
2024-02-26 08:01
AI芯片的一百种死法

扫码打开虎嗅APP

本文来自微信公众号:远川科技评论 (ID:kechuangych),作者:叶子凌,编辑:陈彬,视觉设计:疏睿,题图来自:视觉中国
前几天,英伟达成为首家市值达到2万亿美金的芯片公司,创造了历史。同一时间,一家名为Groq的初创公司横空出世,扬言“三年之内赶超英伟达”。
Groq狠话的底气,来源于它所开发的芯片——LPU。
LPU的全称是Language Processing Unit,翻译过来就是语言处理单元,是一种新型AI加速器。在它的支持下,大模型的推理速度快得惊人,瞬间能输出长篇幅答案;而使用了英伟达芯片的GPT-4,只能一个字一个字往外蹦。
前者的响应速度最高可达到500T/S,而后者只有40T/S[1]。
这是什么概念?相当于一秒钟生成300个单词,7分钟生成一部《哈姆雷特》长度级的文章。
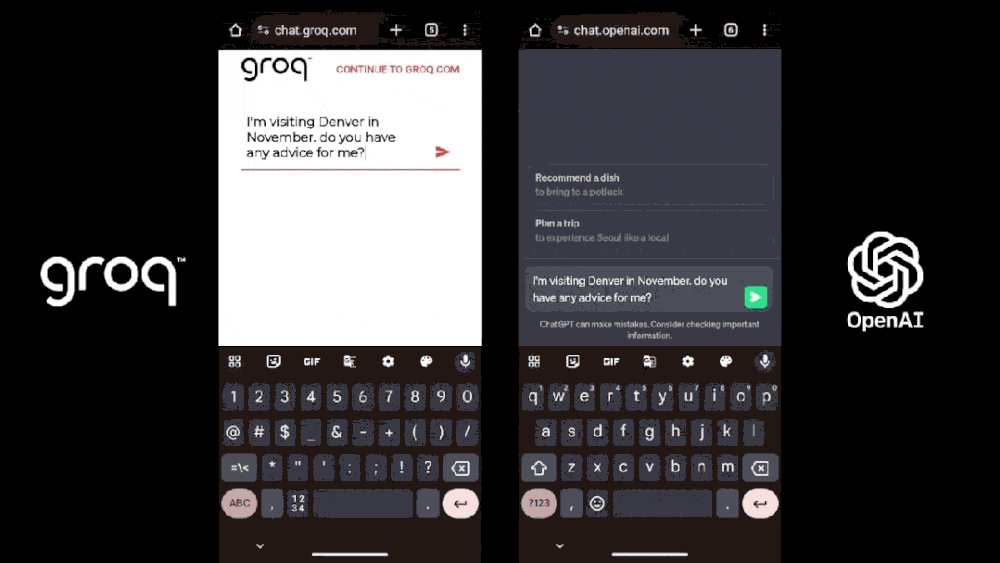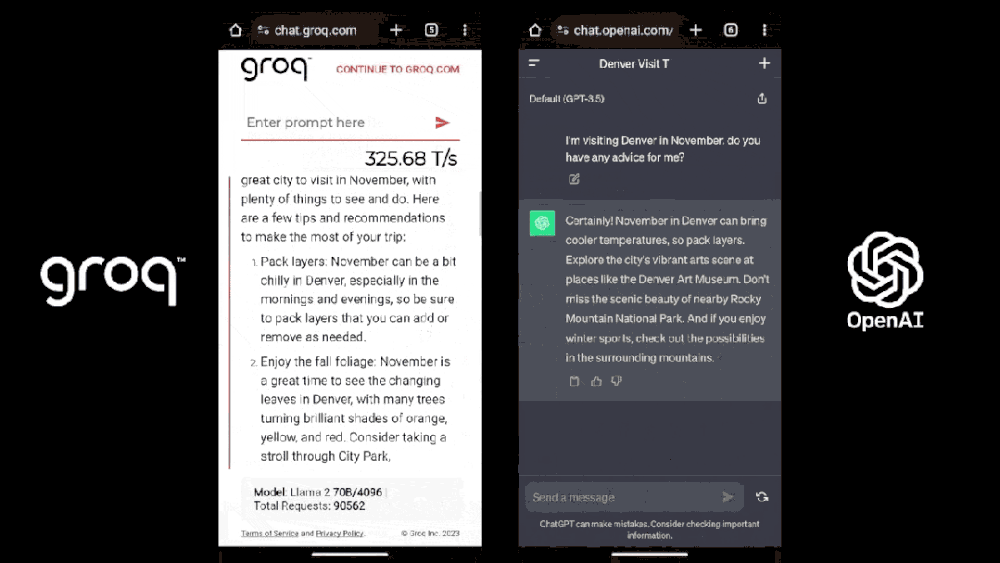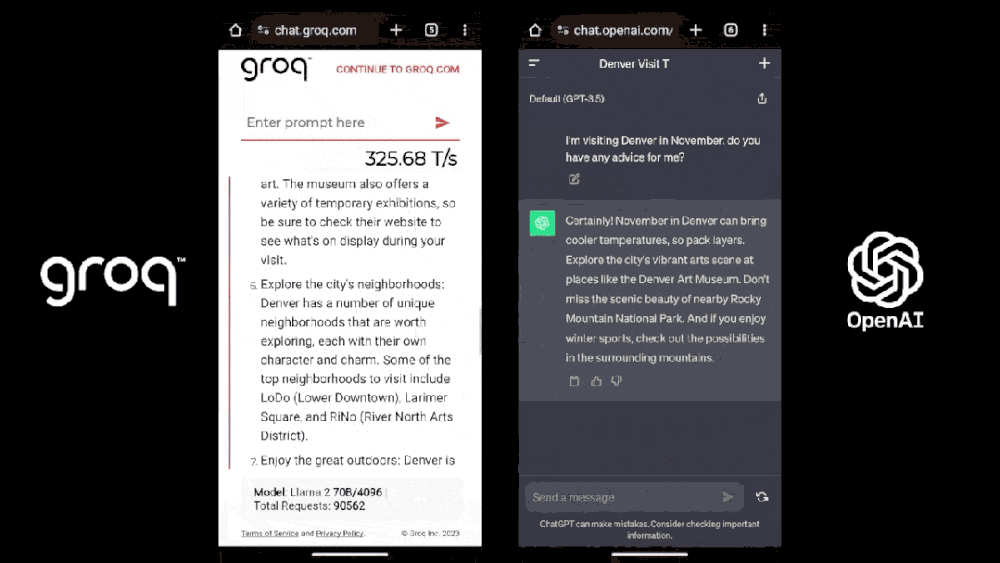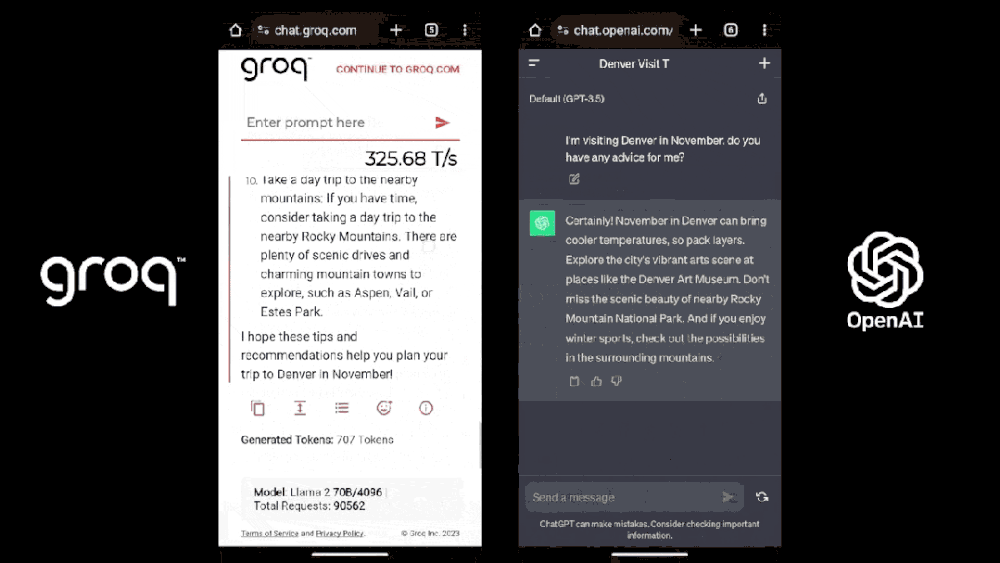
Groq背后的团队也可谓群星璀璨,公司CEO Jonathan Ross是谷歌初代TPU的设计者之一。早期谷歌TPU团队的10位成员中,8位都跳槽到了Groq。
自2016年成立,Groq就饱受市场关注。2020年,Groq的芯片被美国阿贡实验室采用。2021年,Groq获老虎环球基金等机构投资,估值超过10亿美元。
然而,Groq公司的各种“挑衅”,英伟达完全没放在眼里。相比之下,此前“奥特曼7万亿美元造芯”的新闻出来之后,黄仁勋至少还出来说了两句。
