2024-03-13 17:56


扫码打开虎嗅APP

本文来自微信公众号:酷玩实验室(ID:coollabs),作者:酷玩实验室,题图来自:视觉中国
旧金山的广场、海边、街头,一个无头机器人迈着僵硬的步伐踽踽独行,同时它的手臂也以相同的频率摆动。
视频/Humanoid Locomotion as Next Token Prediction&UC Berkely
这个不起眼的机器人,却引起了Sora团队的注意。
他们一个夸它牛,一个说它把AI带入了现实。
说实话,看到这个机器人的视频时,我的内心是毫无波澜的。虽然这是一个来自著名的加州大学伯克利分校的团队,但这步子僵硬且机械,似乎只能用一种频率和幅度迈开,手臂也是一样,而设计者甚至潦草到不给它装个脑袋。
要知道,隔壁特斯拉的Optimus正在把玩鸡蛋,Figure熟练地倒咖啡,而波士顿动力的ATLAS都开始跑酷了。
那Sora的人到底在吹什么呢?它那蹩脚的步伐里又藏着什么意义?
简单来说,因为加州大学伯克利分校的这篇论文,我们在科幻电影里经常看到的,那个人形机器人与人类共存的时代可能很快就要来了。
01
在他们的论文一开始,我就看到了一个熟悉的名字:Transformer。
我不禁收起了看乐子的心态,开始认真研究起来。

