2024-02-27 11:58


扫码打开虎嗅APP

本文来自:Alpha Engineer,作者:费斌杰,题图来自:视觉中国
昨夜,Mistral AI放大招,正式发布Mistral Large模型,并且推出对标ChatGPT的对话产品:Le Chat。
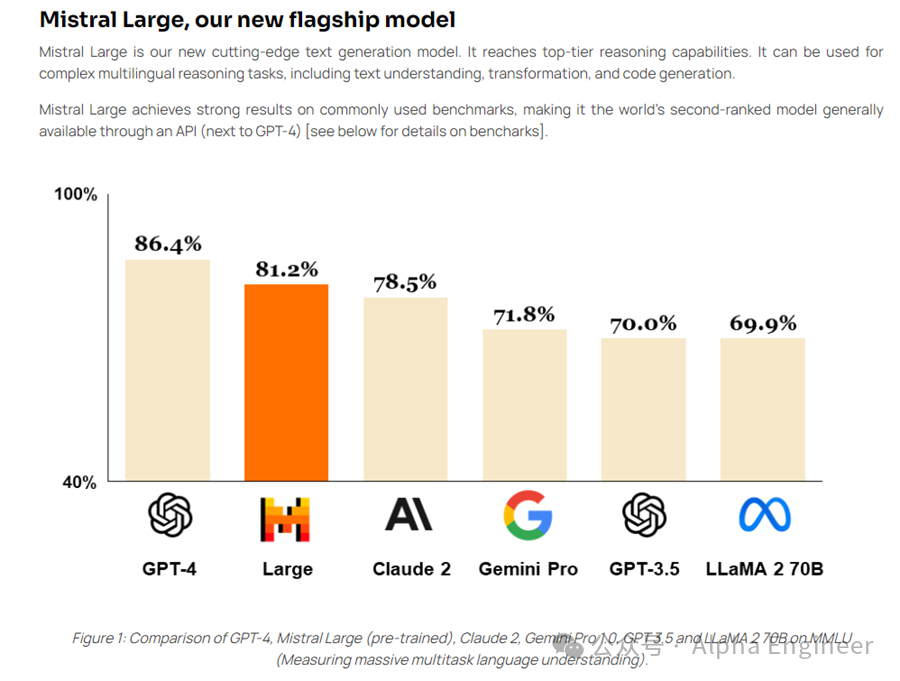
作为Mistral新推出的旗舰模型,本次发布的Mistral Large在常识推理和知识问答上均表现出色,综合评分超过Gemini Pro及Claude 2,仅次于GPT-4,荣登世界第二的宝座。
说到Mistral相信大家并不陌生。对,就是那个二话不说上磁力链接的Mistral。
去年12月8日,Mistral AI在几乎没有任何预热的情况下,直接在Twitter上低调发布了最新大模型的下载磁力链接,引爆整个AI圈。清新脱俗的画风让Jim Fan不禁高呼:Magnet link is the new arxiv。

时隔不到3个月,这次Mistral又带给了我们怎样的惊喜呢?