毕竟,眼下Groq的种种套路,老黄可再熟悉不过了。
文字游戏
当下,制约AI芯片发展的主要困境,是内存墙:内存的传输速度远远慢于处理器算力,导致性能迟迟上不去。
如果把芯片想象成一个餐厅,那么内存就是仓库,处理器就是后厨。
仓库送菜比后厨烹饪还慢,严重限制了餐厅的出菜速度。因此,包括英伟达在内的芯片厂商,都在围绕“仓库(内存)”做文章。而Groq碾压英伟达的秘诀,也藏在内存结构里。
传统计算机所使用的内存,其实有两种:DRAM容量较大,但传输速度较慢,起主存作用;而SRAM容量较小,但传输速度极快,作为缓存发挥辅助作用。一直以来,二者都是合作关系,缺一不可。
但Groq为了追求极致的速度,摒弃了DRAM,让SRAM扛起了LPU的主存大旗。
这相当于砍掉距离厨房较远的大仓库,直接将所有食材都堆在厨房边的菜篮子里。在这样的设计思路下,LPU不但在速度上形成降维打击,还轻松绕过了两个成本最高的技术:HBM和先进封装。
这也构成了Groq另一个大吹特吹的宣传核心:便宜。
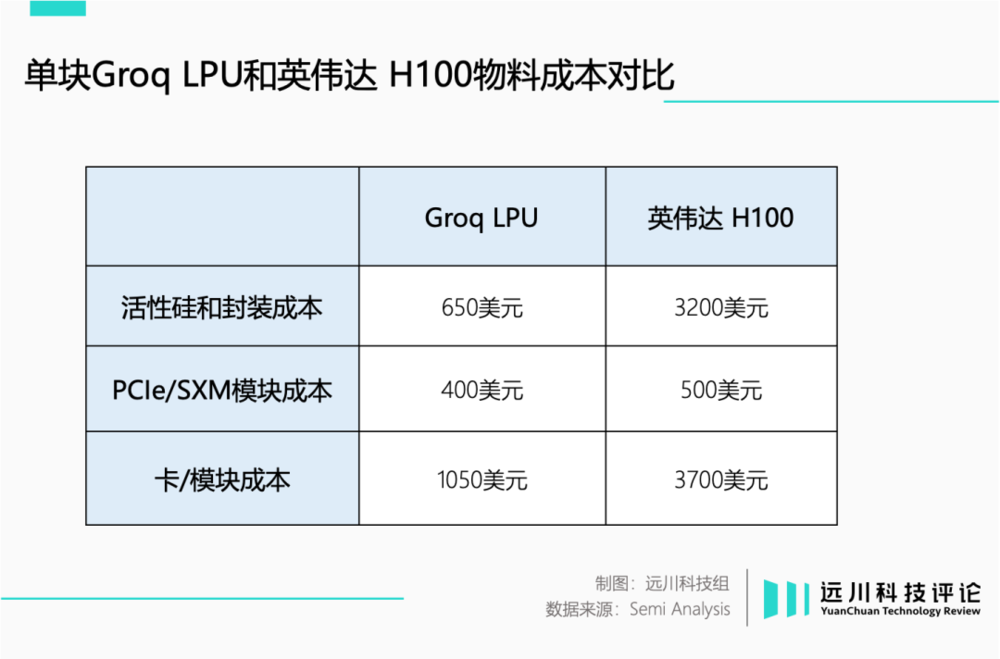
根据Semi Analysis的拆解,LPU由于具备架构优势,物料成本仅为1050美元。相比之下,去年让全球疯狂的H100芯片,物料成本则达到3700美元[2]。
在售价层面,一块LPU的价格是20000美元,远低于H100的35000美元。
但历史无数次告诉我们,大部分弯道超车的结局都是“有田下山”,LPU也不例外。
大模型对内存大小也有着很高的要求。参数量越大的模型,运行时所需要存储的数据也会更多。
SRAM虽然快,但缺陷是容量小,通常只有4MB至16MB。Groq研发团队多年苦心钻研,最终也只是将LPU的容量提升至230MB。而一块H100的内存容量是80GB,两者间差了约356倍。菜篮子再怎么升级换代,终究无法和仓库相提并论。
