2018-11-07 20:42


扫码打开虎嗅APP

本文来自微信公众号:蓝狐笔记(ID:lanhubiji)。
基因测序行业在近二十年的时间里,发生了巨大的变化,其中一个最让人吃惊的变化是它的测序成本大幅下降。2001年,人类基因组完成测序,耗资高达30亿美元,而现在成本降至1000美元,随着时间的推移,甚至有可能降低到100美元以下。
如此幅度的成本下降,意味着大规模人群采用的条件已经初步具备。那问题来了,就算是价格普通人可以负担,但对于人们来说,为什么要去做基因测序?目前看有几个好处:一是便于更好做疾病诊断;二是做疾病的提前预防,通过基因测序发现患某些病的概率较高,可以提前采取措施。如好莱坞明星安吉丽娜·朱莉进行基因测序之后,发现自己有易患乳腺癌的基因,因此采取措施提前切掉乳腺。(当然,从科学角度,这并不是说一定需要采取这样的措施,或者采取这样的措施之后就一定能解决问题,仅目前来说,这里提供了一个可供选择的预防方案。);三是有助于创建个性化治疗方案。
这是从普通个人来说的直接好处,从行业发展的角度,或者从整体人类利益的角度,如果通过某种方式,能实现把基因组数据共享给研究者,这对研究人员找出规律,提供个性化保健方案、治疗方案或研发新药等都有帮助。
如果实现了基因组数据共享,这里有机会诞生一个数十亿美金以上的基因组数据市场。不管是基因组数据的所有者、还是基因组数据的需求方,都会从中获益。
那么,如何来创建基因测序的交易市场?它需要解决哪些问题才有机会真正创建?这就是本文试图阐述的地方。
本文以Nebula Genomics为案例进行阐述。这也是蓝狐笔记最近关注的一个试图通过借助区块链技术和模式来创造基因测序市场的案例。
Nebula Genomics:创造基因测序市场的梦想
Nebula Genomics为了推动基因测序行业的发展,试图在多个方面进行探索。
首先是Nebula Genomics要继续推动基因测序成本的显著降低,唯有如此,才能让更多普通老百姓参与进来,参与的人越多,意味着基因组的数据越多。
其次,大多数人对新事物,尤其是基因测序这样涉及个人隐私和安全的事情会比较在意,也会有疑虑,如果不能解决普通人的担忧,那么,即使价格便宜,也会遇到走向主流人群采用的障碍,所以,Nebula Genomics会优先考虑提高基因组数据的安全和保护。
最后,这个行业存在着基因组数据的明显需求者。但是,目前这些需求者能够得到的基因组数据少之又少。Nebula Genomics也希望让基因组数据的买家能够更有效率获取更多的数据。
基于以上明晰的思路,Nebula Genomics试图通过区块链技术来解决问题,以一种去中心化、加密的方式来达成目标。
基因组数据交易市场为什么有机会?
先来看看什么是基因组数据。蓝狐笔记参考了相关基因组资料,先给大家简要分享关于基因组数据的基本概念。
DNA(脱氧核糖核酸)是一种链状分子,它编码每个生物体蓝图。DNA由四个构建块组成,其链状分子的长度可变。DNA的构建区块由字母表示,包括A(腺嘌呤)、T(胸腺嘧啶)、C(胞嘧啶)、G(鸟嘌呤)。细胞中发现的DNA总数称之为它的基因组。基因则是DNA的序列,它可以编码蛋白质生产指令,是多功能的分子机器。人类的基因组大约有64亿个字母。人类基因组中的大多数功能序列还是未知世界。
那么,为什么要对DNA进行测序?