图/论文Humanoid Locomotion as Next Token Prediction
要知道这可是Transformer,搞出了GPT和Sora的Transformer。
不过,Transformer此前都是在搞文本和图像方面的研究,它是怎么用来训练机器人运动的?
要理解这个问题,我们得首先知道机器人是如何运动的。
在机器人领域,通常把这三部分叫做感知层、决策层和执行层。
拿人来类比,感知层就相当于人体的眼睛、鼻子、耳朵、皮肤等一切感官;决策层就相当于大脑和脊髓组成中枢神经系统,负责对接收到的信息综合处理,且对将要执行的动作进行规划。执行层则相当于肌肉和骨骼,完成相应的动作;
人做一个动作是很轻松的。但对机器人而言,不论是从感知到决策,还是从决策到执行,都不是一件容易的事情。
比如简简单单迈一步,我需要根据视觉信息去绘制数字空间,决策层根据数字空间去规划机器人每一部分的运动轨迹,要迈多大的步子,什么样的速度,运动时如何保持平衡等等,然后决策层将这些考虑因素输出成机器人各部位能够执行的指令传递出去。
在以往的机器人设计当中,这部分的指令是需要程序员人工编程的,而且是每一种可能遇到的情况,比如地面软了、地面滑了、前高后低了、前低后高了等等,都需要对每一个关节,每一台电机,重新编程。
程序员可以考虑一万种情况,但一旦出现第一万零一种情况,就需要重新单独编程。
这也是为什么,ATLAS永远活在视频里,并且好几个月才出现一次。因为换个动作,换个环境,它就会歇菜。
但请注意了,开头这个迈着蹩脚步伐,在海边、街道、广场走的无头机器人,它能适应从未见过的新情况,并且只用了27个小时的数据就训练到了目前的程度。
02
为什么Transformer的加入能带来这个变化?
其实它本身的底层逻辑很简单,就是在一段文字之后,不停地接下一个单词,从而形成一整段的文字。
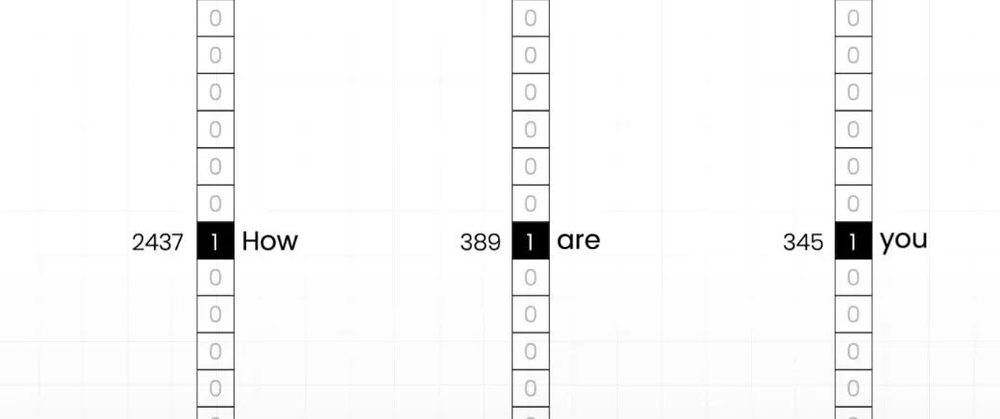
在Transformer出现前,这一领域中最热门的模型是RNN。
RNN在做单词接龙时同样也会考虑到上下文,且它的网络结构比Transformer更加精细,但当它的规模一大,就会出现自身无法解决的系统性问题。
因为当你在接龙时必须考虑到上下文,RNN的上下文信息是像击鼓传花一样,从句子开头传到末尾,当上下文信息没传到句末,就没法接词,所以RNN难做并行运算,计算效率很低。
相比之下,Transformer的上下文信息是计算句末的词与所有词的关系得到,非常直给,也很容易规模化。
当你把规模做到一定程度,比如像GPT-3.5那样的1750亿参数,它就表现出远超RNN的能力,不仅话语通顺,还可以呈现出丰富的知识,很高的逻辑性和情商,跟用户对答如流。
那么伯克利这个团队是怎么用Transformer的呢?
在该团队的论文的摘要中,他们将“现实世界的人形机器人控制问题视为一个预测下一个token的问题”。
简单来说,机器人的运动就像一串文字,下一时刻该怎么动,就类似下一个词语该怎么接。
他们的研究带来了两个巨大的改变:
第一,机器人不再单纯地“模仿”了。
正如当Transformer的参数量大到一定程度后“智能”突然涌现出来一样,这个机器人不仅能够在从未训练过的场景里行走,还能做出“倒退”这样训练中从没出现过的动作。
第二,他们搞定了规模做大的必需品,大规模的训练数据。
他们的训练数据有四大来源:先前的神经网络,基于模型的控制器,运动捕捉,以及油管上的人类视频。
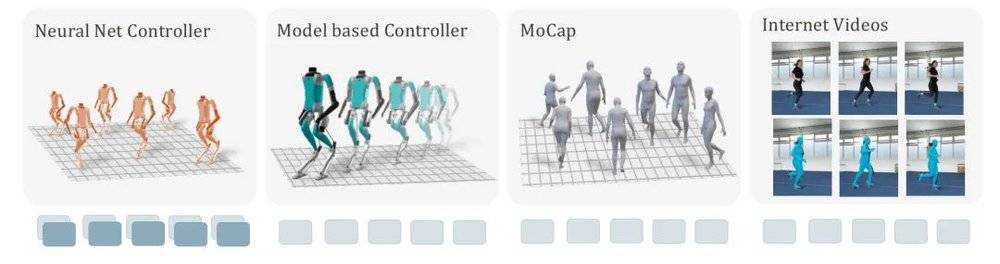
图/论文Humanoid Locomotion as Next Token Prediction
好家伙,直接能把油管视频拿来用了?
他们还真用了,不过不是直接把视频扔进去训练,而是得先把这些视频“洗”一遍,也就是把这些视频里的人抽象成3D数字人,然后再拿去训练。
要知道,同样用了Transformer的GPT,正是用了从网络中提取而来的大规模文本数据,才实现了规模效应,成长为今天这个样子的。
这篇论文中,他们同样发现,运用在机器人领域的Transformer,同样具有规模效应。随着数据量和参数规模的增大,预测的错误率有了明显下降。
而这意味着,当规模大到一定程度,就像GPT-4能翻译,能做题还能写小说一样,机器人不仅能适应全场景,而且能在手、头、腰等多个部分有更加自然的动作。
03
我相信很多人都想象过,人与非常像人的机器人共生的世界。
在那个世界,机器人会代替我们去做任何我们不想干的事儿,养老和单身也再也不会成为问题。另一方面,我们也需要时刻提防机器人可能的“起义”“暴动”。
2024年是智能机器人成为风口的一年。
英伟达的CEO黄仁勋说机器人基础模型可能即将出现,“从那时起,五年后,将看到一些非常令人惊奇的事情”。
开发通用人形机器人的AI机器人公司Figure,2月29日在B轮融资中筹集了6.75亿美元,估值为26亿美元,其投资者包括了微软、OpenAI、英伟达、亚马逊的CEO贝佐斯等多个处于硅谷金字塔尖的玩家。
OpenAI更是直接跟Figure达成合作协议,准备把多模态模型拓展到机器人身上。
这些引领着科技进步的势力在人形机器人上看到了未来。
美国著名的科学哲学家托马斯·库恩在他的著作《科学革命的结构》中提出了“范式转换”一词。当科学的范式发生转换,结果就是科学革命。
2017年,Transformer出现后,横扫了自然语言领域,成为了新的范式,自此AI界发生了巨大变化,如今我们生活中遇到的几乎所有知名AI,包括GPT、Claude、Sora、文心一言、华为的盘古、阿里的通义千问等等,全都采用了Transformer架构。
现在,它要准备征服机器人界了。
那一天,要来了吗?
本文来自微信公众号:酷玩实验室(ID:coollabs),作者:酷玩实验室

 37:03
37:03



 17:21
17:21





 17:57
17:57

 25:37
25:37
 15:28
15:28
 05:53
05:53
 07:01
07:01
 12:58
12:58
 24:51
24:51
 04:54
04:54