想装下所有的食材,唯一的办法就是把菜篮子数量堆上去。因此,在运行同样参数的模型时,需要用到的LPU数量就远远高于GPU。
前阿里技术副总裁贾扬清就算了一笔账:
以运行LLaMA 70b模型为例,需要572张LPU,售价1144万美元;但如果换成H100,其实只需要8张,总价格在30万美元左右——所谓的“便宜”压根不成立。
芯片一多,整体的功耗成本也直线上升。LPU每年至少消耗25.4万美元电费,而H100顶多花费2.4万美元。

事实证明,Groq的遥遥领先,只是隐去了核心信息的文字游戏。它所宣传的“高速”,是以近乎夸张的使用成本换来的:运行三年LLaMA 70b模型,LPU的使用成本将比英伟达的GPU高出32倍。
当然,Groq的研发团队显然对此心知肚明。选择此时大张旗鼓,更像是一种拉投资的举动。
事实上,这已经不是Groq第一次公开“蹭热度”了。
之前GPT Store刚发布时,Groq给OpenAI的奥特曼发了一封信,嘲笑使用GPTs跟在“深夜读《战争与和平》一样缓慢”。马斯克的聊天机器人Grok发布时,它也跑去贴脸嘲讽,质疑Grok抄袭了自己的名字。
过去几年,打着“替代英伟达”旗号的初创公司数不胜数,Groq只不过是其中之一。目前,在超车英伟达的这条弯道,已经出现了严重塞车。
前车之鉴
Groq最直观的参考样本,是来自英国的Graphcore。
Graphcore诞生之初,也曾拿着“技术路线别出心裁、演示视频酷炫惊艳、性能数据秒杀同行”的剧本,拳头产品IPU与Groq的LPU设计思路异曲同工,也是用高速的SRAM取代DRAM作为芯片内存,以实现极致的传输性能。
同时,Graphcore调整了芯片架构,专注于处理高性能计算。
它曾颇有自知之明地表示“不与英伟达直接竞争”,只将目标客户定位在特别需要大量高性能计算的化学材料和医疗等特殊领域。
