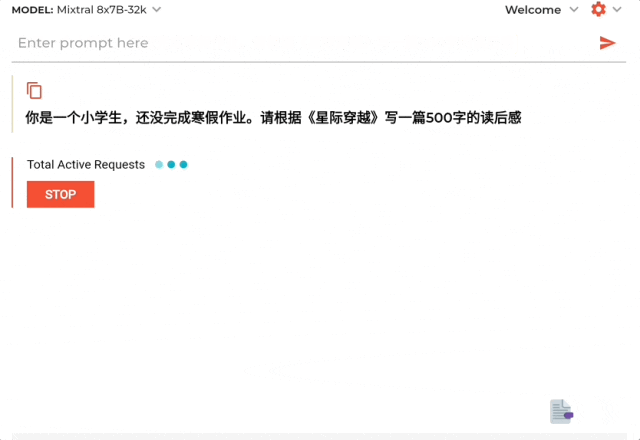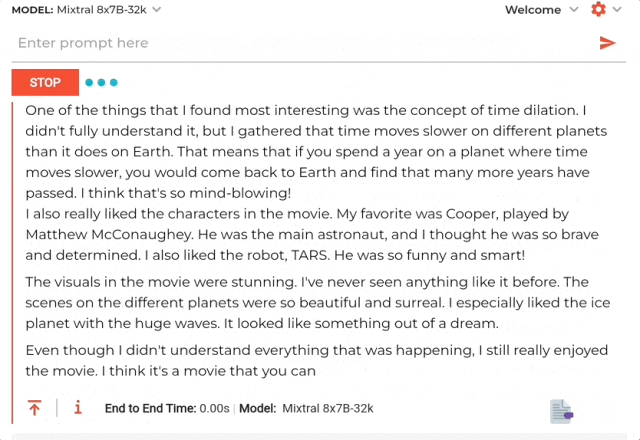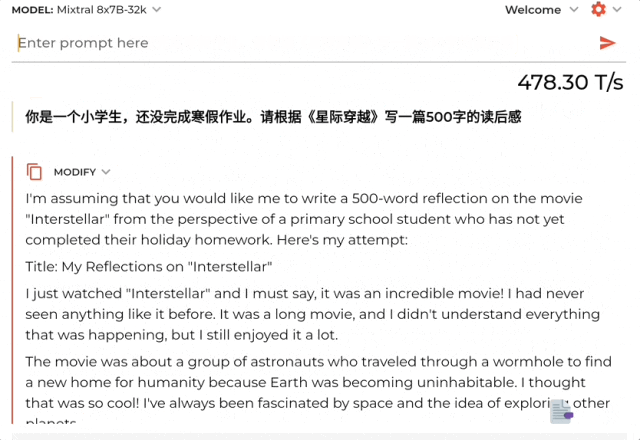
不过内容是英文的,以及读后感只有三百六十多字。但后面也赶紧做了解释说考虑到是小学生写不了那么多……