科学家在研究过程中发现了DNA的功能和结构,他们试图通过读取更多的DNA序列,研究它们,找出规律。前面也提到,一开始基因测序成本很高,几乎不可能用于主流人群。但,该领域的技术发展迅速。新一代的测序机器可以实现对数亿分子的并行读取。新技术的进步让DNA测序成本极速下降。另外,通过蛋白质编码基因组区域的靶向测序也利于降低成本。
目前市面上也有不少的个人基因测序公司,比如Ancestry和23andMe公司。两家公司使用基于DNA微阵列的基因分型来实现基因检测。不过它不是对连续的DNA序列进行测序,而是以大致规律的间隔来识别单个字母。它们采用的方法无法全面识别字母,它们目前产生的数据对于基因组数据拥有者和研究者来说,价值相对有限。
从全基因测序数据中,个人可以全面了解个人基因组成。研究者也能在更多数据中,不断更新迭代研究结果。全基因测序数据对研究人员价值更大。比如说,全基因测序是鉴定非编码DNA变体的唯一方法。在现实中,超过90%的临床重要的DNA部分都落在非编码区域。这也意味着,全基因测序有可能是发现治疗靶标的主要手段。目前来看,测序模式对于微阵列的基因分型模式,有它的优点之处。如果能在实践中证明更有效,那么,它在基因组市场上,会产生很重大的影响。
对于个人来说,好处是什么?
前文也简要提及了基因组测序对个人的可能潜在好处。下面更详细地阐述其好处。
地球上任何两个人的基因组中有99.9%是相同的。而剩余的0.1%则决定了每个人的差异。0.1%的差异中有超过400万的基因变体,这些变体产生了人与人之间的不同,包括身体特征、性格以及疾病倾向。
这也就是说,如果完成每个人的全基因测序,就可以找出每个人独一无二的地方。它可以为健康相关的事情做出最佳选择,包括减肥、锻炼、医疗、生育等。如果一旦成为现实,这意味着个性化的精确医疗保健时代成为可能,可以根据每个人的基因组特性,提前做好预防措施。
医疗处方上来看,FDA批准的药物中,有超过7%的药物会受基因变体的影响,导致一些患者会出现对药物产生不良反应。如果有了全基因测序,医生可以向患者开出更合适的药物和更合适的剂量。比如有一种药物叫warfarin,它是一种常用的血液稀释药物,但它可能会导致部分患者内部出血,这部分患者往往是携带了增强其血液稀释效应的基因变体。
预防性治疗来看,大约有2%的人在高度“可操作的”基因中携带早发性致病变异体。这些基因跟存在治疗的病理相关,可能改变个体的结果。比如,BRCA1和BRCA2基因的突变会显著增加乳腺癌和卵巢癌的风险。从预防性的角度,它会建议具有这些基因变异的妇女经常接受筛查。
对于大多数人来说,基因变体中携带有致命性的变体不多,但仍有问题。比如脂肪肝疾病影响了8000万美国人,但它有时候很难被发现,超过50%的人口基因变异增加脂肪肝并发症的风险。
优生优育方面来说,两位计划生孩子的父母可以进行基因测序,以此发现他们生下来的孩子可能的健康情况。通过父母双方遗传的疾病相关的变体,导致后代的患病风险。目前看,全世界的5%人口中患有遗传性疾病,这些绝大多数病症都从上一辈遗传来的。这些都是可以通过全基因测序进行检测。
减肥方面,目前已经发现基因变体会影响减肥策略的有效性。这意味着,不同人有不同的有效减肥策略,可以根据不同人的基因变体制定个性化的减肥方案。
体育锻炼方面,基因变体也与体育成绩相关,包括耐力、肌肉量、运动受伤风险等。比如,韧带撕裂的风险跟胶原蛋白基因的变体相关,对于某些基因变体的人来说,拳击等运动中的头部击打会显著增加脑部疾病的风险。这也意味着,不同的基因变体,对于不同人的运动机能影响是不同的。
这也就能理解,为什么在运动场上,有些人可以长达十年以上的持续高水平,如足球场上的梅西,而还有些人则是玻璃体质,虽然天赋很高,但容易受伤。其中部分原因也跟每个人的基因变体相关。如果进行了基因变体的测序,一是可以测试个体有没有持续的竞技水平可能,二是也可以针对性的进行预防和改善。
最后一个是基因编辑方面。基因工程首先要鉴定出导致身体特征和疾病易感性的基因变体。然后在此基础上进行基因组的编辑。比如,让肌肉生长抑制素基因失去活力有可能可以治愈退化肌肉疾病。
从产业需求来看,产业为什么有这么强的动力来获取基因组数据和表型数据?