2019年,微软成为Graphcore首款IPU的大客户。2020年5月,微软科学家将IPU内置于微软Azure操作系统中,用于识别胸部X光片。这位科学家说:“Graphcore芯片可以在30分钟内完成GPU需要5个小时才能完成的工作。”
在最风光的2016年至2020年间,Graphcore共拿到了7.1亿美元融资,估值高达27.7亿美元,一度被视为全英国乃至欧洲全村的希望。Graphcore的投资者不仅有微软、三星、戴尔等科技巨头,也囊括了红杉资本、柏基投资等顶级风投。
相比今天的Groq,当年的Graphcore只能说有过之无不及。但Graphcore的后续发展却远远不及当时的预期。
2022年,Graphcore全年营收只有270万美元,为英伟达同期收入的万分之一,且相较前一年下降46%,亏损达到了2亿美元。2023年,人工智能浪潮爆发,英伟达业绩再度暴涨。H100一卡难求之时,Graphcore以为自己至少能捡英伟达的漏,结果却连汤都没喝着。
去年,Graphcore的创始人Nigel Toon向英国首相写了篇“公开信”,讨要补贴。
他在“公开信”里说,“Graphcore已经为英国预留了多达3000个IPU芯片,可以为整个国家提供服务”,几乎已经是明示要钱[4]。
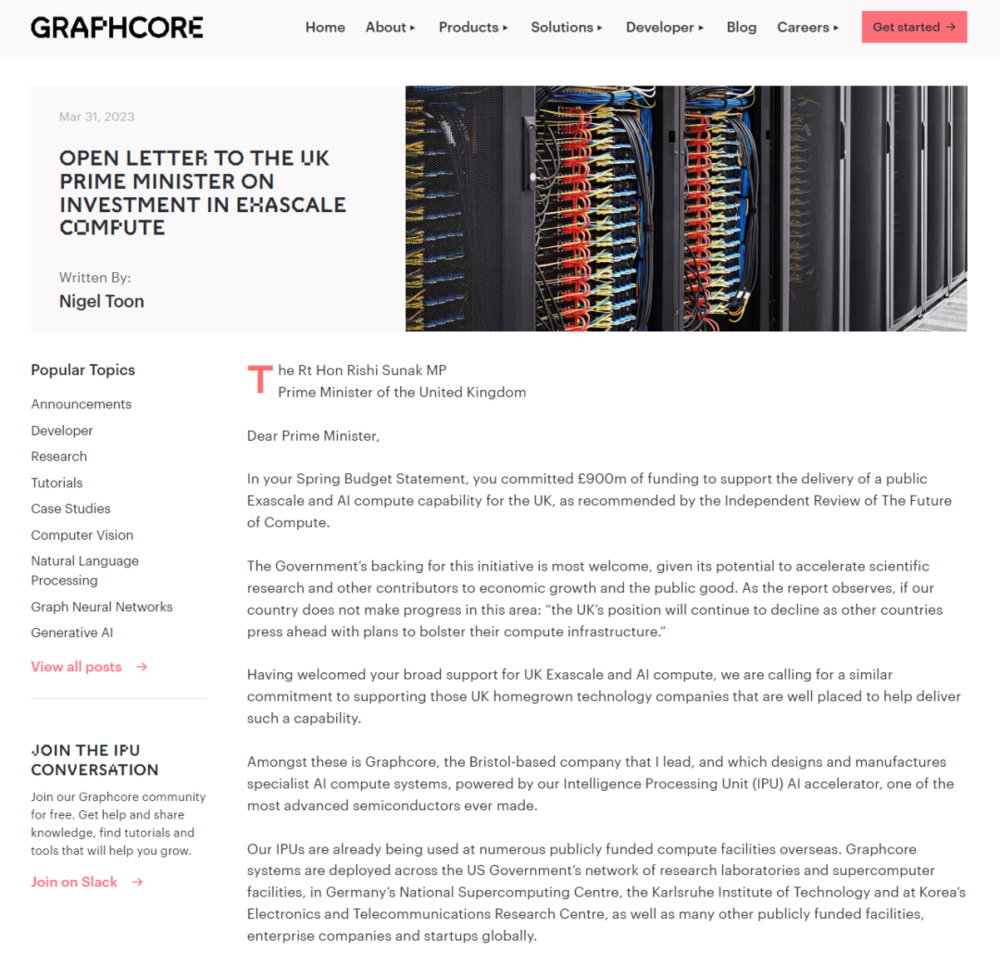
图/Graphcore官网
不久前,一面业绩亏损,一面融资无果的Graphcore走向了最后一条路:寻求收购。根据The Telegraph爆料,其售价可能在5亿多美元——不到2020年最高估值时期的五分之一[5]。
当年,以Graphcore为首的挑战者们,各怀绝学,来势汹汹,颇有一种六大门派围攻光明顶的既视感。然而,如今多已作鸟兽散。
去年3月,芯片公司Mythic一度因资金耗尽而濒临倒闭,快要淹死之际,才好不容易等到了救命缰绳,拿到了1300万美元融资。