至于GPT-4这边的表现,内容质量自然更好,也体现了整个思路过程。但要完全生成超过了三十秒。单是读后感内容的生成,也有近二十秒钟的时间。

除了Demo演示外,Groq现在支持API访问,并且完全兼容,可直接用OpenAI的API进行简单切换。
可以免费试用10天,这期间可以免费获得100万Tokens。
目前支持Llama 2-70B和7B, Groq可以实现4096的上下文长度,还有Mixtral 8x7B这一型号。当然也不局限于这些型号,Groq支持具体需求具体定制。
价格方面,他们保证:一定低于市面上同等价格。
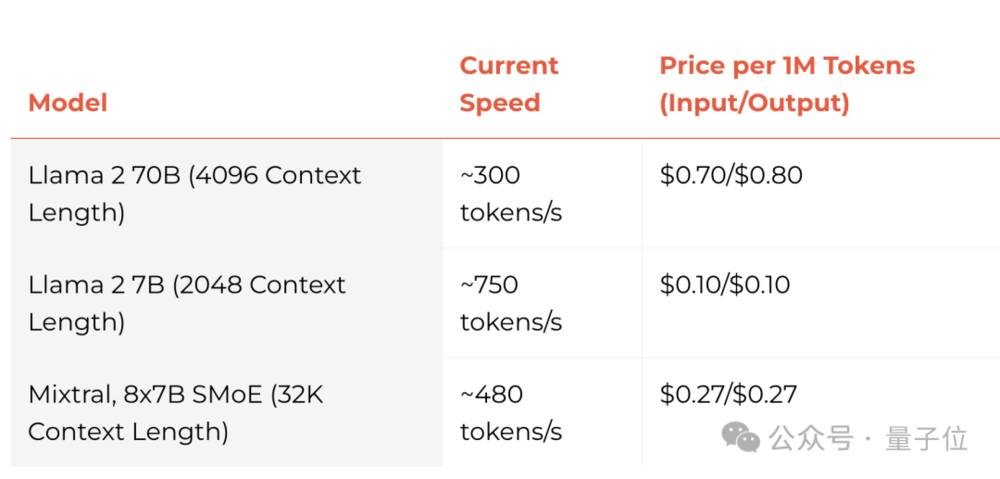
不过可以看到,每秒500tokens似乎还不是终极速度,他们最快可以实现每秒750Tokens。
谷歌TPU团队创业项目
Groq是集软硬件服务于一体的大模型推理加速方案,成立于2016年,创始团队中很多都是谷歌TPU的原班人马。
公司领导层的10人中,有5人都曾有谷歌的工作经历,3人曾在英特尔工作。
创始人兼CEO Jonathan Ross,设计并实现了第一代TPU芯片的核心元件,TPU的研发工作中有20%都由他完成。