研究人员和生物公司、制药公司都受制于基因组数据缺乏、数据质量低、数据采集效率低、数据获取成本高等因素影响。
基因组数据的可用性还很低。原因是因为目前的数据样太小,很少有人做过全基因组的测序。如果没有大的基因组数据集,就比较难建立基因变体和性状之间的关联性。不仅是数据,还需要通过机器学习来研究,比如深度学习,通过大量的模型训练,获得真正有意义的结果。目前看,基因组学领域还很难获得AI学习所需的足够数据量。
表型数据是指包括所有个人特征在内的信息,也包括病史等。表型数据和基因组数据一起用来鉴定基因变体和性状之间的关联。但目前来看,表型数据有几个问题:一是数据需求方对随机数据集不感兴趣,而对具有特定表型的个体数据集感兴趣,而是数据购买者会从有某些表型特征的个人中获取数据。其次,基因组数据的拥有者需要有意愿来提供表型数据,没有表型数据,只有基因组数据就没多大作用。最后,目前收集的表型数据质量不稳定,通过中间人收集存在问题。
从数据采集看,效率低下。目前现状是,制药和生物技术公司从一些非营利或营利组织获取基因组的数据。但整个购买流程效率低下,很难满足需求。一是数据采购流程没有自动化,需要签订合同、付款、传输数据等,这些人工劳动对数据采集来说,不够高效。二是,不同来源的基因组和表型数据通常采用不同的数据格式编码,这让标准化不同数据集变得非常耗时。这些问题都是生物和制药技术公司头疼的问题。
基因组大数据还不是真正的大数据,很难用作机器学习,也不利于后续的研究发展。据估计,目前人类完成基因测序的人口才100万人,0.02%的人口都不到。即便如此,由于单个人的基因测序通常会产生很大的数据量,大约能达到200千兆字节,必须使用计算密集型计算处理。这意味着如果未来有上亿人口进行基因测序的话,会面临很大的挑战。一是需要大量的存储空间来存储基因组的数据;二是网络传输的速度也会对数据共享造成困难;三是基因组大数据的处理和分析需要大量的算力支持。
Nebula网络存在的目的就是要解决以上的问题。
Nebula模式重塑基因测序行业
Nebula模型跟传统模式完全不同。它试图通过去中心化的模式来重塑基因测序行业,它构建的基因组数据交易市场,在数据掌控权、数据的隐私和安全保护、经济体系、大数据的准备等方面都有自己的解决方案。
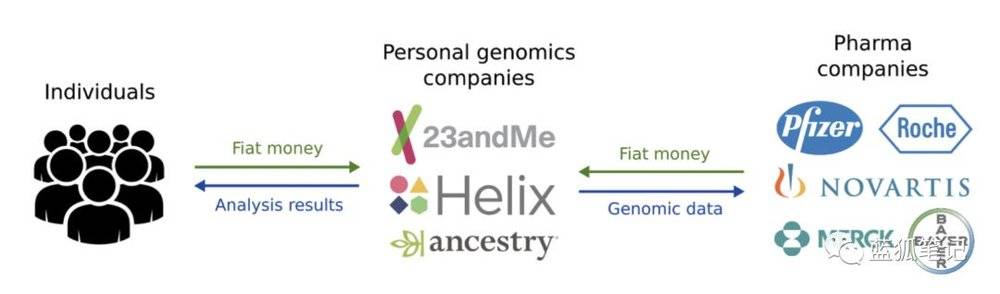
(传统模式)
首先是数据的控制权和安全保护。
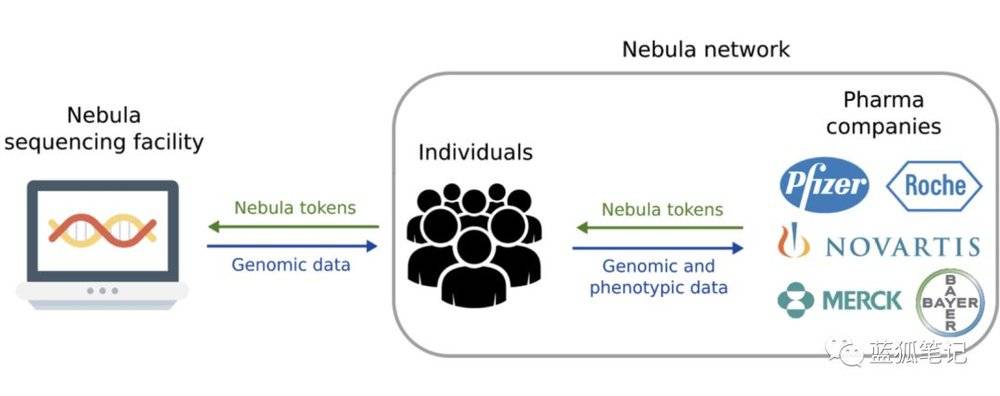
(Nebula模式)