另一家芯片公司Blaize也出现了类似的困境,最后靠着中东土豪的投资,才活了下来。
在剩下的公司中,Habana是唯一活得不错的——它被英特尔以20亿收购,保留了独立运营的权利。
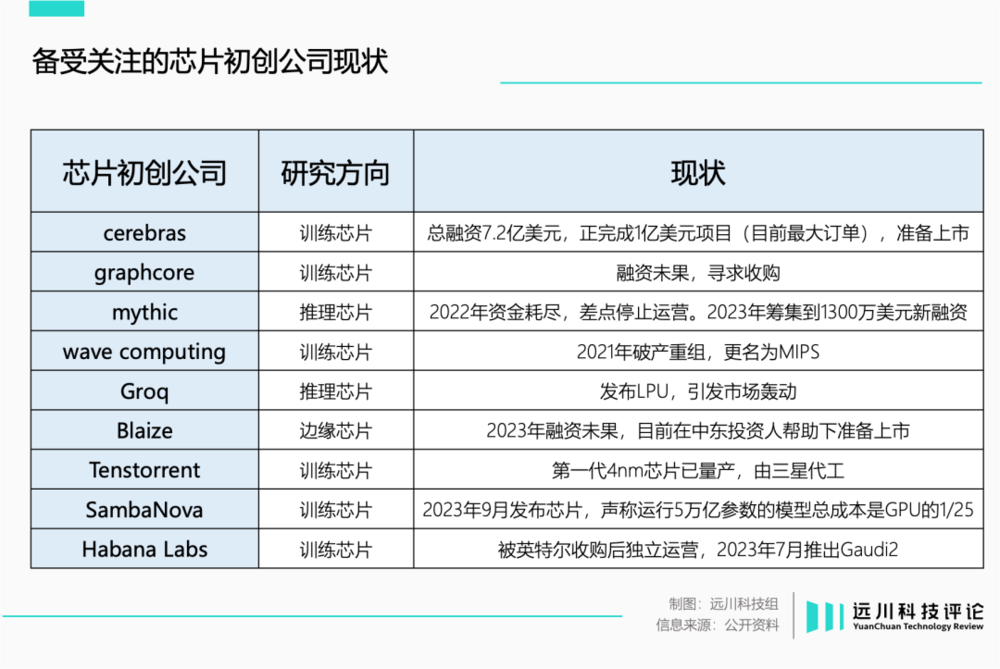
从Graphcore到Mythic,这些芯片公司的技术路线各不相同;然而,它们失败的原因却出奇一致。事实上,今天大火的Groq,同样也极有可能倒在同一个地方:芯片卖不出去。
真正的护城河
英伟达的GPU固然厉害,但它卖芯片的套路,才是真正的护城河。
每年,英伟达都会投入相当一部分的研发经费,围绕GPU搭建系统性能力。当然,这是高情商的说法,低情商的说法是开发一套“捆绑销售”的产品——这才是英伟达最坚实的城墙。目前,英伟达的城墙共有3层:
第一层城墙,是CUDA的编程生态。
众所周知,GPU最初的使用场景是游戏与视频图像渲染。早期,一些华尔街精英偶尔利用GPU的并行计算能力来跑交易,但由于需要重新编写大量代码,因此并未广泛传播开来。
黄仁勋坚信GPU能用于更多领域,因此在2006年推出了降低编程门槛的软件架构CUDA,和自家GPU捆绑推出。
后来,苹果和AMD都推出了类似平台,但此时CUDA生态早已构建,在“用的人越多,CUDA越好用,新开发者越倾向于选择CUDA”的良性循环中稳定前进。
如今,CUDA可以让英伟达GPU的使用成本大幅降低。
一位私有云CEO曾在接受采访时说过,理论上AMD卡也不是不能用,但要把这些卡调试到正常运转,需要多耗费两个月[6]——找谁下单,答案不言而喻。
第二层城墙,是NV-Link的高速传输。
一个数据中心,不可能只使用一块AI芯片。然而,如果将2块AI芯片连在一起,那么实际算力必然会小于2,因为数据传输的速度慢于芯片算力,且过程中还存在损耗。