Groq没有走GPU路线,而是自创了全球首个L(anguage)PU方案。
LPU的核心奥义是克服两个LLM瓶颈——计算密度和内存带宽,最终实现的LLM推理性能比其他基于云平台厂商快18倍。
据此前他们介绍,英伟达GPU需要大约10焦耳到30焦耳才能生成响应中的tokens,而Groq设置每个tokens大约需要1焦耳到3焦耳。
因此,推理速度提高了10倍,成本却降低了十分之一,或者说性价比提高了100倍。
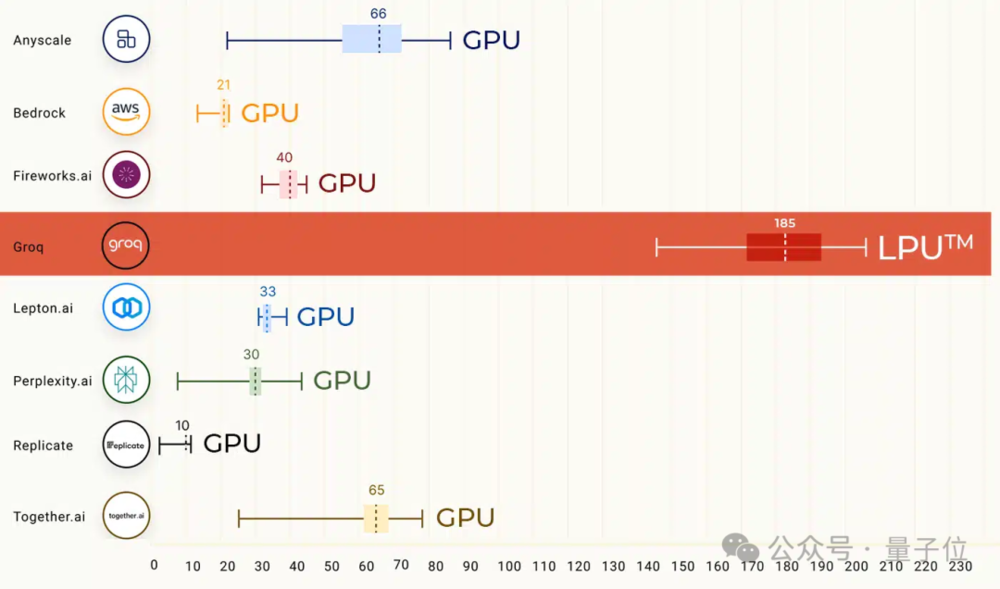
延迟方面,在运行70B模型时,输出第一个token时的延时仅有0.22秒。
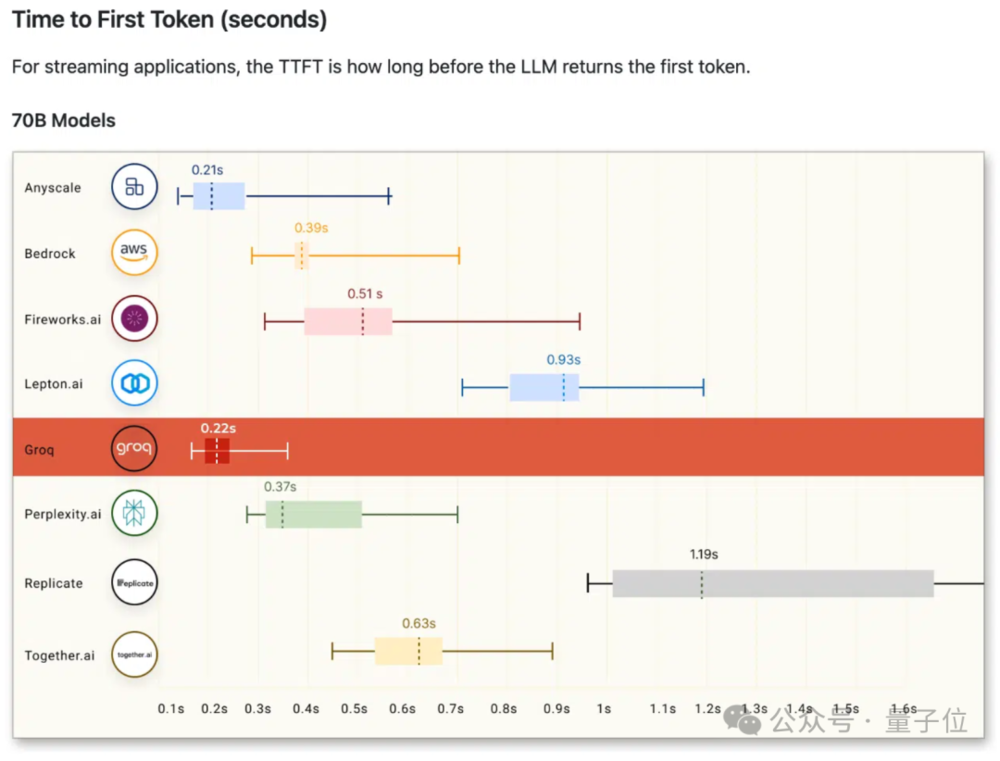
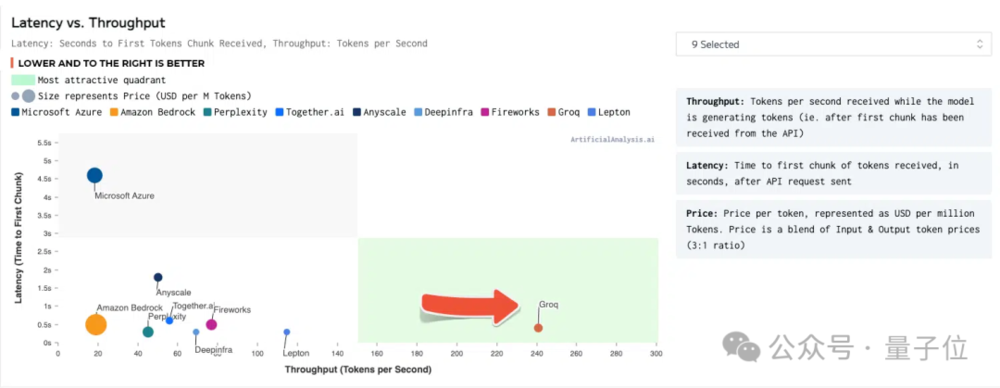
甚至为了适应Groq的性能水平,第三方测评机构ArtificialAnalysis还专门调整了图表坐标轴。
据介绍,Groq的芯片采用14nm制程,搭载了230MB大SRAM来保证内存带宽,片上内存带宽达到了80TB/s。