惊喜1:精通多国语言,能文能武能Coding
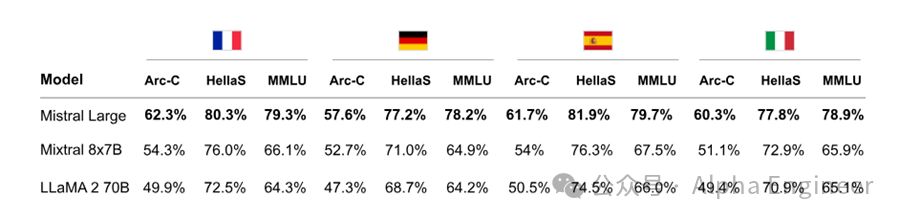
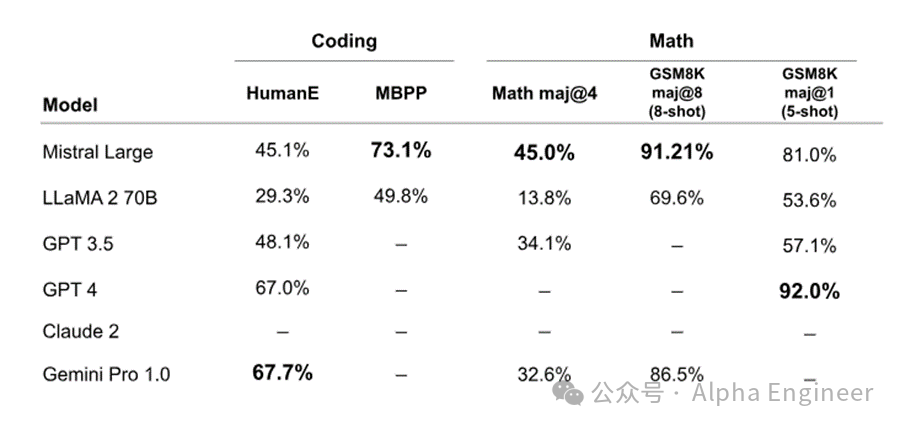
根据官方文档描述,Mistral Large模型精通包括英语、法语、西班牙语、德语和意大利语在内的多国语言,达到母语水平。
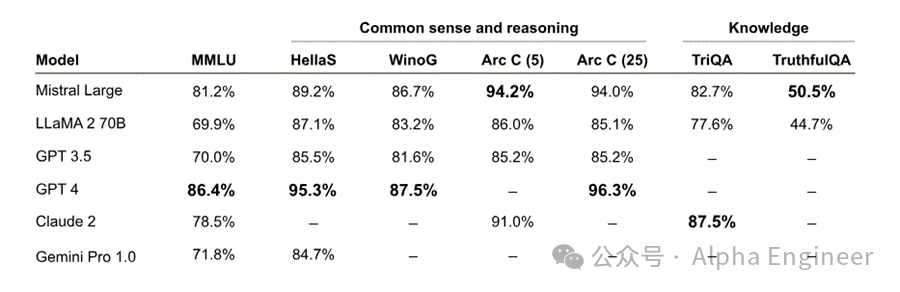
在HellaSwag、Arc-C、MMLU等benchmark上,Mistral Large的性能表现碾压Llama 2 70B,后者是目前世界公认的最强开源大模型。
与此同时,Mistral Large在数学和代码上的能力也不弱,在MBPP pass@1、Math maj@4、GSM8K maj@8、GSM8K maj@1上均有相当不错的表现,超过了GPT-3.5。
惊喜2:价格只有GPT-4的1/7,支持32k上下文窗口
32k tokens的上下文窗口可能不太直观,具体来说约等于2万个英文单词的长度。
GPT-4-32k目前的价格是这样的:一百万个输入token花费60美元,一百万个输出token对应120美元。
相比之下,根据Mistral Large API的报价,一百万个输入token定价8美元,一百万个输出token对应24美元。同等上下文窗口的条件下,Mistral Large的定价比GPT-4便宜了5倍~7.5倍,可谓诚意满满。
惊喜3:牵手Azure,微软生态渐成
值得玩味的是,在模型发布的同时,Mistral特意提及了与微软Azure的合作。Azure的客户可以直接通过Azure AI Studio和Azure Machine Learning访问Mistral的模型。

微软作为OpenAI背后的金主,一直以来也在与其他大模型公司积极合作。
去年7月,微软就与Meta达成合作,将Llama 2模型上架到Azure供客户使用。不得不佩服Nadella的战略眼光和生态手腕。

MoE再下一城
Mistral一直以来是MoE路线的拥趸。去年12月初发布的Mistral 8×7B就是一个技术MoE架构的大模型。当时Arthur就发出预告,将在2024年推出性能对标GPT-4的MoE模型,没想到幸福来得这么快。
那么MoE是什么,为什么MoE被业界寄予厚望,它会给未来大语言模型的发展带来怎样的变化和冲击?