在传统的基因测序行业的商业模式中,人们不仅给基因测序公司付费以获取分析结果,同时,这些公司还会把这些基因组数据进行二次获利,把它们卖给需要这些数据的制药和生物技术公司。
Nebula模式则不同,个人付费给测序服务提供者之后,测序的数据归个人所有(将来测序仪器如果便宜,个人也可以自行测序)。生物和制药技术公司如果要获得基因测序数据,必须向用户购买,而不是向之前的测序公司购买。这改变了基因测序数据的归属权问题。
同时基因测序数据还通过Nebula网络获得保护。个人的数据由个人存储,包括个人基因测序和表型数据。数据所有人控制访问的权限。此外,Nebula还使用英特尔的软件保护扩展(SGX)和同态加密对共享数据进行加密和安全分析。
为了保护个人的隐私,在数据的买卖过程中,数据所有者是匿名的,而数据购买者必须是透明的。所有的数据交易记录都不可变地存储在Nebula区块链中。
其次,token模式而非法币模式。
在传统的模式中,个人向基因测序公司支付法币以获得测序结果,生物和制药技术公司也是向基因测序公司支付法币以获得研究数据。
而Nebula的token经济模式中,形成了Nebula内部的一套经济体系。
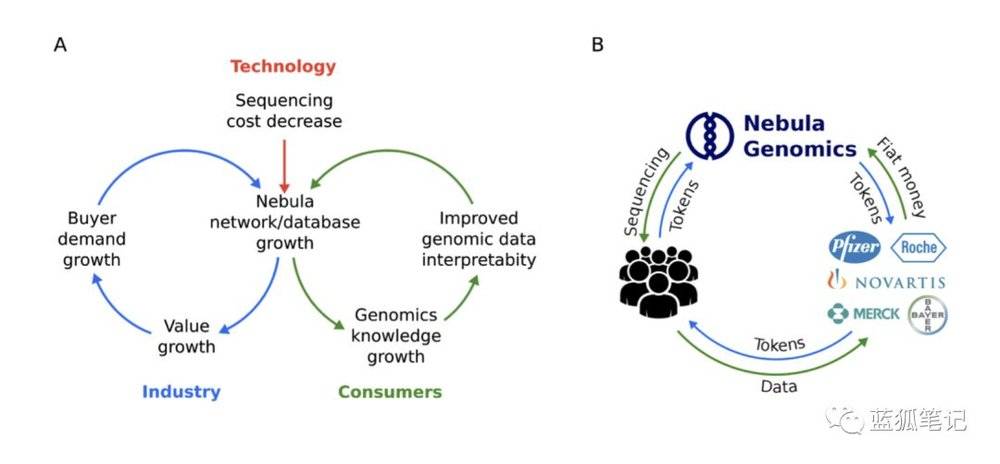
从上图可以看到Nebula的token主要用于内部经济体系的循环。个人在Nebula测序的设施中获得个人的基因测序服务,需要用Nebula 代币支付,而生物和制药技术公司也需要用Nebula代币来购买基因组数据和表型数据。
从这个模型中,Nebula代币的价值增长主要根源于整个Nebula网络的增长。它通过降低测序成本,吸引更多个体加入测序,而同时行业的需求也在增加,进一步降低测序成本。而随着基因组数据的增加,能够给用户带来更多的好处,比如疾病预防、减肥、生育管理等,这会进一步提升对基因组数据和表型数据的需求。而这个Nebula的经济体系中,流通的是Nebula代币,这个代币的价值会随着Nebula网络整体价值的提升而增加。
再次,基因测序成本更低。
Nebula通过提供基因测序数据交易市场极大降低测序成本。为什么这么说?一是没有基因测序数据的个人可以加入Nebula网络支付token后获得测序数据。由于生物和制药技术公司对有表型的个体感兴趣,这样,这些公司可以提供补贴,降低基因测序成本。同时,随着参与测序的机构越多,需求也越大,也许某一天,用户可以免费获得基因测序的服务。同时,已有基因测序数据的用户也可以通过加入Nebula网络进行数据的售卖获得收益。