显然,在GPU数量迅速膨胀的数据中心内,解决数据传输问题是关键。
2016年,英伟达为IBM服务器提供GPU时,首次用上了自研的NVLink技术,带宽高达80G/s,通信速度提高了5倍,性能提升了14%,好评不断。此后几年,英伟达一边迭代NVLink技术,一边规定该技术必须绑定自家芯片使用。
套路虽然简单直白,但就是有效。
而第三层城墙,则是英伟达的“铁杆好兄弟联盟”。
过去一年,英伟达是全球最主要的人工智能投资方之一,活跃程度甚至超过了a16z和红杉等顶级投资机构。
据外媒统计,英伟达去年至少有35笔人工智能投资,包括:由前DeepMind联合创始人创办的Inflection AI,欧洲人工智能独角兽Mistral,世界最大的开源模型社区Hugging Face等等[7]。
积极投资的目的其实很简单:当黄仁勋提着美金和H100芯片,敲开这些公司的大门,没有人会再拒绝英伟达。
这所有的一切,足以让市面上绝大多数公司,都绑死在英伟达的船上。
面对性能强大的英伟达GPU,各路初创公司们或许有办法,打造出性能相匹敌的产品。然而。英伟达卖芯片的套路,却让这些公司始终难以招架。因此,Graphcore等挑战者的失败,真的不是不努力。
当眼下的炒作逐渐回归寂静,Groq也得思考相同的问题:到底谁会翻过三座大山来买LPU?
尾声
2月23日,英伟达市值突破2万亿美元。距离上一个1万亿,仅仅过了9个月。
Groq的爆火,让市场又一次开始讨论同一个问题:到底有没有人能叫板英伟达?
遗憾的是,英伟达远比人们想象的要强大。人工智能浪潮给芯片行业提供了一块大蛋糕,英伟达并没有分蛋糕的意思,而是整个端走塞进了口袋。
芯片初创公司Mythic的CEO曾愤然表示,人工智能火了,他们却更难融资了,就是英伟达“搞坏了大环境”。