什么是MoE?
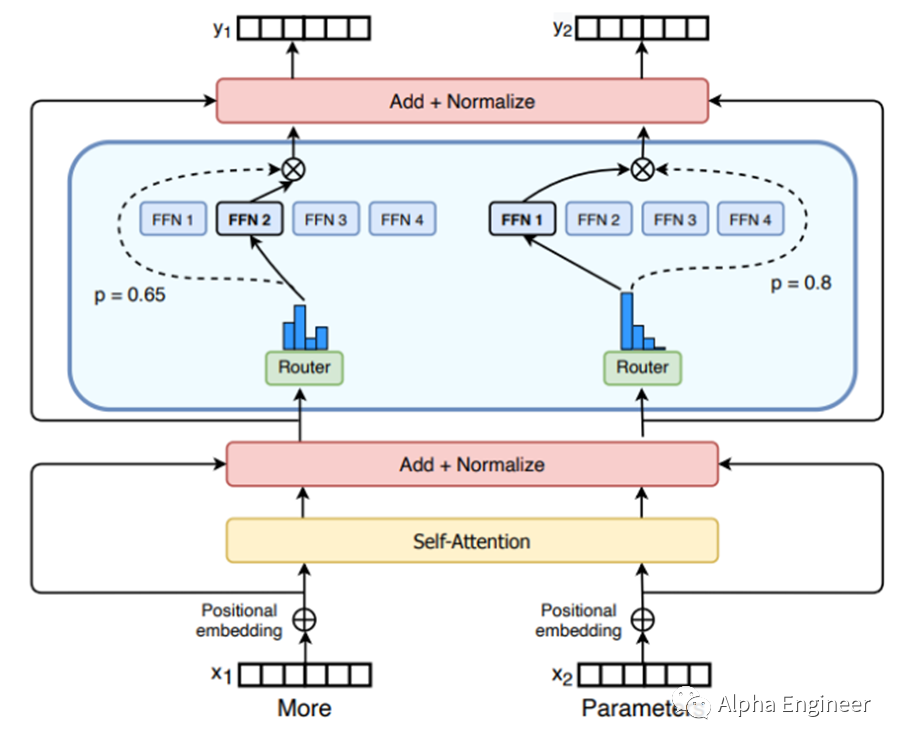
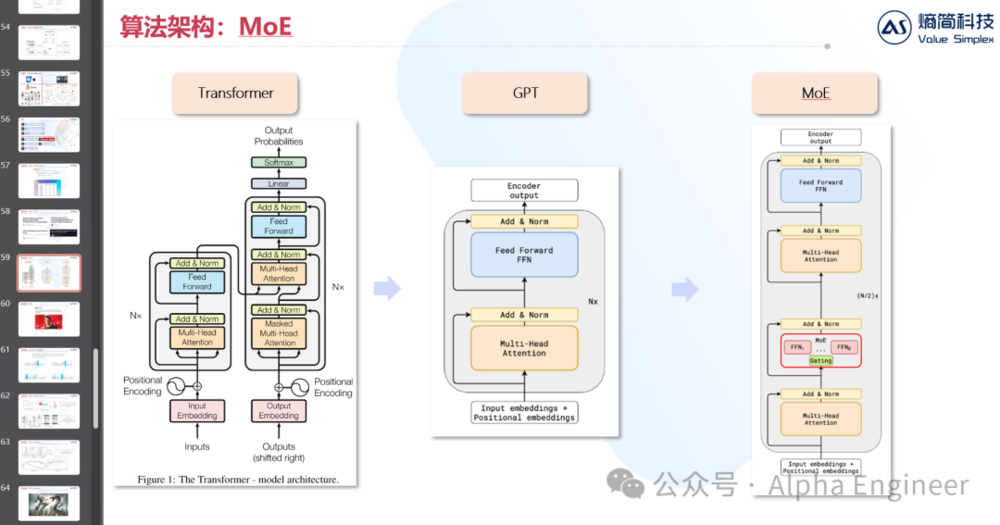
MoE的全称是Mixture of Experts,即混合专家模型。MoE架构分为两部分:专家(Experts)、路由(Router)。每个专家都是一个神经网络。在实操中,专家就是一个FFN(Feed Forward Network)。一个MoE层中可以包括很多个专家,从8个到2048个都有。路由,顾名思义,决定了每个token交给哪个专家来处理。一个token可以同时路由到多个专家。路由模型参数的训练,是MoE模型训练中的核心。
MoE解决了什么问题?