第四,数据采集效率更高。
Nebula网络通过基因测序市场推动用户测序的意愿。尤其是它对用户的疾病预防、减肥、优生优育等方面都有潜在的积极意义。这导致用户加入测序的意愿大增。
同时,通过Nebula网络还可以解决数据孤岛的问题。它通过去中心化的私有数据存储方式来解决数据碎片化问题。所有拥有基因组数据的个人或组织都可在Nebula网络上提供数据,同时保留数据的所有权。
另外,数据需求方和提供者可以直接联系,能够有针对性获得高质量的表型数据。基于Nebula的智能合约的调查工具可以帮助数据购买者更高效的获取目标数据。Nebula网络会提供基因组和表型数据的标准格式。最后,智能合约的有效应用,也会促进数据采购的加速,自动签署合同,自动付款和传输数据,这都会让比原来的人工过程高效很多。
最后,可为大数据爆发做好准备。
鉴于基因组数据非常庞大,通过让数据所有者存储自己的数据,解决了中心化数据存储的问题。Nebula计划使用可用的边缘网络存储空间。此外,为了便于数据需求者计算基因组数据,Nebula还引入特定的数据编码格式,也方便基因组数据在网络上快速传输。数据需求者可方便利用支持英特尔软件保护扩展(SGX)的任何计算硬件资源,他们可以在Nebula Genomics提供的计算节点、买家自己的节点或其他第三方节点上分析数据。
Nebula网络:Blockstack平台与Nebula区块链
Nebula网络建立于Blockstack平台和以太坊驱动的Nebula区块链上。那么,Nebula网络由哪些节点组成?它的基因组数据是怎么来的?基因组测序数据是怎么处理的?又是如何存储的?如何保证隐私和安全的?测序数据和表型数据的交易记录会记录在哪里?它后续会不会把测序过程也实现去中心化?
这些问题都是构建真正可落地的基因组数据交易市场的重要问题。
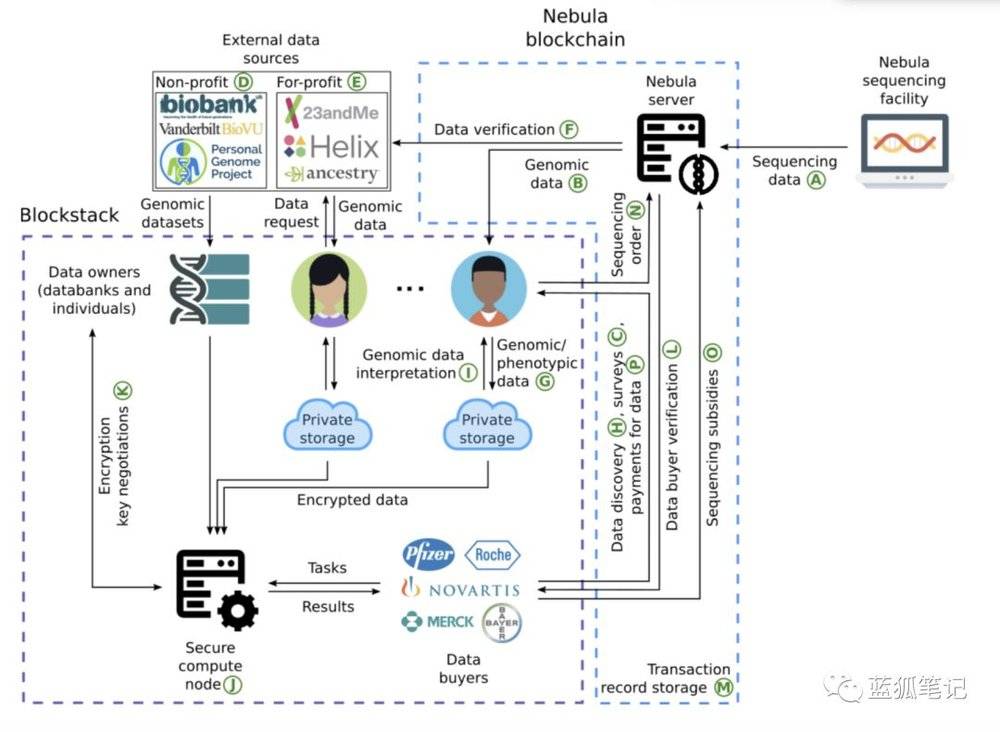
(Nebula网络)
首先来看Nebula网络的节点。
Nebula网络包括数据所有者节点、数据购买者节点、安全计算节点、Nebula服务器。数据所有者节点包括两部分主体,一是想要共享基因组数据和表型数据的个人,二是拥有基因组数据库的组织。
数据购买者节点一般是制药和生物技术公司。他们会使用Nebula代币从数据所有者中购买基因组和表型数据,并分析安全计算节点上的数据。完全计算节点运行Arvados生物信息开源平台以计算基因组数据。安全计算节点可以由Nebula Genomics,数据购买者或其他第三方操作。