算力层面,Gorq芯片的整型(8位)运算速度为750TOPs,浮点(16位)运算速度则为188TFLOPs。
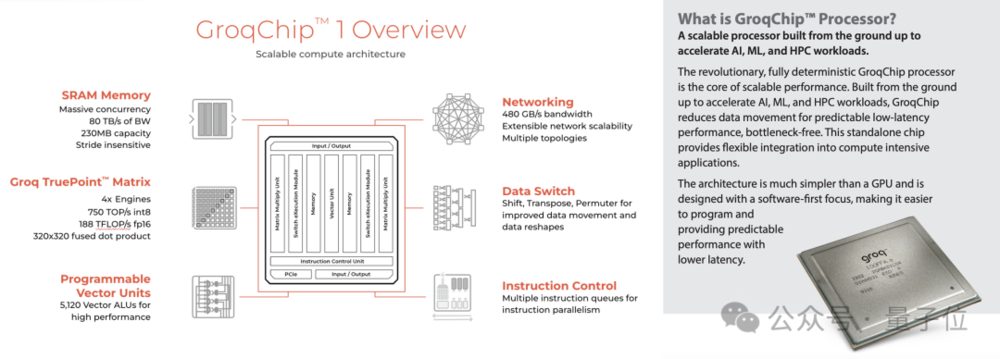
Groq主要基于该公司自研的TSP架构,其内存单元与向量和矩阵深度学习功能单元交错,从而利用机器学习工作负载固有的并行性对推理进行加速。
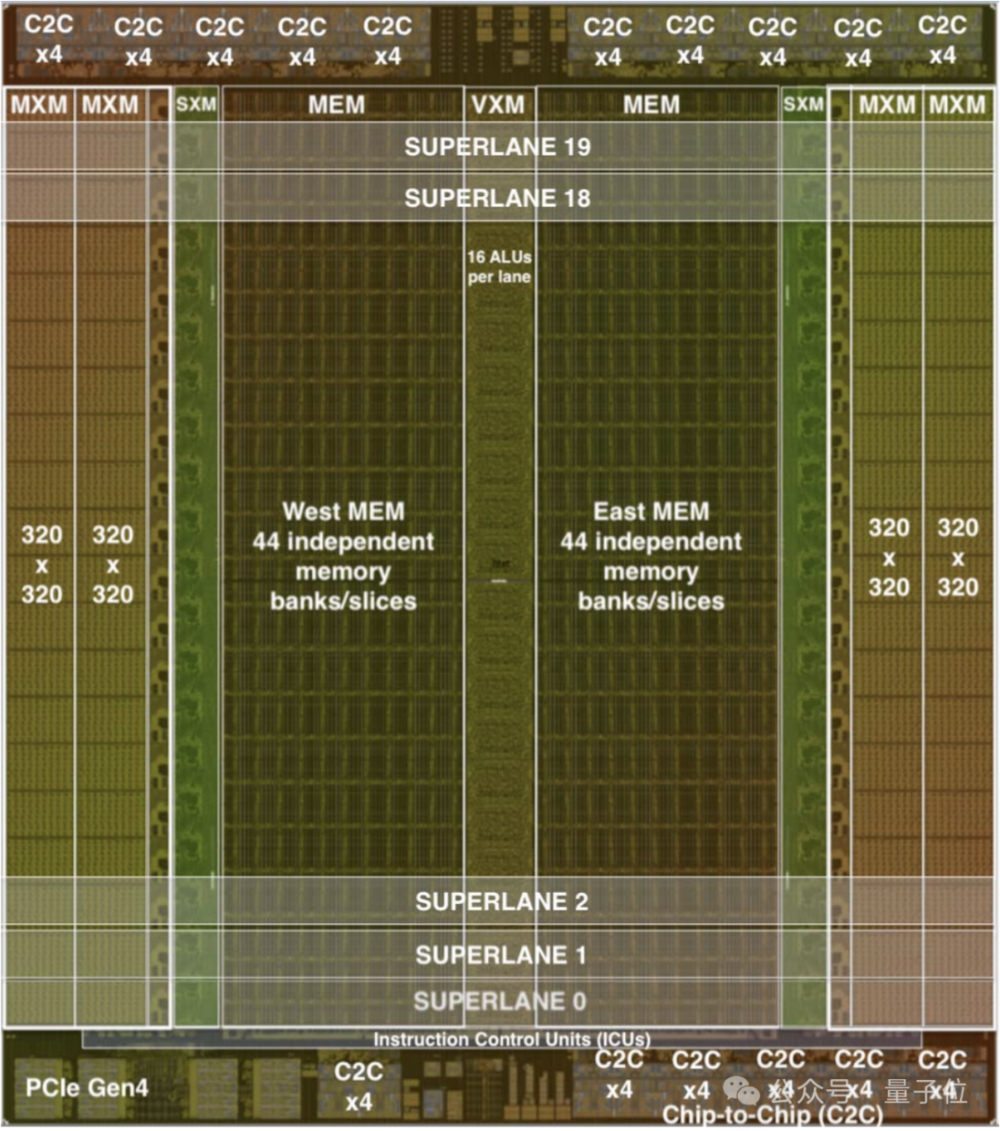
在运算处理的同时,每个TSP都还具有网络交换的功能,可直接通过网络与其他TSP交换信息,无需依赖外部的网络设备,这种设计提高了系统的并行处理能力和效率。
结合新设计的Dragonfly网络拓扑,hop数减少、通信延迟降低,使得传输效率进一步提高;同时软件调度网络带来了精确的流量控制和路径规划,从而提高了系统的整体性能。
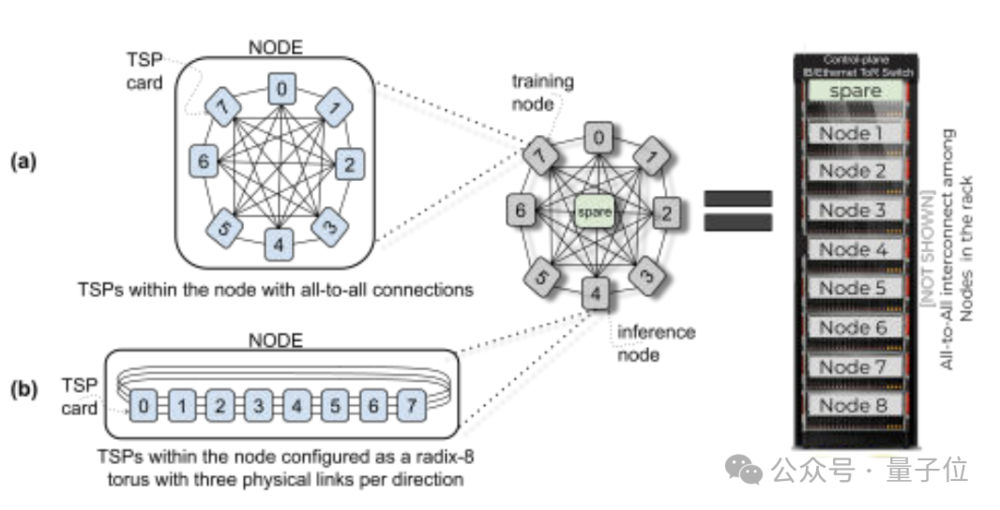
Groq支持通过PyTorch、TensorFlow等标准机器学习框架进行推理,暂不支持模型训练。
此外Groq还提供了编译平台和本地化硬件方案,不过并未介绍更多详情,想要了解的话需要与团队进行联系。