MoE架构本身并不复杂,但是相比搞清楚MoE架构是什么,更重要的是弄明白为什么我们需要MoE架构,它究竟解决了什么具体问题。
众所周知,大模型的性能表现与其参数规模高度相关。参数规模越大,大模型就能吸收更多知识,从而获得更好的性能表现。但是扩大参数规模的同时,也会显著增加算力成本支出,造成较大的研发开支,让不少人对扩大参数规模望而却步。
那么有没有一种方法,能够在控制算力成本不变的前提下,尽可能多地扩大模型的参数规模呢?MoE就能做到这一点,其背后的核心思想是通过引入稀疏性,让大模型在推理时,每次只激活部分参数,让不同的“专家”网络来解决不同的问题。这样一来,针对不同的输入,大模型能够按需选择激活不同的“专家”网络,使得大模型在算力成本不变的前提下,大幅提升参数规模。
MoE的起源
关于MoE在深度神经网络中的研究,可以追溯到2017年的一篇论文,标题叫做Outrageously Large Neural Networks(没错,就叫“超级巨大的神经网络”)。

MoE的基本思想是,由多个专家共同构成一个复杂神经网络,每个专家擅长处理一类问题。打个通俗的比方,专家A擅长解数学题,专家B擅长提取摘要,专家C擅长做翻译,专家D擅长写代码。实际情况比这个复杂一些,但是理念相通。
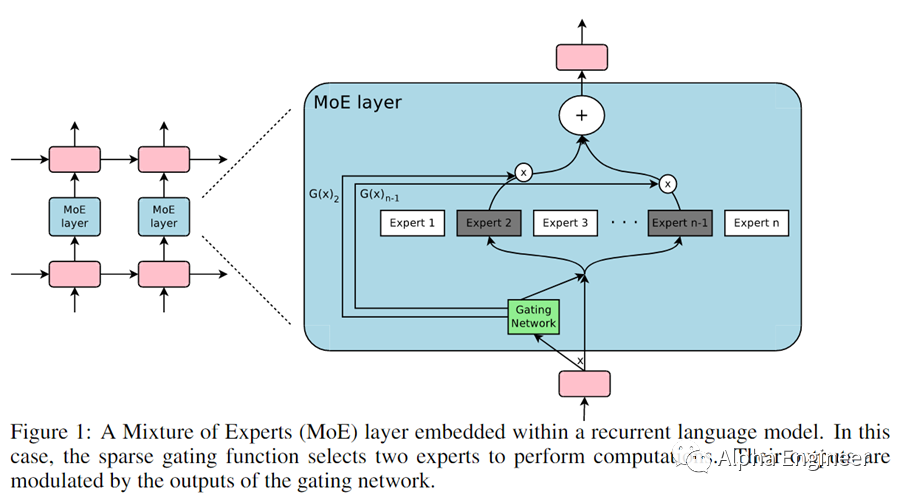
那么怎么决定用哪个专家网络呢?这就需要用到路由了。路由本身也是一个神经网络,它决定了各个专家的权重。路由网络和专家网络的参数,都是模型训练的对象,在反向传播的过程中被不断优化。
介绍完MoE的架构和起源,让我们更深一步,解构MoE的关键特性与挑战。
MoE关键词
关键词1:稀疏性(Sparsity)
MoE的第一个关键词是稀疏性。
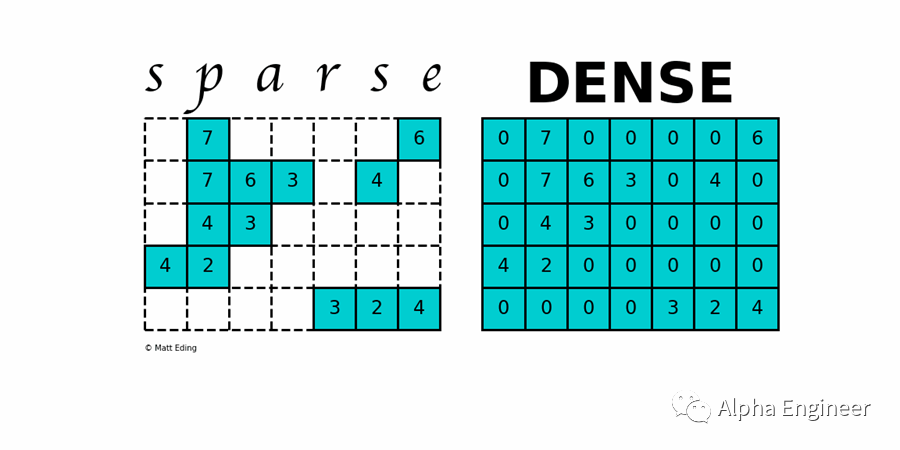
稀疏性(Sparsity)与条件计算(Conditional Computing)相关。在一个稠密模型中,任何一个输入都会用到所有模型参数,而稀疏矩阵让我们能够针对不同的输入,按条件激活不同部分的参数。通过引入稀疏性,我们能够在计算量不变的前提下,大幅提升模型的参数规模。
关键词2:负载均衡(Load Balancing)