Nebula服务器处理主要是处理Nebula测序设施中生成的测序数据,同时验证来自外部的基因组数据,验证数据购买者的身份。
其次,Nebula网络的基因组数据是怎么来的?
Nebula测序设施预计使用下一代的DNA测序技术。新一代测序技术会产生数十亿的约250个字母的短读数。一个人的基因测序文件大概约10个测序读数,大小达到150~200千兆字节左右。Nebula Genomics计划与Veritas Genetics合作测序。通过与Veritas合作,Nebula Genomics可以符合监管,也不用担负“得到认证的DNA测序设施”的相关运营成本。
除了使用Nebula测序设施产生的基因组数据,其他来源的数据也可以在Nebula网络上出现。比如数据所有人使用Nebula的工具将它的数据转为基因组拼块格式。Nebula服务器会验证数据的真实性。数据所有者也需要提供真实性的证据。另外,在Nebula网络上提供基因组数据集的组织则需要Nebula Genomics的工作人员的验证。同时,数据所有者也可选择在未经验证情况下提供数据,由市场买家来决定是否愿意为这一类数据付费。
除了基因组数据之外,为了发挥数据的作用,也需要表型数据的配合。而表型数据的生成主要依赖于向数据所有者发布调查问卷。通过调查问卷反馈提供该个体的症状、处方药物和诊断等。Nebula也在参与跨数据库的表型数据标准相关工作。
再次,Nebula基因组数据是怎么处理的?
当前在Nebula网络上产生的测序数据将在Nebula服务器上处理。首先将测序读数参考人类基因组,对比后重建基因组序列,之后标识出基因变体。同时,为了实现快速传输,变体的编码列表需要考虑节省空间。编码方案还需要考虑支持有效计算,尤其是支持机器学习。Nebula将采用基因组拼接的编码方案。
基因组被分成重叠的可变长度序列,每个拼接块都由所包含测序的哈希摘要代表。所有拼块位置中的拼块变体都收集在拼块库中。它们会随着新基因测序和新变体的发展不断增加。个体基因组由测序的哈希数组代表。这些哈希数组会转移到数据所有者节点,之后可共享给数据的需求者。这样做的好处是可以实现快速的网络传输,因为个体的基因组通过哈希数组来代表,大小只有10兆字节。
另外测序读数文件也会传输给数据所有者节点,文件很大,约有150到200千兆字节,但只需从Nebula服务器传输过去,一次即可。这些数据不会跟买家共享。一旦文件传输完成,所有数据会从Nebula服务器中删除。
第四,基因组数据和表型数据是怎么存储的?