而在第三方网站上,搭载Groq芯片的加速卡售价为2万多美元,差不多15万人民币。
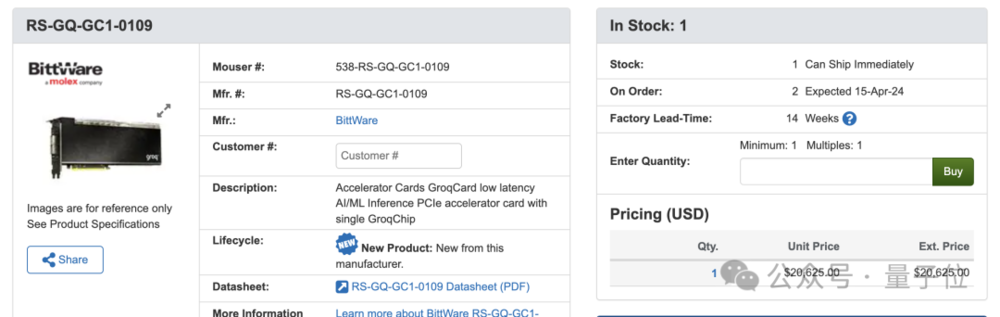
它由知名电子元件生产商莫仕(molex)旗下的BittWare代工,同时该厂也为英特尔和AMD代工加速卡。