在MoE模型训练的过程中,能力强的专家会更容易被路由优先选择。这种自我强化机制,会导致训练到最后,Routing机制只倾向于激活固定的几个专家,而绝大部分专家并没有得到有效训练。在一个理想的MoE模型中,多个专家网络应该各有所长,取长补短,这样才能够使得整体模型的性能最优。
如果只有极个别的专家能力出众,其他专家表现平平,整体模型的性能会显著下降。为了让各个专家网络的负载更加均衡,我们需要在Routing网络中加入auxiliary loss,这个loss的加入能够确保每个专家都得到比较均衡的训练。

关键词3:并行(Parallelism)
上面我们从算法理论角度对MoE进行了介绍,但是在实操中,训练一个MoE模型绝非易事。
一方面,MoE引入了分支计算,这并不是GPU所擅长的计算类型,导致运算低效。另一方面,由于MoE模型参数规模可能较大,实操中往往会将一个专家网络部署在一个计算节点上,这就涉及到多个计算节点之间的数据通信,通信带宽就成为了MoE模型训练的一个重要瓶颈。
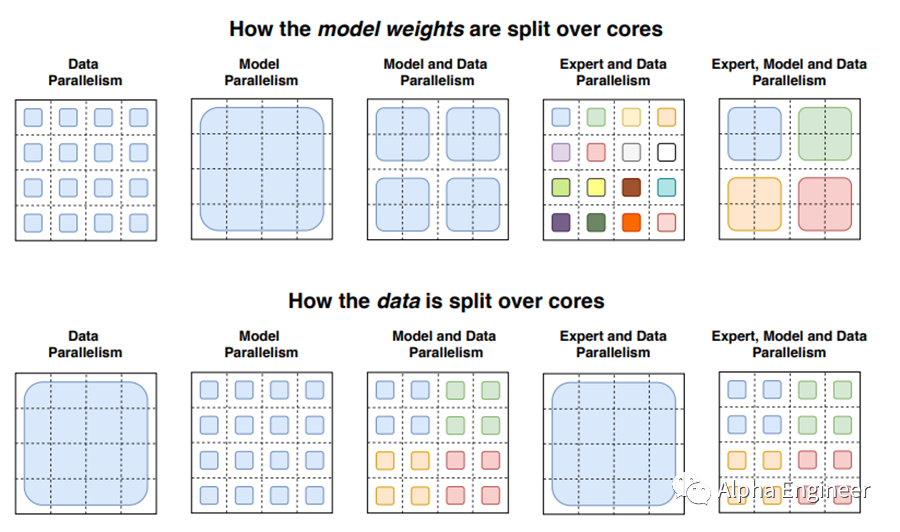
为了解决这些问题,这里需要引入了并行(Parallelism)的概念。目前一共有三种并行方法,分别是:数据并行、模型并行、专家并行。通过对并行的有效运用,能够显著提升MoE模型的训练和推理效率。在GShard的研究中,Google的研究员设计了一种工程框架,能够有效训练MoE模型,感兴趣的朋友可以在文末参考链接中查看原论文。
MoE的挑战
挑战1:训练的不稳定性
虽然MoE有很多优点,但是独特的架构也带来了新的挑战,其中之一就是MoE在训练过程中有着较高的不稳定性。
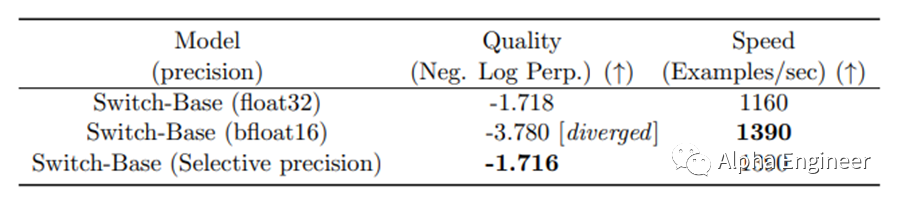
一种有效的解决方案是引入“选择性精度控制”(Selective Precision)。什么是选择性精度控制呢?由于Routing机制的本质是一个Softmax函数,内含求幂,需要更高的参数精度。与此相比,专家网络是一个FFN,不需要这么高的参数精度。因此,可以尝试将MoE模型中专家网络对应的参数精度降低到bfloat16,这样便可以显著降低MoE模型训练的不稳定性。
挑战2:模型蒸馏