数据存储和访问的控制会使用Blockstack平台,平台也可以构建去中心化应用。Blockstack存储系统允许用户选择自己的存储提供商,比如Dropbox,并管理其对数据的访问。
Blockstack也支持数据发现,可实现表型注册表。数据需求方可以查询数据所有者节点,浏览过去的调查,识别参与过特定调查问卷的数据所有者。
由代表个人基因组的哈希数组引用的拼块库会存储在公共的存储中,比如IPFS或BitTorrent。所有Nebula网络上的节点都能够访问拼块库。尤其是,计算节点进行数据分析时访问拼块库。
第五,基因组数据如何实现安全计算的?
Nebula网络目前使用Arvados生物信息开源平台来处理和管理基因组和表型数据。这个平台主要是为基因组和其他大规模生物医学数据设计,包括IBM Watson等在内的不少大型机构客户也在使用。同时,为了安全计算,Arvados在适用于安全计算节点上的英特尔软件保护拓展(简写是SGX)区域内运行。
SGX是一组指令代码,可以扩展英特尔x86架构,并允许专用内存区域的创建。其中代码和数据是隔离的,并受到外部处理的保护。总之,英特尔软件保护扩展(SGX)允许不受信任的第三方对私有数据进行安全的远程计算。它实现了安全计算,同时这些计算比同态加密数据计算和安全多方计算的效率要高。
此外,通过将SGX与同态加密的混合,可以加速特定的计算。在Nebula网络中,数据所有者使用安全计算节点进行加密和共享个人基因组和表型数据。
不少生物信息计算的第一步是生成列联表,包含基因组变体计数和相应表型。列联表计算仅需加法运算,可以使用加性同态加密方案执行计算。首先,每个数据所有者节点使用加性同态加密方案加密值1或0,表示基因组变体存在或不存在。之后,计算节点会对SGX专用内存区域之外的所有加密值求和。加密的求和可以在SGX专用内存区域内进行解密,执行进一步计算。因此,加性同态加密可以将解密数量减少至一个。
由于使用SGX有两个主要缺点。一是必须仔细设计软件以实现在SGX 专用内存区域内部运行,同时不会把私有数据泄漏。二是所有计算必须在英特尔CPU上执行,意味着计算不能用GPU加速。但后续的机器学习,需要从GPU加速中获益。
为解决这个问题,Nebula采用了SGX 专用内存区域和GPU加速计算中的数据保护混合方法。数据会在SGX 专用内存区域中聚合和预处理,但是计算密集型的计算会在SGX 专用内存区域之外的GPU执行。SGX 专用内存区域的预处理通过三种方式来保护数据的隐私。一是所有数据完全匿名化,SGX预处理隐藏输入数据的来源。二是只聚合数据汇总,比如列联表。哈希数组编码所有基因组,它们不会被暴露出来。三是随机噪声会添加进入数据,以增强安全。
SGX-GPU混合模型的还有一个好处是Arvados的复杂性可以保持在SGX专用内存区域之外。这会极大减少工程量。
第六,Nebula网络提供卖家隐私保护
以太坊区块链为数据所有者节点提供一定程度匿名保护。网络地址是加密标识符,与任何个人信息无关。此外,对于买方需要进行验证。从基因组数据的所有者角度,他们都想知道自己的数据卖给了谁,他们是不是靠谱。为了实现买家的透明,他们需要提供真实信息,并在法律上确定不能把数据分享给其他第三方。这些认证工作由Nebula工作人员完成验证。
第七,Nebula网络的区块链服务
Nebula基因组数据交易市场的所有交易记录都会记录在Nebula区块链上,这是不可篡改的记录。
Nebula将为合作伙伴提供测序设施,包括价格合理的全基因组测序服务。该服务可以使用Nebula代币支付。同时,随着DNA测序价格下降,还会变得更便宜。另外,数据购买者也可以补贴个人的测序成本。
此外,Nebula调查工具会使用以太坊区块链的智能合约,可以让数据购买者创建高度定制化的调查。比如可以向所有参与调查的人支付同样的Nebula代币奖励,也可以根据不同的贡献奖励不同数量的代币。
数据购买者也可以使用以太坊智能合约来购买个人基因组数据。数据所有者收到代币支付之后,他们的加密基因组数据会传送到安全计算节点进行计算。表型数据的购买也采用类似方式。
第八,基于Nebula网络也会产生有价值的第三方应用
跟其他的中心化的应用程序平台不同,Nebula采用去中心化的模式来汇聚基因组数据。基因组数据由个体用户自己控制。
比如,数据所有者可以利用Nebula的基因变体解释器进行个人基因组的数据解读。Nebula的变体解释器是基于Blockstack的分布式应用,在用户本地数据上执行。Nebula最初版本的变体解释器是基于Veritas的变体解释器。这里还有一个正向循环的好处。随着Nebula数据库的增加,会发现更多基因和健康之间的关联关系,这会让Nebula的变体解释器的表现越来越好。由此吸引更多人加入到Nebula的网络。如果实现了这一点,这会成为一个自我增强的系统。
最后,Nebula对于测序本身也会采用去中心化模式吗?