目前,Groq的官网正在招人。
技术岗位年薪为10万~50万美元,非技术岗位则为9万~47万美元。

“目标是三年超过英伟达”
除此之外,这家公司还有个日常操作是叫板喊话各位大佬。
当时GPTs商店推出之后,Groq就喊话奥特曼:用GPTs就跟深夜读战争与和平一样慢……阴阳怪气直接拉满。
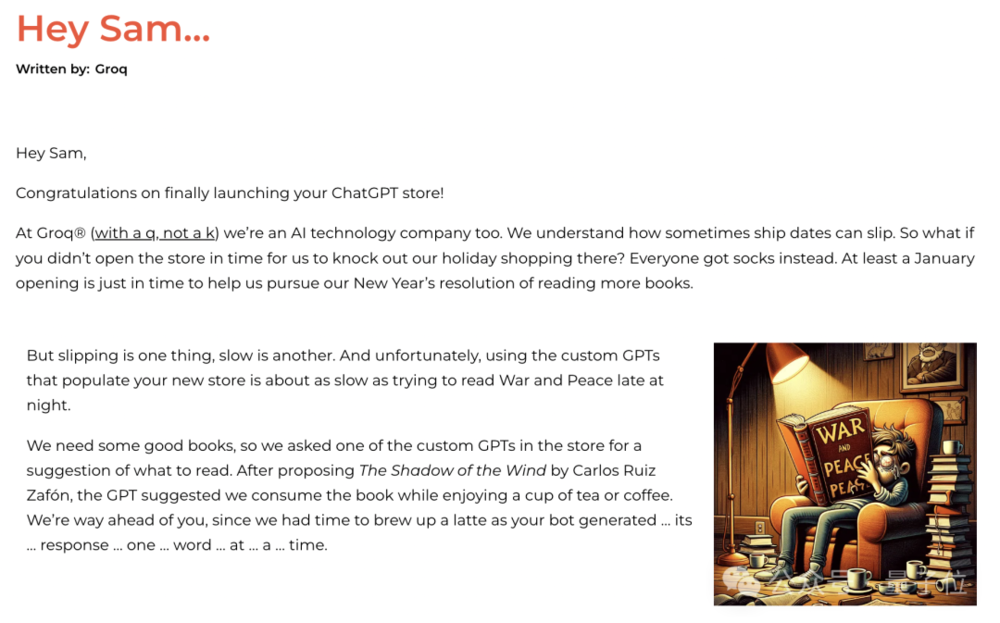
马斯克也曾被它痛斥,说“剽窃”自己的名字。

在最新讨论中,他们疑似又有了新操作。
一名自称Groq工作人员的用户与网友互动时表示,Groq的目标是打造最快的大模型硬件,并扬言:
三年时间内赶超英伟达。

这下好了,黄院士的核武器有新的目标了。
参考链接:
[1] https://wow.groq.com/
[2] https://news.ycombinator.com/item?id=39428880å
本文来自微信公众号:量子位(ID:QbitAI),作者:白交、克雷西

 05:44
05:44


 11:57
11:57





 14:24
14:24


 11:51
11:51
 05:19
05:19
 09:31
09:31
 11:13
11:13
 06:21
06:21
 10:32
10:32
 07:19
07:19