本次Mistral发布的8×7B大模型部署起来比较容易,我们可以把每个专家网络部署在不同的节点上。但有些MoE模型在生产环境部署起来就没那么方便了。
MoE模型究竟可以有多大?这里举一个例子,在一项叫做“Switch Transformers”的研究中,作者发布了一个拥有2048个专家的MoE模型,其参数规模达到惊人的1.6 trillion。虽然MoE模型都是稀疏的,每次计算时不需要用到所有参数,但是你总得把所有参数都加载到内存中才能运行。
就以Mistral本次发布的8×7B的MoE模型为例,为了运行这个模型进行推理,你的VRAM需要能够加载一个47B的模型(不是56B,因为除了专家网络之外的其他参数是共用的)。假设我们将每个token路由到2个专家网络,那么该模型推理时的FLOP大致和一个12.9B的模型相当,因为每次推理都会激活两个专家网络。
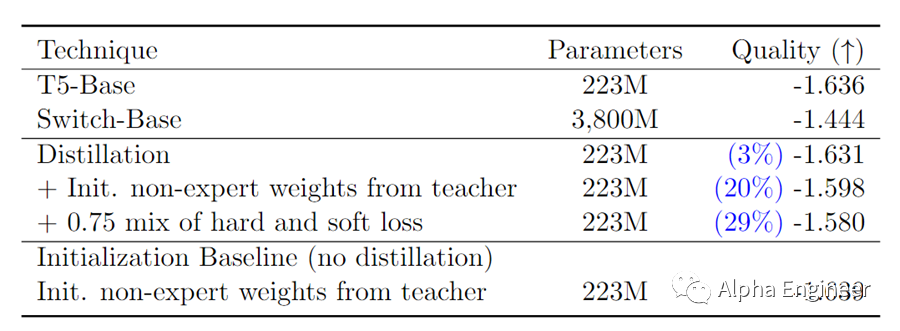
为了降低MoE模型对生产环境硬件的要求,研究人员提出了一种有效的方法:模型蒸馏(Model Distillation)。顾名思义,模型蒸馏就是把一个稀疏的MoE模型压缩成一个参数规模小得多的致密模型,同时尽可能保留稀疏性带来的好处。在“Switch Transformer”的研究中,当研究人员把稀疏模型蒸馏回原本的致密模型时,依然保留了30%左右的稀疏增益。
挑战3:微调困难,容易过拟合
虽然MoE在预训练阶段显著节省了算力,但是容易在微调阶段陷入过拟合的困境,因为参数规模太大了。
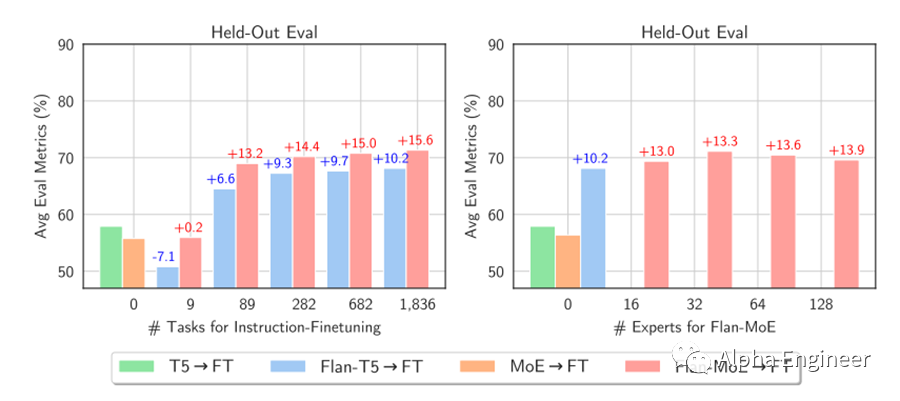
解决方案之一就是为MoE模型设置更高的Dropout Rate。在今年7月的一份研究中(MoEs Meets Instruction Tuning),研究人员分析了指令微调对MoE模型的性能影响。实验结果表明,通过指令微调,MoE模型的性能提升幅度,比稠密模型的性能提升更大。这说明在MoE模型中引入的auxiliary loss能够有效降低过拟合现象。
参考文献
[1] Mixture of Experts Explained, Hugging Face
[2] Shazeer N, Mirhoseini A, Maziarz K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[J]. arXiv preprint arXiv:1701.06538, 2017.
[3] Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. The Journal of Machine Learning Research, 2022, 23(1): 5232-5270.[4] Jacobs R A, Jordan M I, Nowlan S J, et al. Adaptive mixtures of local experts[J]. Neural computation, 1991, 3(1): 79-87.
[5] Zoph B, Bello I, Kumar S, et al. St-moe: Designing stable and transferable sparse expert models[J]. arXiv preprint arXiv:2202.08906, 2022.
[6] Du N, Huang Y, Dai A M, et al. Glam: Efficient scaling of language models with mixture-of-experts[C]//International Conference on Machine Learning. PMLR, 2022: 5547-5569.
[7] Lepikhin D, Lee H J, Xu Y, et al. Gshard: Scaling giant models with conditional computation and automatic sharding[J]. arXiv preprint arXiv:2006.16668, 2020.
本文来自:Alpha Engineer,作者:费斌杰

 05:44
05:44









 13:10
13:10
 11:57
11:57
 34:59
34:59
 06:21
06:21
 07:53
07:53
 07:13
07:13
 32:45
32:45
 12:11
12:11
 05:19
05:19