相比较于传统模式,通过去中心化的数据存储和安全计算,Nebula在基因组数据保护方面达成新的高度。但是,数据的生成依然是在中心化的测序设施中发生。如果测序设施的受到攻击,基因组数据也有可能会被盗取。要避免这种风险,唯一办法是连测序本身也实现去中心化。
最理想的情况是,个人购买DNA测序机器自行测序,这样就不用通过中心机构的测序设施来完成测序。当然,目前看,还不现实。因为当前的DNA测序仪器很大,很贵,价值可达100万美元,也不易操作,普通用户很难承受。
当然,技术也在发展,也许未来可能诞生手机一样的DNA测序仪器,成本也能降至1000美元左右。但是,这需要时间。在过渡期内,Nebula Gemonics还会一直寻求最新技术,帮助个人实现可负担的基因测序。而最终的目标就是超去中心化的测序模式发展。
结语
传统的基因测序模式很难建立起真正的基因组数据交易市场。因为它很难解决基因组数据归用户所有的问题,无法调用用户参与积极性,在获取大规模数据方面存在天然的障碍。
而利用区块链的去中心化模式,则带来改变。以Nebula为例,它首先把基因组数据的所有权归还给个体。其次,它构建了能够保护用户数据的安全计算。再次,它充分利用智能合约、区块链技术以及代币体系。
这样的结果是,Nebula的模式可以实现基因组数据的买家和卖家直接交易,跟传统的模式不同,数据的买家和卖家之间的交易降低了成本。成本的降低导致基因组测序服务价格更加便宜,推动更多人参与进来。更多人参与进来,导致数据价值的提升,数据价值的提升能够让基因测序服务本身更有指导意义,包括对医疗、生育、减肥、保健等方面都重要的影响。
尤其是一旦实现了基因组测序数据、相应的表型数据与机器学习的结合,可能会给人类带来很多意想不到的新发现,可以为每个人提供个性化的健康指导。这对于大多数人来说,都具有足够的吸引力。
此外,Nebula通过去中心化的模式也解决了人们对隐私保护的担忧。为了让人们不用担心,Nebula中的基因组数据拥有者可以私下存储自己的基因组数据,同时控制访问权限。数据共享时,也会采用加密安全计算等技术。与此同时,数据的拥有者会保持匿名,数据买家则要求是身份完全透明。Nebula的区块链存储所有的交易记录,这些交易记录都不可篡改。
对于数据的需求方来说,通过从个体用户直接获取高质量的基因组数据和相应的表型数据,可以降低成本,更方便从数据中找出规律,便于研发新药,便于为用户提供个性化的健康方案。
鉴于基因组测序目前的价格还不便宜,还有普通用户在区块链技术及相关技术的使用上还存在一定的易用性障碍,要形成真正的基因组测序交易市场还有很长的路要走。对此,我们要保持清醒的认识,同时也有充分的耐心。
从以上的阐述可以看到,区块链技术和去中心化的模式能够对基因组测序行业产生重塑的作用,期待像Nebula这样的项目能够充分利用区块链,创建出真正的有规模效应的去中心化的基因组数据交易市场。一旦走向正向循环,这会产生前所未有的行业效应。
本文来自微信公众号:蓝狐笔记(ID:lanhubiji)。

 08:30
08:30









 01:51
01:51
 12:52
12:52
 13:48
13:48
 05:31
05:31
 12:33
12:33
 05:20
05:20
 08:15
08:15
 12:22
12:22
 07:13
07:13