根据PitchBook数据,截至2023年8月底,美国芯片初创企业融资8.814亿美元,约为2022年同期的一半。交易数量的变化则更加触目惊心:从23宗减少到了4宗[8]。
Graphcore、Mythic的前车之鉴历历在目,所以也不怪Groq跟大家玩儿文字游戏。面对这么一个“汤都不给喝”的庞然大物,Groq又能怎么办呢?
参考资料
[1] Jay Scambler,X
[2] Groq Inference Tokenomics: Speed, But At What Cost,Semi Analysis
[3] 大模型最快推理芯片一夜易主:谷歌TPU创业团队打造,量子位
[4] OPEN LETTER TO THE UK PRIME MINISTER ON INVESTMENT IN EXASCALE COMPUTE,Graphcore
[5] British AI champion explores foreign sale,The Telegraph
[6] Nvidia H100 GPUs: Supply and Demand,GPU Utils
[7] Nvidia emerges as leading investor in AI companies,FT
[8] Nvidia's dominance in AI chips deters funding for startups,reuters
本文来自微信公众号:远川科技评论 (ID:kechuangych),作者:叶子凌,编辑:陈彬,视觉设计:疏睿

 14:23
14:23

 16:53
16:53


 27:17
27:17
 11:04
11:04


 06:32
06:32
 14:18
14:18

 14:24
14:24
 33:45
33:45



 05:26
05:26
 13:00
13:00





